神经网络结构搜索 NAS
文章目录
-
- 【NAS:Neural Architecture Search with Reinforcement Learning】
- 【NASNet:Learning Transferable Architectures for Scalable Image Recognition】
- 【MnasNet:Platform-Aware Neural Architecture Search for Mobile】
- 【ENAS:Efficient Neural Architecture Search】
Neural Architecture Search(NAS)
https://blog.csdn.net/jinzhuojun/article/details/84698471
【NAS:Neural Architecture Search with Reinforcement Learning】
CSDN:https://blog.csdn.net/saturdaysunset/article/details/107072379
【NASNet:Learning Transferable Architectures for Scalable Image Recognition】
CSDN:https://blog.csdn.net/saturdaysunset/article/details/107144507
【MnasNet:Platform-Aware Neural Architecture Search for Mobile】
cnblogs:https://www.cnblogs.com/marsggbo/p/12229794.html
CSDN:https://blog.csdn.net/weixin_37993251/article/details/91354813
代码:https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet
【优化目标】
之前的NAS算法(如DARTS,ENAS)考虑更多的是模型最终结果是否是SOTA,MnasNet则是希望搜索出又小又有效的网络结构,因此将多个元素作为优化指标,包括准确率,在真实移动设备上的延迟等,最终定义的优化函数如下:
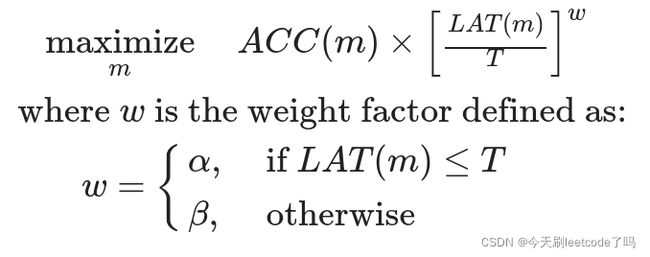
上式中个符号含义如下:
mm表示模型(model)
ACC(m)ACC(m)表示在特定任务上的结果(如准确率)
LAT(m)LAT(m)表示在设备上测得的实际计算延迟时间
TT表示目标延迟时间(target latency)
ww表示不同场景下对latency的控制因子。当实测延迟时间LAT(m)LAT(m)小于目标延迟时间TT时,w=αw=α;反之w=βw=β
上面式子其实表示为帕累托最优,因为一般而言延迟越长,代表模型越大,即参数越大,相应地模型结果也会越好;反之延迟越小,模型表现也会有略微下降。
文中提到latency单位提升会带来5%的acc提升。也就是说假如模型A最终延迟为t,准确率为a;模型B延迟为2t,那么它的准确率应该是a(1+5%)。但是这两个模型的reward应该是相等地,套用上面的公式有
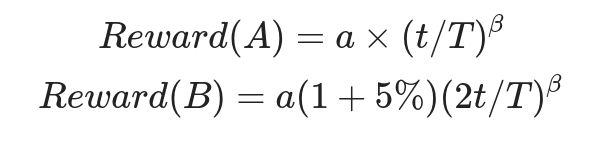
求解得到α=β=−0.7
【搜索空间】
之前的NAS算法都是搜索出一个比较好的cell,然后重复堆叠若干个cell得到最终的网络,这种方式很明显限制了网络的多样性。MnasNet做了一些改进可以让每一层不一样,具体思路是将模型划分成若干个block,每个block可以由不同数量的layer组成,每个layer则由不同的operation来表示,


可以看到搜索空间包含如下:
标准卷积,深度可分离卷积(DWConv), MBConv(即上面提到的MobileNetV2的卷积模块)
卷积核大小:3, 5, 7等
Squeeze-and-excitation ratio (SE-Ratio): 0, 0.25
Skip-connection
输出通道数
不同block中的layer数量 NiNi
【搜索算法】
和ENAS一样使用的是强化学习进行搜索,这里不做细究(其实论文里也没怎么说)。
如图1所示,搜索框架由三个部分组成:一个基于递归神经网络(RNN)的控制器、一个获取模型精度的训练器和一个用于测量延迟的基于手机的推理引擎。
我们遵循众所周知的sample-eval-update循环来训练控制器。
每一步,控制器第一批样本使用当前的参数θ,一批模型从其RNN中基于softmax logits预测令牌序列。
对于每一个采样的模型m,我们将其训练在目标任务上,得到其精度ACC(m),并在实际手机上运行,得到其推理延迟LAT(m)。
然后用公式2计算奖励值R(m)。每一步结束时,控制器的参数θ更新通过最大化期望的奖励由方程5使用近端策略优化[30]。
sample-evalupdate循环重复,直到达到最大数量的步骤或参数θ收敛。
【ENAS:Efficient Neural Architecture Search】
CSDN:https://blog.csdn.net/zhou_438/article/details/114173951
CSDN:https://blog.csdn.net/saturdaysunset/article/details/107170009
论文:https://arxiv.org/abs/1802.03268
代码(torch):https://github.com/carpedm20/ENAS-pytorch
部分代码解读:https://blog.csdn.net/saturdaysunset/article/details/107170009
ENAS论文的全称是Efficient Neural Architecture Search via Parameter Sharing,是由谷歌、CMU和斯坦福大学联合推出的论文。
从早期的两篇NAS论文(NAS、NASNet)可以看出,在搜索架构的过程中,需要动用500个GPU,这对于普通人来说根本是可望而不可及的研究领域。
ENAS的论文着重解决计算资源问题,将NAS的计算资源和搜索时间大幅降低,让一般的研究人员也能探索神经网络架构搜索的领域。
【基本思想】
(1)用controller RNN去预测每一个网络层(layer)的卷积参数;
(2)将controller RNN的输出作为强化学习中的action作用于搜索空间,设计子网络;
(3)在训练完子网络后,将数据验证集的精度作为强化学习的reward去训练controller RNN的参数
【Controller RNN结构】
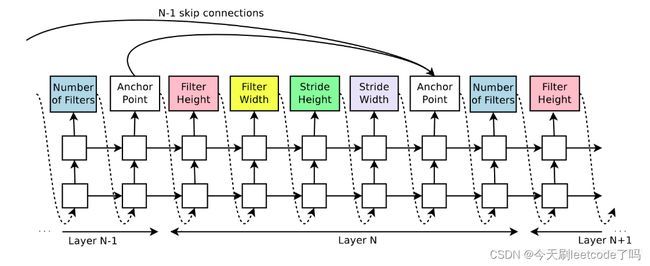
RNN是递归循环网络,上一个序列的RNN输出和隐藏层状态会作为下一个序列RNN的输入状态。本论文的controller RNN是一个2层的LSTM(长短时记忆,RNN中的一种),每层有35个隐节点。
每一次输出都是卷积操作的其中一种参数(例如:卷积核长度、宽度、步长等等),从第一层卷积层开始预测,逐步迭代预测到最后一层。
假设第一层的卷积操作有5种参数,网络共有10个卷积层,那么controller RNN总共要预测50个序列。
论文在controller的输出上还添加了一个anchor point,用于预测从前面某一层layer来的跳跃连接(skip connection)。
在预测出所有卷积层的参数后,把这些参数用来构建子网络模型
。将训练数据分成验证集和训练集两部分,训练集用于训练子网络模型,在训练结束后,子网络模型计算在验证集上的精度,并把精度值作为reward反馈给强化学习,强化学习进而去优化controller RNN的参数。
之所以会采用强化学习的方法去训练controller RNN的参数,是因为controller RNN的输出到子网络生成验证集的精度不是可导函数的计算过程,从验证集上获得的Loss无法通过梯度下降的方法传递到controller RNN的输出上。
由于每预测出一个子网络后,均需要在数据集上训练一段时间,为了加速controller RNN的训练过程,需要在集群上训练子网络和controller RNN。
论文采用parameter server的方式将K个controller的参数共享,每个controller一次共生成m个子网络,每个GPU训练一个子网络模型。将m个子网络的精度作为minibatch的数据分布式训练controller参数
【设计思想】
采用NAS论文controller RNN和强化学习的思想
采用NASNet的Cell和Block的设计
将搜索的模型参数共享,所有子网络共享同一份模型参数
在前两点上,借鉴了NAS论文方法和NASNet论文方法,都是采用controller RNN去预测Cell里面Block的input和operation等,Cell的种类也和NASNet一样,分为Normal和Reduction两种。
论文最大的改进在于第3点。之前的强化学习方法每次选择子网络后,都是重新开始训练一遍子网络模型,再从验证集上获得模型的精度。而ENAS的Cell模型空间参数只有一份,每次选择子网络后,都是在已训练的模型参数上继续训练。
比如说,Cell的第一个Block第一次选择的是3 × 3 3\times33×3的卷积和5 × 5 5\times55×5的卷积,在第一次训练完后,会反馈一次验证集的精度给controller RNN,如果第二次选择到了3 × 3 3\times33×3的depthwise卷积和5 × 5 5\times55×5卷积,那么3 × 3 3\times33×3的depthwise卷积从初始化开始训练,而5 × 5 5\times55×5的卷积则是在上一次训练后保存的基础上继续训练,就不用从初始化开始重新训练。
这种方法可以节省大量的子网络训练时间,因为很多参数重新训练的过程都是相似而冗余的,大量的计算时间浪费在同样的训练过程。ENAS通过参数共享的方式,让之前的子网络训练得到充分利用,在节省分布式计算资源的同时,也节省了大量的搜索时间。
在视觉分类的实验上,ENAS以Cifar-10为搜索数据集,在同时搜索整个网络架构的macro搜索空间(NAS论文方法)上,ENAS只使用了1个GPU(GTX1080Ti),用时7个小时;在只搜索Cell的micro搜索空间(NASNet论文方法)上,ENAS同样也只用了1个GPU,搜索了11.5个小时。