【深度学习-第2篇】CNN卷积神经网络30分钟入门!足够通俗易懂了吧(图解)
网络上有着很多关于CNN入门的教程,但是总还是觉得缺少足够简易、直观、全面的文章,能让人通读下来酣畅淋漓,将CNN概念尽收囊中。本篇文章就想尝试一下,真正地带小白同学们轻松入门。
这篇文章包含很多图片,为了花这些图笔者颇费了些功夫,认真看下来,相信你一定能有所收获。
一、从前馈神经网络说起
1.必会的内功:前馈神经网络
前馈神经网络(Feedforward Neural Networks)是最基础的神经网络模型,也被称为多层感知机(MLP)。
它由多个神经元组成,每个神经元与前一层的所有神经元相连,形成一个“全连接”的结构。每个神经元会对其输入数据进行线性变换(通过权重矩阵),然后通过一个非线性函数(如ReLU或Sigmoid)进行激活。这就是前馈神经网络的基本操作。
在本专栏之前关于神经网络入门的文章中介绍的就是前馈神经网络。
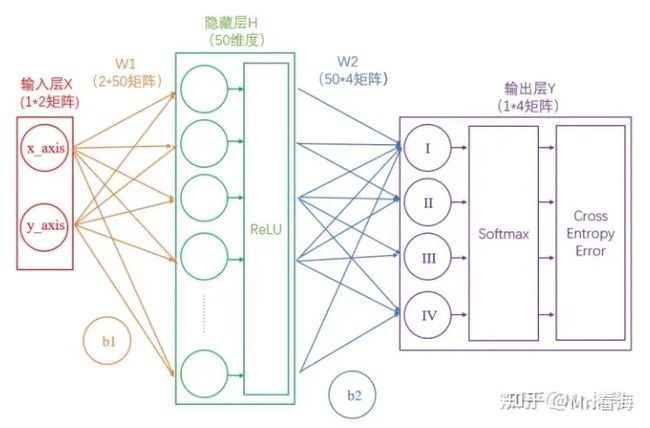
图1.前馈神经网络结构示意
前馈神经网络是深度学习的基础,所以强烈建议同学们在正式学习CNN之前,先看下边这篇文章:
Mr.看海:神经网络15分钟入门!足够通俗易懂了吧
下边关于CNN的讲解,是建立在你已经看过上边这篇文章的基础上哦!
2.从军体拳到降龙十八掌:从前馈神经网络到CNN
许多初学者在深度学习的学习过程中,通常都会从学习卷积神经网络(Convolutional Neural Network, 简称CNN)开始。很大程度上,是由于CNN的基本组成部分与前馈神经网络有很紧密的关联,甚至可以说,CNN就是一种特殊的前馈神经网络。
这两者的主要区别在于,CNN在前馈神经网络的基础上加入了卷积层和池化层(下边会讲到),以便更好地处理图像等具有空间结构的数据。
现在画图说明一下。对于前馈神经网络,我们可以将简化后的网络结构如下图表示:

图2. 前馈神经网络的简易表示
当然,【全连接层-ReLU】可以有多个,此时网络结构可以表示为:
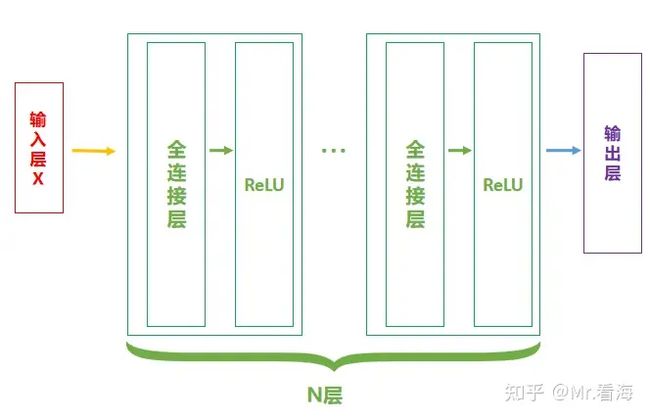
图3. 具有N个隐藏层的前馈神经网络结构
简单地说,CNN就是在此基础上,将全连接层换成池化层,并在ReLU层之后加入池化层(非必须),那么一个基本的CNN结构就可以表示成这样:
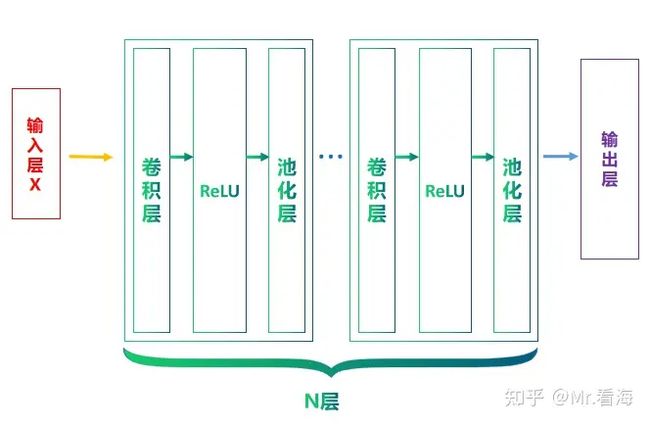
图3. N层的卷积神经网络结构
好了,现在现在问题已经简化为理解卷积层和池化层了。
二、从卷积层开始说卷积
1.为什么要用卷积?
不知道大家会不会有个疑问:所谓深度学习,不就是层数比较多的神经网络嘛,那为什么不能使用一种几十层的前馈神经网络,而要设计一个所谓的卷积神经网络呢?
如果能想到这层,说明你是经过认真思考的。
卷积神经网络最早主要是用来处理图像信息的,在用全连接前馈网络来处理图像时,会存在以下几个问题[1]:
- 参数太多:如果输入图像大小为100*100(即图像高度为100,宽度为100,单颜色通道),那么第一个隐藏层的每个神经元到输入层都有100*100=10000个互相独立的连接,每个连接对应一个权重参数,随着隐藏层神经元数量的增多,参数的规模也会急剧增加,这会导致整个神经网络的训练效率非常低。
- 不利于表达空间结构: 图像具有重要的空间结构信息。相邻的像素在语义上通常更加相关。前馈神经网络在处理图像数据时,会将图像展开成一个向量,这就破坏了图像的空间结构。而CNN通过卷积操作能够更好地保留和利用这些空间信息。
- 难以反映平移不变性: 对于图像识别任务,对象出现在图像中的具体位置并不重要,只要能够识别出对象的特征就行。CNN由于权重共享,可以无论特征在何处出现都能被检测到,从而提供了一种平移不变性。
- 难以表征抽象层级: CNN通过多个卷积层和池化层的叠加,可以从低级的边缘和纹理特征逐渐抽取出高级的语义特征。这个特性使得CNN非常适合于处理图像等需要多层抽象表示的数据。
2.又谈“什么是卷积?”
之所以要说“又”,是因为之前我专门写过一篇讲卷积的文章,从信号处理的角度解释了卷积的概念和特点:Mr.看海:这篇文章能让你明白卷积。
卷积的过程,其实是一种滤波的过程,所以卷积核(Convolution Kernel)还有一个别名叫做Filter,也就是滤波器。
在之前我写的一篇文章中曾得到过结论:当一组数像滑窗一样滑过另外一组数时,将对应的数据相乘并求和得到一组新的数,这个过程必然和卷积有着莫大的关系。

图4. 一维卷积过程
上图演示的就是一维数据的卷积过程,其中权重系数都为1/3,也就是均值滤波的过程。
变换不同的权重系数,滤波器将展现出不同的滤波特性。
所以我们又可以得到一个结论:当权重系数(卷积核)的参数改变时,它可以提取的特征类型也会改变。所以训练卷积神经网络时,实质上训练的是卷积核的参数。
将上述卷积过程拓展到二维,就是下图这样:
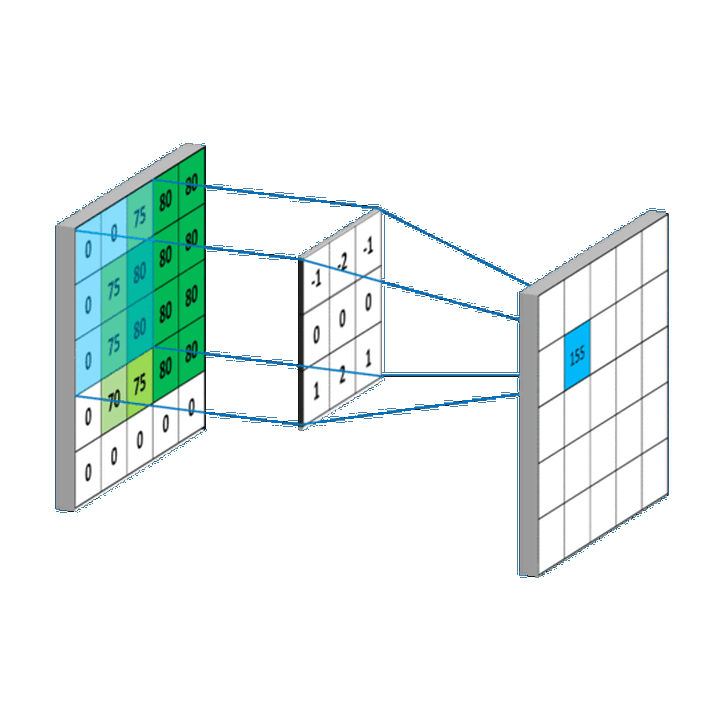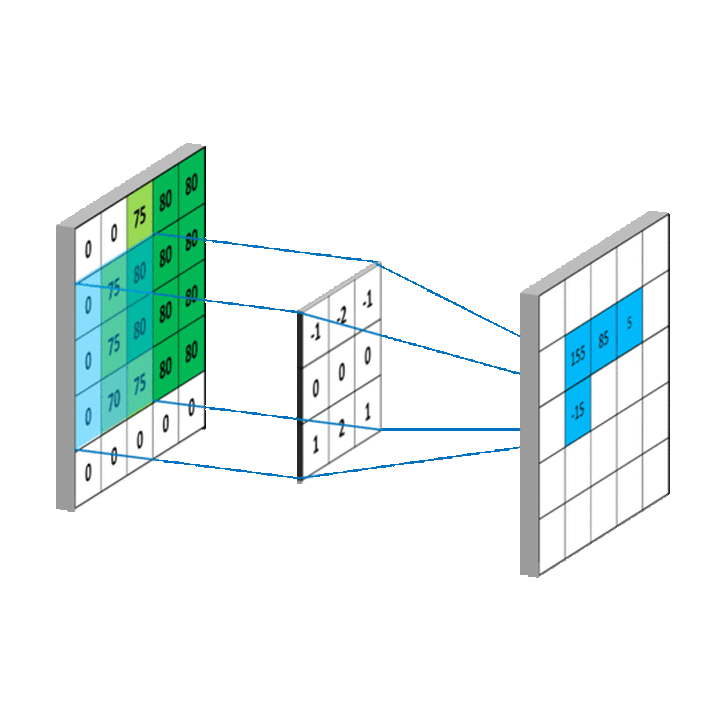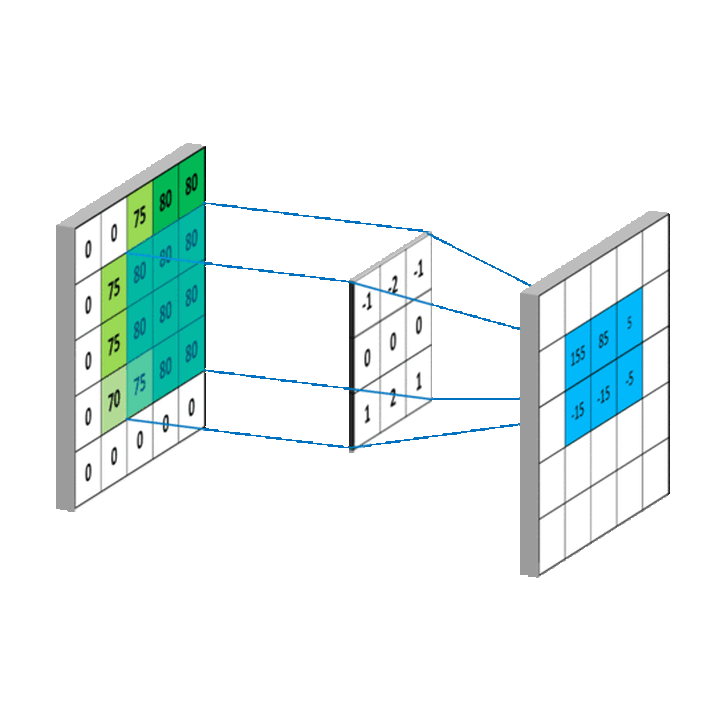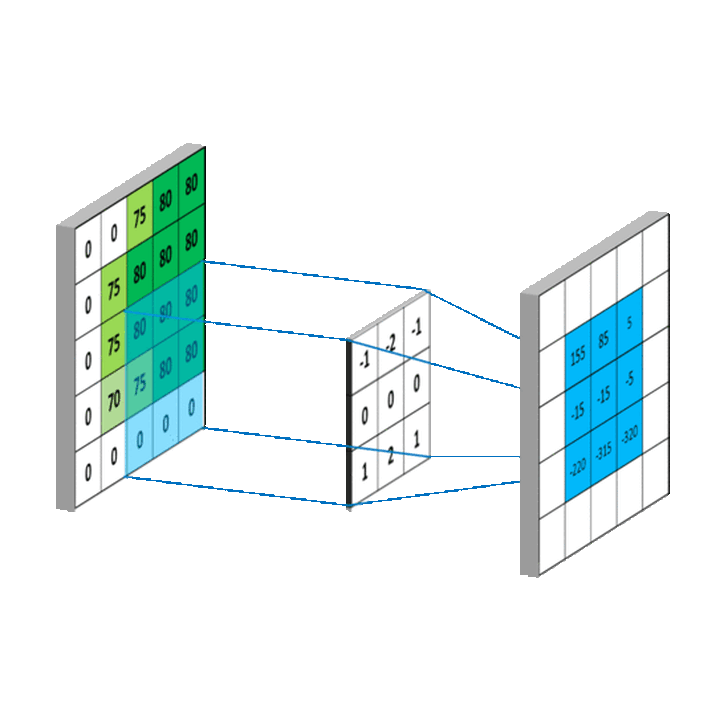
图5. 来源:https://mlnotebook.github.io/post/CNN1/
中间的矩阵就是所谓的卷积核。
现在我通俗地讲解一下这个卷积运算过程:
1.定义一个卷积核:卷积核是一个小的矩阵(例如3x3或5x5),包含一些数字。这个卷积核的作用是在图像中识别特定类型的特征,例如边缘、线条等,也可能是难以描述的抽象特征。
2.卷积核滑过图像:卷积操作开始时,卷积核会被放置在图像的左上角。然后,它会按照一定的步长(stride)在图像上滑动,可以是从左到右,也可以是从上到下。步长定义了卷积核每次移动的距离。
3.计算点积:在卷积核每个位置,都会计算卷积核和图像对应部分的点积。这就是将卷积核中的每个元素与图像中对应位置的像素值相乘,然后将所有乘积相加。
4.生成新的特征图:每次计算的点积结果被用来构建一个新的图像,也称为特征图或卷积图。
5.重复以上过程:通常在一个 CNN 中,我们会有多个不同的卷积核同时进行卷积操作。这意味着我们会得到多个特征图,每个特征图捕捉了原始图像中的不同特征。
其中每一次运算的分解图如下:
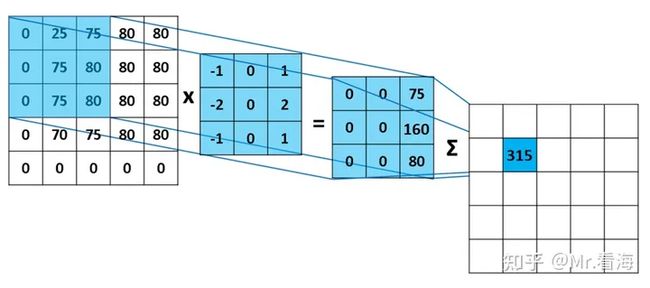
图6. 来源https://mlnotebook.github.io/post/CNN1/,部分数值做了更正
3.卷积核的取值如何影响特征输出
现在我们使用MNIST数据集作为案例。
MNIST是一个很有名的手写数字识别数据集。对于每张照片,都是以一个28*28的矩阵存储的。
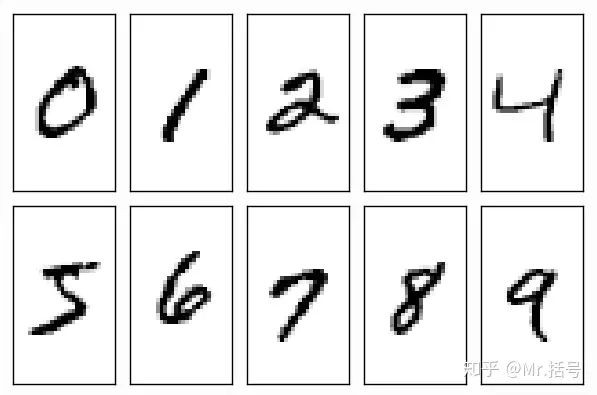
图7. MNIST数据集数字0~9示例
现在我们从数据集中随便选一个数字8,并进行卷积运算。这个卷积计算过程如下图(其中灰度深浅代表了数值大小):
图8. 红色为输入,橙色为卷积层,绿色为卷积结果,使用的是平均卷积核
这里我们选三种不同的卷积核看一下:
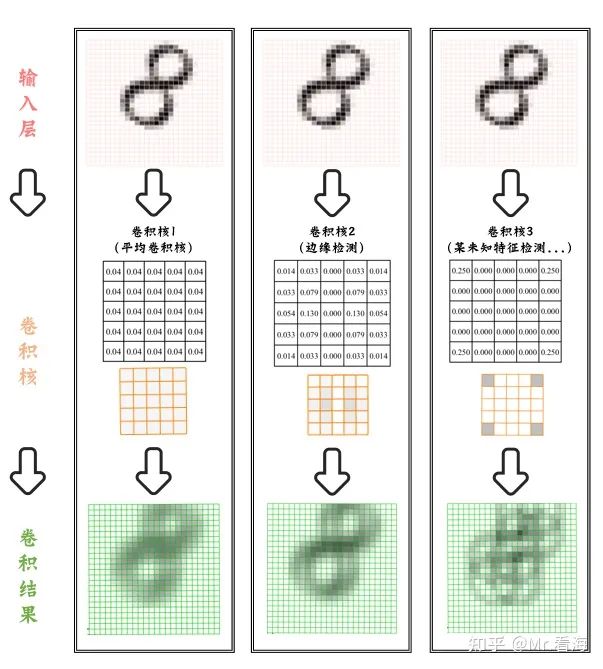
图9. 三种不同的卷积核计算下卷积结果
上述使用了三种不同的卷积核,第一种卷积核所有元素值相同,所以它可以计算输入图像在卷积核覆盖区域内的平均灰度值。这种卷积核可以平滑图像,消除噪声,但会使图像变得模糊。第二种卷积核可以检测图像中的边缘,可以看到输入的8的边缘部分颜色更深一些,在更大的图片中这种边缘检测的效果会更明显。第三种卷积核的四个角的权重为0.25,这是我随意赋的值,得到的结果像是几个窄窄的8重叠起来了。
需要注意的是,虽然上边说道不同的卷积核有着不同的作用,但是在卷积神经网络中,卷积核并不是手动设计出来的,而是通过数据驱动的方式学习得到的。这就是说,我们并不需要人工设计出特定的卷积核来检测边缘、纹理等特定的特征,而是让模型自己从训练数据中学习这些特征,即模型可以自动从复杂数据中学习到抽象和复杂的特征,这些特征可能人工设计难以达到。
这个自学习的过程具体是怎样实现的,过会儿还会讲到,我们先继续讲卷积运算。
4.卷积运算重要参数之——步长(Stride)
在卷积神经网络(CNN)中,"步长"(stride)是一个重要的概念。步长描述的是在进行卷积操作时,卷积核在输入数据上移动的距离。在两维图像中,步长通常是一个二元组,分别代表卷积核在垂直方向(高度)和水平方向(宽度)移动的单元格数。
例如,步长为1意味着卷积核在每次移动时,都只移动一个单元格,这就意味着卷积核会遍历输入数据的每一个位置;同理,如果步长为2,那么卷积核每次会移动两个单元格。
下图是步长为3时的卷积运算过程。
图10. 步长值设置为3,卷积输出结果尺寸大幅减小
步长的选择会影响卷积操作的输出尺寸。更大的步长会产生更小的输出尺寸,反之同理。
之所以设置步长,主要考虑以下几点:
- 降低计算复杂性:当步长大于1时,卷积核在滑动过程中会"跳过"一些位置,这将减少输出的尺寸并降低后续层的计算负担。
- 模型的可扩展性:增大步长可以有效地降低网络层次的尺寸,使得模型能处理更大尺寸的输入图片。
- 控制过拟合:过拟合是指模型过于复杂,以至于开始"记住"训练数据,而不是"理解"数据中的模式。通过减少模型的复杂性,我们可以降低过拟合的风险。
- 减少存储需求:更大的步长将产生更小的特征映射,因此需要更少的存储空间。
5.卷积运算重要参数之——零填充(zero-padding)
不知道大家注意到没有,在图9中,输入的28*28维矩阵在进行卷积计算之后,维度降为了24*24,是因为啥呢?
从下图可以比较清楚地看出,卷积核从左上角开始扫描时,每条边只能滑动三次。如果定义输入层的边长是M,卷积核的边长是K,那么卷积后输出的边长是M-K+1。
图11. M-K+1=5-3+1=3
所以从上边公式看出来,数据在进行卷积运算之后尺寸会缩小。众所周知,CNN是一种深度学习网络,包含很多个卷积层,那么这样一直算到后边,尺寸岂不是要变成1了?
即使没有变成1,过小的数据尺寸也会导致信息的丢失。
对此,解决办法就是在输入数据进行卷积运算前,在四周补充一圈(或多圈)数字,通常补充的是0,所以就叫“零填充”。下图中补充后的数据再进行卷积,计算结果就能保持5*5的维度啦。
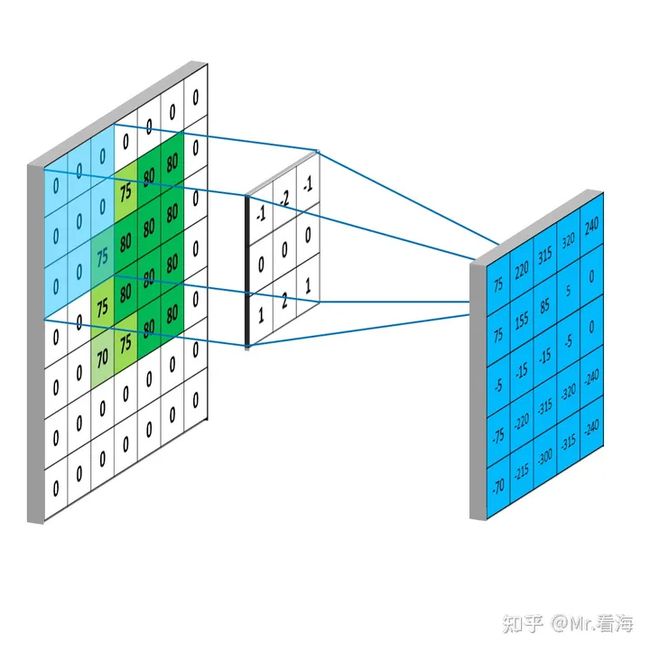
图12. 图片来源https://mlnotebook.github.io/post/CNN1/
这里我们将上述计算卷积输出的矩阵大小的公式进一步扩展,引入填充的圈数P,以及步长的长度S,此时卷积输出的矩阵边长为:
输出边长L输出边长=(M−K+2P)/S+1
需要注意,上述公式中的除法需向下取整。该公式不难推导,这里就不展开说啦。
除了上边说到的控制空间维度,防止信息丢失以外,零填充还有一个重要的意义是:更充分利用输入数据的边缘信息。
当未进行填充时,上下边缘用到的次数较少,就像下图:
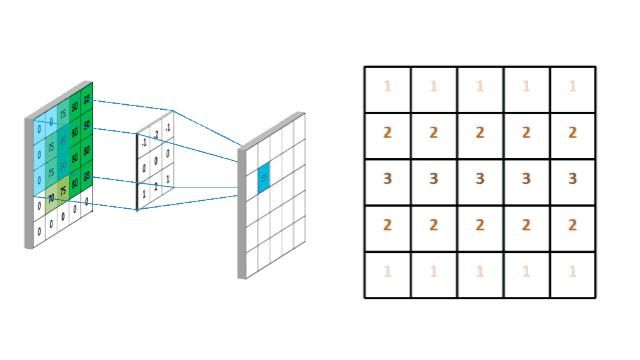
图13. 上下边缘的数据只被用到了1次,中间的用到了3次
当进行填充后,边缘数据进行了更为充分的利用,就像下图:
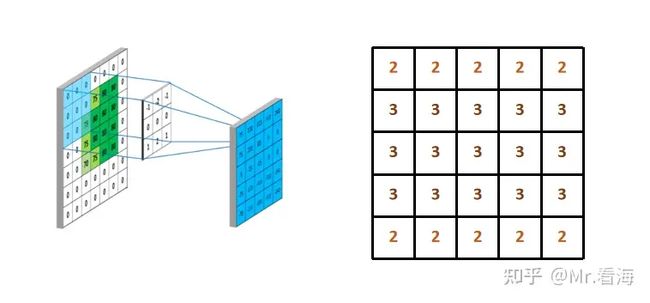
图14. 这张不是动图(∩_∩)
这种能够更均匀地处理所有信息,包括边缘信息的性质,是零填充在卷积神经网络中被广泛使用的重要原因之一。
三、再说激活层
1.ReLU在CNN中的位置
再回顾一下CNN的结构(下图),卷积层后边紧跟着就是ReLU激活层,虽然在以前的文章(Mr.看海:神经网络15分钟入门!足够通俗易懂了吧)中讲过ReLU,不过为了文章的完整性,这里还是再简单介绍一下。
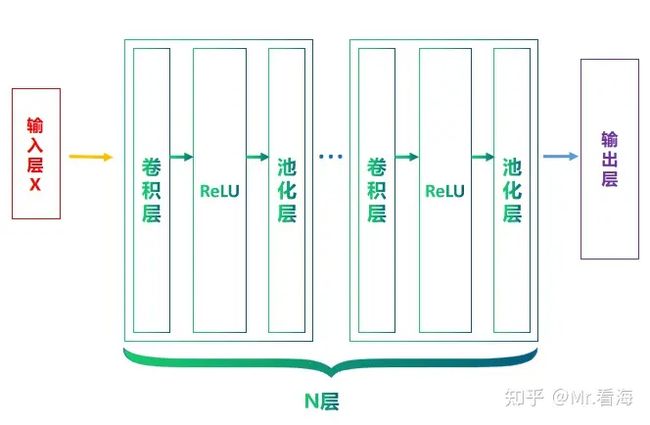
图15. 卷积神经网络结构的二次出镜
卷积层和全连接一样,也是一种线性变换,无论进行多少次这样的操作,都只能获得输入数据的线性组合。如果没有非线性的激活函数,那么即使是多层的神经网络,在理论上也可以被一个单层的神经网络所表达,这极大地限制了网络的表达能力。
ReLU函数是一个非线性函数,只保留正数元素,将负数元素设置为0。这种简单的修正线性单元具有许多优点,例如,它能够缓解梯度消失问题,计算速度快,同时ReLU的输出是稀疏的,这有助于模型的正则化。ReLU的响应函数图像如下:

图16. ReLU的理念其实很简单。当输入小于等于0时,输出0;当输入大于0时,输出1。
2.ReLU激活的动态演示
下图展示的是含负值的输出层经过ReLU计算的过程,图中红色代表负数,灰色代表正数,颜色越深数值的绝对值越大:
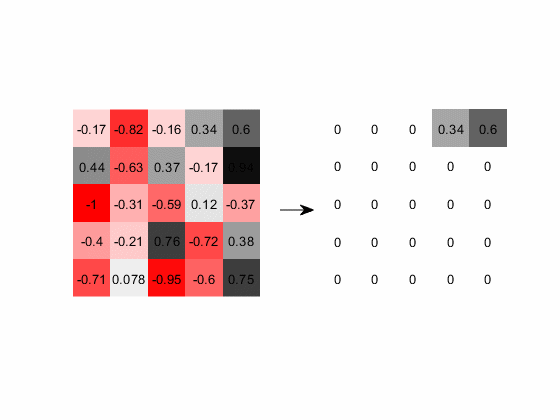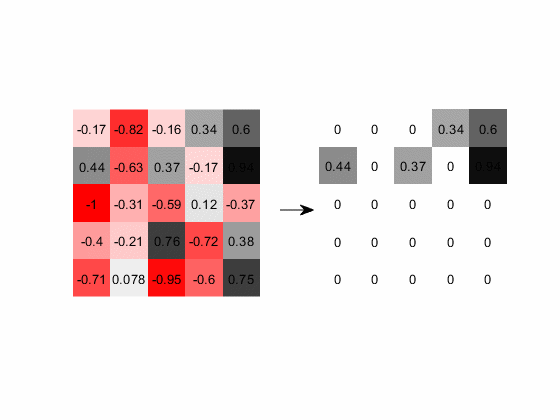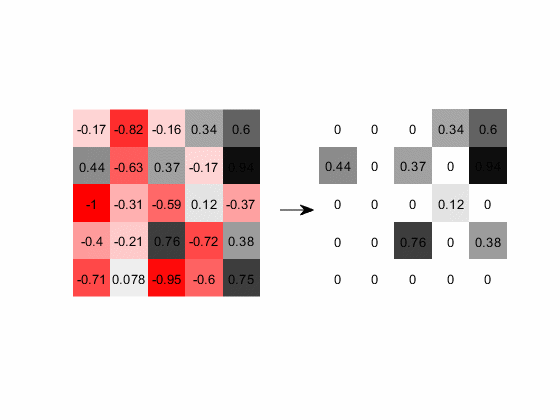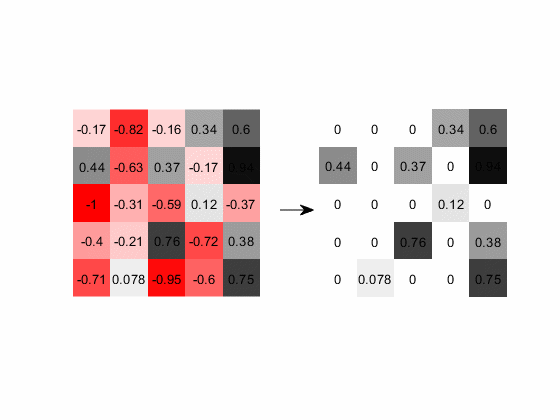
图16. 负值经过ReLU层后全部赋值为0
在我们上边手写字体的例子里,由于输入层数据和卷积核都不小于0,所以卷积计算结果全都不小于0,ReLU层前后数据不会发生变化,下边我设置一个含负数的卷积核,这样卷积运算的结果就会包含负数,此时卷积运算+ReLU非线性激活的过程就如下图:
图17. 卷积运算+ReLU非线性激活的过程
四、化繁为简的池化层
1.什么是池化层?
ReLU激活层之后就是池化层。
池化层的主要作用是对非线性激活后的结果进行降采样,以减少参数的数量,避免过拟合,并提高模型的处理速度。
池化层主要采用最大池化(Max Pooling)、平均池化(Average Pooling)等方式,对特征图进行操作。以最常见的最大池化为例,我们选择一个窗口(比如 2x2)在特征图上滑动,每次选取窗口中的最大值作为输出,这就是最大池化的工作方式:

图18. 最大池化(Max Pooling)的计算过程演示,左侧图像池化运算得到右侧图像
大致可以看出,经过池化计算后的图像,基本就是左侧特征图的“低像素版”结果。也就是说池化运算能够保留最强烈的特征,并大大降低数据体量。
对于平均池化,顾名思义,就是对窗口内的数据取平均值。相信大家都很容易理解,不再赘述。
2.加入池化层-完整的“卷积单元”
第三次看下边这张图:
图19. 我又来了——卷积神经网络结构
到现在,“卷积层→ReLU→池化层”这样一个CNN网络中的基本组成单元的基础概念就讲完了。但是需要注意,卷积层、ReLU和池化层的组合是一种常见模式,但不是唯一的方式。比如池化层作为降低网络复杂程度的计算环节,在算力硬件条件越来越好的当下,有些时候是可以减少采用次数的,也就是池化层可以在部分层设置、部分层不设置。
完整的“卷积层→ReLU→池化层”这样一个运算单元,使用上述手写字体的动图可以表示如下:
图20. “卷积→ReLU→池化”完整过程
五、关于输出层
在卷积神经网络中,最后一层(或者说最后一部分)通常被称为输出层。这个层的作用是将之前所有层的信息集合起来,产生最终的预测结果。
对于CNN进行分类任务时,输出部分的网络结构通常是一个或多个全连接层,然后连接Softmax。
当然,如果想要从卷积层过渡到全连接层,你需要对卷积层的输出进行“展平”处理,简而言之就是将二维数据逐行串起来,变成一维数据。
由于此时数据经过多层卷积和池化操作,数据量已大大减少,所以全连接层设计的参数就不会有那么多了。
输出层部分的结构我在之前的文章里有详细的讲解,具体请看下边这篇文章的第三节输出的正规化和第四节如何衡量输出的好坏:
Mr.看海:神经网络15分钟入门!足够通俗易懂了吧
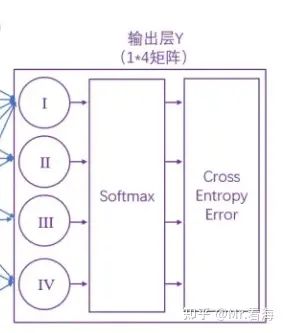
图21. 输出部分示意图(对于分类问题)
六、通过实例完整理解CNN网络结构
上边的内容已经将CNN的核心知识点都讲了一遍,就像乐高的几种基本的积木模块都介绍完了。
剩下的就是拼装的过程。
1.基础模块:输入层→卷积层→ReLU→池化层
- 1.1 输入层:在上边的例子中,输入层就是28*28的矩阵,需要注意由于我们的分析对象是灰度图,它是单通道图像,所以更准确的说法是输入层是1*28*28的矩阵,对于三通道的彩色图片的话,输入层就是3*28*28的维度了。
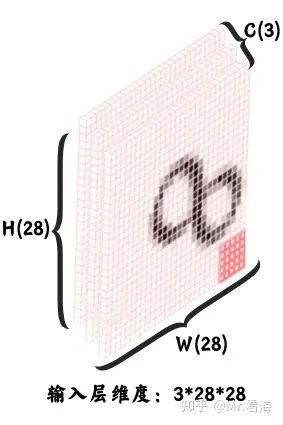
图22. 彩图通常是三通道,这里使用黑白图像作为示意,大家理解就好
- 1.2 卷积运算:需要注意,在设置卷积核的时候,除了要设置卷积核的尺寸(即长和宽),还要设置卷积核的数量。卷积核的数量决定了卷积层的输出特征图的数量,也就决定了卷积层的深度。也就是说,如果你有4个卷积核,那么你的卷积层就会输出4个特征图,形成一个深度为4的输出。
所以在卷积运算这一步,需要设置或者说调试的参数有这几个:卷积核的长度、宽度、数量、卷积运算步长、零填充的圈数。
此时卷积核的维度就是这样的:

图23. 卷积核维度,需要注意,每个卷积核矩阵中的数值应该都是不同的,这里仅作为示意。
- 1.3 卷积运算输出(特征图):由于每个卷积核都会对应一张特征图的输出,所以4个卷积核就对应着4张特征图。而特征图的边长的计算方法在上文讲到过,综合了输入数据的边长、步长、卷积核大小、零填充情况等等,可以计算出特征图的边长。
我们设置步长S为3,不进行零填充即P=0,输入数据的边长为M=28,卷积核边长K=5,则:
L=(M−K+2P)/S+1=(28−5+2∗0)/3+1=8 (注意,此处除法向下取整)
所以此时特征图维度如下:
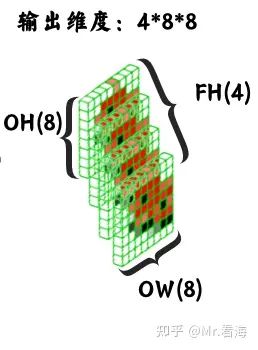
图24. 输出特征图维度,需注意,在实际计算中四张特征图应该是不同的
- 1.4 ReLU非线性激活:ReLU的计算不影响特征图尺寸,仅对特征图数值进行调整计算,此时特征图维度如下:

图25. ReLU非线性激活的输出维度,相对于上一层级未发生变化
- 1.5 池化层输出:池化层的会影响特征图尺寸,但不会影响特征图数量,尺寸的变化也很容易计算,下图是在经过2*2的最大池化窗口后的计算结果,特征图的边长变为:8/2=4。
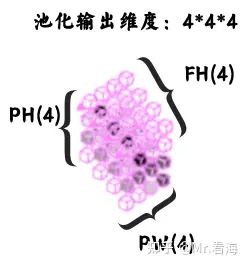
图26. 池化层输出结果,数据量得到进一步缩减
将上述过程完整连接起来,可以表示为下图:

图27. 完整的输入层→卷积层→ReLU→池化层
2.由基础模块搭建摩天大楼
上述图27展示的是一层卷积层的典型结构,在实际应用中,CNN往往是由多个卷积层构成,后续再缀接卷积层,则就是将上一层的输出作为后续的输入,然后重复“输入层→卷积层→ReLU→池化层”这个过程,当然池化层是非必须的。
此时卷积网络整体结构可以这样表示:
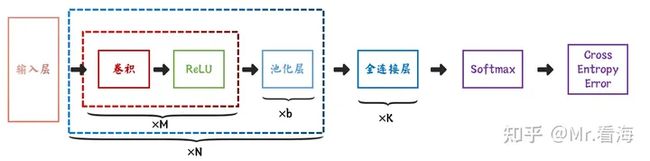
图28. 常用卷积网络整体结构通用表达方式,参考《神经网络与深度学习》
一个卷积块为连续M个卷积层和b个汇聚层,一个卷积网络中可以堆叠N个连续卷积块,然后在后面接着K个全连接层、Softmax以及交叉熵损失。
在上边图27的基础上,我们尝试再添加一个卷积层(这个不添加池化层了),此时就相当于将图27中的池化层输出的特征图(维度4*4*4)作为了输入,然后进行卷积和非线性激活操作,网络结构如下图:

图29. 输入层→卷积层→ReLU→池化层→卷积层→ReLU
为了方便大家观看,我将此图纵向再贴一遍,手机党可以横屏查看:

图30. 横版大图
3.连接输出层实现最终功能
由于上边的图片太长了,在输出层这部分,我们从最后一部分ReLU输出开始画起。
- 3.1 展平。展平是从卷积层到全连接层的一个必要步骤。卷积层的输出是一个三维张量,具有宽度、高度和深度(特征图的数量)。然而,全连接层期望的是一个一维向量的输入。因此,我们需要将这个三维张量“展平”成一个一维向量。
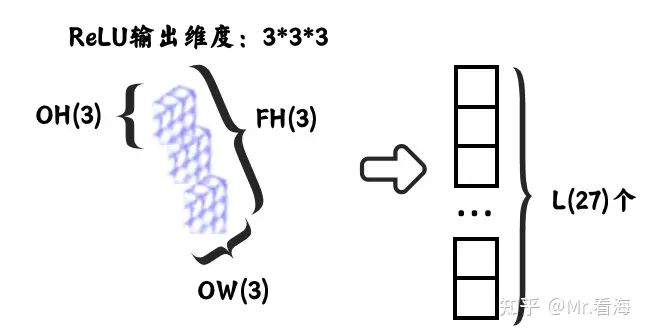
图31. 三维张量的“展开”过程
- 3.2 全连接层。全连接层的每一个节点都与前一层的所有节点相连。它的任务是学习卷积层和池化层提取出来的高级特征之间的非线性关系。全连接层通常用来执行分类任务,需注意全连接的输出维度和分类类别数是相同的。因为手写字体共有10种数字,所以类别就是10。

图32. 全连接层
- 3.3 Softmax。Softmax可以将一个实数向量转换成一个概率分布。换句话说,Softmax 函数会输出每个分类的概率,这些概率之和为1。在输出层使用Softmax激活函数是分类任务中的常见做法,因为它可以直观地给出每个类别的预测概率。

图33. Softmax层
- 3.4 交叉熵损失。在训练神经网络的过程中,我们需要一个指标来衡量模型的性能,这就是损失函数的作用。对于分类问题,常用的损失函数是交叉熵损失。交叉熵损失可以衡量预测的概率分布与真实分布之间的差异。
将上述各层串联起来,就是完整的输出层网络结构,即下图:

图34. 输出层网络结构
至此CNN神经网络的正向传播过程就讲完了,上述例子完整的结构如下图:

图35. 输入层→卷积层→ReLU→池化层→卷积层→ReLU→展平→全连接→Softmax→交叉熵损失
七、参数更新与迭代
关于反向传播,我就化用之前文章的表述了:
上边的1~6节,讲述了CNN神经网络的正向传播过程。一句话复习一下: CNN的正向传播过程是从输入层开始,通过一系列的卷积层、激活函数、池化层,然后通过全连接层,最后经过softmax激活函数进行分类,并通过交叉熵损失来量化当前网络的优劣。
算出交叉熵损失后,就要开始反向传播了。其实反向传播就是一个 参数优化的过程,优化对象就是网络中的所有 卷积核(其实还有偏置参数,相当于前馈神经网络里的b,本文不展开说了)。
神经网络的神奇之处,就在于它可以自动做参数的优化。
这里举一个形象的例子描述一下这个参数优化的原理和过程:
假设我们操纵着一个球型机器行走在沙漠中

我们在机器中操纵着旋钮矩阵,分别就是对应卷积核中的各个参数。当我们旋转其中的某个旋钮时,球形机器会发生移动,但是旋转旋钮大小和机器运动方向之间的对应关系是不知道的。而我们的目的就是 走到沙漠的最低点。
此时我们该怎么办?只能挨个试喽。
如果增大旋钮1后,球向上走了,那就减小旋钮1。
如果增大旋钮2后,球向下走了,那就继续增大旋钮2。
如果增大旋钮3后,球向下走了一大截,那就多增大些旋钮3。
。。。
这就是进行参数优化的形象解释(有没有想到求导?),这个方法叫做梯度下降法。
当我们的球形机器走到最低点时,也就代表着我们的交叉熵损失达到最小(接近于0)。
当通过上述方式反复迭代之后,我们就得到 一个训练好的CNN模型,他的本质就是一整套网络结构参数。
此时如果导入任意一组手写图片,利用图35的流程,就能得到分类结果啦。
结语
CNN的基本原理至此讲完了。这篇文章前前后后花了大概半个月的时间,其中尽可能多用图解,以希望读到这篇文章的同学们能真的看懂弄通。
后边我还会针对CNN进行一些补充讲解,例如:
- 常见的卷积神经网络结构
- CNN在MATLAB和Python中的快速实现
- CNN工程应用实例
- 常见问题答疑汇编等等
“一站式”让大家搞懂并且用上CNN。
撰写不易,感觉文章有用的同学们,请在收藏的同时点个赞吧!