【How to Design Translation Prompts for ChatGPT: An Empirical Study 论文略读】
How to Design Translation Prompts for ChatGPT: An Empirical Study 论文略读
- INFORMATION
- Abstract
- 1 Introduction
- 2 Background
- 3 Experiments
-
- 3.1 Prompt Design
- 3.2 Experimental Setup
-
- 3.2.1 Datasets
- 3.2.2 Baselines and Evaluation Metrics
- 3.3 Multilingual Translation
- 3.4 POS tags for ChatGPT
- 3.5 Translation Diversity
- 3.6 Multi-domain Translation
- 3.7 Few-shot Prompts
- 4 Conclusion and Further work
- Acknowledgements
INFORMATION
标题: How to Design Translation Prompts for ChatGPT: An Empirical Study
时间: 2023/04/21 预印版
作者: Yuan Gao , Ruili Wang , Feng Hou
单位: School of Mathematical and Computational Science Massey University, New Zealand
链接: https://arxiv.org/pdf/2304.02182.pdf
Abstract
最近发布的ChatGPT在自然语言理解和生成方面展示了惊人的能力。鉴于机器翻译在很大程度上依赖于这些能力,将ChatGPT应用于机器翻译具有很大的前景。使用简单提示不能完全释放ChatGPT的翻译能力。因此,在本文中,我们提出了几个包含翻译任务信息(如英语到德语),(ii)上下文域信息(如新闻),(iii)词性标签的翻译提示,旨在进一步释放ChatGPT的翻译能力。 实验结果表明,本文提出的翻译提示能够显著提高ChatGPT的翻译性能。我们使用多引用测试集来评估翻译质量,该测试集由每个源句子的10种不同的人工翻译组成,与商业系统相比,ChatGPT获得了更好的性能。此外,我们还根据我们提出的翻译提示开发了一些简短提示,这些提示在不同的翻译方向上不断显示出改进。
1 Introduction
机器翻译(MT)的目标是在计算机的帮助下,将文本从一种语言自动翻译成另一种目标语言。作为人工智能的一个重要研究领域,机器翻译已经引起了学术界和工业界的广泛关注(Stahlberg, 2020;Yang等人,2020)。近年来,将大规模的预训练语言模型纳入自然语言处理的趋势越来越大(Yang et al., 2019;Brown等人,2020年)。这些模型通常针对大量文本数据进行训练,并能够捕获输入文本的丰富表示形式。整合大型语言模型已经在各种自然语言处理任务中显示出了巨大的进步,包括机器翻译(Lewis等人,2020年)。
最近发布的ChatGPT1是OpenAI开发的一个强大的预训练语言模型。ChatGPT建立在GPT-3.5的基础上,并通过人类反馈的强化学习(RLHF)进行优化。由于其惊人的自然语言理解和生成能力,ChatGPT吸引了数百万用户。虽然ChatGPT主要被设计成一个智能对话系统,但它也可以执行大量类似人类的任务(例如,写诗、修复代码错误等)。然而,最近的研究(Jiao et al., 2023)显示,与其他商业翻译系统(如谷歌Translate和DeepL Translate)相比,带有简单提示符的ChatGPT表现出不可忽视的性能差距。
©2023作者。本文在Creative Commons 4.0许可下,没有衍生作品,署名,CCBY-ND
1https://openai.com/blog/chatgpt/
与其他商业翻译系统不同的是,ChatGPT能够根据提供的提示调整输出偏倚。因此,用户可以在ChatGPT的对话框中输入各种翻译提示,而不是只向ChatGPT请求翻译。由于OpenAI只提供了一个web接口来访问ChatGPT,我们不能修改内部组件或检索ChatGPT的中间表示。因此,我们将ChatGPT作为一个黑盒系统,探索什么样的翻译提示才能充分释放ChatGPT的翻译能力。我们假设,提供翻译任务或上下文域信息可以使ChatGPT聚焦于当前输入数据,从而提高翻译质量。此外,我们还尝试在提示中引入词性(POS)标记作为辅助信息来辅助ChatGPT。
在本研究中,我们提出了几个包含翻译任务信息(如英语到德语)、上下文域信息(如新闻)、词性标签(POS)的翻译提示,旨在进一步释放ChatGPT的翻译能力。我们进行了全面的实验来评估我们提出的翻译提示对提高ChatGPT翻译性能的效果。实验结果表明,使用我们的翻译提示的ChatGPT在多语言翻译中显著优于我们的基线提示。我们在多引用和多域场景下评估ChatGPT。我们观察到,使用多引用测试集对每个源句子进行10种不同的人工翻译时,翻译性能有了显著的改善,甚至超过了商业翻译系统。在多领域翻译的情况下,我们通过四个不同的领域测试集进行实验,分析了性能。我们观察到,当使用包含领域信息的翻译提示时,ChatGPT表现良好,并且始终比其他提示获得更高的BLEU分数。此外,我们向ChatGPT提供错误的域信息,以验证它是否能够正确理解域信息。实验结果表明,ChatGPT能够理解所提供的域信息,并相应地调整生成的翻译。
最后,根据我们提出的翻译提示,我们开发了少镜头提示。这种方法的动机是先前的研究利用大规模语言模型(LLMs),通过提供几个输入-输出例子来增强下游任务(Brown et al., 2020;Chen等人,2021年;窦等,2022)。为了减轻ChatGPT上任何意想不到的影响,我们有选择地从同一个数据集采样多个高质量的翻译对作为示例。 请注意,所选的示例和测试示例是相互排斥的,以确保可靠和无偏的评价。
2 Background
机器翻译(MT) 是自然语言处理领域的一个重要研究领域,近年来受到了广泛的关注。机器翻译的主要目标是在计算机的帮助下将文本数据从源语言自动转换为目标语言。因此,一个成熟的翻译系统必须具备强大的语言理解能力和语言生成能力,才能产生足够流利的翻译。前期工作(Liu et al., 2019;Guo et al., 2020)的研究表明,llm可以增强翻译系统理解源文本的能力,但难以提高生成能力。ChatGPT在自然语言理解和自然语言生成方面都表现出了令人印象深刻的性能,它在广泛的环境中理解和生成类人反应的能力证明了这一点。因此,探讨ChatGPT在翻译中的应用是一个很有吸引力和前景的研究领域。
ChatGPT 是一个大规模的语言模型,在GPT-3.5基础上进行了微调。正如官方网站所述,ChatGPT使用RLHF进行了优化,并对大量文本数据进行了训练,以根据提示中提供的说明生成详细的响应。虽然ChatGPT主要被设计成一个智能对话系统,但它能够执行各种类似人类的任务,包括机器翻译。然而,最近的研究(Jiao et al., 2023)发现,与其他商业翻译系统(如谷歌Translate和DeepL Translate)相比,ChatGPT表现出不可否认的性能差距,而且这种差距在低资源语言中更严重。因此,我们将探索如何通过设计不同的翻译提示来释放ChatGPT的翻译能力。
基于ChatGPT的培训目标是使用提示来指导回复的生成,我们认为适当的翻译提示可以释放更多的ChatGPT翻译潜力。在本工作中,我们采用了几个翻译提示来触发ChatGPT进行翻译,并在综合实验中对其进行评价。
3 Experiments
在本节中,我们首先描述我们设计的翻译提示,并提供关于实验设置的详细信息,包括使用的数据集、基线和评估指标。我们还进行了不同的实验,以探讨提出的提示语在不同翻译任务下的有效性。并给出了实验结果和分析。
3.1 Prompt Design
ChatGPT经过训练,根据提供的提示生成相应的响应。这种性质决定了它对提示符提供的信息非常敏感。Jiao(2023)使用了由ChatGPT本身提供的三种不同的提示符,它们显示了类似的翻译性能。提示信息如下:

我们认为,翻译结果不太可能受到这三个提示符的显著影响,因为它们只是提供了ChatGPT建议的一般性说明,没有任何补充信息。值得注意的是,ChatGPT是在大量多语言通用域数据集上进行训练的,因此,生成的文本不可避免地受到各种先验知识的影响,而不是仅仅基于当前的输入。因此,我们认为指定翻译任务或上下文域可以使ChatGPT更关注当前输入的文本,从而得到更好的翻译。基于此,我们从两个角度提出了TT和CD两种翻译提示,并将其与(Jiao et al., 2023)(参考TP3)中最有效的提示进行比较。此外,我们将POS标签作为辅助信息整合到TT和CD中,分别命名为TT- POS和CD- POS。本工作中采用的所有翻译提示如表1所示。

表1:本文采用的翻译提示。TT表示翻译任务,CD表示上下文域,“-pos”表示提示符中包含POS标签。TP3是直接从Jiao(2023)中提取的,没有任何版本,其他提示是基于TP3构建的。
3.2 Experimental Setup
3.2.1 Datasets
我们在一系列的基准上进行实验,包括多语言翻译、多引用翻译和多域翻译。在多语言场景下,我们选择英语↔西班牙语和英语↔法语,其翻译质量好,如图1所示,并进一步进行西班牙↔法语翻译,以评价非英语场景下的ChatGPT↔法语。我们使用Flores-101数据集(Goyal等人,2022年)对上述所有翻译方向,其中包含了每种语言的1012个来自维基百科文章的句子。由于ChatGPT生成的文本比传统的翻译系统更加灵活和多样化,因此用单一的参考来评估ChatGPT的实际性能是具有挑战性的。因此,我们采用多引用测试集来评估ChatGPT的翻译质量,该测试集为每个源句收集10个不同的人工翻译,数据由(Ott et al., 2018)发布。

图1:ChatGPT回答的最佳翻译
由于可用计算资源导致的响应延迟,使用ChatGPT进行翻译可能是一个耗时且劳力密集的过程。因此,我们遵循(Jiao et al., 2023)中提出的策略,从每个测试集中随机抽取50对句子对作为我们最终的测试集。
3.2.2 Baselines and Evaluation Metrics
为了评估我们提出的提示的有效性,我们将其与TP3进行比较,TP3作为一个基线,不提供关于输入文本的补充信息。此外,由于ChatGPT是一个完善的预训练系统,我们补充我们的研究,通过比较两种主流商业翻译系统,谷歌翻译和DeepL翻译在不同提示下的表现,而不是从头开始训练的学术翻译系统。我们通过公开发布的web interface2访问ChatGPT,同样的方式访问谷歌翻译和DeepL翻译。为了保证结果的可靠性,我们取三个随机抽样测试集的平均分数,以保证我们的评价结果不受随机性的影响。此外,我们使用多个指标评估我们的系统的性能,包括BLEU (Papineni等人,2002年),ChrF++ (Popovi´c, 2017年)和TER (Snover等人,2006年)。在这项工作中,我们使用SacreBLEU报告BLEU分数(Post, 2018)。
3.3 Multilingual Translation
我们对英语(En)、法语(Fr)和西班牙语(Es)这三种高资源语言进行了完整的多语种翻译,这三种语言都使用拉丁语,属于欧洲语系(英语属于日耳曼语系,法语和西班牙语属于罗曼语系(Fan et al., 2021))。结果见表2。可以看出,使用TP3的ChatGPT的性能普遍落后于谷歌Translate或DeepL Translate,但在某些翻译方向上仍具有竞争力,这与Jiao et al., 2023;彭等,2023)。具体来说,在西班牙语→英语翻译中,ChatGPT的BLEU得分比谷歌Translate高出+0.10。
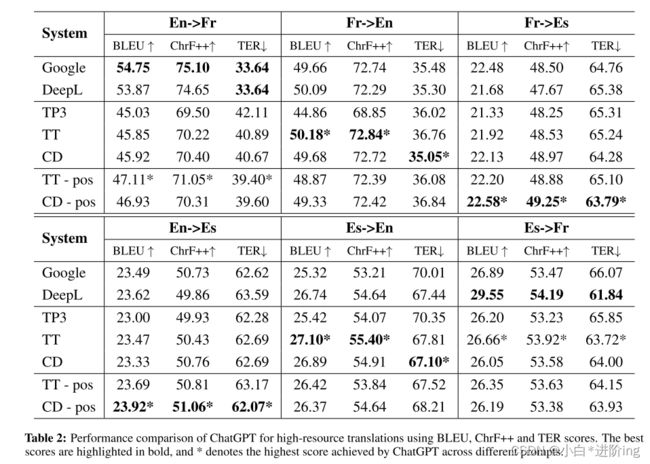
*表2:使用BLEU、ChrF++和TER评分对高资源翻译的ChatGPT性能比较。最好的分数以粗体突出显示,表示ChatGPT在不同提示中获得的最高分数。
与TP3的结果相比,我们的翻译提示在4个以英语为中心的译文上分别提高了0.89、5.32、0.47和1.68 BLEU分,证明了我们提示的有效性。令人惊讶的结果出现在X→英语翻译中,在法语→英语和西班牙语→英语翻译中,我们的提示明显超过TP3,甚至比商业系统的BLEU分数分别高出0.52和1.78。研究结果表明,ChatGPT在英语生成任务中具有巨大的潜力。对西班牙语↔法语的翻译来说,我们的提示相对于TP3的提高微乎其微,不像以英语为中心的任务有惊人的进步。
3.4 POS tags for ChatGPT
神经网络机器翻译已经被证明可以从额外提供的语言特征中获益,特别是对于不充分表示的语言。Petrushkov等人(2018)利用人工反馈来提高翻译的准确性和鲁棒性。Niu和Carpuat(2020)通过不同的方式采用目的语形式来提高翻译模型的性能。Li等人(2022)在提示中插入单词约束和语法约束,以提高翻译质量。此外,广泛的工作(Khan等人,2020年;Perera et al., 2022)对利用POS标签改进翻译进行了研究。POS标签提供了定位句子中每个单词的句法信息,以帮助消除单词的歧义并理解句子的语法结构。 例如,知道一个单词的POS标签可以帮助判断它在句子中是主语、宾语还是修饰语。 因此,我们推测,将POS标签作为辅助信息,可以进一步帮助ChatGPT在TT和CD上释放翻译能力。我们将POS标签序列直接与原句连接,并将两个序列的[句子]/[POS]标签前置,对其进行识别和分割。我们应用Stanza (Qi et al., 2020)为测试样本自动生成POS标签。
从表2的结果可以看出,加入POS标签可以在很多翻译方向上提高ChatGPT,如提高英语→法语+2.08 BLEU分,法语→西班牙语+1.25 BLEU分,英语→西班牙语+0.92 BLEU分。但在法语→英语、西班牙语→英语、西班牙语→法语等方面有所下降。我们怀疑性能下降是由于辅助信息通过引入噪声或增加输入文本的复杂性对原始输入产生负面影响而引起的。虽然没有明确说明加入POS标签的必要性,但毫无疑问,辅助信息在某种程度上对ChatGPT有积极的影响。此外,什么样的辅助信息以及如何进行整合仍然是未来研究的重要问题。
虽然带有POS标签的ChatGPT并没有得到持续的改进,但是它显示了完全理解输入内容的能力,能够区分两个序列,并且最终的输出只包含了【句子】部分的翻译。在这方面,ChatGPT表现出了非凡的熟练程度。
3.5 Translation Diversity
由于ChatGPT是对大量文本数据进行训练的,所以模型分布在假设空间中过于广泛。因此,该模型在词汇生成过程中具有更大的灵活性。此外,ChatGPT是一个专门定制的智能聊天机器人,并通过RLHF训练方案进行了优化,使其能够产生连贯和简洁的响应,以方便读者理解。然而,在没有干预的情况下,ChatGPT的这些属性导致了不确定性翻译,这种翻译是为了增强流利性和可理解性而故意生成的,但却与黄金引用不一致。
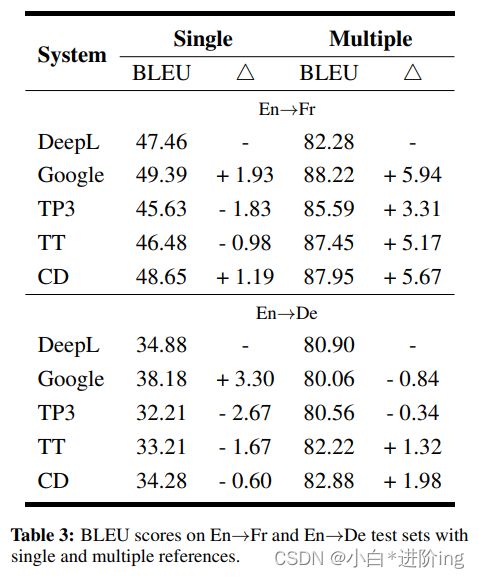
因此,我们遵循Ott等人(2018)的工作,使用多引用测试集来评估翻译质量,该测试集为每个源句子收集了10种不同的人工翻译。分别从WMT 2014英法英德新闻集中随机抽取两个多引用测试集的源句。实验结果如表3所示。与之前的实验结果类似,ChatGPT在单参考文献评估时仍然表现出竞争水平的性能(在En-Fr上的CD比DeepL高出1.19 BLEU),而在多参考文献评估时取得显著改善(在En-Fr上的CD比DeepL高出5.67 BLEU)。这些结果提供的经验证据表明,使用更全面的标准来评估ChatGPT的翻译性能是必要的。 此外,使用CD的ChatGPT在新闻集上的表现一贯优于其他提示,这与Flores-101之前的结果相反。为了进一步了解这一点,我们在下一节进行多领域翻译。
3.6 Multi-domain Translation
在FLORES(如表2所示)和WMT(如表3所示)测试集上使用TT和CD时,ChatGPT的翻译性能表现出不一致。具体来说,在FLORSE测试集上,ChatGPT和TT的性能比CD好,而在WMT测试集上,使用CD的性能比使用TT好。业绩方面的这种变化可能归因于评价数据的不同来源。FLORES数据集包含包含多个主题的维基百科文章(Goyal等人,2022年),应该被视为一个通用的域数据集。另一方面,表3中使用的数据来自特定的(News)域。为了研究带有CD的ChatGPT对特定领域的翻译是否有效,我们对来自(Hendy et al., 2023)的多领域测试集进行了实验,这些测试集涵盖了四个领域,即新闻、电子商务、社交和会话。
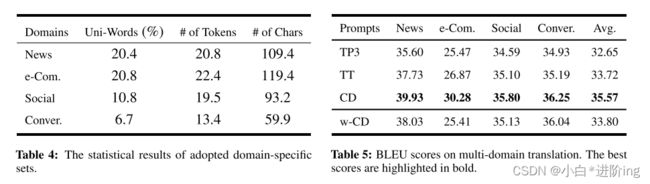
表4说明了从不同领域获得的数据集中观察到的统计模式的多样性。不同领域的数据在唯一词的比例、平均句子长度和平均单词长度上显示出明显的差异。特别地,会话域似乎是一个通用域,它只包含6.7%的在其他集合中不存在的唯一词。此外,与其他域集相比,平均句子长度和每个词的平均字符数明显较短,如表4所示。值得注意的是,我们在计算单词之前采用了小写和词元化,目的是消除形态变换对词汇重叠的影响,比例的计算是基于符号的总数,而不是单词在词汇中的数量。
如表5所示,CD配合ChatGPT在所有领域都表现出色,平均BLEU得分分别比TP3和TT高出+2.92和+1.85。同时,新闻和电子商务领域与社会和会话领域(分别比TP3表现出+1.21和+1.32)相比,具有更高独特词汇比例的新闻和电子商务领域实现了更大的改进(分别比TP3表现出+4.33和+4.81)。这表明,在从特定领域翻译数据时,域信息对ChatGPT是有利的。 然而,从BLEU分数得到的结果表明,翻译质量和领域唯一性之间缺乏明显的相关性。为了评估提供不正确的域信息的影响,我们进行了一个比较实验,使用错误的域信息来提示ChatGPT(称为w-CD)。实验结果表明,错误的域名信息对翻译质量有显著影响, 尤其是在新闻和电子商务领域。这与前面使用正确的域信息的观察结果一致,表明域信息显式地影响ChatGPT的翻译,特别是在具有更具体单词的域上。
3.7 Few-shot Prompts
最近的研究(Brown et al., 2020;Chen等人,2021年;Dou等人,2022)已经证明了上下文学习对于llm的优势。上下文学习包括向输入文本添加几个输入输出示例(按照提示执行),以增强llm跨多个任务的性能,而无需对参数或体系结构进行任何调整。Li和Liang(2021)提出了前缀调优方法,该方法使用一些带标签的数据,使一般llm能够通过针对下游数据集训练的专门向量实现具有竞争力的结果。受前缀调优的启发,Tsimpoukelli等人(2021)利用上下文学习来提高LLM在各种多模式任务上的性能。此外,还有一系列的研究集中在llm对MT的促进上(Vilar et al., 2022;张等,2023)。语境学习依赖于所选例子的质量和数量,之前的研究表明,提供更多高质量的例子会导致更大的下游任务改进(Yang et al., 2020;魏等,2022)。然而,例子的数量受到LLM体系结构的限制(Olmo et al., 2021),提供更多的例子并不会带来任何有意义的改进(Hendy et al., 2023)。
因此,在本节中,我们通过从原始测试集中选择1和5个示例(shots),并将它们与之前使用的提示(即TP3、TT、CD)集成,来进行少镜头提示的实验,如图2所示。请注意,所选的镜头与用于测试的数据不重叠。为了获取镜头的质量,我们使用LaBSE (Feng et al., 2022)对后面的翻译对(Hendy et al., 2023)进行评分,然后选择top-1和top-5对作为上下文镜头。在少镜头提示的情况下,我们进行了法语→英语和西班牙语→英语的实验,结果如图3、4所示。我们比较了三种少发设置的性能,分别是0发、1发和5发。

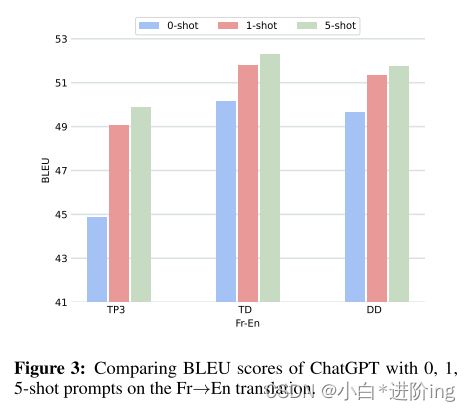
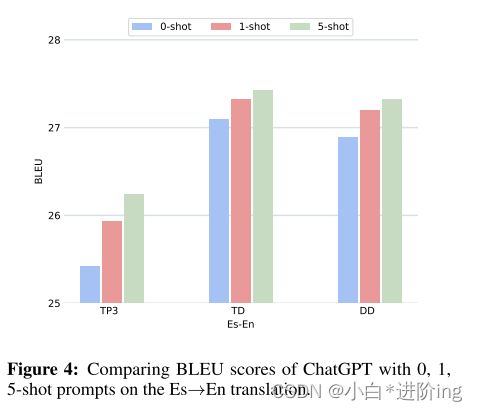
根据观察,对于TP3、TT和CD,使用1shot和5 shot设置的ChatGPT在性能上比0 shot有实质性的改善。 然而,值得注意的是,当应用于基本TP3时,少shot提示产生的收益最大,这一现象在法语→英语和西班牙语→英语翻译中是一致的。换句话说,将少镜头学习与设计好的提示相结合,并不一定会带来同等的附加改进。我们推测,上下文截图中包含的信息与设计的提示提供的信息之间存在一些重叠。另一方面,持续改进。
4 Conclusion and Further work
在这项工作中,我们提出了一个实证研究如何释放ChatGPT的翻译能力,通过使用不同的翻译提示进行机器翻译。具体来说,我们在各种翻译设置中评估和分析我们提出的提示,包括多语言、多引用、多领域和少镜头翻译。
我们的研究结果表明,ChatGPT通过使用适当设计的提示,能够比商业翻译系统获得更好的结果。此外,我们将POS标签纳入TT和CD作为辅助信息,但观察到的部分翻译方向的不稳定性表明,该策略需要进一步研究,以充分了解其局限性和潜力。
考虑到ChatGPT是专门为对话而训练的,并且在生成句子时优先考虑连贯和简洁,这可能不足以评估单一参考的翻译质量。我们使用多引用测试集来评估ChatGPT的性能。这使我们能够考虑到可能翻译的多样性。实验结果表明,使用多参考文献评估ChatGPT的翻译性能与使用单一参考文献评估ChatGPT的翻译性能有显著差异。这凸显了使用更全面的评估标准来评估ChatGPT翻译质量的重要性。
为了进一步研究CD对ChatGPT的影响,我们对多域测试集进行了实验。实验结果表明,在提示符中引入正确的域信息可以有效地提高ChatGPT的翻译性能。此外,我们使用了少镜头提示来提示ChatGPT,这可以在不同的翻译方向上实现实质性的改进。
总之,我们发现在提示符中为ChatGPT提供有关输入文本的正确信息(例如翻译任务和上下文域)可以进一步释放ChatGPT的性能,但是,当信息过于复杂或噪声过大时,就会产生严重的性能下降。此外,使用少镜头示例是一种需要认真考虑的方法,因为输入-输出示例包含许多无法通过特定文本显式传递的隐藏信息。
Acknowledgements
本研究得到了新西兰商业、创新和就业部(MBIE) 2020年Catalyst: Strategic New Zealand - Singapore Data Science Research Programme基金的支持。