《Reinforcement Learning: An Introduction》第5章笔记
Chapter 5 Monte Carlo Methods
Monte Carlo 方法不假设拥有完备的环境知识,它仅仅需要经验–从与环境的实际或模拟交互中得到的一系列的状态、动作、和奖励的样本序列。
Monte Carlo方法是基于平均采样回报的来解决强化学习问题的方法。
5.1 Monte Carlo Prediction
Monte Carlo 方法的基本思想:一个状态的价值是它的期望回报,也就是从那个状态开始能得到的期望的未来累积折扣奖励。因此一种简单的实现方法是将从访问到状态开始观察到的回报平均化。随着越来越多的回报被观察到,这个平均值肯定会收敛到期望值。
假设我们要估计在策略 π \pi π下的状态s的价值 v π ( s ) v_{\pi}(s) vπ(s),并且给定一个遵循策略 π \pi π并且经过状态s的episodes集合。 将一个episode中状态s的每一次出现称为对s的一次访问(visit)。可想而知,在同一个episode里,状态s可能会被访问多次,我们将一个episode里状态s第一次被访问称为s的首次访问(first visit to s)。
-
首次访问MC方法(The first-visit MC method)将首次访问后的平均回报作为 v π ( s ) v_{\pi}(s) vπ(s)的估计。
-
每次访问MC方法(every-visit MC method)将其估计为所有访问 s 之后的平均回报。
-
首次访问MC方法和每次访问MC方法非常相似但有些许不同的理论性质。 当s的访问次数趋于无穷时,两者都可以收敛到 v π ( s ) v_{\pi}(s) vπ(s)。
下图是首次访问MC方法的流程图,每次访问MC方法除了去检查 S t S_t St是否已经出现过之外,是一样的。

【Example 5.1: Blackjack】 是一个用MC方法的例子。
Monte Carlo算法能用回溯图表示吗?当然可以,对于Monte Carlo 的估计值 v π v_{\pi} vπ, 状态节点是根节点,而它下面的是一个特定的单个序列的整个转移轨迹(以终止状态结束),如下图所示。

Monte Carlo 方法不是自举(bootstrap)的,它对于每个状态的估计是独立的。因为这个特点,当只想知道一个状态或一小部分状态的价值时,Monte Carlo方法就特别有吸引力;此时只需要从这些感兴趣的状态出发生成很多样本序列,并只对这些状态进行平均回报的计算。(这是Monte Carlo 方法的第三个优点,可以从实际经验学习,也可以从模拟经验学习是另外两个优点)
5.2 Monte Carlo Estimation of Action values
Monte Carlo 方法的最优目标之一是估计 q ∗ q_* q∗,为了实现它,考虑对动作价值的策略评估问题。
对动作价值的策略评估问题是估计 q π ( s , a ) q_{\pi}(s, a) qπ(s,a), 即遵循策略 π \pi π,从状态s出发,采取动作a的期望回报。 Marlo Carlo方法估计动作价值的方法与上一节估计状态价值时是一样的。如果在状态s被访问,并且采取了动作a时,称状态-价值对在一个序列中被访问:
- 每次访问MC(every-visit MC)方法将所有动作-价值对得到的回报的平均值作为动作价值函数的近似。
- 首次访问MC(first-visit MC)方法将每个序列中第一次在这个状态下采取这个动作得到的回报的平均值作为动作价值函数的近似。
此时我们面临的唯一复杂情况是许多状态-价值对可能从来没有被访问过。当 π \pi π是一个确定性策略,那么遵循 π \pi π意味着在每个状态只会观测到一个状态的回报。当无法获取回报进行平均时,Monte Carlo将无法根据经验来改善其他动作的估计。所以与第2章讨论过k臂赌博机问题一样,这是如何保持探索(maintaining exploration)的普遍问题。解决这个问题的一个方法是:
exploring starts:使序列从一个指定的状态-价值对开始,同时保证所有状态-价值对都有一个非零概率被选择成起点。这个方法保证了,在采样序列的数目趋向无穷时,所有状态-价值对都会被访问无数次。
5.3 Monte Carlo Control
在第4章 提到过广义策略迭代GPI(generalized policy iteration,GPI),GPI同时维护一个近似的策略和近似的价值函数。价值函数不断迭代使其更精确地近似对应当前策略的价值函数,而策略也根据当前的价值函数不断调优,就如下图显示的那样,这两个过程最终会使策略和价值函数趋向最优解。
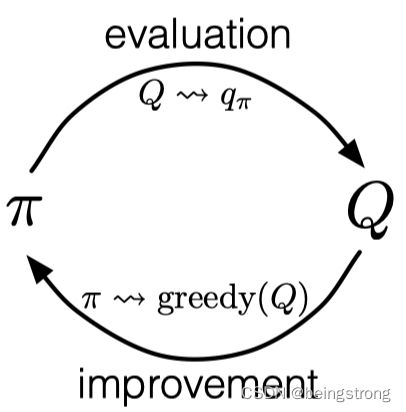
经典策略迭代的Monte Carlo 版本,从任意策略 π 0 \pi_0 π0开始,交替完成策略迭代和策略提升,以最优策略和动作价值函数作为终止:
π 0 ⟶ E q π 0 ⟶ I π 1 ⟶ E q π 1 ⟶ I π 2 ⟶ E ⋯ ⟶ I π ∗ ⟶ E q ∗ \pi_0 \stackrel{E}{\longrightarrow} q_{\pi0} \stackrel{I}{\longrightarrow} \pi_1 \stackrel{E}{\longrightarrow} q_{\pi1} \stackrel{I}{\longrightarrow} \pi_2 \stackrel{E}{\longrightarrow} \cdots \stackrel{I}{\longrightarrow} \pi_* \stackrel{E}{\longrightarrow} q_* π0⟶Eqπ0⟶Iπ1⟶Eqπ1⟶Iπ2⟶E⋯⟶Iπ∗⟶Eq∗
上式中的 ⟶ E \stackrel{E}{\longrightarrow} ⟶E是策略评估, ⟶ I \stackrel{I}{\longrightarrow} ⟶I是策略提升。策略评估可以按照5.2节所述执行。如果基于两个假设:1. 序列是由探索性出发(exploring start)生成的;2. 进行策略评估时可以在无限多的序列中进行探索。Monte Carlo方法可以对任意 π k \pi_k πk 精确的计算对应的 q π k q_{\pi_k} qπk。
策略提升方法是在当前价值函数上贪心地选择动作。对于任意的动作价值函数q,对应的贪心策略为:对于任意的 s ∈ S s \in \mathcal{S} s∈S,一定选择具有最大动作价值的动作:
π ( s ) = ˙ a r g m a x a q ( s , a ) ( 5.1 ) \pi(s) \dot{=} \mathop{argmax}\limits_a \ q(s, a) \qquad (5.1) π(s)=˙aargmax q(s,a)(5.1)
策略提升能够通过将 q π k q_{\pi_k} qπk的贪心策略作为 π k + 1 \pi_{k+1} πk+1 来实现,这样的 π k \pi_k πk和 π k + 1 \pi_{k+1} πk+1满足4.2节的策略提升定理,对于所有状态 s ∈ S s \in \mathcal{S} s∈S:
q π k ( s , π k + 1 ( s ) ) = q π k ( s , a r g m a x a q π k ( s , a ) ) = max a q π k ( s , a ) ≥ q π k ( s , π k ( s ) ) ≥ v π k ( s ) \begin{aligned} q_{\pi_k}(s, \pi_{k+1}(s)) &\ = \ q_{\pi_k}(s, \mathop{argmax}\limits_a\ q_{\pi_k}(s, a)) \\ &\ = \ \max\limits_a q_{\pi_k}(s, a) \\ &\ \ge \ q_{\pi_k}(s, \pi_k(s)) \\ &\ \ge \ v_{\pi_k}(s) \end{aligned} qπk(s,πk+1(s)) = qπk(s,aargmax qπk(s,a)) = amaxqπk(s,a) ≥ qπk(s,πk(s)) ≥ vπk(s)
在之前章节学到过,这个定理保证了 π k + 1 \pi_{k+1} πk+1 一定比 π k \pi_k πk更优,除非 π k \pi_{k} πk已经是最优策略,这样两者都是最优策略。所以在只能得到若干个回合采样序列而不知道环境动态知识时, Marte Carlo方法就可以用来寻找最优策略。
前面我们提到作了两个假设来保证Marte Carlo方法的收敛,但是为了得到一个实际可用的算法,我们必须去除这两个假设,我们先考虑如何去掉第一个假设。
去掉第一个假设,即策略评估时可以在无限多的序列中进行探索,有两种方法(DP和Monte Carlo方法都适用):
- 在每次策略评估中对 q π k q_{\pi_k} qπk做出尽量好的逼近。这要求做一些假设并定义一些测度,来获取逼近误差的幅度和出现概率的上下界,然后采取足够多的步数来保证这些边界足够小。这个方法可以保证收敛到令人满意的近似水平,但是在实际使用中,即使问题足够小,也可能需要太多的序列用于计算。
- 不再要求在策略改进之前就完成策略评估。在每一个评估步骤中,我们让动作价值函数逼近 q π k q_{\pi_k} qπk,但我们并不期望它在经过很多步之前非常接近真实的值。 在第4章中的价值迭代就是一种极端实现方式。
在每一个序列结束后,使用观测到的回报进行策略评估,并在该序列访问到的每一个状态上进行策略的改进,基于这个思路的算法,被称为Monte Carlo ES(Monte Carto with Exploring Starts),伪代码如下图:

5.4 Monte Carlo Control without Exploring Starts
如何避免很难被满足的探索性出发假设呢?唯一的一般性方法是保证agent能够持续地选择所有动作,有两种方法可以保证这一点,被称为在线策略(on-policy)方法和离线策略(off-policy)方法:
- 在线策略方法尝试评估和提升用来决策的策略。也就是用于生成采样数据序列的策略和用于实际决策的待评估和改进的策略是相同的。前文的Monte Carlo ES 方法是一个在线策略的例子。
- 离线策略方法评估和提升的策略不同于用来生成数据的策略。
本节讨论在线Monte Carlo 方法如何用来去除不实际的探索性出发假设。
在线策略控制方法的策略通常是soft的,也就是说对于对于所有 s ∈ S s \in \mathcal{S} s∈S和 a ∈ A ( s ) a \in \mathcal{A}(s) a∈A(s),有 π ( a ∣ s ) > 0 \pi(a | s) >0 π(a∣s)>0,但它们会逐渐逼近到一个确定性策略。在线策略算法使用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略,在大多数时候选择具有最大预估动作价值的动作,以一个小的概率 ϵ \epsilon ϵ 来从所有动作中等概率的随机选择一个动作。也就意味着所有非贪心动作有一个最小概率 ϵ ∣ A ( s ) ∣ \frac{\epsilon}{|\mathcal{A}(s)|} ∣A(s)∣ϵ被选中,而贪心动作有概率 1 − ϵ + ϵ ∣ A ( s ) ∣ 1- \epsilon + \frac{\epsilon}{|\mathcal{A}(s)|} 1−ϵ+∣A(s)∣ϵ。 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略是 ϵ − s o f t \epsilon-soft ϵ−soft策略的一个例子,即对某个 ϵ > 0 \epsilon > 0 ϵ>0,对于所有状态和动作满足 π ( a ∣ s ) ≥ ϵ ∣ A ( s ) ∣ \pi(a|s) \ge \frac{\epsilon}{|\mathcal{A}(s)|} π(a∣s)≥∣A(s)∣ϵ。
在线策略的首次访问MC控制算法的伪代码如下图,对于任意的 ϵ − s o f t \epsilon-soft ϵ−soft策略 π \pi π,根据 q π q_{\pi} qπ生成的任意一个 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略保证优于或等于 π \pi π。

根据策略提升定理,对于任意 ϵ − s o f t \epsilon-soft ϵ−soft策略 π \pi π,任意根据 q π q_{\pi} qπ生成的 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略都是对其的提升。假设 π ′ \pi^{\prime} π′是一个 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略, 策略提升定理的条件成立,因为对于任意的状态 s ∈ S s \in \mathcal{S} s∈S:
q π ( s , π ′ ( s ) ) = ∑ a π ′ ( a ∣ s ) q π ( s , a ) = ϵ ∣ A ( s ) ∣ ∑ a q π ( s , a ) + ( 1 − ϵ ) max a q π ( s , a ) ( 5.2 ) ≥ ϵ ∣ A ( s ) ∣ ∑ a q π ( s , a ) + ( 1 − ϵ ) ∑ a π ( a ∣ s ) − ϵ ∣ A ( s ) ∣ ( 1 − ϵ ) q π ( s , a ) ( t h e s u m i s a w e i g h t e d a v e r a g e w i t h n o n n e g a t i v e w e i g h t s s u m m i n g t o 1 , a n d a s s u c h i t m u s t b e l e s s t h a n o r e q u a l t o t h e l a r g e s t n u m b e r a v e r a g e d ) = ϵ ∣ A ( s ) ∣ ∑ a q π ( s , a ) − ϵ ∣ A ( s ) ∣ ∑ a q π ( s , a ) + ∑ a π ( a ∣ s ) q π ( s , a ) = v π ( s ) \begin{aligned} q_{\pi}(s, \pi^{\prime}(s)) &\ = \sum_a \pi^{\prime}(a|s) q_{\pi}(s, a) \\ &\ = \ \frac{\epsilon}{|\mathcal{A}(s)|} \sum_a q_{\pi}(s, a) + (1- \epsilon)\max\limits_a q_{\pi}(s, a) \qquad (5.2) \\ &\ \ge \frac{\epsilon}{|\mathcal{A}(s)|} \sum_a q_{\pi}(s, a) + (1- \epsilon) \sum_a \frac{\pi(a|s) - \frac{\epsilon}{|\mathcal{A}(s)|}}{(1- \epsilon)} q_{\pi}(s, a) \\ &(the\ sum\ is\ a\ weighted\ average\ with\ nonnegative\ weights\ summing\ to\ 1,\ and\ as\ such\ it\ must\ be\ less\ than\ or\ equal\ to\ the\ largest\ number\ averaged) \\ & = \frac{\epsilon}{|\mathcal{A}(s)|} \sum_a q_{\pi}(s, a) - \frac{\epsilon}{|\mathcal{A}(s)|} \sum_a q_{\pi}(s, a) + \sum_a \pi(a|s) q_{\pi}(s, a)\\ &\ = \ v_{\pi}(s) \end{aligned} qπ(s,π′(s)) =a∑π′(a∣s)qπ(s,a) = ∣A(s)∣ϵa∑qπ(s,a)+(1−ϵ)amaxqπ(s,a)(5.2) ≥∣A(s)∣ϵa∑qπ(s,a)+(1−ϵ)a∑(1−ϵ)π(a∣s)−∣A(s)∣ϵqπ(s,a)(the sum is a weighted average with nonnegative weights summing to 1, and as such it must be less than or equal to the largest number averaged)=∣A(s)∣ϵa∑qπ(s,a)−∣A(s)∣ϵa∑qπ(s,a)+a∑π(a∣s)qπ(s,a) = vπ(s)
所以,通过策略提升定理,有 π ′ ≥ π \pi^{\prime} \ge \pi π′≥π,也就是对于所有状态 s ∈ S s \in \mathcal{S} s∈S,有 v π ′ ( s ) ≥ v π ( s ) v_{\pi^{\prime}}(s) \ge v_{\pi}(s) vπ′(s)≥vπ(s),而该式等号成立的条件是:当且仅当 π ′ \pi^{\prime} π′和 π \pi π都是最优的 ϵ − s o f t \epsilon-soft ϵ−soft策略,也就是它们比所有其他的 ϵ − s o f t \epsilon-soft ϵ−soft策略都更优或相同(证明略,见原书)。
5.5 Off-policy Prediction via Importance Sampling
所有的学习控制算法有一个困境:它们希望学习到的动作可以使随后的智能体行为是最优的,但是为了探索所有的动作,以保证找到最优动作,它们需要采取非最优的行动。那怎么解决这个困境呢? 离线策略(off-policy)的解决办法是使用两个策略,一个策略用来学习并成为最优策略,被称为目标策略(target policy);另一个策略做更多探索,用来产生智能体的行动样本,被称为行为策略(behavior policy)。这种情况下认为学习所用的数据“off"了目标策略,因此整个过程被称为离线策略学习。
在线策略和离线策略的对比:
- 在线策略通常更简单,且首先被考虑。
- 离线策略需要额外的概念和记号。并且因为其数据来自一个不同的策略,所以离线策略方法方差更大,收敛更慢。
- 但是离线策略更强大更通用,可以将在线策略看做是目标策略和行为策略是相同的离线策略方法的特例。
假设将目标策略记为 π \pi π, 行为策略记为 b b b,两个策略是已知且固定。
覆盖假设(assumption of coverage): 为了使用从 b b b得到的序列来估计 π \pi π,我们要求在 π \pi π下采取的每个动作都至少偶尔能在 b b b下发生,也就是说当 π ( a ∣ s ) > 0 \pi(a|s) >0 π(a∣s)>0时,要求 b ( a ∣ s ) > 0 b(a|s)>0 b(a∣s)>0。 在这个假设下,在与 π \pi π不同的状态下, b b b必须是随机的。而目标策略 π \pi π可能是确定的。
几乎所有的离线策略都使用重要性采样(importance sampling),一种给定来自其他分布的样本的条件下,来估计某种分布的期望值的通用技术。
重要度采样比(importance-sampling ratio):轨迹在目标策略和行为策略中出现的相对概率。离线策略学习将回报用重要度采样比来加权的方式来应用重要性采样。给定起始状态 S t S_t St,后续的状态-价值轨迹 A t , S t + 1 , A t + 1 , ⋯ , S T A_t, S_{t+1},A_{t+1},\cdots,S_T At,St+1,At+1,⋯,ST在策略 π \pi π下发生的概率是:
P r { A t , S t + 1 , A t + 1 , ⋯ , S T ∣ S t , A t : T − 1 ∼ π } = π ( A t ∣ S t ) p ( S t + 1 ∣ S t , A t ) π ( A t + 1 ∣ S t + 1 ) ⋯ p ( S T ∣ S T − 1 , A T − 1 ) = ∏ k = t T − 1 π ( A k ∣ S t ) p ( S k + 1 ∣ S k , A k ) \begin{aligned} &Pr\{A_t, S_{t+1}, A_{t+1}, \cdots, S_T|S_t, A_{t:T-1} \sim \pi \} \\ & = \pi(A_t|S_t)p(S_{t+1}|S_t,A_t) \pi(A_{t+1}|S_{t+1}) \cdots p(S_T|S_{T-1}, A_{T-1}) \\ & = \prod^{T-1}_{k=t} \pi(A_k|S_t) p(S_{k+1}|S_k, A_k) \end{aligned} Pr{At,St+1,At+1,⋯,ST∣St,At:T−1∼π}=π(At∣St)p(St+1∣St,At)π(At+1∣St+1)⋯p(ST∣ST−1,AT−1)=k=t∏T−1π(Ak∣St)p(Sk+1∣Sk,Ak)
式中的 p p p是第3章中的式(3.4)定义过的状态转移概率,因此在目标策略和行为策略下的轨迹的相对概率(重要度采样比)为:
ρ t : T − 1 = ˙ ∏ k = t T − 1 π ( A k ∣ S t ) p ( S k + 1 ∣ S k , A k ) ∏ k = t T − 1 b ( A k ∣ S t ) p ( S k + 1 ∣ S k , A k ) = ∏ k = t T − 1 π ( A k ∣ S t ) b ( A k ∣ S t ) ( 5.3 ) \rho_{t:T-1}\ \dot{=}\ \frac {\prod^{T-1}_{k=t} \pi(A_k|S_t) p(S_{k+1}|S_k, A_k)} {\prod^{T-1}_{k=t} b(A_k|S_t) p(S_{k+1}|S_k, A_k)} \ = \ \prod_{k=t}^{T-1} \frac {\pi(A_k|S_t)}{b(A_k|S_t)} \qquad (5.3) ρt:T−1 =˙ ∏k=tT−1b(Ak∣St)p(Sk+1∣Sk,Ak)∏k=tT−1π(Ak∣St)p(Sk+1∣Sk,Ak) = k=t∏T−1b(Ak∣St)π(Ak∣St)(5.3)
尽管整体轨迹的概率值依赖于MDP的状态转移概率,并且MDP的状态转移概率通常是不可知的,但是它们在分子和分母中是完全相同的,所以可被约分。重要度采样比最终仅依赖于两个策略及其数据,而不依赖于MDP。
我们希望估计目标策略下的期望回报(价值),但是我们只有从行为策略得到的回报 G t G_t Gt,这些从行为策略得到的回报有错误的期望 E [ G t ∣ S t = s ] = v b ( s ) \mathbb{E}[G_t|S_t=s]\ = \ v_b(s) E[Gt∣St=s] = vb(s),所以不能用它们的平均来得到 v π v_{\pi} vπ。解决方法是使用重要性采样,使用重要度采样比 ρ t : T − 1 \rho_{t:T-1} ρt:T−1可以调整回报使其有正确的期望值:
E [ ρ t : T − 1 G t ∣ S t = s ] = v π ( s ) ( 5.4 ) \mathbb{E}[\rho_{t:T-1}G_t|S_t=s] = v_{\pi}(s) \qquad (5.4) E[ρt:T−1Gt∣St=s]=vπ(s)(5.4)
介绍完基础概念后,终于到了本节算法出场的时候了,也就是平均化一批遵循策略 b b b的观测序列的回报来估计 v π ( s ) v_{\pi}(s) vπ(s)的Monte Carlo 算法。对于每次访问MC方法,定义所有访问过的状态s的时刻集合为 T ( s ) \mathcal{T}(s) T(s); 对于首次访问MC方法, T ( s ) \mathcal{T}(s) T(s)只包含在序列内首次访问状态s的时刻。用 T ( t ) T(t) T(t)表示时刻t后的首次终止, G t G_t Gt表示在t之后到达 T ( t ) T(t) T(t)的回报。则 { G t } t ∈ T ( s ) \{G_t\}_{t \in \mathcal{T}(s)} {Gt}t∈T(s)是状态s对应的回报值,而 { ρ t : T ( t ) − 1 } t ∈ T ( s ) \{\rho_{t:T(t)-1}\}_{t \in \mathcal{T}(s)} {ρt:T(t)−1}t∈T(s) 是对应的重要度采样比,为了估计 v π ( s ) v_{\pi}(s) vπ(s),有两种方法:
- 普通重要性采样(ordinary importance sampling): 根据重要度采样比来调整回报值并对结果进行平均:
V ( s ) = ˙ ∑ t ∈ T ( s ) ρ t : T ( t ) − 1 G t ∣ T ( s ) ∣ ( 5.5 ) V(s)\ \dot{=} \ \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t:T(t)-1} G_t }{|\mathcal{T}(s)|} \qquad (5.5) V(s) =˙ ∣T(s)∣∑t∈T(s)ρt:T(t)−1Gt(5.5) - 加权重要性采样(weighted importance sampling):根据重要度采样比来调整回报值并对结果进行加权平均,式中如果分母为零,则值也为零:
V ( s ) = ˙ ∑ t ∈ T ( s ) ρ t : T ( t ) − 1 G t ∑ t ∈ T ( s ) ρ t : T ( t ) − 1 ( 5.6 ) V(s)\ \dot{=} \ \frac{\sum_{t \in \mathcal{T}(s)} \rho_{t:T(t)-1} G_t }{\sum_{t \in \mathcal{T}(s)} \rho_{t:T(t)-1}} \qquad (5.6) V(s) =˙ ∑t∈T(s)ρt:T(t)−1∑t∈T(s)ρt:T(t)−1Gt(5.6)
那这两种重要度采样方法有什么区别呢?
- 对于首次访问MC方法,普通重要性采样是无偏的,加权重要性采样是有偏的
- 对于首次访问MC方法,普通重要性采样的方差一般是无界的,而如果假设回报有界,即使重要性采样比是无界的,加权重要性采样的方差也能收敛到零。
- 在实际应用中,加权重要性采样因为低方差被偏好使用,但是普通重要性采样因为更容易扩展到本书后面的函数逼近的近似方法也不会被放弃使用。
- 在每次访问MC方法中,两种重要性采样方法都是有偏的,但是随着样本数增加,偏差会逐渐趋近于0。
实际使用中,每次访问MC方法更常被使用,因为它不需要跟踪状态是否被访问过,并且更容易扩展到近似。使用加权重要性采样的用于off-policy的策略评估的完整版每次访问MC算法在下一节5.6节会学到。
5.6 Incremental Implementation
在第2章的2.4节学过的增量式实现可以直接应用到Monte Carlo方法,在那里是计算平均奖励,在Monte Carlo方法中我们计算平均回报。对于在线策略Monte Carlo方法可以直接使用已经学过的增量式实现方法,而对于离线策略Monte Carlo方法,需要分别讨论一下普通重要性采样和加权重要性采样。
普通重要性采样方法,可以直接使用第2章的增量式方法,只是将奖励替换成缩放后的回报就可以了。
加权重要性采样方法,因为需要对回报加权平均,就需要一个略微不同的增量式算法。
假设有一个回报序列 G 1 , G 2 , ⋯ , G n − 1 G_1, G_2, \cdots, G_{n-1} G1,G2,⋯,Gn−1,都从相同的状态开始,并且每一个回报都对应一个随机权重 W i W_i Wi(例如, W i = ρ t i : T ( t i ) − 1 ) W_i=\rho_{t_i:T(t_i)-1}) Wi=ρti:T(ti)−1)。希望得到如下估计,并且在获得了一个额外的回报值 G n G_n Gn时能保持更新:
V n = ˙ ∑ k = 1 n − 1 W k C k ∑ k = 1 n − 1 W k , n ≥ 2 ( 5.7 ) V_n \dot{=} \frac {\sum^{n-1}_{k=1} W_kC_k} {\sum^{n-1}_{k=1}W_k}, \quad n\ge 2 \ \qquad (5.7) Vn=˙∑k=1n−1Wk∑k=1n−1WkCk,n≥2 (5.7)
为了能不断跟踪 V n V_n Vn的变化,必须为每一个状态维护前n个回报对应的权值的累加值和 C n C_n Cn, V n V_n Vn的更新规则为:
V n + 1 = ˙ V n + W n C n [ G n − V n ] , n ≥ 1 ( 5.8 ) a n d C n + 1 = ˙ C n + W n + 1 , C 0 = ˙ 0 V_{n+1}\ \dot{=}\ V_n + \frac{W_n}{C_n}[G_n - V_n], \ n\ge1 \ \qquad (5.8) \\ and\ \ \ \ C_{n+1}\ \dot{=}\ C_n + W_{n+1},\ C_0\ \dot{=}\ 0 Vn+1 =˙ Vn+CnWn[Gn−Vn], n≥1 (5.8)and Cn+1 =˙ Cn+Wn+1, C0 =˙ 0
下图是一个完整的Monte Carlo 策略评估的增量式算法,虽然命名为离线策略场景,并使用加权重要性采样,但是可以适用于在线策略场景(通过使目标和行为策略一样,并且W总是为1)。

5.7 Off-policy Monte Carlo Control
下图是离线Monte Carlo控制算法的伪代码,使用行为策略生成数据,学习和提升目标网络。为了探索所有的可能性,要求行为策略一定是的soft的。

这个方法一个潜在的问题是,当回合中的所有其余动作都是贪心的,此方法只能从回合的尾部学习。如果非贪心的行为很普遍,那么学习将会很慢,尤其是对长回合早期出现的状态,这可能会大大减慢学习速度。解决这个问题的最重要方法可能是结合下一章会学到的时间差分学习。如果 γ \gamma γ小于1,下一节提出的想法可能也有很大帮助。
5.8 *Discounting-aware Importance Sampling
TODO,后面再看
5.9 *Per-decision Importance Sampling
TODO,后面再看
5.10 Summary
关键知识点
- Monte Carlo 方法的三个优点
- Monte Carlo 方法的第四个优点:不符合马尔科夫性时损害较小,因为它们不是自举的(boostrap)
- 探索式出发
- 在线策略(on-policy)算法
- 离线策略(off-policy)算法
- 重要性采样、普通重要性采样、加权重要性采样
参考资料
- 《Reinforcement Learning: An Introduction》Sutton, Richard S. and Andrew G. Barto. 第2版, 书籍网站
- https://github.com/ShangtongZhang/reinforcement-learning-an-introduction
- https://github.com/YunlianMoon/reinforcement-learning-an-introduction-2nd-edition/tree/master