pandas学习笔记
pandas介绍
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。
Panel :三维的数组,可以理解为DataFrame的容器。
Panel4D:是像Panel一样的4维数据容器。
PanelND:拥有factory集合,可以创建像Panel4D一样N维命名容器的模块。
安装pandas
pip install pandas
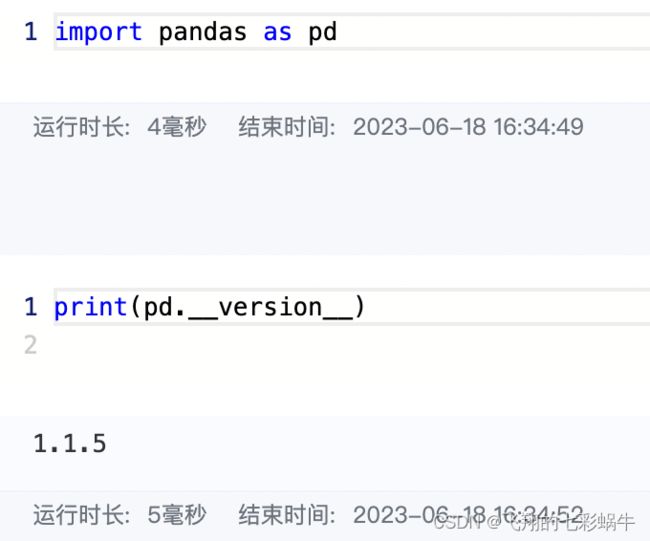
print(pd.__version__)
导入pandas
series
切片
ser[1:3]
'''
b 7
c 6
dtype: object
'''
ser[1:2]
'''
b 7
dtype: object
'''
还支持开放式切片:
ser[4:]
'''
e 5
f 3
dtype: object
'''
ser[:4]
'''
a 9
b 7
c 6
d 2
dtype: object
'''索引
和列表一样,每个 Series 也有一个自然索引位,可以通过索引获取这个位置上的值。
ser[0] # 第一个位置
# '9'
ser[-1] # 最后一个位置
# '3'
ser[-2] # 倒数第二个位置
# '5'
05.Pandas四种新增数据列_pandas series添加数据_CSDN专家-微编程的博客-CSDN博客
pandas基础教程二_Series数据结构 - 知乎
#1.使用列表:
import pandas as pd
lst = [1,2,3,4,5,6]
sl = pd.Series(lst)
print(sl)修改
Series(五):Series的增、删、改、查_series增加_数据分析与统计学之美的博客-CSDN博客
x = pd.Series([10,23,31,16],index=list("abcd"))
display(x)
# 获取到某个值后,采用赋值方式修改值
display(x.loc["a"])
x.loc["a"] = 666
display(x)
x.iloc[2] = 888
display(x)
————————————————
版权声明:本文为CSDN博主「数据分析与统计学之美」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_41261833/article/details/104149081dataframe
说明
增:增加一行或一列;
删:删出一行或一列;
改:修改某行或某列;
查:获取Datarame中的值;
DataFrame(6):DataFrame的增、删、改、查_51CTO博客_dataframe
查
注意:不管是单独获取到一行、还是一列,得到的都是一个Series。不管是单独获取到多行、还是多列,得到的都是一个DataFrame。
3.Series常用属性
Series有很多的常用属性,这些属性在数据分析的时候比较常用,我们来列举几个常用的:
| 属性 | 属性说明 |
| loc | 通过索引值取数 |
| iloc | 通过索引位置取数 |
| size | 获取Series中数据量 |
| shape | Series数据维度 |
| dtype | Series数据类型 |
| Values | 获取Series的数据 |
我们举例说明一下这些属性的用法:
切片
Python dataframe 索引 切片_dataframe切片_正在学习中的李斌的博客-CSDN博客
# 行的索引本质是切片
# 单行索引
df[0:1] # 第1行
df[5:6] # 第6行
# 多行索引
df[0:10] # 获取前10行
df[:10] # 获取前10行
df[5:] # 获取第5行和后面所有的行
df[0:100:5] # 获取前100行中的 每5行行取一行,总计20行
#---------------------------------------------------
————————————————
版权声明:本文为CSDN博主「正在学习中的李斌」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35240689/article/details/126994625首先我们来看一下loc:
#loc
import pandas as pd
obj = pd.Series([1,2,3,4],index=['a','b','c','d'])
print(obj['a'])
print(obj['a':'c'])
print(obj.loc['a'])
print(obj.loc['a':'c'])
print(obj.loc[['a','c']])我们来看一下iloc
print(obj.iloc[0])
print(obj.iloc[0:2])
print(obj.iloc[[0,2]])
#输出结果如下:
1
a 1
b 2
dtype: int64
a 1
c 3
dtype: int64增
行 / 列
1)增加行
① df.loc()
df = pd.DataFrame({"A":[1,3,5,7,9],
"B":[2,4,6,8,10],
"C":[3,6,9,12,15],
"D":[1,2,3,4,5]},
index=list("abcde"))
display(df)
df.loc["f"] = pd.Series([1,2,3,4],index=df.columns)
-----------------------------------
©著作权归作者所有:来自51CTO博客作者黄至尊qwe的原创作品,请联系作者获取转载授权,否则将追究法律责任
DataFrame(6):DataFrame的增、删、改、查
https://blog.51cto.com/u_14346314/55371962)增加列
① 增加一列:df[“新列名”]
df = pd.DataFrame({"A":[1,3,5,7,9],
"B":[2,4,6,8,10],
"C":[3,6,9,12,15],
"D":[1,2,3,4,5]},
index=list("abcde"))
display(df)
df["E"] = pd.Series([6,6,6,6,6],index=df.index)
-----------------------------------
©著作权归作者所有:来自51CTO博客作者黄至尊qwe的原创作品,请联系作者获取转载授权,否则将追究法律责任
DataFrame(6):DataFrame的增、删、改、查
https://blog.51cto.com/u_14346314/5537196删
删除一行:df.drop(axis=0)
df = pd.DataFrame({"A":[1,3,5,7,9],
"B":[2,4,6,8,10],
"C":[3,6,9,12,15],
"D":[1,2,3,4,5]},
index=list("abcde"))
display(df)
df.drop(["a","d"],axis=0)
-----------------------------------
©著作权归作者所有:来自51CTO博客作者黄至尊qwe的原创作品,请联系作者获取转载授权,否则将追究法律责任
DataFrame(6):DataFrame的增、删、改、查
https://blog.51cto.com/u_14346314/5537196删除一列
df = pd.DataFrame({"A":[1,3,5,7,9],
"B":[2,4,6,8,10],
"C":[3,6,9,12,15],
"D":[1,2,3,4,5]},
index=list("abcde"))
display(df)
df.drop(["B"],axis=1)
-----------------------------------
©著作权归作者所有:来自51CTO博客作者黄至尊qwe的原创作品,请联系作者获取转载授权,否则将追究法律责任
DataFrame(6):DataFrame的增、删、改、查
https://blog.51cto.com/u_14346314/5537196改
#更新一列值
df2.loc[:,'D']
df2.loc[:,'D'] = 5
df2
df2.iloc[1,3]
df2.iloc[1,3] = 10.1
df2
#通过where更新
df3 = df.copy()
df3[df3 > 0] = -df3
df3
原文链接:https://blog.csdn.net/zi_ying123/article/details/109690451
pandas学习笔记目录

pandas可视化
散点图
Python Pandas 图形绘制(三):散点图(单维度和交叉维度)_pandas绘制散点图_AItrust的博客-CSDN博客
直方图
【数据可视化】Pandas画直方图_pandas 直方图_ChenVast的博客-CSDN博客

折线图
Pandas——Matplotlib绘制折线图_pandas画折线图_黑桃5200的博客-CSDN博客
df.map()
1. 对Series进行映射换值操作:
series.map(map_dict)
其中,map_dict是一个字典类型的参数,键为需要替换的元素,值为替换后的元素。示例如下:
import pandas as pd
# 创建Series
s = pd.Series(['apple', 'banana', 'orange'])
# 定义映射字典
map_dict = {'apple': 'red', 'banana': 'yellow', 'orange': 'orange'}
# 映射换值
s.map(map_dict)
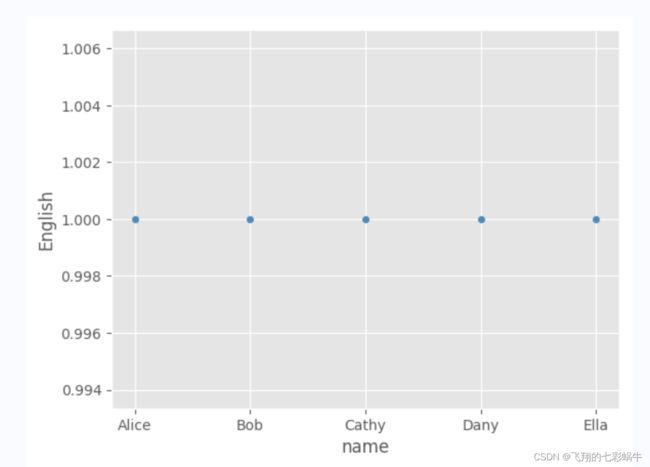
import pandas as pd
data = {'name' : pd.Series(['Alice', 'Bob', 'Cathy', 'Dany', 'Ella']),
'English' : pd.Series([3, 2.6, 2, 1.7, 3]),
'Math' : pd.Series([1.1, 2.2, 3.3, 4.4, 5]),
}
df = pd.DataFrame(data)
df.English = df.English.map(lambda x: 1 if x > 0 else x)
# df['是否重复']=df['filename'].map(path_info) #df.map的第二种用法,参数为字典,产生新的列
df.apply()
import pandas as pd
data = {'name' : pd.Series(['Alice', 'Bob', 'Cathy', 'Dany', 'Ella']),
'English' : pd.Series([3, 2.6, 2, 1.7, 3]),
'Math' : pd.Series([1.1, 2.2, 3.3, 4.4, 5]),
}
df = pd.DataFrame(data)
def get_add(English, Math):
return English + Math
# 策略实现
df['add_score'] = df.apply(lambda row: get_add(row['English'], row['Math']), axis=1)分组处理
DataFrame.groupby()函数的各种用法详解_dataframe groupby_Cabbage coder的博客-CSDN博客
groupby
axis
groupby的函数定义:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)

import pandas as pd
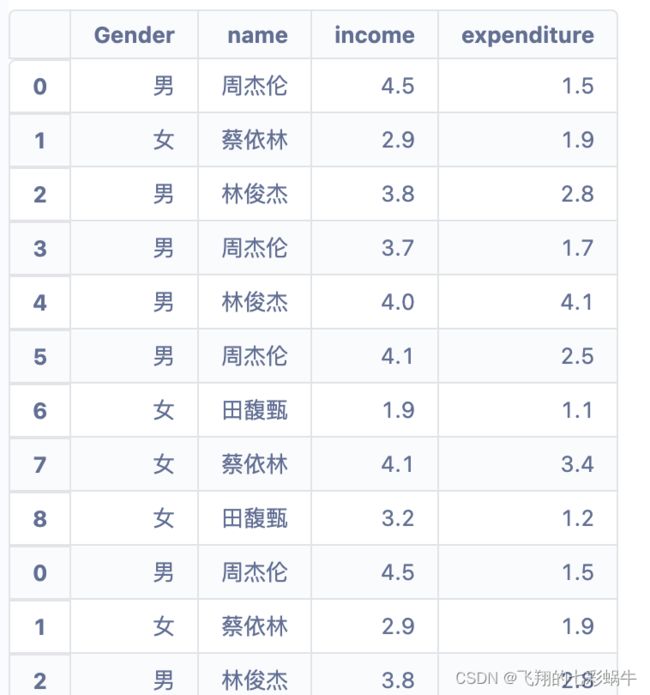
df = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周杰伦', '蔡依林', '林俊杰', '周杰伦', '林俊杰', '周杰伦', '田馥甄', '蔡依林', '田馥甄'],
'income' : [4.5, 2.9, 3.8, 3.7, 4.0, 4.1, 1.9, 4.1, 3.2],
'expenditure' : [1.5, 1.9, 2.8, 1.7, 4.1, 2.5, 1.1, 3.4, 1.2]
})
#根据其中一列分组
df_expenditure_mean = df.groupby(['Gender']).mean()
#根据其中两列分组
df_expenditure_mean = df.groupby(['Gender', 'name']).mean()
#只对其中一列求均值
df_expenditure_mean = df.groupby(['Gender', 'name'])['income'].mean()
df.groupby([‘Gender’, ‘name’]).agg([‘mean’, ‘sum’])
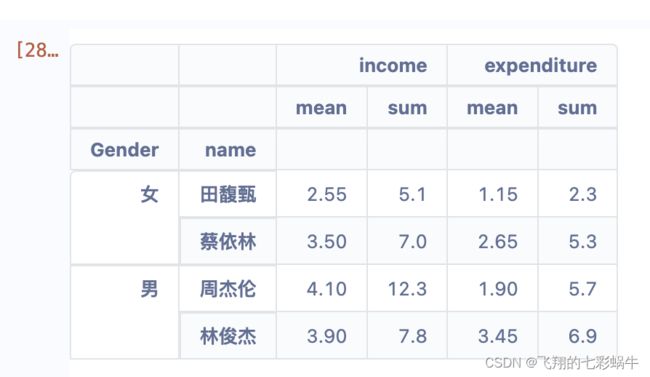
# 加一句df_apply_index = df_apply.reset_index()
df_apply = df.groupby(['Gender', 'name'], as_index=False).apply(lambda x: sum(x['income']-x['expenditure'])/sum(x['income']))
df_apply = pd.DataFrame(df_apply,columns=['存钱占比'])#转化成dataframe格式
df_apply_index = df_apply.reset_index()
Pandas DataFrame: groupby agg的使用_条件漫步的博客-CSDN博客
concat
dataframe.concat()_dataframe的concat_漂亮的刘大漂亮的博客-CSDN博客
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
相同字段的表首尾相接
import pandas as pd
df1 = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周杰伦', '蔡依林', '林俊杰', '周杰伦', '林俊杰', '周杰伦', '田馥甄', '蔡依林', '田馥甄'],
'income' : [4.5, 2.9, 3.8, 3.7, 4.0, 4.1, 1.9, 4.1, 3.2],
'expenditure' : [1.5, 1.9, 2.8, 1.7, 4.1, 2.5, 1.1, 3.4, 1.2]
})
df2 = pd.DataFrame({'Gender' : ['男', '女', '男', '男', '男', '男', '女', '女', '女'],
'name' : ['周杰伦', '蔡依林', '林俊杰', '周杰伦', '林俊杰', '周杰伦', '田馥甄', '蔡依林', '田馥甄'],
'income' : [4.5, 2.9, 3.8, 3.7, 4.0, 4.1, 1.9, 4.1, 3.2],
'expenditure' : [1.5, 1.9, 2.8, 1.7, 4.1, 2.5, 1.1, 3.4, 1.2]
})
data=pd.concat([df1, df2],axis=0)