【youcans动手学模型】MobileNet 模型-CIFAR10图像分类
欢迎关注『youcans动手学模型』系列
本专栏内容和资源同步到 GitHub/youcans
【youcans动手学模型】MobileNet 模型-CIFAR10图像分类
-
- 1. MobileNet 卷积神经网络模型
-
- 1.1 模型简介
- 1.2 论文介绍
- 2. 在 PyTorch 中定义 MobileNet V1 模型类
-
- 2.1 深度可分离卷积(DSC)模块
- 2.2 MobileNet V1 模型类
- 2.3 MobileNet V1 模型类(之二)
- 3. 基于 MobileNet 模型的 CIFAR10 图像分类
-
- 3.1 PyTorch 建立神经网络模型的基本步骤
- 3.2 加载 CIFAR10 数据集
- 3.3 建立 MobileNet 网络模型
- 3.4 MobileNet 模型训练
- 3.5 MobileNet 模型的保存与加载
- 3.6 模型检验
- 3.7 模型推理
- 4. 基于 MobileNetV1 模型对 CIFAR10 进行图像分类的完整例程
本文用 PyTorch 实现 MobileNet 网络模型,使用 CIFAR10 数据集训练模型,进行图像分类。
1. MobileNet 卷积神经网络模型
Andrew G. Howard, Menglong Zhu 等在 2017 年发表论文“MobileNets: Effificient Convolutional Neural Networks for Mobile Vision Applications”,提出深度可分离卷积(depth-wise separable convolutions)模型,是轻量级深度神经网络的重要。
【论文下载地址】
MobileNets: Effificient Convolutional Neural Networks for Mobile Vision Applications
【GitHub地址】:https://github.com/Zehaos/MobileNet
1.1 模型简介
传统的卷积操作同时对输入特征图的空间交互性(spatial correlations)和跨通道交互性(cross-channel correlations)进行映射。
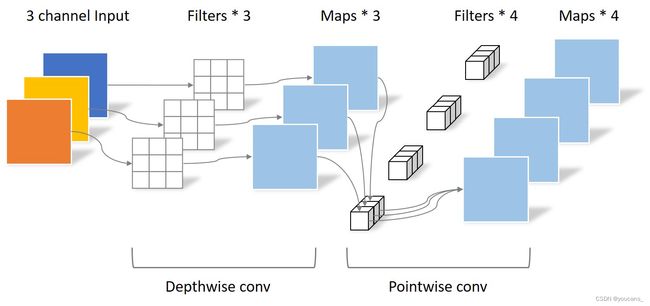
MobileNet 提出深度可分离卷积(Depthwise Separable Convolution,DSC)将传统的卷积运算分解为深度卷积(depthwise convolution)和逐点卷积(pointwise convolution),实现跨通道相关性和空间相关性的解耦。
- 深度卷积,每个卷积核只作用于单一通道的分组卷积,分组数等于输入通道数,实现空间相关性的映射。
- 逐点卷积,在级联通道上进行 1*1 卷积,实现跨通道相关性的映射。
1.2 论文介绍
【论文摘要】
本文针对移动端和嵌入式视觉应用程序的需求,提出了轻量级的 MobileNets 模型。MobileNets 基于流水线架构,使用深度可分离卷积(Depthwise Separable Convolution)来构建轻量级的深度神经网络架构。
MobileNets 模型引入了两个超参数:宽度因子 α 和分辨率因子 ρ,可以有效地在延迟和准确性之间进行权衡,用户可以根据需求为应用程序选择大小适当的模型。
我们做了大量权衡资源和准确性的实验。对于 ImageNet 分类问题,MobileNets 与其它常用模型相比也具有很好的性能。测试了 MobileNets 在目标检测、细粒度分类、人脸识别和地理定位等各种任务和用例中的有效性。
【论文背景】
自从 AlexNex 赢得 ILSVRC 2012 图像挑战赛以来,深度卷积神经网络在计算机视觉中大受欢迎,应用广泛。总的趋势是建立更深、更复杂的网络,以实现更高的精度。然而,精度的提高不一定使网络在模型大小和速度方面更加高效。在机器人技术、自动驾驶汽车和增强现实等实际应用中,识别任务需要在计算能力有限的平台上及时执行。
因此,人们对建立小型和高效的网络越来越感兴趣,常用方法是压缩预训练网络或直接训练小网络。MobileNet 主要由 L. Sifre 的 Rigid-motion scattering for image classification 中的深度可分离卷积构建。Factorized convolutional neural networks 也引入了类似的分解卷积以及拓扑连接的使用,随后 Xception 网络提出了扩大深度可分离网络。另一个小型网络是SqueezeNet,它使用 bottleneck 方法来设计一个非常小的网络。
【主要创新】
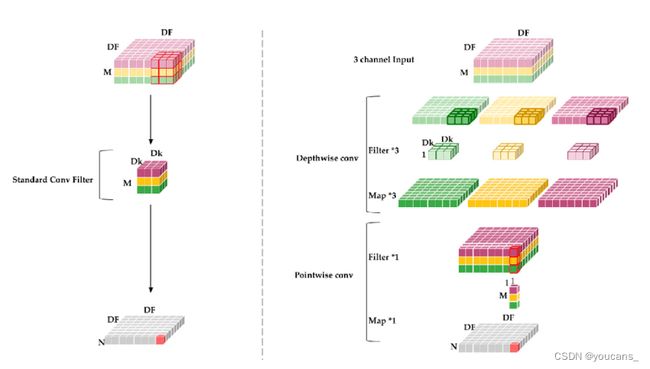
MobileNet 的核心是深度可分离卷积(depthwise separate convolution,DSC)。
(1)标准卷积层
传统的卷积操作对输入特征图的空间进行跨通道的映射,输入是 I w ∗ I h ∗ n i n I_w*I_h*n_{in} Iw∗Ih∗nin 的特征图,输出是 I G ∗ I G ∗ n o u t I_G*I_G*n_{out} IG∗IG∗nout 的特征图,参数量为 n i n ∗ k w ∗ k h ∗ n o u t n_{in}*k_w*k_h*n_{out} nin∗kw∗kh∗nout,计算量为 n i n ∗ I w ∗ I h ∗ k w ∗ k h ∗ n o u t n_{in}*I_w*I_h*k_w*k_h*n_{out} nin∗Iw∗Ih∗kw∗kh∗nout。

(2)深度可分离卷积
深度可分离卷积将传统的卷积运算分解为深度卷积和逐点卷积。
- 深度卷积(depthwise convolution),每个卷积核只作用于单一通道的分组卷积,分组数等于输入通道数,实现空间相关性的映射。
- 逐点卷积(pointwise convolution),在级联通道上进行 1*1 卷积,实现跨通道相关性的映射。
- MobileNet 对深度卷积层和逐点卷积层都使用了 BatchNorm 和 ReLU 。

深度卷积的参数量为 n i n ∗ k w ∗ k h n_{in}*k_w*k_h nin∗kw∗kh,计算量为 I w ∗ I h ∗ n i n ∗ k w ∗ k h I_w*I_h*n_{in}*k_w*k_h Iw∗Ih∗nin∗kw∗kh。
逐点卷积的参数量为 n i n ∗ n o u t n_{in}*n_{out} nin∗nout,计算量为 I w ∗ I h ∗ n i n ∗ n o u t I_w*I_h*n_{in}*n_{out} Iw∗Ih∗nin∗nout。
因此,深度可分离卷积常规的卷积操作相比,参数量、计算量大大减少,如下式所示:
I w ∗ I h ∗ n i n ∗ k w ∗ k h + I w ∗ I h ∗ n i n ∗ n o u t I w ∗ I h ∗ n i n ∗ k w ∗ k h ∗ n o u t = 1 n o u t + 1 k w ∗ k h \frac{I_w*I_h*n_{in}*k_w*k_h + I_w*I_h*n_{in}*n_{out}}{I_w*I_h*n_{in}*k_w*k_h*n_{out}} = \frac{1}{n_{out}} + \frac{1}{k_w*k_h} Iw∗Ih∗nin∗kw∗kh∗noutIw∗Ih∗nin∗kw∗kh+Iw∗Ih∗nin∗nout=nout1+kw∗kh1
以 16 个输入通道和 32 个输出通道上的 3x3卷积层为例:
-
常规的卷积操作有 16*32*3*3=4608 个参数。
-
在深度可分离卷积中,第一步空间卷积有 16*3*3= 144 个参数,第二步深度方向卷积有 16*32*1*1= 512 个参数,共 656 个参数。
【模型结构】
MobileNet 基于流线型架构,使用深度可分离卷积来构建轻量级深度神经网络
建立非常小的、低延迟的模型
MobileNet 模型基于深度可分离卷积,这是一种分解卷积形式,将标准卷积分解为深度卷积和称为点卷积的 1 × 1 卷积。
【模型配置】
MobileNet 模型的具体结构如下。
其中,dw 表示深度分离卷积,s1 表示 stride=1 大小不变,s2 表示 stride=2 高宽减半。
除了最后的全连接层 FC 不使用激活函数,其它层都使用 BN 和 ReLU 非线性函数。
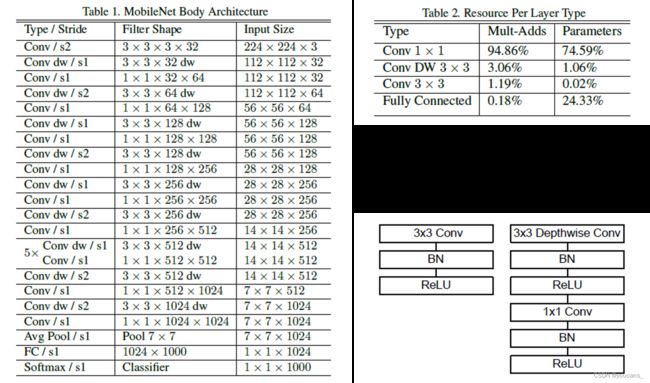
表 2 指出,在 MobileNet 模型中,逐点卷积层(1*1 卷积)的参数占比接近 75%,全连接层的参数占比约 24%,其它参数占比很小,而 95% 的计算量消耗在逐点卷积。
【模型超参数】
在 MobileNet 模型中,引入了两个超参数:宽度因子 α 和分辨率因子 ρ,可以有效地在延迟和准确性之间进行权衡,用户可以根据需求为应用程序选择大小适当的模型。
宽度因子 α(Width multiplier)
宽度因子用于控制输入和输出的通道数,使输入通道从 M 变为 α M \alpha M αM,输出通道从 N 变为 α N \alpha N αN。
与标准卷积层相比,深度可分离卷积的计算量和参数降低了约 α 2 \alpha^2 α2 倍。因此,通过调节宽度因子 α,可以很方便的控制模型的大小。
取值范围 α ∈ ( 0 , 1 ] \alpha \in (0, 1] α∈(0,1],通常设为 1.0, 0.75, 0.5 或 0.25。
分辨率因子 ρ( resolution multiplier)
分辨率因子用于控制输入和内部层表示,即控制输入图像的分辨率 。 输入的分辨率越低,预测的精度也越低,但下降并不大 。取值范围 ρ ∈ ( 0 , 1 ] \rho \in (0, 1] ρ∈(0,1],通常设置输入分辨率为 224 , 192 , 160 或 128。
通过分辨率因子,可以将深度可分离卷积的计算量降低了约 ρ 2 \rho^2 ρ2 倍。因此,通过调节宽度因子 ρ,也可以很方便的控制模型的大小。
宽度因子 α 和分辨率因子 ρ 对模型精度、计算量和参数量的影响如下表所示。
【模型性能】
MobileNet 模型性能如下表所示。
(1)与轻量级模型相比:小规模的 MobileNet 模型与 SqueezeNet相比性能更好,计算量只有其 4.5%,参数量相当;与 AlexNet 相比性能更好,计算量只有其 10%,参数量只有其 2%。
(2)与经典模型相比:标准规模的 MobileNet 模型与 VGG16 相比性能略低 1%,但计算量只有其 1/27,参数量只有其 1/33;与 GoogleNet(Inception V1) 相比性能略优,计算量是其 1/3,参数量是其 2/3;与 Inception V3 相比,性能略低不到 1%,但计算量只有其 1/9,参数量只有其 1/7。

2. 在 PyTorch 中定义 MobileNet V1 模型类
MobileNet 模型是一种网络框架,针对不同的任务可以进行不同的网络结构设计和超参数配置。
2.1 深度可分离卷积(DSC)模块
深度可分离卷积(DSC)是 MobileNet 网络架构的核心,由深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)连接组成,实现了跨通道相关性和空间相关性的完全解耦。
深度可分离卷积模块(DSC)的例程如下。
# 深度可分离卷积 DSC, 深度卷积 Depthwise + 逐点卷积 Pointwise
class DSCconv(nn.Module):
def __init__(self, in_ch, out_ch, stride=1):
super(DSCconv, self).__init__()
self.depthConv = nn.Sequential( # 深度卷积, (DW+BN+ReLU)
nn.Conv2d(in_ch, in_ch, kernel_size=3, stride=stride,
padding=1, groups=in_ch, bias=False),
nn.BatchNorm2d(in_ch),
nn.ReLU6(inplace=True))
self.pointConv = nn.Sequential( # 逐点卷积, (PW+BN+ReLU)
nn.Conv2d(in_ch, out_ch, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU6(inplace=True))
def forward(self, x):
x = self.depthConv(x)
x = self.pointConv(x)
return x
对应的标准卷积模块例程如下:
# 标准卷积层, 3*3 Conv + BN + ReLU
class convBN(nn.Module):
def __init__(self, in_ch, out_ch, stride=1):
super(convBN, self).__init__() # 3*3 Conv + BN + ReLU
self.convLayer = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(in_ch),
nn.ReLU6(inplace=True))
def forward(self, x):
x = self.convLayer(x)
return x
2.2 MobileNet V1 模型类
MobileNet 模型类定义如下,该模型与 MobileNet 论文原文的结构基本一致。
需要注意的是,该模型类是针对 ImageNet 数据集,输入图片大小为 224*224。
对于不同的数据集,可能需要进行一些适应性的调整。例如 CIFAR10 数据集图像分类问题数据集规模较小,图片尺寸为 32*32,可以对 MobileNet 模型进行适当的调整。
# 定义 MobileNetV1 模型
class MobileNetV1(nn.Module):
def __init__(self, input_channel=3, num_classes=100):
super(MobileNetV1, self).__init__()
self.num_classes = num_classes
self.entry = nn.Sequential(
nn.Conv2d(input_channel, 32, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True))
self.stage1 = nn.Sequential(
DSCconv(32, 64, 1),
DSCconv(64, 128, 2),
DSCconv(128, 128, 1),
DSCconv(128, 256, 2),
DSCconv(256, 256, 1))
self.stage2 = nn.Sequential(
DSCconv(256, 512, 2),
DSCconv(512, 512, 1),
DSCconv(512, 512, 1),
DSCconv(512, 512, 1),
DSCconv(512, 512, 1),
DSCconv(512, 512, 1))
self.stage3 = nn.Sequential(
DSCconv(512, 1024, 2),
DSCconv(1024, 1024, 1))
self.avgpool = nn.AdaptiveAvgPool2d((1,1)) # torch.Size([batch, 1024, 1, 1])
self.linear = nn.Linear(in_features=1024, out_features=num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.entry(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
out = self.softmax(x)
return out
使用 print(model) 可以输出 MobileNet V1模型的结构如下:
MobileNetV1(
(entry): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(stage1): Sequential(
(0): DSCconv(
(depthConv): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(1): DSCconv(
(depthConv): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(2): DSCconv(
(depthConv): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(3): DSCconv(
(depthConv): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(4): DSCconv(
(depthConv): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
)
(stage2): Sequential(
(0): DSCconv(
(depthConv): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=256, bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(1): DSCconv(
(depthConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(2): DSCconv(
(depthConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(3): DSCconv(
(depthConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(4): DSCconv(
(depthConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(5): DSCconv(
(depthConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
)
(stage3): Sequential(
(0): DSCconv(
(depthConv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
(1): DSCconv(
(depthConv): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024, bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
(pointConv): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU6(inplace=True)
)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(linear): Linear(in_features=1024, out_features=100, bias=True)
(softmax): Softmax(dim=1)
)
2.3 MobileNet V1 模型类(之二)
注意到 MobileNet V1 模型类中反复调用深度可分离卷积 DSCconv 类,因此可以用一个参数列表来表示,以简化程序,便于调整。
改进的 MobileNet 模型类定义如下。如果进一步把 cfg 作为参数传递,可以更加灵活地调整模型架构。
# 深度可分离卷积 DSC, 深度卷积 Depthwise + 逐点卷积 Pointwise
class DSCconv(nn.Module):
def __init__(self, in_ch, out_ch, stride=1):
super(DSCconv, self).__init__()
self.depthConv = nn.Sequential( # 深度卷积, (DW+BN+ReLU)
nn.Conv2d(in_ch, in_ch, kernel_size=3, stride=stride,
padding=1, groups=in_ch, bias=False),
nn.BatchNorm2d(in_ch),
nn.ReLU6(inplace=True))
self.pointConv = nn.Sequential( # 逐点卷积, (PW+BN+ReLU)
nn.Conv2d(in_ch, out_ch, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU6(inplace=True))
def forward(self, x):
x = self.depthConv(x)
x = self.pointConv(x)
return x
class MobileNetV1_cfg(nn.Module):
cfg = [(64, 1), # (in=32, out=64, s=1)
(128, 2), # (in=64, out=128, s=2)
(128, 1), # (in=128, out=128, s=1)
(256, 2), # (in=128, out=256, s=2)
(256, 1), # (in=256, out=256, s=1)
(512, 2), # (in=256, out=512, s=2)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(1024, 2), # (in=512, out=1024, s=2)
(1024, 1)] # (in=1024, out=1024, s=1)
def __init__(self, num_classes=100):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_ch=32)
self.avgpool = nn.AdaptiveAvgPool2d((1,1)) # torch.Size([batch, 1024, 1, 1])
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_ch):
layers = []
for x in self.cfg:
out_ch = x if isinstance(x, int) else x[0]
stride = 1 if isinstance(x, int) else x[1]
layers.append(DSCconv(in_ch, out_ch, stride))
in_ch = out_ch
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layers(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
3. 基于 MobileNet 模型的 CIFAR10 图像分类
3.1 PyTorch 建立神经网络模型的基本步骤
使用 PyTorch 建立、训练和使用神经网络模型的基本步骤如下。
- 准备数据集(Prepare dataset):加载数据集,对数据进行预处理。
- 建立模型(Design the model):实例化模型类,定义损失函数和优化器,确定模型结构和训练方法。
- 模型训练(Model trainning):使用训练数据集对模型进行训练,确定模型参数。
- 模型推理(Model inferring):使用训练好的模型进行推理,对输入数据预测输出结果。
- 模型保存与加载(Model saving/loading):保存训练好的模型,以便以后使用或部署。
以下按此步骤讲解 MobileNet 模型的例程。
3.2 加载 CIFAR10 数据集
通用数据集的样本结构均衡、信息高效,而且组织规范、易于处理。使用通用的数据集训练神经网络,不仅可以提高工作效率,而且便于评估模型性能。
PyTorch 提供了一些常用的图像数据集,预加载在 torchvision.datasets 类中。torchvision 模块实现神经网络所需的核心类和方法, torchvision.datasets 包含流行的数据集、模型架构和常用的图像转换方法。
CIFAR 数据集是一个经典的图像分类小型数据集,有 CIFAR10 和 CIFAR100 两个版本。CIFAR10 有 10 个类别,CIFAR100 有 100 个类别。CIFAR10 每张图像大小为 32*32,包括飞机、小汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车 10 个类别。CIFAR10 共有 60000 张图像,其中训练集 50000张,测试集 10000张。每个类别有 6000张图片,数据集平衡。
加载和使用 CIFAR 数据集的方法为:
torchvision.datasets.CIFAR10()
torchvision.datasets.CIFAR100()
CIFAR 数据集可以从官网下载:http://www.cs.toronto.edu/~kriz/cifar.html 后使用,也可以使用 datasets 类自动加载(如果本地路径没有该文件则自动下载)。
下载数据集时,使用预定义的 transform 方法进行数据预处理,包括调整图像尺寸、标准化处理,将数据格式转换为张量。标准化处理所使用 CIFAR10 数据集的均值和方差为 (0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)。transform_train在训练过程中,增加随机性,提高泛化能力。
大型训练数据集不能一次性加载全部样本来训练,可以使用 Dataloader 类自动加载数据。Dataloader 是一个迭代器,基本功能是传入一个 Dataset 对象,根据参数 batch_size 生成一个 batch 的数据。
使用 DataLoader 类加载 CIFAR-10 数据集的例程如下。
# (1) 将[0,1]的PILImage 转换为[-1,1]的Tensor
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.Resize(32), # 图像大小调整为 (w,h)=(32,32)
transforms.ToTensor(), # 将图像转换为张量 Tensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# 测试集不需要进行数据增强
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# (2) 加载 CIFAR10 数据集
batchsize = 128
# 加载 CIFAR10 数据集, 如果 root 路径加载失败, 则自动在线下载
# 加载 CIFAR10 训练数据集, 50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='../dataset', train=True,
download=True, transform=transform_train)
# train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize,
shuffle=True, num_workers=8)
# 加载 CIFAR10 验证数据集, 10000张验证图片
test_set = torchvision.datasets.CIFAR10(root='../dataset', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000,
shuffle=True, num_workers=8)
# 创建生成器,用 next 获取一个批次的数据
valid_data_iter = iter(test_loader) # _SingleProcessDataLoaderIter 对象
valid_images, valid_labels = next(valid_data_iter) # images: [batch,3,32,32], labels: [batch]
valid_size = valid_labels.size(0) # 验证数据集大小,batch
print(valid_images.shape, valid_labels.shape)
# 定义类别名称,CIFAR10 数据集的 10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
3.3 建立 MobileNet 网络模型
建立一个 MobileNet 网络模型进行训练,包括三个步骤:
- 实例化 MobileNet 模型对象;
- 设置训练的损失函数;
- 设置训练的优化器。
torch.nn.functional 模块提供了各种内置损失函数,本例使用交叉熵损失函数 CrossEntropyLoss。
torch.optim 模块提供了各种优化方法,本例使用 Adam 优化器。注意要将 model 的参数 model.parameters() 传给优化器对象,以便优化器扫描需要优化的参数。
# (3) 构造 MobileNetV1 网络模型
model = MobileNetV1(num_classes=10) # 实例化 MobileNetV1 网络模型
model.to(device) # 将网络分配到指定的device中
# print(model)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 定义损失函数 CrossEntropy
optimizer = torch.optim.Adam(lr=0.001, params=model.parameters()) # 定义优化器 Adam
3.4 MobileNet 模型训练
PyTorch 模型训练的基本步骤是:
- 前馈计算模型的输出值;
- 计算损失函数值;
- 计算权重 weight 和偏差 bias 的梯度;
- 根据梯度值调整模型参数;
- 将梯度重置为 0(用于下一循环)。
在模型训练过程中,可以使用验证集数据评价训练过程中的模型精度,以便控制训练过程。模型验证就是用验证数据进行模型推理,前向计算得到模型输出,但不反向计算模型误差,因此需要设置 torch.no_grad()。
使用 PyTorch 进行模型训练的例程如下。
# (4) 训练 MobileNetV1 模型
epoch_list = [] # 记录训练轮次
loss_list = [] # 记录训练集的损失值
accu_list = [] # 记录验证集的准确率
num_epochs = 100 # 训练轮次
for epoch in range(num_epochs): # 训练轮次 epoch
running_loss = 0.0 # 每个轮次的累加损失值清零
for step, data in enumerate(train_loader, start=0): # 迭代器加载数据
optimizer.zero_grad() # 损失梯度清零
inputs, labels = data # inputs: [batch,3,32,32] labels: [batch]
outputs = model(inputs.to(device)) # 正向传播
loss = criterion(outputs, labels.to(device)) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 累加训练损失值
running_loss += loss.item()
# if step%100==99: # 每 100 个 step 打印一次训练信息
# print("\t epoch {}, step {}: loss = {:.4f}".format(epoch, step, loss.item()))
# 计算每个轮次的验证集准确率
with torch.no_grad(): # 验证过程, 不计算损失函数梯度
outputs_valid = model(valid_images.to(device)) # 模型对验证集进行推理, [batch, 10]
pred_labels = torch.max(outputs_valid, dim=1)[1] # 预测类别, [batch]
accuracy = torch.eq(pred_labels, valid_labels.to(device)).sum().item() / valid_size * 100 # 计算准确率
print("Epoch {}: train loss={:.4f}, accuracy={:.2f}%".format(epoch, running_loss, accuracy))
# 记录训练过程的统计数据
epoch_list.append(epoch) # 记录迭代次数
loss_list.append(running_loss) # 记录训练集的损失函数
accu_list.append(accuracy) # 记录验证集的准确率
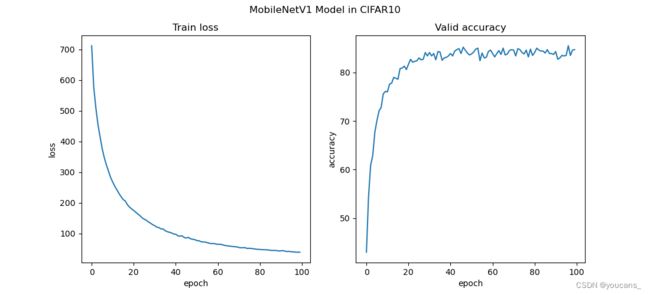
程序运行结果如下:
Epoch 0: train loss=711.8080, accuracy=43.00%
Epoch 1: train loss=575.9495, accuracy=54.40%
Epoch 2: train loss=508.9343, accuracy=60.90%
Epoch 3: train loss=455.0433, accuracy=62.90%
…
Epoch 98: train loss=38.9741, accuracy=84.60%
Epoch 99: train loss=38.7399, accuracy=84.70%
经过 20 轮左右的训练,使用验证集中的 1000 张图片进行验证,模型准确率达到 80% 以上。继续训练可以进一步降低训练损失函数值,验证集的准确率保持在 85%左右。
3.5 MobileNet 模型的保存与加载
模型训练好以后,将模型保存起来,以便下次使用。PyTorch 中模型保存主要有两种方式,一是保存模型权值,二是保存整个模型。本例使用 model.state_dict() 方法以字典形式返回模型权值,torch.save() 方法将权值字典序列化到磁盘,将模型保存为 .pth 文件。
# (5) 保存 MobileNetV1 网络模型
save_path = "../models/MobileNetV1_Cifar1"
model_cpu = model.cpu() # 将模型移动到 CPU
model_path = save_path + ".pth" # 模型文件路径
torch.save(model.state_dict(), model_path) # 保存模型权值
使用训练好的模型,首先要实例化模型类,然后调用 load_state_dict() 方法加载模型的权值参数。
# 以下模型加载和模型推理,可以是另一个独立的程序
# (6) 加载 MobileNetV1 网络模型进行推理
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检测并指定设备
model = MobileNetV1(num_classes=10) # 实例化 MobileNetV1 网络模型
model.to(device) # 将网络分配到指定的 device 中
model_path = "../models/MobileNetV1_Cifar1.pth"
model.load_state_dict(torch.load(model_path))
model.eval() # 模型推理模式
需要特别注意的是:
(1)PyTorch 中的 .pth 文件只保存了模型的权值参数,而没有模型的结构信息,因此必须先实例化模型对象,再加载模型参数。
(2)模型对象必须与模型参数严格对应,才能正常使用。注意即使都是 MobileNet 模型,模型类的具体定义也可能有细微的区别。如果从一个来源获取模型类的定义,从另一个来源获取模型参数文件,就很容易造成模型结构与参数不能匹配。
(3)无论从 PyTorch 模型仓库加载的模型和参数,或从其它来源获取的预训练模型,或自己训练得到的模型,模型加载的方法都是相同的,也都要注意模型结构与参数的匹配问题。
3.6 模型检验
使用加载的 MobileNet 模型,输入新的图片进行模型推理,可以由模型输出结果确定输入图片所属的类别。
使用测试集数据进行模型推理,根据模型预测结果与图片标签进行比较,可以检验模型的准确率。模型验证集与模型检验集不能交叉使用,但为了简化例程在本程序中未做区分。
# (7) 模型检测
correct = 0
total = 0
for data in test_loader: # 迭代器加载测试数据集
imgs, labels = data # torch.Size([batch,3,32,32) torch.Size([batch])
# print(imgs.shape, labels.shape)
outputs = model(imgs.to(device)) # 正向传播, 模型推理, [batch, 10]
labels_pred = torch.max(outputs, dim=1)[1] # 模型预测的类别 [batch]
# _, labels_pred = torch.max(outputs.data, 1)
total += labels.size(0)
correct += torch.eq(labels_pred, labels.to(device)).sum().item()
accuracy = 100. * correct / total
print("Test samples: {}".format(total))
print("Test accuracy={:.2f}%".format(accuracy))
使用测试集进行模型推理,测试模型准确率为 85.46%。
Test samples: 10000
Test accuracy=85.46%
3.7 模型推理
使用加载的 MobileNet 模型,输入新的图片进行模型推理,可以由模型输出结果确定输入图片所属的类别。
从测试集中提取几张图片,或者读取图像文件,进行模型推理,获得图片的分类类别。在提取图片或读取文件时,要注意对图片格式和图片大小进行适当的转换。
# (8) 提取测试集图片进行模型推理
batch = 8 # 批次大小
data_set = torchvision.datasets.CIFAR10(root='../dataset', train=False,
download=False, transform=None)
plt.figure(figsize=(9, 6))
for i in range(batch):
imgPIL = data_set[i][0] # 提取 PIL 图片
label = data_set[i][1] # 提取 图片标签
# 预处理/模型推理/后处理
imgTrans = transform(imgPIL) # 预处理变换, torch.Size([3,32,32])
imgBatch = torch.unsqueeze(imgTrans, 0) # 转为批处理,torch.Size([batch=1,3,32,32])
outputs = model(imgBatch.to(device)) # 模型推理, 返回 [batch=1, 10]
indexes = torch.max(outputs, dim=1)[1] # 注意 [batch=1], device = 'device
index = indexes[0].item() # 预测类别,整数
# 绘制第 i 张图片
imgNP = np.array(imgPIL) # PIL -> Numpy
out_text = "label:{}/model:{}".format(classes[label], classes[index])
plt.subplot(2, 4, i+1)
plt.imshow(imgNP)
plt.title(out_text)
plt.axis('off')
plt.tight_layout()
plt.show()
结果如下。

# (9) 读取图像文件进行模型推理
from PIL import Image
filePath = "../images/img_car_01.jpg" # 数据文件的地址和文件名
imgPIL = Image.open(filePath) # PIL 读取图像文件, 结果如下。

4. 基于 MobileNetV1 模型对 CIFAR10 进行图像分类的完整例程
本文的完整例程如下。
# Begin_MobileNetV1_CIFAR_2.py
# MobileNet model for beginner with PyTorch
# 经典模型: MobileNetV1 模型 CIFAR10 图像分类
# Copyright: [email protected]
# Crated: Huang Shan, 2023/05/26
# _*_coding:utf-8_*_
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
import numpy as np
# 深度可分离卷积 DSC, 深度卷积 Depthwise + 逐点卷积 Pointwise
class DSCconv(nn.Module):
def __init__(self, in_ch, out_ch, stride=1):
super(DSCconv, self).__init__()
self.depthConv = nn.Sequential( # 深度卷积, (DW+BN+ReLU)
nn.Conv2d(in_ch, in_ch, kernel_size=3, stride=stride,
padding=1, groups=in_ch, bias=False),
nn.BatchNorm2d(in_ch),
nn.ReLU6(inplace=True))
self.pointConv = nn.Sequential( # 逐点卷积, (PW+BN+ReLU)
nn.Conv2d(in_ch, out_ch, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU6(inplace=True))
def forward(self, x):
x = self.depthConv(x)
x = self.pointConv(x)
return x
class MobileNetV1(nn.Module):
cfg = [(64, 1), # (in=32, out=64, s=1)
(128, 2), # (in=64, out=128, s=2)
(128, 1), # (in=128, out=128, s=1)
(256, 2), # (in=128, out=256, s=2)
(256, 1), # (in=256, out=256, s=1)
(512, 2), # (in=256, out=512, s=2)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(512, 1), # (in=512, out=512, s=1)
(1024, 2), # (in=512, out=1024, s=2)
(1024, 1)] # (in=1024, out=1024, s=1)
def __init__(self, num_classes=100):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_ch=32)
self.avgpool = nn.AdaptiveAvgPool2d((1,1)) # torch.Size([batch, 1024, 1, 1])
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_ch):
layers = []
for x in self.cfg:
out_ch = x if isinstance(x, int) else x[0]
stride = 1 if isinstance(x, int) else x[1]
layers.append(DSCconv(in_ch, out_ch, stride))
in_ch = out_ch
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layers(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
# 优化结果写入数据文件
import pandas as pd
def WriteDataFile(epoch_list, loss_list, accu_list, filepath):
# print("def WriteDataFile()")
optRecord = {
"epoch": epoch_list,
"train_loss": loss_list,
"accuracy": accu_list}
dfRecord = pd.DataFrame(optRecord)
dfRecord.to_csv(filepath, index=False, encoding="utf_8_sig")
print("写入数据文件: %s 完成。" % filepath)
return
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# (1) 将[0,1]的PILImage 转换为[-1,1]的Tensor
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.Resize(32), # 图像大小调整为 (w,h)=(32,32)
transforms.ToTensor(), # 将图像转换为张量 Tensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# 测试集不需要进行数据增强
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# (2) 加载 CIFAR10 数据集
batchsize = 128
# 加载 CIFAR10 数据集, 如果 root 路径加载失败, 则自动在线下载
# 加载 CIFAR10 训练数据集, 50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='../dataset', train=True,
download=True, transform=transform_train)
# train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize,
shuffle=True, num_workers=8)
# 加载 CIFAR10 验证数据集, 10000张验证图片
test_set = torchvision.datasets.CIFAR10(root='../dataset', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000,
shuffle=True, num_workers=8)
# 创建生成器,用 next 获取一个批次的数据
valid_data_iter = iter(test_loader) # _SingleProcessDataLoaderIter 对象
valid_images, valid_labels = next(valid_data_iter) # images: [batch,3,32,32], labels: [batch]
valid_size = valid_labels.size(0) # 验证数据集大小,batch
print(valid_images.shape, valid_labels.shape)
# 定义类别名称,CIFAR10 数据集的 10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
# (3) 构造 MobileNetV1 网络模型
model = MobileNetV1(num_classes=10) # 实例化 MobileNetV1 网络模型
model.to(device) # 将网络分配到指定的device中
# print(model)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 定义损失函数 CrossEntropy
optimizer = torch.optim.Adam(lr=0.001, params=model.parameters()) # 定义优化器 Adam
# (4) 训练 MobileNetV1 模型
epoch_list = [] # 记录训练轮次
loss_list = [] # 记录训练集的损失值
accu_list = [] # 记录验证集的准确率
num_epochs = 100 # 训练轮次
for epoch in range(num_epochs): # 训练轮次 epoch
running_loss = 0.0 # 每个轮次的累加损失值清零
for step, data in enumerate(train_loader, start=0): # 迭代器加载数据
optimizer.zero_grad() # 损失梯度清零
inputs, labels = data # inputs: [batch,3,32,32] labels: [batch]
outputs = model(inputs.to(device)) # 正向传播
loss = criterion(outputs, labels.to(device)) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 累加训练损失值
running_loss += loss.item()
# if step%100==99: # 每 100 个 step 打印一次训练信息
# print("\t epoch {}, step {}: loss = {:.4f}".format(epoch, step, loss.item()))
# 计算每个轮次的验证集准确率
with torch.no_grad(): # 验证过程, 不计算损失函数梯度
outputs_valid = model(valid_images.to(device)) # 模型对验证集进行推理, [batch, 10]
pred_labels = torch.max(outputs_valid, dim=1)[1] # 预测类别, [batch]
accuracy = torch.eq(pred_labels, valid_labels.to(device)).sum().item() / valid_size * 100 # 计算准确率
print("Epoch {}: train loss={:.4f}, accuracy={:.2f}%".format(epoch, running_loss, accuracy))
# 记录训练过程的统计数据
epoch_list.append(epoch) # 记录迭代次数
loss_list.append(running_loss) # 记录训练集的损失函数
accu_list.append(accuracy) # 记录验证集的准确率
# (5) 保存 MobileNetV1 网络模型
save_path = "../models/MobileNetV1_Cifar1"
model_cpu = model.cpu() # 将模型移动到 CPU
model_path = save_path + ".pth" # 模型文件路径
torch.save(model.state_dict(), model_path) # 保存模型权值
# 优化结果写入数据文件
result_path = save_path + ".csv" # 优化结果文件路径
WriteDataFile(epoch_list, loss_list, accu_list, result_path)
# 训练结果可视化
plt.figure(figsize=(11, 5))
plt.suptitle("MobileNetV1 Model in CIFAR10")
plt.subplot(121), plt.title("Train loss")
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch'), plt.ylabel('loss')
plt.subplot(122), plt.title("Valid accuracy")
plt.plot(epoch_list, accu_list)
plt.xlabel('epoch'), plt.ylabel('accuracy')
plt.show()
参考文献:
- Andrew G. Howard, Menglong Zhu MobileNets: Effificient Convolutional Neural Networks for Mobile Vision Applications, 2017
【本节完】
版权声明:
欢迎关注『youcans动手学模型』系列
转发请注明原文链接:
【youcans动手学模型】MobileNet 模型-CIFAR10图像分类
Copyright 2023 youcans, XUPT
Crated:2023-06-20