CPU与GPU统一虚拟内存(CUDA UM)原理
CPU与GPU的统一内存(CUDA Unified Memory)原理
文章目录
- CPU与GPU的统一内存(CUDA Unified Memory)原理
- 一、UM下的CUDA编程
- 二、UM的实现原理
-
- 1. cudaMallocManaged分配CUDA内存
- 2. CPU缺页中断处理
- 3. CUDA Kernel 运行:
- 三、UM的性能缺陷及优化
-
- 1.用 `cudaMemPrefetchAsync` 避免缺页中断
- 2.用`cudaMemAdvise`告知分配内存的特性
- 四、其他 (TBD)
-
- 1.与UM相关的API简介
- 2.一些CUDA Memory的优化方法
- 五、参考文献
一、UM下的CUDA编程
在PCIE接口上插上GPU,就变成了我们Desktop形式的CPU/GPU,
CPU与GPU分离,各自有属于自己的物理地址:
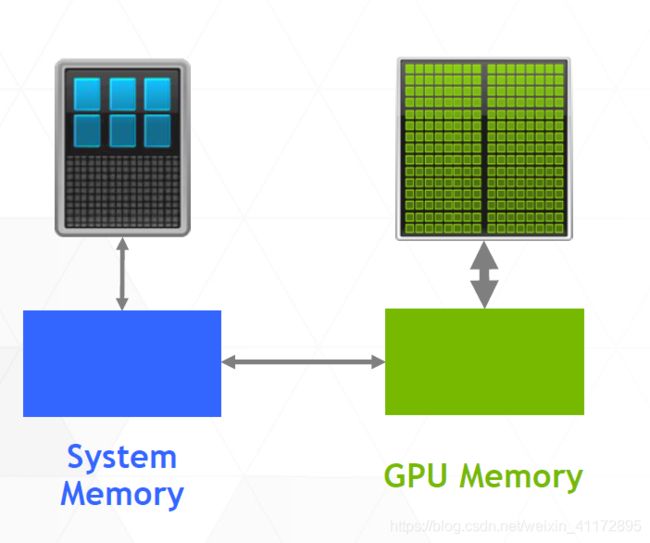
在这种情况下,我们比较熟悉的CUDA编程是用cudaMalloc和cudaHostMalloc分别分配device和host内存,先后显示调用cudaMemcpy进行拷贝。
但是使用的UM (Unified Memory)的cudaMallocManaged就不需要显示的将hostMem内容拷贝到deviceMem了,例子如下:
{
char * array = nullptr;
cudaMallocManaged(&array, N) //分配内存
fill_data(array);
qsort<<<...>>>(array); //GPU process
cudaDeviceSynchronize();
use_data(array); //CPU process
cudaFree(array);
}
同一个指针array可以同时分别在CUDA和CPU使用,但编程框架中只显示分配了个地址数值。所以必然有底层逻辑在CPU和GPU各自独立的空间之间拷贝了数据,使其表现为程序员看似GPU和CPU使用了同一段地址。
那么问题来了,CUDA Host Runtime悄悄的做了什么。
二、UM的实现原理
我们以如上的程序为例子:
1. cudaMallocManaged分配CUDA内存
Pascal及以上架构的GPU是可以处理页错误(Page Fault)的,cudaMallocManaged是cudaRuntimeAPI,其不仅仅只为CPU分配内存,还将CPU端的页信息发送到GPU上:
图中的例子所示,假设array占用两个内存页,内存分配在GPU上,但cudaRuntime同时在CPU端创建了指针array的内存页:
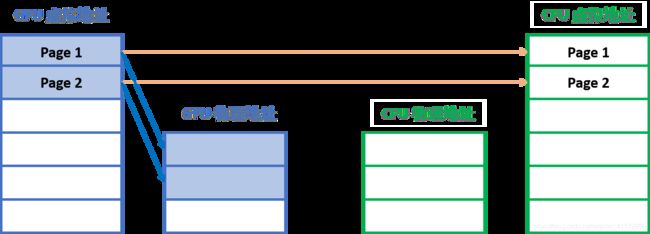
值得注意的是,由于CPU和GPU都用相同数值的array指针,所以页的页号在CPU和GPU端是相同的。
2. CPU缺页中断处理
接下来程序在CPU端调用fill_data(array)但实际上CPU没有为array实际分配内存空间,仅仅是有保留的页表存在,所以必然会产生缺页中断:
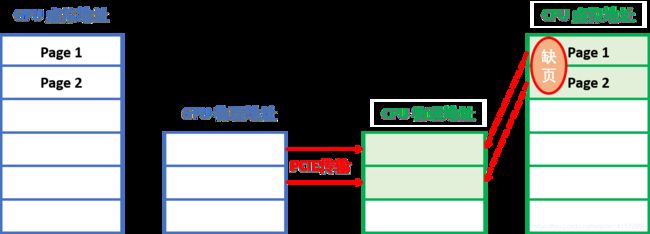
此时的缺页中断会促使GPU内存的内容通过PCIE总线migrate到CPU内存当中,待CPU处理完缺页,fill_data才函数会继续处理。
当GPU的页传输到CPU当中,为保证数据一致性,GPU的页就标记为失效。
3. CUDA Kernel 运行:
之后程序调用cudaKernel: sort<<<....,s>>> 此时,轮到GPU发生缺页中断和数据migrate了:
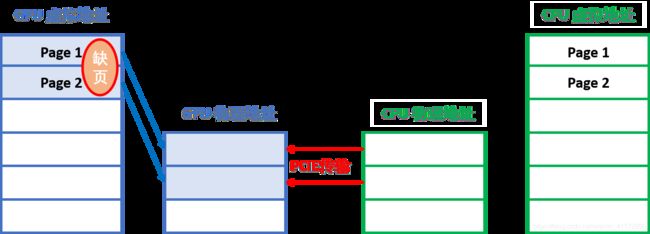
待Kernel处理完毕,cudaDeviceSyncornize等待万里,CPU再执行use_data首先会发生缺页中断,数据再传回CPU。
三、UM的性能缺陷及优化
1.用 cudaMemPrefetchAsync 避免缺页中断
毫无疑问,除去数据频繁搬运不说。这些缺页中断看着就很让人蛋疼,内存页的数据量小,页的数量很多。导致缺页中断次数多,CPU在用户态和内核态之间来回摇摆,而且内存页的传输不一定用到了DMA。
为了提升传输性能,这时就要引入cudaMemPrefetchAsync,调用DMA来异步传输,再通过cudaStream同步。这样指定的device端由于知道预取多大的数据,就不会频繁的发生缺页中断了。
#define GPU_DEVICE 0
{
char * array = nullptr;
cudaMallocManaged(&array, N) //分配内存
fill_data(array);
cudaMemPerfechAsync(array, N, GPU_DEVICE ,NULL); //告诉GPU预取的数据,使其可以一次性DMA读取
qsort<<<...>>>(array); //GPU process
cudaMemPerfechAsync(array, N, cudaCpuDeviceId ,NULL); //告诉CPU预取的数据,使其可以一次性DMA读取
cudaDeviceSynchronize();
use_data(array); //CPU process
cudaFree(array);
}
2.用cudaMemAdvise告知分配内存的特性
对于使用cudaMallocManaged开辟的内存,当cudaKernel启动时,CPU端的内存页会变为失效状态。当CPU做处理时,GPU端的内存页会变为失效状态。这么做的原因是为了保证数据一致性,但有些应用场景不要求这么严格的数据一致性,场景比如CPU和GPU都对同一片地址空间进行读取操作而没有写入操作就不存在数据竞争,CPU和GPU原本能同时进行操作,然而却被UVM子系统却杜绝了这样的并行操作。
此时就需要cudaMemAdvise上场了,它能告知一片地址空间的特性,有了先验信息,driver会在背后做更多的优化。
- A.
cudaMemAdviseSetReadMostly及cudaMemAdviseUnSetReadMostly
这两个是cudaMemAdvise的Flag,用来为某个device设定/解除内存空间ReadMostly的特性,device所指的设备可以有一个只读副本而不发生数据迁移,当两端没有写入时,两个副本的数据是一致的。
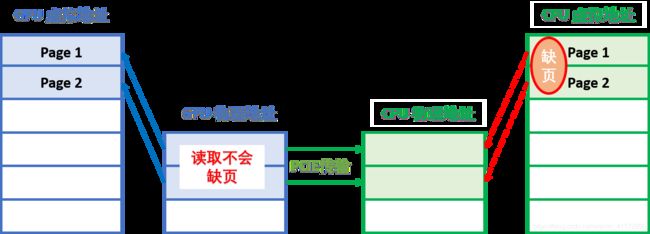
如图所示CPU需要使用地址空间,而此地址空间已经通过cudaMemAdvise设定CPU为cudaMemAdviseSetReadMostly时,CPU产生一个只读副本(copy),而不是数据迁移(migrate)。这样CPU/GPU端依然可以同时读取数据。当有一端写入数据时,对端数据立即失效而只在写入端存在一个副本。
#define GPU_DEVICE 0
{
char * array = nullptr;
cudaMallocManaged(&array, N) //分配内存
fill_data(array);
cudaMemAdvise(array, N, cudaMemAdviseSetReadMostly, GPU_DEVICE); //提示GPU端几乎仅用于读取这片数据
qsort<<<...>>>(array); //GPU page-fault产生read-only副本
//cudaDeviceSynchronize();
use_data(array); //CPU process 没有page-fault.
cudaFree(array);
}
典型用法是配合cudaMemPrefetchAsync使用,这样CPU和GPU都没有缺页中断了,而且可以同时执行。
#define GPU_DEVICE 0
{
char * array = nullptr;
cudaMallocManaged(&array, N) //分配内存
fill_data(array);
cudaMemAdvise(array, N, cudaMemAdviseSetReadMostly, GPU_DEVICE); //提示GPU端几乎仅用于读取这片数据
cudaMemPrefetchAsync(array, N, GPU_DEVICE, NULL); // GPU prefetch
qsort<<<...>>>(array); //GPU 无缺页中断,产生read-only副本
//cudaDeviceSynchronize();
use_data(array); //CPU process 没有page-fault.
cudaFree(array);
}
- B.用
cudaMemAdvisePreferredLocation来指定数据存储位置,数据只在指定设备上一个副本,不发生迁移和拷贝 (Resist Migrations)
不发生迁移,意思是数据仅可以存储在指定的device端,缺页中断时产生到指定device的内存映射,而不复制到本地。(当不能建立地址映射表,如CPU不能访问GPU内存,此时依然会数据迁移)如图所示:
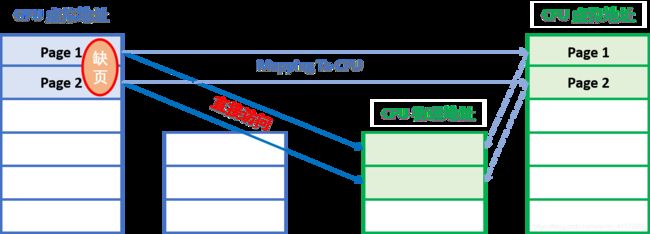
代码如下:
#define GPU_DEVICE 0
{
char * array = nullptr;
cudaMallocManaged(&array, N) //分配内存
//fill_data(array); //也可以uncommit
cudaMemAdvise(array, N, cudaMemAdvisePreferredLocation, GPU_DEVICE); //从此,这片空间仅可以存在CPU上。
qsort<<<...>>>(array); //GPU发生缺页中断,将数据populate到CPU,建立一个访问CPU内存的映射表
cudaDeviceSynchronize();
use_data(array);
cudaFree(array);
}
- C.
cudaMemAdviseSetAccessedBy标志
与cudaMemAdvisePreferredLocation作用相似,都是Resist Migrate。用于GPU访问CPU,或GPU之间访问,地址映射表会立即建立,不用等到发生缺页中断。同时,若数据发生迁移,这其余设备的映射表自动更新。用于不关心数据Location但关心缺页中断影响性能的情况。比如Multi-GPU的Cluster。
四、其他 (TBD)
1.与UM相关的API简介
2.一些CUDA Memory的优化方法
五、参考文献
[1]https://developer.nvidia.com/blog/maximizing-unified-memory-performance-cuda/
[2]https://developer.nvidia.com/blog/beyond-gpu-memory-limits-unified-memory-pascal/
[3]https://developer.nvidia.com/blog/unified-memory-cuda-beginners/
[4]https://zhuanlan.zhihu.com/p/82651065
[5]https://on-demand.gputechconf.com/gtc/2018/presentation/s8430-everything-you-need-to-know-about-unified-memory.pdf
[6]https://developer.download.nvidia.com/video/gputechconf/gtc/2020/presentations/s21819-optimizing-applications-for-nvidia-ampere-gpu-architecture.pdf
[7]https://arxiv.org/pdf/1910.09598.pdf
[8]https://www.olcf.ornl.gov/wp-content/uploads/2018/02/SummitDev_Unified-Memory.pdf