【博弈论笔记】第三章 完全且完美信息动态博弈
文章目录
- 第三章 完全且完美信息动态博弈
-
- 3.1 动态博弈的表示法和特点
- 3.2 策略的可信性和纳什均衡的不稳定问题
-
- 3.2.1 相机选择和策略的可信性问题
- 3.2.2 纳什均衡的不稳定问题
- 3.2.3 逆推归纳法
- 3.3 子博弈和子博弈完美纳什均衡
-
- 3.3.1 子博弈
- 3.3.2 子博弈完美纳什均衡
- 3.4 四个经典动态博弈
-
- 3.4.1 斯塔克博格模型
- 3.4.2 劳资博弈
- 3.4.3 议价博弈
- 3.4.4 委托——代理理论
- 3.5 有同时选择的动态博弈
-
- 3.5.1 标准模型
- 3.5.2 间接融资和挤兑风险
- 3.5.3 国际竞争和最优关税
- 3.6 动态博弈分析的问题和扩展讨论
-
- 3.6.1 逆推归纳法的问题
- 3.6.2 颤抖手均衡和顺推归纳法
- 3.6.3 蜈蚣博弈
- Summary
此部分博弈论笔记参考自经济博弈论(第四版)/谢识予和老师的PPT,是在平时学习中以及期末备考中整理的,主要注重对本章节知识点的梳理以及重点知识的理解,细节和逻辑部分还不是很完善,可能不太适合初学者阅读(看书应该会理解的更明白O(∩_∩)O哈哈~)。现更新到博客上供大家浏览,希望能够帮助到正在学习博弈论的大家。
第三章 完全且完美信息动态博弈
3.1 动态博弈的表示法和特点
定义:博弈方选择策略的行动有先后顺序,而且后行动者可以观察到先行动者的策略选择,并据此作出相应策略选择的博弈。
-
基本概念:
-
阶段:动态博弈中,一个博弈方的一次选择,或几个博弃方的一次同时选择, 称为博弈的一个“阶段” 。动态博弈至少有两个阶段。
-
表示方法:扩展形:节点代表博弈方、从节点出发的线段代表可选策略、及线段终端处的数组代表得益的形式,来表示动态博弈的方法称为“扩展形” 。下图为例:

-
-
特点
-
特点1:动态博弈的策略和结果与静态博弈不同
-
附加概念
行动——动态博弈的一个阶段中,博弈方的一次对策选择。
策略——动态博弈的所有阶段中, 博弈方选择行动的完整计划。
-
-
特点2:动态博弈具有非对称性
- 先行动方可能拥有先行的主动权——先行优势。
- 后行动方能观察到先行动方的行为,可以相机抉择——后发制人优势。
-
3.2 策略的可信性和纳什均衡的不稳定问题
3.2.1 相机选择和策略的可信性问题
动态博弈中博弈方的策略是他们自己预先设定的。在各个博弈阶段针对各种情况的相应行为选择的计划,这些策略实际上并没有强制力,而且实施起来有一个过程,因此只要有符合博弈方自己眼前利益的机会,他们完全可以在博弈过程中改变计划。这种情况叫做动态博弈中的“相机选择”问题。
例:开金矿博弈
甲开采价值4千万元的金矿,缺1千万资金,想说服乙投资,许诺采到金子后对半分成。

在不同的法律环境下有不同的策略可信性,因此就有了不同的相机选择:

结论
- (1)动态博弃中,博弈方会相机选择,即根据不同阶段的情况灵活做出决策
- (2)动态博弃中, 博弃方的策略选择和博弈结果,与策略可信性密切相关
- (3)策略的可信性是动态博弈分析的核心问题之一
3.2.2 纳什均衡的不稳定问题
在法律保障不足时(如下图所示):
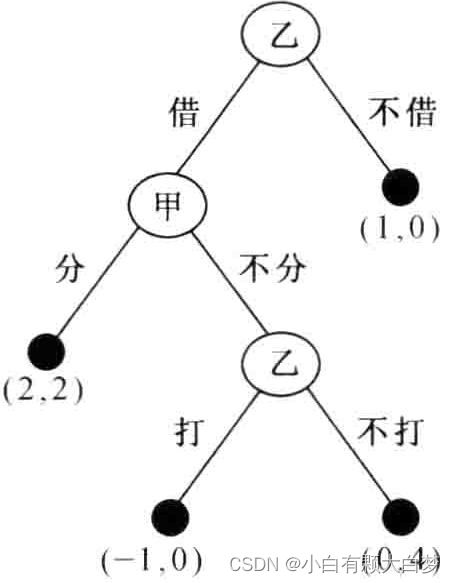
此前的纳什均衡(借;打;分)(这种情况仍算是一个纳什均衡,给定其中一方的策略时,单独偏离对自己都是不利的)会变化成(不借),这是因为包含不可信的承诺威胁,乙第三阶段的打官司无法真正实施。
纳什均衡在动态博弈中可能缺乏稳定性的根源在于他不能排除博弈方策略中可能包含的不可信行为设定。
3.2.3 逆推归纳法
从动态博弈最后一个阶段博弈方的行为开始分析,逐步倒推回前一个阶段相应博弈方的行为分析,一直倒推至第一个阶段的分析方法,称为“逆推归纳法”。
如下图所示,就是从最后分析,乙选择不打,就把这个节点提上去
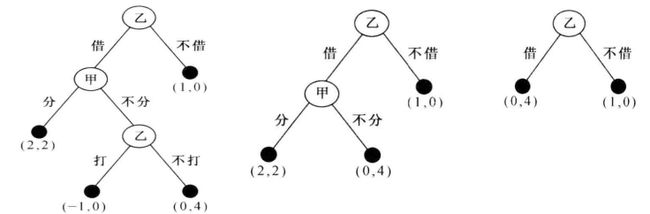
通过逆推,把多阶段动态博弈简化为一系列单方博弃,然后对单方博弈进行分析。之后归纳各博弈方在各阶段的选择,就能得到各博弈方在整个动态博弈中的完整策略。
3.3 子博弈和子博弈完美纳什均衡
由于纳什均衡在动态博恋博弈中不能排除不可信的行为选择, 不是真正具有稳定性的均衡概念, 因此需要发展新的均衡概念以满足动态博弈分析的需要。
3.3.1 子博弈
由一个动态博弈第一阶段以后的某阶段开始的后续博弈阶段构成,有初始信息集和进行博弈所需的全部信息,能够自成一个博弈的原博弈组成部分,称为原动态博弈的一个“子博弈” 。
-
首先子博弈不能包括原博弈的第一个阶段,这也意味着动态博弈本身不是自己的子博弈。
-
其次子博弈必须有一个明确的初始信息集,意味着子博弈不能分割任何信息集,有多节点信息集不完美信息博弈可能不存在子博弈(例如好天气坏天气博弈)
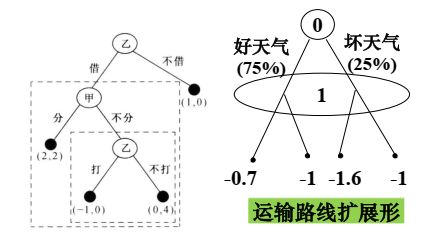
在开金矿博弈中,每层虚线框代表了一级子博弈,因此开金矿博弈第三阶段是原博弈的“二级子博弈”
3.3.2 子博弈完美纳什均衡
如果一个完全且完美信息动态博弈的一个策略组合,满足在整个动态博弈及它的所有子博弈中都构成纳什均衡,那么该均衡就是一个“子博弈完美纳什均衡” 。
子博弈完美纳什均衡与纳什均衡的根本不同之处 , 也是这个概念的价值所在, 就在于它能够排除均衡策略中不可信的威胁或承诺, 因此是真正稳定的。子博弈完美纳什均衡能排除不可信行为选择的原因是,虽然包含不可信行为选择的策略组合可以构成整个博率的纳什均衡, 但不可信行为至少在某些子博弈中无法构成纳什均衡, 因此会被排除出去。
在法律保障力度不足的开金矿博弈中:
(借,打,分)是整个博弈的纳什均衡(任何一方都不能改变自己的策略而得益,甲选择分了,如果不分而乙选择打,则收益下降,因此仍是纳什均衡),但在第二级子博弈中并不是纳什均衡(因为乙选择打在这个小的子博弈里来说就不是纳什均衡),因此不是“子博弈完美纳什均衡”。
这也就验证了子博弈完美纳什均衡能够排除不可信的威胁
而(不借,不打;不分)才是子博弈完美纳什均衡。
此时第二阶段甲的选择节点,第三阶段乙的选择节点为“不在选择路径上”,两博弈方策略中在这两个节点的选择为“不在均衡路径上的选择”
All in all 子博弈完美纳什均衡也是纳什均衡, 是比纳什均衡更强的均衡概念, 且是动态博弈分析最核心的概念。动态博弈分析必须先找出它们的子博弈完美纳什均衡, 求动态博弈子博弈完美纳什均衡的基本方法 正是逆推归纳法。逆推归纳法从动态博弈的最后一级子博弈开始, 逐步找博弈方在各级子博弈中的最优选择。逆推归纳法确定的各博弈方策略不可能包含不可信的行为选择, 找出的均衡策略组合一定是子博弈完美纳什均衡。
3.4 四个经典动态博弈
子博弈完美纳什均衡和逆推归纳法是分析动态博弈的两大工具。
3.4.1 斯塔克博格模型
两个寡头产量博弈,较强的一方先选择产量,较弱的一方后选择,后者知道前者选择
两者的利润函数为: u 1 = u 1 ( q 1 , q 2 ) = q 1 P ( Q ) − c 1 q 1 = q 1 [ 8 − ( q 1 + q 1 ) ] − 2 q 1 = 6 q 1 − q 1 q 2 − q 1 2 \begin{array}{c}u_1=u_1(q_1,q_2)=q_1P(Q)-c_1q_1=q_1[8-(q_1+q_1)]-2q_1=6q_1-q_1q_2-q_1^2\end{array} u1=u1(q1,q2)=q1P(Q)−c1q1=q1[8−(q1+q1)]−2q1=6q1−q1q2−q12
u 2 = u 2 ( q 1 , q 2 ) = q 2 P ( Q ) − c 2 q 2 = q 2 [ 8 − ( q 1 + q 2 ) ] − 2 q 2 = 6 q 2 − q 1 q 2 − q 2 2 u_2=u_2(q_1,q_2)=q_2P({Q})-c_2 q_2=q_2[8-(q_1+q_2)]-2q_2 =6q_2-q_1q_2-q_2^2 u2=u2(q1,q2)=q2P(Q)−c2q2=q2[8−(q1+q2)]−2q2=6q2−q1q2−q22
逆推法决策,厂商2: u 2 ′ = 6 − q 1 − 2 q 2 = 0 u_2^{'}=6-q_1-2q_2=0 u2′=6−q1−2q2=0,即 q 2 = 6 − q 1 2 q_2=\frac{6-q_1}{2} q2=26−q1
与古诺模型求解方法不同:前者联立方程;后者代入法
厂商1知道厂商2会这么选,因此 u 1 = 3 q 1 − q 1 2 2 u_1=3q_1-\frac{q_1^{2}}{2} u1=3q1−2q12,可得 q 1 ∗ = 3 q_1^{*}=3 q1∗=3,因此 q 2 ∗ = 1.5 q_2^{*}=1.5 q2∗=1.5,得益为(4.5,2.25)
与古诺模型比较,其产量为(2,2)得益为(4,4),可见厂商1有先行优势
3.4.2 劳资博弈
工会决定工资W,厂商决定雇佣人数L
工会的效用函数 u = u ( W , L ) u=u(W, L) u=u(W,L) ,厂商的利润函数为 $π = π (W,L) = R(L) -W× L $
根据逆推法,厂商先决策 π ′ = R ( L ) ′ − W = 0 \pi^{'}=R(L)^{'} -W=0 π′=R(L)′−W=0 得出人数和工资的关系
之后工会根据厂商的L选择W,最大化效用
3.4.3 议价博弈
-
三回合议价博弈
甲乙分1万元,博弈规则: (1) 甲先提方案,乙接受则议价结束,拒绝则由乙提方案;(2)若甲接受,议价结束,拒绝则由甲提新方案,乙必须接受;(3) 议价每多进行一回合,双方分得现金产生消耗,消耗系数为δ (eg:0.98)

根据逆推归纳:第三回合是确定的
从第二回合开始,乙的最优策略,使甲的收益不低于 δ 2 S \delta^2 S δ2S,即 δ S 2 = δ 2 S \delta S_2= \delta^2 S δS2=δ2S,所以 S 2 = δ S S_2=\delta S S2=δS,同时要使 δ ( 10000 - S 2 ) ≥ δ 2 ( 10000 - S ) \delta(10000\text{-}S_2)\geq\delta^2(10000\text{-}S) δ(10000-S2)≥δ2(10000-S),显然成立。
第一回合时甲知道乙的策略,所以给乙 δ ( 10000 − S 2 ) \delta(10000-S_2) δ(10000−S2),即 δ ( 10000 − δ S ) \delta(10000-\delta S) δ(10000−δS),甲剩余 10000 ( 1 − δ ) + δ 2 S 10000(1-\delta)+\delta^2 S 10000(1−δ)+δ2S
对于子博弈纳什均衡进一步分析:第三回合甲的方案乙必须接受——》 S=10000 ,所以甲得益 S 1 = 10000 ( 1 − δ + δ 2 ) \mathbf{S}_1=10000(1-\delta+\delta^2) S1=10000(1−δ+δ2)
最终: [ 10000 ( 1 − δ + δ 2 ) , 10000 ( δ − δ 2 ) ] [10000(1-\delta+\delta^2),10000(\delta-\delta^2)] [10000(1−δ+δ2),10000(δ−δ2)]
① δ——》 1,甲接近得到全部得益,乙的得益接近0;
② δ——》 0,甲接近得到全部利益,乙的得益接近0;
③ δ = 0.5,甲得到7500元,乙可分得最多的2500元, δ=0.5 给乙带来的议价能力最大;甲具有优势的原因 : A. 先行优势; B. 结束博弈的特权
-
无限回合议价博弈
双方极其聪明理性,必有逆推归纳解,得益(S,10000-S) 也就是甲第一回合提出S,乙接受
Shaked和 Sutton(1984)证明:从第三回合开始的无限回合博弈的结果,与从第一回合开始的博弈结果相同 ——》甲第三回合提出S,乙接受,得益(S, 1000-S)
最终: S = S 1 = 10000 − 10000 δ + δ 2 S S = 10000 1 + δ \mathbf{S}=\mathbf{S}_1={1}0{000}-10000\mathbf{\delta}+\mathbf{\delta}^2\mathbf{S}\quad\mathbf{S}=\frac{1\mathbf{0}\mathbf{000}}{1+\mathbf{\delta}} S=S1=10000−10000δ+δ2SS=1+δ10000
甲的得益是 δ 的减函数,乙的得益是 δ 的增函数;δ=0,甲独占所有得益; δ =1,双方平分得益。
3.4.4 委托——代理理论
委托代理人关系的一个问题是代理人工作成果的确定性问题,即代理人的工作成果是否完全由其工作情况所确定
-
无不确定性的委托——代理博弈
代理人的工作成果取决于努力程度,无意外风险导致工作成果减少。委托人可根据工作成果掌握代理人的工作情况。
三阶段委托 :
① 代理人努力时双方得益 R(E):委托人的较高收益 ;w(E):代理人的较高报酬;E:代理人努力工作的成本
② 代理人偷懒时双方得益 R(S):委托人的较低收益 ;w(S):代理人的较低报酬; S:代理人偷懒工作的成本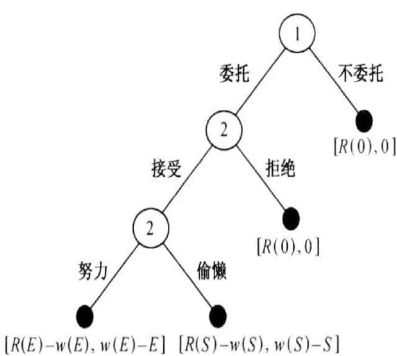
采用逆推归纳法:
第三阶段:必须满足w(E)-E>w(S)-S ,代理人才会选择努力,这一约束称为激励相容约束。
经济意义:只有当代理人得到的报酬,在其偷懒所得报酬的基础上有一个补偿,代理人才选择努力。
第二阶段:代理人参与委托的条件: w ( E ) − E > 0 , w ( S ) − S > 0 w(E)-E>0,w(S)-S>0 w(E)−E>0,w(S)−S>0,这称为参与约束
第一阶段:
A. 代理人努力时委托人的选择: R(E)-w(E) > R(0)——委托,R(E)-w(E) < R(0)——不委托
B. 代理人偷懒时委托人的选择: R(S)-w(S) > R(0)——委托,R(S)-w(S) < R(0)——不委托数值例子:

-
“有不确定性但可监督” 的委托——代理博弈
代理人的努力和成果之间不再完全一致,但通常是根据工作情况而不是工作结果来支付报酬,这意味着产出不确定性地风险完全由委托人承担。
假设:
两种可能产出:(20, 10)
代理人努力——》 产出20的概率0.9,产出10的概率0.1
代理人偷懒——》 产出20的概率0.1,产出10的概率0.9其他与上述题相同。
在表示时引入博弈方0天气
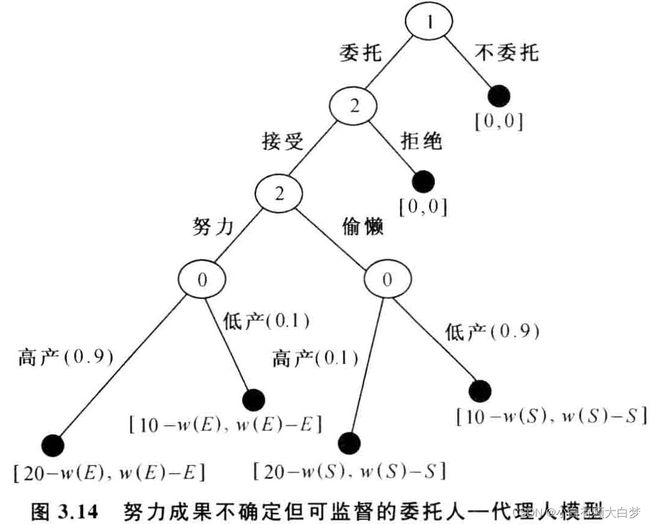
仍可由逆推归纳法进行分析:
参与激励约束:w(E)-E>w(S)-S——》 努力 ; w(S)-S>w(E)-E——》 偷懒
委托约束:w(E)-E>0和w(S)-S>0——》接受委托
代理人努力,委托人得益:0.9× [20-w(E)]+0.1× [10-w(E)]>0 ⟶ \longrightarrow ⟶ 委托,否则不委托
代理人偷懒,委托人得益:0.1× [20-w(S)]+0.9× [10-w(S)] ⟶ \longrightarrow ⟶ 委托
此时的根据仍是代理人的工作情况而不是工作结果,只要代理人努力了就发高工资
具体要根据数值例子才能进一步分析
-
“有不确定性且不可监督” 的委托——代理博弈
委托人无法完全监督代理人的工作,只能根据工作成果而不是工作情况发工资,不确定性风险由双方承担。
(0上的这个大圆圈是表示委托人不清楚博弈是走哪个分支,委托人只知道工作成果,属于不完全信息)
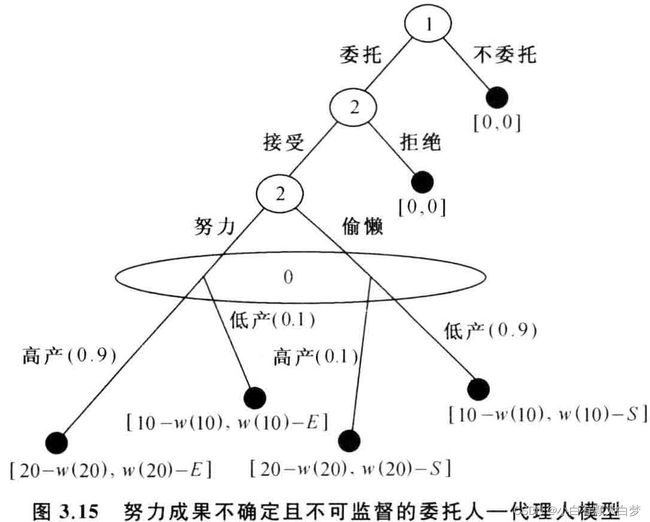
逆推归纳法:
第三阶段:激励相容约束
0.9 × [ w ( 20 ) − E ] + 0.1 × [ w ( 10 ) − E ] > 0.1 × [ w ( 20 ) − S ] + 0.9 × [ w ( 10 ) − S ] 0.9× [w(20)-E]+0.1× [w(10)-E] > 0.1 × [w(20)-S]+0.9× [w(10)-S] 0.9×[w(20)−E]+0.1×[w(10)−E]>0.1×[w(20)−S]+0.9×[w(10)−S]
第二阶段:在第三阶段代理人选择努力的情况下, 倒推回第二阶段, 参与约束为
0.9 × [ w ( 20 ) − E ] + 0.1 × [ w ( 10 ) − E ] > 0 0.9× [w(20)-E]+0.1× [w(10)-E] >0 0.9×[w(20)−E]+0.1×[w(10)−E]>0
第一阶段:虽然委托人无法看到代理人第三阶段的选择, 但对代理人的决策思路是清楚的。给定模型中的 E 、 S 、 E 、 S 、 E、S、 w ( 20 ) 、 w ( 10 ) w(20) 、 w(10) w(20)、w(10) 的数值或公式, 委托人完全清楚代理人是否会选择努力。 假设委托人判断代理人会选择努力, 那么根据模型设定, 委托人的期望得委托条件:
0.9 × [ 20 − w ( 20 ) ] + 0.1 × [ 10 − w ( 10 ) ] > 0 ⟶ 委托 0.9× [20-w(20)]+0.1× [10-w(10) ] > 0 \longrightarrow委托 0.9×[20−w(20)]+0.1×[10−w(10)]>0⟶委托
激励机制设计的关键:确定w(20)和w(10)
-
“选择报酬和连续努力水平” 的委托
在有不确定性且不可监督的情况下,委托人可选择薪酬制度(也就是薪酬函数),代理人在连续区间选择努力水平时。
假设:
① 代理人不接受委托时会有其他得益: U U U
② 代理人努力的成本是努力程度的单调递增函数: C = C ( e ) C=C(e) C=C(e)③ 代理人的努力程度 e e e分布在连续区间
④ 产出R是e的随机函数: R = R ( e ) R=R(e) R=R(e)
⑤ 委托人据R支付报酬: w = w ( R ) = w [ R ( e ) ] w=w(R)=w[R(e)] w=w(R)=w[R(e)]得益函数为:
委托人得益函数: R − w = R ( e ) − w [ R ( e ) ] R-w=R(e)-w[R(e)] R−w=R(e)−w[R(e)]
代理人得益函数: w − C = w [ R ( e ) ] − C ( e ) w-C=w[R(e)]-C(e) w−C=w[R(e)]−C(e)逆推归纳法:
第二阶段:参与约束: w [ R ( e ) ] − C ( e ) ≥ U w[R(e)]-C(e) ≥ U w[R(e)]−C(e)≥U
第一阶段:委托人得益函数: R ( e ) − w [ R ( e ) ] = R ( e ) − C ( e ) − U R(e)-w[R(e)] = R(e)-C(e)-U R(e)−w[R(e)]=R(e)−C(e)−U
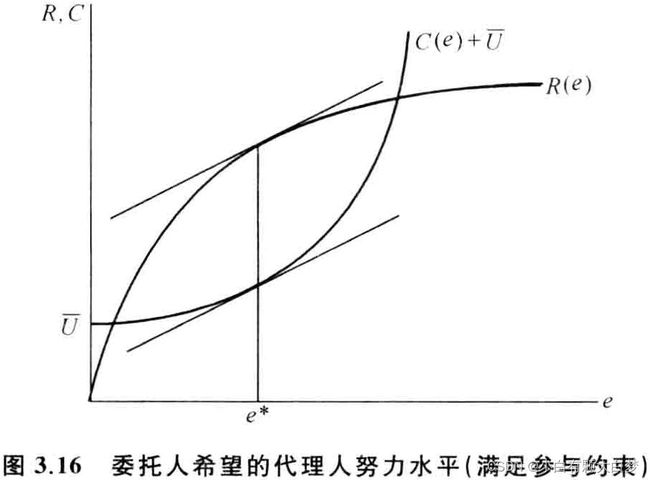
在图像上表示委托人得益最大化,也就是两条曲线斜率相等的点
委托人按“参与约束” 和“激励相容约束”设计报酬函数,即$w[R(e*)]-C(e*) ≥ w[R(e)]-C(e) $
-
例子:店主和店员
R——商店的利润, e——店员的努力程度
R = R ( e ) = 4 e + η R=R(e)=4e+η R=R(e)=4e+η, η η η——均值为0的随机扰动项,店员的成本函数: C = C ( e ) = e 2 C=C(e)=e^2 C=C(e)=e2,店员接受工作的机会成本: U = 1 U=1 U=1,店员工资 = 固定工资 + 利润提成: S = A + B [ R ( e ) ] = A + B [ 4 e + η ] S=A+B[R(e)]=A+B[4e+η] S=A+B[R(e)]=A+B[4e+η]对于得益:
店主得益函数: 4 e + η − A − B [ 4 e + η ] = 4 ( 1 − B ) e + ( 1 − B ) η − A 4e+ η -A-B[4e+ η]=4(1-B)e+(1-B) η -A 4e+η−A−B[4e+η]=4(1−B)e+(1−B)η−A
店主期望得益: 4 ( 1 − B ) e − A 4(1-B)e-A 4(1−B)e−A
店员得益函数: A + B [ 4 e + η ] − e 2 A+B[4e+η]-e^2 A+B[4e+η]−e2
店员期望得益: A + 4 B e − e 2 A+4Be- e^2 A+4Be−e2逆推归纳法:第二阶段参与约束:期望得益: A + 4 B e − e 2 > = 1 A+4Be- e^2>=1 A+4Be−e2>=1,
M a x ( A + 4 B e − e 2 ) —— > e ∗ = 2 B Max(A+4Be- e^2)——> e^*=2B Max(A+4Be−e2)——>e∗=2B 含义:店员最佳努力水平取决于利润提成的比例B。
店主的选择:
首先须满足店员参与约束条件的下限: A + B [ 4 e + η ] − e 2 = 1 A+B[4e+η]-e^2=1 A+B[4e+η]−e2=1
其次最大化店主得益: ( 4 e + η ) – A − B [ 4 e + η ] = 4 e + η − e 2 − 1 (4e+ η) – {A-B[4e+ η]} = 4e+ η -e^2-1 (4e+η)–A−B[4e+η]=4e+η−e2−1,期望得益: 4 e − e 2 − 1 4e-e^2-1 4e−e2−1
为使店主得益最大,店员努力程度 e ∗ ∗ = 2 e^{**}=2 e∗∗=2 ,代入 e ∗ = 2 B e^*=2B e∗=2B 得 B = 1 B=1 B=1,之后得 A = − 3 A=-3 A=−3
含义:全部利润给店员作提成,店主不发固定工资,向店员收取3单位的承包费或租金,即承包制、 租赁经营制
子博弈完美纳什均衡:(承包或租赁经营制;接受;努力工作)
3.5 有同时选择的动态博弈
至少某个阶段存在两个或多个博弈方同时选择的动态博弈模型
3.5.1 标准模型
(1) 有4个博弈方:博弈方1、 2、 3、 4;
(2) 第一阶段:博弈方1和2同时在策略集合A1和A2中选择a1和a2;
(3) 第二阶段:博弈方3和4看到博弈方1和2的选择后,在策略集合A3和A4中同时选择a3和a4;
(4) 各博弈方得益都取决于所有博弈方的策略a1、 a2、a3、 a4。
3.5.2 间接融资和挤兑风险
假设:
(1) 银行发放一笔2万元贷款,以20%年利率吸引存款
(2) 两储户各有1万元,存1年定期,银行可向企业贷款
(3) 若储户提前取款,银行提前收款,企业投资无法完成,只能收回80%本钱(1.6万)
(4) 若一个储户提前取款,银行偿还其全部本金(1万),另一储户只能取回余款(0.6万)
(5) 若两客户同时提前取款,平分收回的资金(0.8,0.8)
对于储户而言:

根据逆推归纳法,第二阶段中,两个纯策略纳什均衡: (提前,提前), (到期,到期),帕累托上策均衡: (到期,到期),风险上策均衡: (提前,提前) 。
在第一阶段中,若第二阶段的博弈结果: (到期, 到期) ,帕累托上策均衡: (存款, 存款) ,间接融资运行良好。

若第二阶段的博弈结果: (提前,提前) ,帕累托上策均衡: (不存, 不存), 风险上策均衡: (不存, 不存) ,间接融资运行不好。
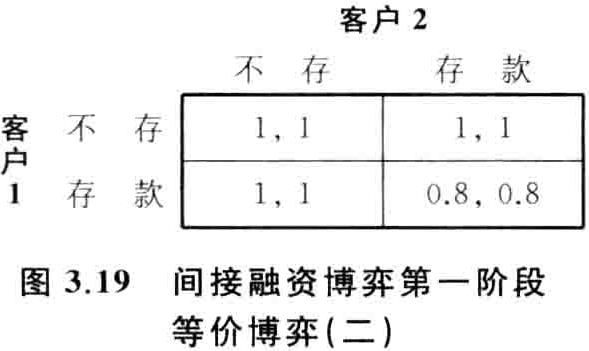
So 存款保险制度——避免低效率均衡
3.5.3 国际竞争和最优关税
假设:
① 4个博弈方:国家1和国家2决定进口关税率;
② 两国分别有:企业1和企业2;
③ 两国消费者既可购买国货,也可购买进口货,国货和进口货完全替代;
④ 国家 i 市场上的商品总量:$ Q_i$
⑤ 市场出清价格: P i = a − Q i P_i = a - Q_i Pi=a−Qi
⑥ 企业 i 生产: h i h_i hi供内销, e i e_i ei供出口——》 Q i = h i + e j Q_i = h_i + e_j Qi=hi+ej
⑦ 企业边际成本= c,固定成本= 0——》 企业 i i i生产成本= c ( h i + e i ) c (h_i + e_i) c(hi+ei)
⑧ 国家 j j j 的关税率为 t j t_j tj——》 企业i出口产品的总成本 = c e i + t j e i =ce_i + t_je_i =cei+tjei , 内销产品的成本为 c h i ch_i chi
两国先同时制定关税率 t 1 和 t 2 t_1和 t_2 t1和t2——》 两企业同时决定内销和出口产量 h 1 、 e 1 和 h 2 、 e 2 h_1、 e_1和 h_2、 e_2 h1、e1和h2、e2
企业的得益:
π i = π i ( t i , t j , h i , h j , e i , e j ) = P i h i + P j e i − c ( h i + e i ) − t j e i = [ a − ( h i + e j ) ] h i + [ a − ( e i + h j ) ] e i − c ( h i + e i ) − t j e i \begin{array}{c}\pi_i=\pi_i(t_i,t_j,h_i,h_j,e_i,e_j)=P_ih_i+P_j e_i-c(h_i+e_i)-t_j e_i\\ =\begin{bmatrix}a-(h_i+e_j)\end{bmatrix}h_i+\begin{bmatrix}a-(e_i+h_j)\end{bmatrix}e_i-c(h_i+e_i)-t_j e_i\end{array} πi=πi(ti,tj,hi,hj,ei,ej)=Pihi+Pjei−c(hi+ei)−tjei=[a−(hi+ej)]hi+[a−(ei+hj)]ei−c(hi+ei)−tjei
国家得益——社会总福利:消费者剩余+本国企业利润+国家关税收入
ω i = w i ( t i , t j , h i , h j , e i , e j ) = 1 2 ( h i + e j ) 2 + π i + t i e j \begin{array}{c}\omega_i&=w_i(t_i,t_j,h_i,h_j,e_i,e_j)\\[6pt]&=\dfrac{1}{2}(h_i+e_j)^2+\pi_i+t_ie_j\end{array} ωi=wi(ti,tj,hi,hj,ei,ej)=21(hi+ej)2+πi+tiej
为了使企业利益最大化:Max(国内市场利润 + 国外市场利润)
max h i ⩾ 0 ∣ h i [ a − ( h i + e i ∗ ) − c ] ∣ max e i ⩾ 0 ∣ e i [ a − ( e i + h j ∗ ) − c ] − t j e i ∣ \max\limits_{h_i\geqslant0}\lvert h_i\big[a-(h_i+e^*_i)-c\big]\rvert\\ \max\limits_{e_i\geqslant0}\lvert e_i\big[a-(e_i+h^*_j\big)-c\big]-t_j e_i\big\rvert hi⩾0max∣hi[a−(hi+ei∗)−c]∣ei⩾0max∣ei[a−(ei+hj∗)−c]−tjei
可得:
国内市场最优供给量 : h i ⋆ = 1 2 ( a − e j ⋆ − c ) h\overset{\star}{_i}=\dfrac{1}{2}(a-e\overset{\star}{_j}-c) hi⋆=21(a−ej⋆−c)
国外市场最优供给量 : e i ∗ = 1 2 ( a − h j ∗ − c − t j ) e\overset{*}{_i}=\dfrac{1}{2}(a-h\overset{*}{_j}-c-t_j) ei∗=21(a−hj∗−c−tj)
两企业( i=1, 2 和 j=2, 1 ), 四个方程求解纳什均衡:
h i ∗ = a − c + t i 3 e i ∗ = a − c − 2 t j 3 h_{i}^{*}=\dfrac{a-c+t_i}{3}\quad e_{i}^{*}=\dfrac{a-c-2t_j}{3} hi∗=3a−c+tiei∗=3a−c−2tj
他们的内外销量只取决于两国征收的关税, h i ∗ h^*_i hi∗是 t i t_i ti的增函数, e i ∗ e^*_i ei∗是 t j t_j tj的减函数。说明关税具有保护本国企业,打击外国企业的作用。
3.6 动态博弈分析的问题和扩展讨论
3.6.1 逆推归纳法的问题
-
只能分析明确设定的博弈
- 要求博弈的结构非常清楚
- 各博弈方了解博弈结构
- 相互知道对方了解博弈结构
-
不能分析太复杂的动态博弈
- 要选择的路径过多时很难使用
-
不能分析两条路径上得益相同的博弈
-
对博弈方的理性要求太高
栗:

子博弈完美纳什均衡:博弃方1第三阶段选T,博弈方2第二阶段选N,博弃方1第一阶段选L(23阶段无法达到)
但如果1第一阶段选择R,2在第二阶段出于理性选择时,他会考虑如果自己选了N,1是否会有足够的理性去选择T,博弈方2对博弈方1在第一阶段犯错的判断不同,对策也就不同。(博弈方1犯错性质:偶然错误?理性程度很低?故意犯错误?)
3.6.2 颤抖手均衡和顺推归纳法
理解博弈方犯错性质的两种方法:颤抖手均衡和顺推归纳法
-
颤抖手均衡思想:把博弈方各阶段的错误看作互不相关的小概率事件。
(1)一个颤抖手均衡的博弈

此时的纳什均衡:(D,L),(U,R)
对于(D,L):博弈方1:拟选D——》 考虑博弈方2可能偏离L而选R——》 博弈方1得益减少为2——》 博弈方1的最佳选择为U。博弈方2:考虑博弈方1的思路后选R——》 (D, L)不稳定。
对于(U,R):博弈方1:拟选U——》 不管博弈方2是否会偏离R——》博弈方1都没必要偏离U;博弈方2:拟选R——》 博弈方1偏离U的概率很小(不超过2/3)——》博弈方2不会改变策略。
(U,R) 对小概率的偶然偏差具有稳定性——“颤抖手均衡”,而(D,L) 不是“颤抖手均衡”
(2) 两个颤抖手均衡的博弈
对博弈方1的得益稍作修改:

对于(D,L):博弈方1:拟选D——》 只要判断博弃方2偏离L的概率很小(不超过20%)——》 博弃方1会坚持选D;博弈方2:考虑博弈方1的思路后选L——》 (D, L) 是颤抖手均衡;
(U, R)也是颤抖手均衡。
(3)一个策略组合成为颤抖手均衡的条件:
- 必须是一个纳什均衡
- 不能包含任何“弱劣策略”
- 弱劣策略——即使博弈方偏离该策略, 也不会对该博弈方造成损失的策略。((1)中博弈方1的策略D)
- 包含“弱劣策略”的纳什均衡经不起任何非理性的扰动,缺乏在有限理性条件下的稳定性
(4)动态博弈中的颤抖手均衡

两条子博弈完美纳什均衡路径:
- 博弃方1选L结束博弈(第一步主动权在博弈方1)
- R—N—T—V
第二条不是颤抖手均衡路径,若博弈方1选R,博弈方2怀疑其理性,可能选M。博弈方1考虑到博弈方2的想法,就不会选R.
(5)改动后的动态博弈中的颤抖手均衡

R—N—T—V是唯一的子博弃完美纳什均衡路径,也是颤抖手均衡。
(3,3)会吸引每个博弈方坚持到最后,只要每个博弃方偏离均衡路径的概率比较小,博究方都会坚持。
(6)根据颤抖手均衡分析原问题
若博弈方1第一阶段错选R,根据颤抖手均衡思想:把博弈方各阶段的错误看作互不相关的小概率事件。博弃方2根据颤抖手均衡思想,还是会选择N。
-
顺推归纳法——解决有意犯错
根据博弃方前面阶段的行为,包括偏离特定均衡路径的行为,推断他们的思路并为后面阶段博弈提供依据的分析方法,称为“顺推归纳法”。 (偏离路径可能是故意的)
(1)Van Damme 博弈(1989)
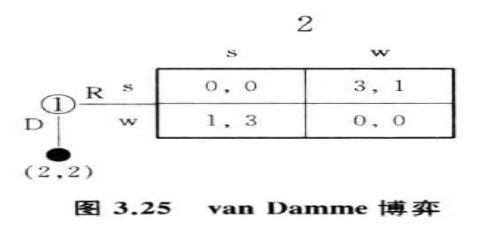
若博弈进行到第二阶段,该如何解释?
- 解释1: 博弃方1在第一阶段选择偶然出错
- 解释2:博弃方1在第一阶段有意错选R
解释2比解释1更有说服力:当博弈方1选择了R之后,Rw是一个严格下策(相较于Rs和D),他不会选,他在第二阶段的最佳选择是w,若博弃方1相信博弃方2的分析能力,可预期自己选R后,博弈方2选w,实现 (s, w) 更大收益。
此时(Rs,w)是稳定的子博弃完美纳什均衡和颤抖手均衡。
3.6.3 蜈蚣博弈
多阶段动态博弈:博弈方1和2轮流选择,共198个阶段。

如果根据倒推归纳法:
(1)最后一个阶段 最佳选择 ⟶ \longrightarrow ⟶ d,得益(98, 101)
(2)倒数第二个阶段 博弃方1选择D,得益(99, 99)
(3)倒数第三个阶段:博弃方2选d
(4) ……., 博弈方1在第一阶段选D结束博弈, 得益(1,1)
逆推归纳法分析结果与人们的直觉很不一致,但具体让人模拟实验的结果表明,实验中人们不会按照逆推归纳法去做,而倾向于一直往后走,与人们的直觉类似。
理论与实际矛盾的根源 :
① 实际中博弈方会期望更大的潜在利益——冒险投机
② 实际中会试探合作精神
③ 实际中试探合作会互动
分析:而博弃越临近结束阶段——》 双方合作的潜在利益越小——》逆推归纳法的逻辑会在某个时刻起作用,但很难预测逆推归纳法的逻辑究竟在什么时候起作用。
此分析得出的推论:阶段数减少到3-5个,开始时合作的可能性小得多。因为选择合作的潜在利益减少了许多,而承担的初始风险确实同样的。
Summary
此部分用于对所学内容的快速梳理记忆
- 基本概念介绍(容易理解)
- 行动——动态博弈的一个阶段中,博弈方的一次对策选择
- 策略——动态博弈的所有阶段中, 博弈方选择行动的完整计划。
-
策略的可信性和纳什均衡的不稳定问题
- 相机选择:指的是博弈方在博弈过程中可能会根据眼前利益(某些策略不具有可信性时)改变计划,如开金矿博弈
- 纳什均衡的不稳定性:由于策略不可信,纳什均衡会发生变化
- 逆推归纳法:通过逆推,把多阶段动态博弈简化为一系列单方博弃
-
子博弈和子博弈完美纳什均衡
- 子博弈的概念:不包括第一个阶段,必须有一个明确的初始信息集
- 子博弈完美纳什均衡:在每一个子博弈中都是纳什均衡,克服了策略不可信的问题
-
四个经典模型
-
斯塔克博弈:类似于古诺,只是有了选择的先后之分
-
劳资博弈:工会后决定工资W,厂商先决定雇佣人数L
-
议价博弈
- 三回合议价:逆推归纳法
- 无限回合:从第三回合开始的无限回合博弈的结果,与从第一回合开始的博弈结果相同
-
委托代理理论
- 无不确定性的委托
- 有不确定性但可监督的委托(店员努力了店的收益不是必然高,但仍根据店员努力情况发工资)
- 有不确定性且不可监督(根据店的收益发工资)
- “选择报酬和连续努力水平” 的委托
以上四种类型主要从激励相容约束(店员努力要比不努力收益高)、参与约束(店员接受了工作不会有负收益)、委托约束(店主委托后净收益不能为负)这三方面分析。
-
-
有同时选择的动态博弈
- 融资和挤兑模型
- 关税模型:先两两联立,再代入求解
-
动态博弈拓展分析方法
- 逆推归纳法存在的问题:要求很高
- 分析犯错性质的两种方法:
- 颤抖手平衡:存在条件:首先是纳什均衡,其次不能包括任何弱劣策略(博弈方偏离了不会造成损失),对于概率较小的偶然偏差来说具有稳定性的被称为颤抖手均衡
- 顺推归纳法:有意偏离均衡路径
- 蜈蚣博弈:用逆推归纳法行不通,双方为了更大的潜在利益互相试探合作。
All in all ,用子博弈完美纳什均衡和逆推归纳法进行分析,加上拓展的几种方法