fabric智能合约
1.智能合约整体介绍
1)fabric架构
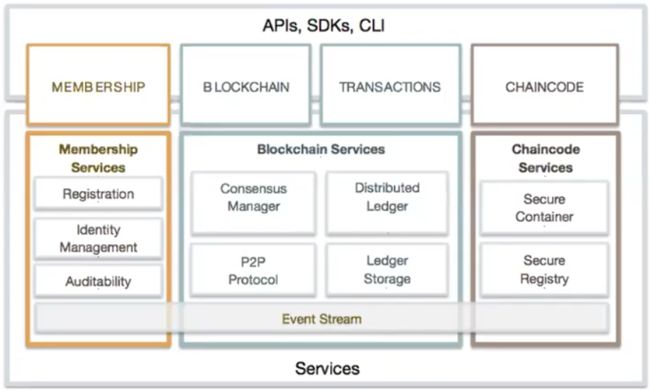
fabric架构分为两个部分,应用层和区块链底层。
对于应用层来说,fabric提供了基于GRPC协议的API来于区块链进行通讯,并且在API的基础上封装了支持go语言、Java语言、node.js等SDK,方便客户端的调用。由于区块链是分布式的账本,并且交易需要进行共识之后才能够进行上链,那么这样一笔交易从开始到结束,耗时就会很长,客户端很可能没接收到响应就已经超时了,因此传统的同步方式就显得很不合适。
fabric提供提供了一套异步的处理的事件机制来解决这个问题。其实不止fabric,国内许多框架像Facebook、BCOS也有事件监听这一机制。在fabric中,客户端通过注册一个事件,当这个事件完成之后,就会通知客户端完成的结果,客户端此时再进行相应的结果处理,这样就解决同步超时的问题。
fabric底层框架分为三个部分。成员服务(Membership services)。区块链服务(Blockchain services)和链码服务(Chaincode services)。成员服务包括三个组件,登录、注册、身份认证、管理和审计。在一个无权限的区块链中,每个节点都是对等的,都可以随意提交交易到链上。fabric的成员服务通过PKI体系和分布式的技术,把fabric变成了一个带权限的区块链。成员服务一共包含三种证书。分别是用于登录注册的用户证书,交易签名验签的交易证书和加密传输的TLS证书。每笔交易在区块链中都会进行签名认证,只有认证过的交易才能够继续进行下一个流程。
链码服务包含两个组件,安全容器和安全注册组件。fabric提供了一套独立于节点的沙盒机制chaincode容器,方便开发不同语言的链码。chaincode容器和peer容器之间是通过gRPC协议进行通讯的。fabric智能合约是和其他的区块链底层框架不同,其他大多数的区块链底层框架都使用了EVM就是solidity语言,但是fabric现在支持通用语言进行编写智能合约。这一点对于开发者来说降低了很大的学习成本,不用单独去学习solid语言,可以直接使用现有的技能来开发智能合约,然后进行链上的操作。
区块链服务提供了一个分布式账本的平台,包含共识管理、分布式账本、点对点网络和分类存储。fabric的共识机制是可插拔的。fabric共识机制包含Kafka、etcdraft等共识。fabric在1.0版本之前,有用过拜占庭共识,但是在后来的版本中去掉了。官方,是有说在以后的版本中还会推出拜占庭共识。fabric框架与其他区块链框架共识方面不同的地方在于,fabric中的区块是通过独立于节点记账节点的orderer节点来产生的。
fabric的链上数据分为两个部分,Blockchain和State。Blockchain就是账本文件,是一系列串联起来的区块,以文件的形式存储在节点中的。这个文件记录了历史区块的交易,不同通道账本存储在不同的文件中。所以它是以物理的方式隔离在不同的文件夹中的,一般都存在于节点的production下目录下。State就是世界状态,记录了账本的最新状态,是以key-value的形式来存储的数据库。
fabric中支持levelDB和couchDB这2种非关系型数据库。区块账本文件占用的空间大小是会不断上涨的,因为它记录了区块的历史。但是世界状态就不一定了,世界状态中的数据是可以进行CRUD操作的,就是我们平时操作关系型数据库MySQL里边的创建(Create)、读取(Read)、更新(Update) 和删除(Delete)的操作。那么这也就解释了一个问题,为什么在fabric链码中会有删除的交易,因为它删除的是状态数据库中的数据,而节点账本中的区块是会不断累加的。BSN最近发布了一个商用版本,大家会发现计费中有存储容量这一项,那么BSN是怎么进行应用容量计算的呢?DSN中记录的存储是节点的账本文件所占的磁盘容量和状态数据库DB所占的磁盘容量之和。
接下来我们看一下这个p2p协议。fabric中有两种网络通讯协议,一种是gossip,一种是gRPC。gossip是在一个组织内部通过这个协议来进行报文交流的。在排序节点和锚节点,也就是主节点之间,是通过gRPC来进行通讯的。
2)交易流程
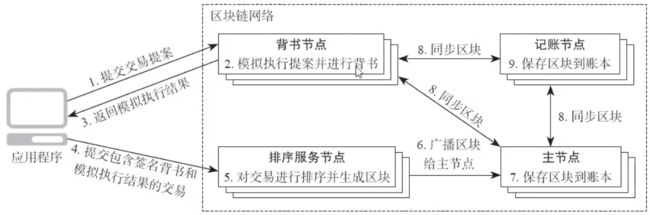
接着看一下交易(Transactions)。交易分为两个部分,一部分是部署,一部分是调用。我们可以通过客户端或者SDK来实现交易的发送,部署的交易包含链码安装,链码实例化和链码升级等操作。这幅图展示了fabric的交易流程。一笔交易从产生到记录到区块和账本中,一共分为九个步骤。
第一步是提交交易提案。在提交交易提案之前,我们应该有一个类似enroll的过程,完成之后我们才能对一笔交易进行签名,签名完成之后再把提案发送给背书。背书节点验证完签名并且在本地模拟交易成功以后,会把背书的结果返回给客户端。客户端在收集到足够的背书结果之后,可以把交易发送给order节点进行排序打块儿。出块之后会把出块的结果通过gRPC的协议发送给主节点。主节点验证完交易之后,会把结果记录到本地的账本中,并且在同一组织内向其他节点分发区块,其他节点验证交易完成之后,也会把结果存储到本地的账本中。****。
3)chaincode
- 简介
-
Fabric中智能合约又称链码(chaincode),是用计算机语言描述合约条款、交易的条件、交易的业务逻辑等,通过调用链码实现交易的自动执行和对账本数据的操作,是应用程序与底层交互的媒介。换句话说,是一段对业务的描述和一种对数据的约束。
-
链码在一个独立于peer节点的docker容器中执行,通过grpc与背书节点进行通讯
-
一个chaincode的账本是与其他chaincode相互隔离的,不能直接访问,只有在相同网络中的chaincode获取相应的许可以后才能调用其他chaincode来访问其他账本。
-
链码支持多种语言编写,包括golang、java、node.js。
chaincode分为两个部分,一部分是chaincode开发,另一部分是chaincode操作。开发就是我们要需要编写代码,操作则是部署相关的,像安装链码、实例化链码、升级链码等。
- chaincode开发
chaincode开发可进一步分为系统链码和用户链码两种。系统链码是不以单独的docker来运行的,它运行在节点进程中。在1.2以后的版本中,系统链码有三个,LSCC、CSCC和QSCC。LSCC是用来处理生命周期相关的功能,我们部署合约的时候,会有一些链码的操作,像链码安装、链码实例化和链码升级等就是通过调用LSCC来实现的,这个链码和chaincode的部署操作息息相关。CSCC负责处理peer侧chaincode的配置。QSCC能够提供账本查询的API,能够通过QSCC来实现区块的查询和交易查询的功能。在1.2版本之前,还有两种系统链码叫ESCC和VSCC。一种是背书系统链码,一种是验证系统链码。
Chaincode包括两种链码(系统链码和用户链码)。
系统链码运行在节点进程中,不以单独的docker运行,包括LSCC、CSCC、QSCC。
- LSCC:生命周期系统链码(life cycle chaincode),处理生命周期相关的功能
- CSCC:配置系统链码(configuration system chaincode),处理peer侧channel的配置
- QSCC:查询系统链码(query system chaincode),提供账本查询API,比如获取区块及交易等
系统链码不用我们用户进行开发,它是fabric需要的一种机制,我们要开发的是用户链码。
用户链码都必须实现chaincode接口,链码包含:Init,Invoke两个方法。其中Init方法会在chaincode接收到instantiate或者upgrade交易时被调用,使chaincode执行必要的初始化操作,包括初始化应用的状态。
Invoke方法接收和处理链下业务系统调用事务处理提案,其参数包含调用的链码程序中函数的名称和具体业务处理数据参数,即在Invoke中根据不同的方法参数调用其他分支处理响应的业务,可以简单理解为链码方法的入口。
- chaincode操作
chaincode的操作就是chaincode部署。当chaincode开发完成或者需要升级时,需要进行chaincode部署。chaincode操作贯穿chaincode的整个生命周期,包含打包(package)、安装(install)、实例化(instantiate)、更新(upgrade)、停止和启动(stop and start)。在安装并实例化成功chaincode之后,就可以调用chaincode中的方法与账本进行交互。

官方并没有实现停止和启动这两个生命周期,那我们的停止操作需要怎么做呢?官方建议是,我们可以通过移除chaincode容器和每个背书节点,删除安装包来停止容器。具体的操作就是通过docker的命令来删除所有主机或者虚拟机上peer节点进行启动的chaincode容器,随后从每个背书节点删除掉安装包就可以了。
2.智能合约开发
1)使用Java开发智能合约
Java语言的链码需要两部分内容,一部分是构建工具,另一部分就是我们写的业务链代码。
Java链码支持两种构建工具gradle和maven。两种构建工具都需要如下三个步骤:
- 添加插件:遮蔽方式的FatJar
- 指定mainClass路径
- 添加fabric-chaincode相关依赖
添加的插件叫FatJar,是把所有的依赖包都打包到一个jar中。 FatJar有三种打包方式,分别是非遮蔽方式(Unshaded)、遮蔽方式(Shaded)和嵌套方式(Jar of Jars)。非遮蔽方式对于是相对于遮蔽方式来说的,非遮蔽方法会把所有的包里的文件都加到一个目录里,然后再打包到同一个jar包中,但是这种情况对于复杂应用可能会碰到同名类相互嵌套的问题。嵌套方法就是在jar包里嵌套其他的jar包,这个方法可以避免同名包名覆盖的问题,但是这个方法不被JVM来支持,原生不支持,因为JDK提供的class loader仅支持装载嵌套包嵌套包的class文件。遮蔽方法会把依赖包中的类路径修改到某个组路径下,这样就可以在一定程度上避免同名类相互遮蔽、相互覆盖的问题,最终发布的jar也不会带入依赖冲突问题给下游。
添加完这个依赖后,在chaincode的实例化或者更新的过程中,会将这个chaincode打包为一个包含所有依赖的jar。然后fabric通过这个all in one的jar来启动一个独立于peer之外的容器。刚刚我们提到过fabric用户链码是独立于peer存在的,然后系统链码是运行在节点进程中的。
Java chaincode常用方法:

2)使用go语言开发智能合约
- 依赖包
- “github.com/hyperledger/fabric/core/chaincode/shim”
- “github.com/hyperledger/fabric/protos/peer”
shim 包为链码提供了 API 用来访问/操作数据状态、事务上下文和调用其他链代码;
peer 包提供了链码执行后的响应信息;
shim.ChaincodeStubInterface提供的方法来读取和修改账本的状态;
peer.Response:封装的响应信息
- chaicode接口
- 参数解析:将传过来的一些参数信息进行一些解析
- 链码互操作:调用不同的智能合约
- 状态操作:提供了一些对数据库状态的操作,比如增加、删除、修改、查询
- 链码事件:提供了一些事件的注册
- 交易信息:交易信息获取,比如获取chainID
- 其他
go chaincode常用方法:

3.开发建议
链码的执行是一个分布式的系统,在多个节点隔离执行,也就是说同一笔交易在整个区块链网络中,会对该交易执行很多次,执行的次数取决于背书的策略的选择,比如说选择这条链上的所有节点都要执行,也可以选择某一个组织的某一个节点上执行。这样有一个结果就是,不管选用哪种方式,它最终执行的结果都必须是相同的。因为客户端会去比较,从不同节点去做模拟交易的结果如果不一样的话,这笔交易就不会给排序节点发送,这样的话,这笔交易就算失败。
那哪些情况会导致这种执行结果不一致呢?一是不稳定的外部依赖,二是随机函数,三是系统的时间。就比如说你要用到外部的一些第三方依赖,可能它不太稳定,或者说这个节点它就不能和外网进行联通,这样的话就会有一些问题,它就是执行不成功。随机函数就更好理解了,如果你选择的是在这条链上的所有节点都要达成共识的话,它在每一个节点上执行的时候,它的随机函数产生的结果肯定都不会不一致,这样的话也是不行的。还有一个就是系统的时间,各个节点,如果节点多的话,它的时间有可能就会存在一些差别,这样的话它提交交易的时候也是不会成功的。
链码编写禁忌:
- 不稳定的外部依赖
- 随机函数
- 系统时间
下面就是介绍一下我们在开发过程中的一些建议。一是必须要校验所有链码方法的参数信息,你比如说要校验参数的个数,另外一个比如说要含一个用户信息,比如说用户的名称,用户名,比如说他对应的一些性别啊,这些信息做一些必要校验,比如说有些是可以为空的话,就无需校验,但是有些它的类型数据是否为空,这些都需要做一些校验。二是不要在init方法中做大量的数据化初始操作,因为在链码的实例化或者升级的过程中只调用一次它,如果初始化大量的数据的话,可能会超时或者失败,直接就提交不成功。三是引用了第三方包的话,需要使用vendor管理第三方引用的一些包,如果不使用这个管理,把这些包也打上去的话,在去合约部署的时候,可能会要去下载这些第三方包,这样的话可能下载不下来,或者是什么原因也会导致他部署失败。四是必须在根目录打成zip包。
链码编写规范:
- 校验所有链码方法参数信息
- 不要在Init方法中大量初始化数据
- 需要使用govendor管理引用第三方包
- 发布服务时,链码包打包时进入项目根目录进行打包,格式为.zip
然后还有一些就是在那个合约的开发过程中需要的一些注意的地方,K值的定义就是。所有的业务系统里边的数据都存在一个数据库中,并且以KY6的形式存储,可能存在就是说不同业务的K值是相同的情况,这样的话就是后者去提交,会把前者的信息给覆盖掉。然后是有一个什么解决方案,就是用不同的业务。来给他加个前缀,然后来作为他的一些K。你比如说用户信息和角色信息,这个是很常用的一些信息,然后它的标识可能会存在是相同的。如果直接用他的标识来存,用作为他的K来存储的话,就会有一些,比如说你用户叫001。然后角色K对应的K值也是001,这样的话它就会存储角色的,角色的话它会把用户信息给覆盖掉。这样的话就是在不同的业务上加上它对应的一些标识,作为他的前缀。比如说用户。就叫USER001,然后角色就叫肉001,这样的话就会避免这些问题。还有一个就是根据配置进行模糊查询的时候。这个跟咱们那个传统数据库里边的那些查询是一样的。比如说这两个。表达式就是执行的查询的语句。前者。这个就是查询的,就是包含了所有K中包含user的一些数据。然后以及前面加个监控号,这种的话,它就是只查询已优的开头的数据。还有一些是需要注意的,就是一些特殊符号需要去做一些转译,比如说英文的小括号。中括号,大括号点,还有那种斜杠,反斜杠都要去做一些转移。第三个呢,说一下那个关于索引的创建。传统的话就是合约的话就是创建数据库,创建索引的话有四种方式,第一种就是命令行,然后直接敲命令,然后去执行,去创建。第二个就是CDB中的话,就是在数据库的这个页面上去做一些。页面上可以看到的一些操作添加。然后还有就是通过HTTP发送,方法为get或者body为杰森格式的包文。然后第四个就是放置在合约中链
链码开发的注意事项:
关于key的定义
- 描述:所有业务数据都存在与一个数据库中,并存储方式是以key-value的形式存储,可能存在不同业务的key值相同的情况,后者保存会覆盖前者信息。
- 解决方案:在不同的业务key值添加前缀
- 示例:用户和角色他们的标识相同,如果以标识作为key存储时,后者保存会覆盖前者信息;但是如果用户:user_用户标识,角色:role_角色标识,这样存储就会避免这个问题
关于根据key值模糊查询
描述:根据key查询同一个业务数据时
解决方案:查询语句使用正则表达式进行查询的
{\“_id\”:{\“$regex”:“user_.*”}检索key中只要含有"user"的数据
{“id":{“$regex\”:\"^user.*\”}检索key以"user"开头的数据
注意:
正则表达式:特殊符号转义关于浮点数计算
关于链码索引
创建索引的4种方式
命令行
couchdb web交互页面点击"All Documents"右边的加号
http发送方法为get、body为json格式的报文
放置在链码中在链码安装更新的时候创建
在main.go的同级目录下创建文件META-INF\statedb\couchdb\indexes在该indexes目录下创建.json文件,文件名随便定,文件个数没有限制。
编辑该json文件,格式如下:
{“index”:{“fields”:[“fileld”]},“ddoc”:“fileldodex”,“name”:“fileld-json-index”,type":“json”}在fabric环境中安装链码。此时couchdb数据库中已经添加了刚刚的索引区块,可以成功执行排序语句
关于跨链调用(InvokeChaincode)
- 由于链码名称和channel名称事先未知,跨链调用时尽量将这些作为函数参数传入链码