焕新老方法 BUTD?WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation 论文阅读笔记
焕新老方法 BUTD?WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- Top-down 方法
- Bottom-up 方法
- 四、方法
-
- 4.1 整体框架
- 4.2 互补的特征提取 Complementary Feature Interaction (CFI)
-
- 用于 Bottom-up 的 Top-down
- 用于 Top-down 的 Bottom-up
- 4.3 高斯得分整合 Gaussian Scoring Integration (GSI)
-
- 分布预测
- 得分采样
- 结果整合
- 五、实验
-
- 5.1 实验步骤
- 5.2 定量分析
-
- 主要的结果
- 不同整合策略的结果
- 特征交互的有效性
- 不同模型结合的互补有效性
- 5.2 定性分析
- 六、结论
写在前面
新的一周快结束了,继续撸代码,做实验中…,但是这周的博文还是继续来了呢~
这篇文章标题很有吸引力,蕴含 2017 年一种用于 VQA 的很爆火的框架:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering,原因在于斩获了 2017 VQA challenge 的冠军,而后开创了两年的 follow。本篇文章不知道与 BUTD 有何关联呢?且听我慢慢道来。
- 论文地址:WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation
- 代码地址:暂未提供,摘要说了将会开源
- 收录于:ICRA 2023
一、Abstract
首先指出 top-down (自顶向下 TD) 和 bottom-up (自下而上 BU) 的方法是解决指代分割的两种主流方式,但同时都有缺陷:TD 由于缺少细粒度的多模态对齐会造成 Polar Negative (PN) 错误(?这是啥);BU 由于缺乏目标的先验信息会造成 Inferior Positive (IP) 错误 (?这又是啥)。而这两种方法在解决错误上是互补的,但直接组合会阻碍模型推理。于是本文提出 Win-win Cooperation (WiCo) ,利用这两种方法的互补性在多模态的交互和整合上实现双向提升。对于多模态交互,提出 Complementary Feature Interaction (CFI) 来提供细粒度的信息到 BU 分支,用于互补信息增强。对于多模态整合,提出 Gaussian Scoring Integration (GSI) 来建模两个分支的高斯性能分布,并采用分布的置信度得分对整合的结果进行加权。实验结果表明 WiCo 效果很好。
二、引言
首先说明 Referring image segmentation (RIS) 指代图像分割的定义。其次目前的方法可以分为两类:top-down (自顶向下 TD) 和 bottom-up (自下而上 BU) 。TD 首先计算由预训练的目标检测器得出的区域 proposals,然后和输入的语言 query 进行跨模态对齐,最后解码和检索出最高置信度得分的区域 proposal 作为分割结果。BT 方法计算每个像素和 query 间的细粒度跨模态对齐,然后解码出相关目标的像素。

根据对上图的观察,TD 和 BU 的方法存在两类错误:Polar Negative (PN) :预测与 GT 完全无关;Inferior Positive (IP) :预测的 mask 与 GT 的重合度不高( IoU ∈ [ 0.5 , 0.8 ] \text{IoU}\in[0.5,0.8] IoU∈[0.5,0.8])。
为分析上述情况原因,绘制了 TD 和 BU 的 IoU 分布:
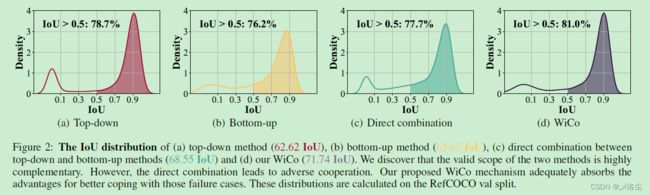
将分布曲线划分为两部分:正样本集(IoU>0.5)和负样本集(IoU<0.5)。由于先验信息抑制了 IP 样本,所以 TP 的正样本集合精度比 BT 方法更高。但由于缺乏细粒度的跨模态对齐,TP 方法更容易输出 PN 样本。于是结合这两种方法的优势,理论上能够实现很好的效果。但是直接结合是不行滴,于是本文提出 Win-win CoopEration (WiCo) ,以一种自适应的方式结合 TD 和 BU 分支。
WiCo 包含两个模块:Complementary Feature Interaction (CFI) 和 Gaussian Scoring Integration (GSI)。CFI 旨在执行两个分支间的交互,用于补偿 TD 分支中细粒度信息的缺乏以及 BU 分支中目标的先验信息。GSI 旨在建模 TD 和 BU 分支的高斯性能分布,通过在分布中采用置信度得分来整合两个分支的结果。本文贡献总结如下:
- 当面对 PN 和 IP 错误的情况下,通过分析一些 TD 和 BU 方法,发现这两种方法存在互补性。
- 提出 WiCo 来充分利用 TD 和 BU 方法的特点,在多模态交互和整合上进行互补。
- 大量的实验表明效果很好。
三、相关工作
Top-down 方法
MAttNet、NMTree、CAC。
Bottom-up 方法
Vision transformer (ViT) 等一系列工作。
四、方法
4.1 整体框架

如上图所示,WiCo 能够兼容任意的 TD 和 BU 方法。其网络由三部分组成:TD 分支、BU 分支 和 “Interaction then Integration”。TD 分支用于部署 TD 方法,BU 分支用于部署 BU 方法,Interaction then Integration 是 WiCo 的关键,旨在建立 TD 和 BU 分支的联系来实现双向提升的效果。
TD 类型的方法本质上是跨模态匹配网络。首先利用预训练的检测器和跨模态匹配网络得到实例 masks M = { m 1 ∈ { 0 , 1 } H × W , m 2 , . . . , m n } \mathcal{M}=\{m^1\in\{0,1\}^{H\times W},m^2,...,m^n\} M={m1∈{0,1}H×W,m2,...,mn}、跨模态实例 embedding E = { E i 1 ∈ R C , E i 2 , . . . , E i n } \mathcal{E}=\{E_i^1\in\mathbb{R}^C,E_i^2,...,E_i^n\} E={Ei1∈RC,Ei2,...,Ein} 和跨模态对齐得分 S = { s 1 , s 2 , . . . , s n } S= \{s^1,s^2,...,s^n\} S={s1,s2,...,sn}。一般情况下,TD 分支输出实例三元组集合 { M , E , S } = { ( m 1 , E i 1 , s 1 ) , ( m 2 , E i 2 , s 2 ) , . . . , ( m n , E i n , s n ) } \{\mathcal{M},\mathcal{E},S\}=\{(m^1,E_i^1,s^1),(m^2,E_i^2,s^2),...,(m^n,E_i^n,s^n)\} {M,E,S}={(m1,Ei1,s1),(m2,Ei2,s2),...,(mn,Ein,sn)},从这一集合提取出的分割结果 P t d P_{td} Ptd 可表示为:
P t d = m argmax ( S ) ∗ S argmax ( S ) P_{td}=m^{\text{argmax}(\mathcal{S})}*S^{\text{argmax}(\mathcal{S})} Ptd=margmax(S)∗Sargmax(S)其中 P t d P_{td} Ptd 为分割的 logits 结果,二分类分割结果为 m argmax ( S ) m^{\text{argmax}}(\mathcal{S}) margmax(S)。
BU 方法本质是跨模态融合网络,旨在编码图像和文本的跨模态像素 embedding 空间 E p ∈ R C × H × W E_p\in\mathbb{R}^{C\times H\times W} Ep∈RC×H×W,并将其解码为分割结果 P b u ∈ R H × W P_{bu} \in \mathbb{R}^{H \times W} Pbu∈RH×W,用公式表示为:
P b u = σ ( Linear ( E p ) ) P_{bu}=\sigma(\operatorname{Linear}(E_p)) Pbu=σ(Linear(Ep))其中 Linear \operatorname{Linear} Linear 为 1 × 1 1\times1 1×1 卷积,用于 logits 的回归, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 为 sigmoid 函数, P b u P_{bu} Pbu 为生成的概率图,通过预测 τ \tau τ 来提取分割结果( τ ( P b u > τ ) \tau(P_{bu}>\tau) τ(Pbu>τ))。一般情况下,BU 分支输出跨模态的像素 embedding 和分割结果。
Interaction then Integration 旨在实现 TD 和 BU 方法的互补性融合。其中 BU 和 TP 分支的输出作为 CFI 的输入来更新特征和结果,而更新后的结果则输入到 GSI 中。
4.2 互补的特征提取 Complementary Feature Interaction (CFI)
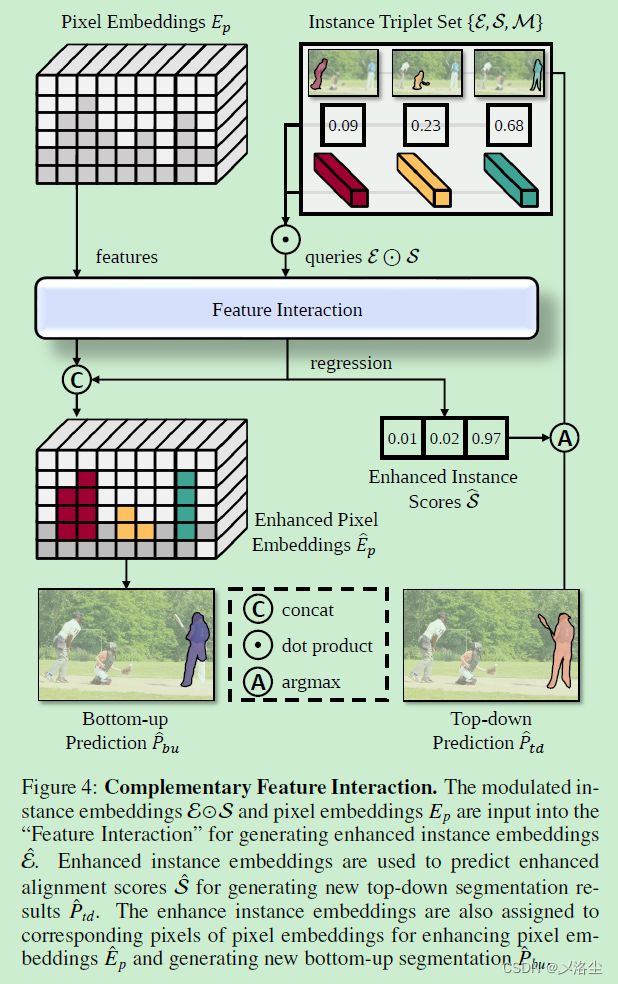
假设已经从 BU 分支中得到像素 embedding E p E_p Ep 和实例三元组集合 { M , E , S } \{\mathcal{M},\mathcal{E},S\} {M,E,S},CFI 旨在增强像素 embedding 的细粒度信息和实例三元组集合的目标信息。
用于 Bottom-up 的 Top-down
为增强 E p E_p Ep,将行像素 embeddings 赋值到每一个增强的实例 embedding E ^ \hat{\mathcal{E}} E^ 对应的像素上,生成增强的像素 embeddings E ^ p \hat E_p E^p:
E ^ p { x , y } = concat ( E p { x , y } ; ∑ j = 1 n 1 { m j [ x , y ] = 1 } E ^ i j ) \hat{E}_{p}^{\{x,y\}}=\operatorname{concat}(E_{p}^{\{x,y\}};\sum_{j=1}^{n}\mathbb{1}_{\{m^j[x,y]=1\}}\hat{E}_{i}^{j}) E^p{x,y}=concat(Ep{x,y};j=1∑n1{mj[x,y]=1}E^ij)其中 E p { x , y } E_{p}^{\{x,y\}} Ep{x,y} 表示像素位置为 ( x , y ) (x,y) (x,y) 处的增强像素 embedding, E i j {E}_{i}^{j} Eij 为第 i i i 个实例的增强实例 embeddings。 1 { m j [ x , y ] = 1 } \mathbb{1}_{\{m^j[x,y]=1\}} 1{mj[x,y]=1} 为索引函数,当 ( x , y ) (x,y) (x,y) 处的第 j j j 个 mask 值为 1 时,其值等于 1,反之为 0。增强的像素 embeddings 之后被解码为新的 BU 结果:
P ^ b u = signoid ( Linear ( E ^ p ) ) \hat{P}_{bu}=\operatorname{signoid}(\operatorname{Linear}(\hat{E}_p)) P^bu=signoid(Linear(E^p))其中 Linear \operatorname{Linear} Linear 共享上一个 Linear \operatorname{Linear} Linear 的权重。
用于 Top-down 的 Bottom-up
为增强实例 embeddings E \mathcal{E} E,采用视觉 Transformer 解码器作为 Feature Interaction 模块,通过细粒度的像素 embedding 信息 E p E_{p} Ep 来精炼实例 embeddings。在输入之前,实例 embeddings 通过跨模态的对齐得分 S \mathcal{S} S 来保留跨模态信息:
E ⊙ S = { E p 1 ∗ s 1 , E p 2 ∗ s 2 , . . . , E p n ∗ s n } \mathcal{E}\odot\mathcal{S}=\{E_p^1*s^1,E_p^2*s^2,...,E_p^n*s^n\} E⊙S={Ep1∗s1,Ep2∗s2,...,Epn∗sn}之后 Transformer 解码器将建模后的实例 embedding E ⊙ S \mathcal{E}\odot\mathcal{S} E⊙S 作为 queries 来生成增强的实例 embedding E ^ \hat{\mathcal{E}} E^ 和预测的增强对齐分数 S ^ \hat{\mathcal{S}} S^。最后更新 TD 分支的分割结果:
P ^ t d = m argmax ( S ^ ) ∗ S ^ argmax ( S ^ ) \hat{P}_{td} =m^{\text{argmax}(\hat{S})}*\hat{S}^{\text{argmax}(\hat{S})} P^td=margmax(S^)∗S^argmax(S^)
4.3 高斯得分整合 Gaussian Scoring Integration (GSI)
GSI 的输入为 TP 分支的输出 P ^ t d \hat P_{td} P^td 和 BU 分支的输出 P ^ b u \hat P_{bu} P^bu。GSI 包含三个步骤:分布预测、得分采样以及结果整合。
分布预测
选择高斯分布建模性能分布,根据两个分支的结果和特征来预测均值 μ \mu μ 和标准差 σ \sigma σ:
μ t d , σ t d = split ( MLP ( E ^ i argmax ( S ^ ) ) μ b u , σ b u = split ( MLP ( GAP ( E p ⊙ P ^ b u ) ) ) \begin{gathered} \mu_{td},\sigma_{td} =\operatorname{split}(\operatorname{MLP}(\hat{E}_i^{\operatorname{argmax}(\hat{S})}) \\ \mu_{bu},\sigma_{bu} =\text{split}(\text{MLP}(\text{GAP}(E_p\odot\hat{P}_{bu}))) \end{gathered} μtd,σtd=split(MLP(E^iargmax(S^))μbu,σbu=split(MLP(GAP(Ep⊙P^bu)))其中 MLP ( ⋅ ) \text{MLP}(\cdot) MLP(⋅) 为 3 层全连接层, GAP ( ⋅ ) \text{GAP}(\cdot) GAP(⋅) 为全局平均池化操作, split ( ⋅ ) \text{split}(\cdot) split(⋅) 为通道 split 操作。根据预测的均值和标准差,BUTD 的性能分布为: N ( μ b u , σ b u ) N(\mu_{bu},\sigma_{bu}) N(μbu,σbu) 和 N ( μ t d , σ t d ) N(\mu_{td},\sigma_{td}) N(μtd,σtd)。
得分采样
在性能分布中采样出一个值作为预测的置信度得分。根据不同的优化策略,利用重参数化 trick 来修改采样过程:
IoU t d = μ t d + σ t d ∗ ϵ , ϵ ∼ N ( 0 , I ) IoU b u = μ b u + σ b u ∗ ϵ , ϵ ∼ N ( 0 , I ) \begin{gathered} \text{IoU}_{td} =\mu_{td}+\sigma_{td}*\epsilon,\epsilon\sim\mathcal{N}(0,\mathbf{I}) \\ \text{IoU}_{bu} =\mu_{bu}+\sigma_{bu}*\epsilon,\epsilon\sim\mathcal{N}(0,\mathbf{I}) \end{gathered} IoUtd=μtd+σtd∗ϵ,ϵ∼N(0,I)IoUbu=μbu+σbu∗ϵ,ϵ∼N(0,I)其中 IoU t d \text{IoU}_{td} IoUtd 和 IoU b u \text{IoU}_{bu} IoUbu 表示 TD 和 BU 分支的置信度得分。利用预测的置信度得分和 GT IoU 的 smooth-L1 损失来优化分布预测模型。
结果整合
argmax ( ⋅ ) \text{argmax}(\cdot) argmax(⋅) 在梯度反向回传中是不可微分的操作,于是在训练阶段采用可微分操作进行代替: λ = o n e − h o t ( a r g m a x ( S ^ ) ) + S ^ − s g ( S ^ ) \lambda=\mathrm{one}-\mathrm{hot}(\mathrm{argmax}(\hat{\mathcal{S}}))+\hat{\mathcal{S}}-\mathrm{sg}(\hat{\mathcal{S}}) λ=one−hot(argmax(S^))+S^−sg(S^)
其中 λ ∈ { 0 , 1 } n \lambda\in\{0,1\}^n λ∈{0,1}n 为 最大值的二值索引向量, o n e − h o t ( ⋅ ) \mathrm{one}-\mathrm{hot}(\cdot) one−hot(⋅) 为 one-hot 编码函数, s g ( ⋅ ) \mathrm{sg}(\cdot) sg(⋅) 为阻止梯度的操作。 λ \lambda λ 用于建立 TD 分支 P ^ t d ′ \hat{P}_{t d}^{\prime} P^td′ 的可微分分割结果:
P ^ t d ′ = ∑ i n m j ∗ λ j ∗ s j \hat{P}_{t d}^{\prime} =\sum_i^n m^j*\lambda^j*s^j P^td′=i∑nmj∗λj∗sj其中 n n n 为实例的数量。为得出最后的分割结果,采用置信度得分来计算 BUTD 分支的权重求和:
P ^ = ( P ^ t d ′ ∗ I o U t d + P ^ b u ∗ I o U b u ) / 2 \hat{P}=(\hat{P}^{'}_{td}*\mathrm{IoU}_{td}+\hat{P}_{bu}*\mathrm{IoU}_{bu})/2 P^=(P^td′∗IoUtd+P^bu∗IoUbu)/2
最后的结果 P ^ \hat{P} P^ 在训练阶段用于计算和 GT mask 的分割损失,而在推理阶段经过阈值 τ \tau τ 过滤得到二值 mask。
五、实验
5.1 实验步骤
- 数据集:RefCOCO、RefCOCO+、RefCOCOg;
- TD 分支:MAttNet,Mask2Former (ResNet-50) 作为实例提取器;
- BU 分支:VLT\CRIS\LAVT;
- 评估指标:mask IoU;
- 优化器:AdamW,学习率:1e-5,权重衰减:5e-2.
- 迭代次数:5000;
- GPU:V100;
- Btach:24;
- 二值化阈值 τ = 0.35 \tau=0.35 τ=0.35(噢,这个地方有点意思,一般都是 0.5)。
5.2 定量分析
主要的结果

不同整合策略的结果

特征交互的有效性
同上表 2。
不同模型结合的互补有效性

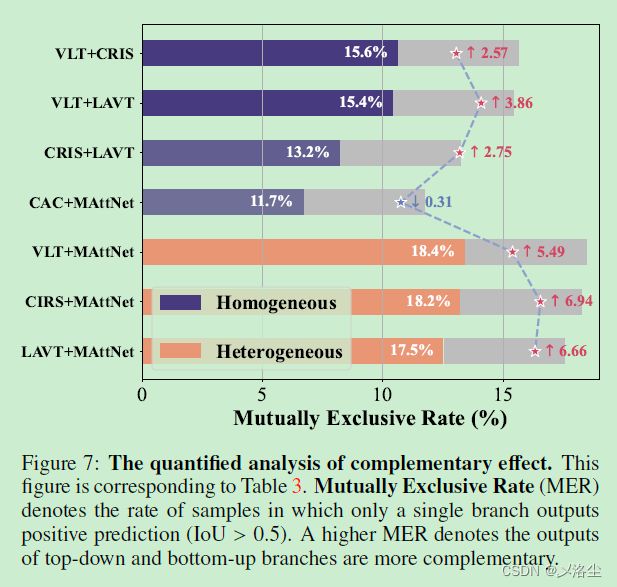
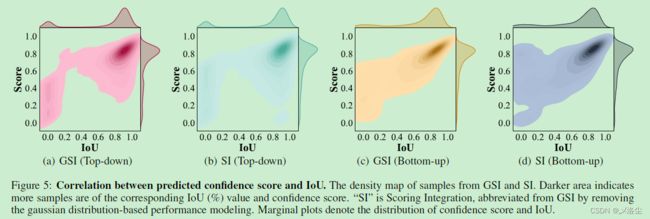
5.2 定性分析

六、结论
现有的 BUTD 方法未能解决 PN 和 IP 错误,但是彼此间能够互补从而更好地处理这两类错误。为充分利用这一互补性,本文遵循 Interaction then Integration 的策略建立 WiCo 机制,从而实现双向提升。具体来说,提出 CFI 使得 TD 分支的先验目标信息和 BU 分支的细粒度信息能够彼此交互,提出 GSI 来建模 BUTD 两分支的性能分布,从而自适应地整合两分支的结果。实验结果表明 WiCo 能够有效提升 BUTD 方法的性能。
写在后面
附录还有一部分内容是关于 IoU 的计算,以及更加的详细对 PN 和 IP 错误的介绍,并用更多的实验进行论证。这篇文章也是立意比较新颖,从 IoU 的角度去定义问题,不知道作者的写作动机是啥,难道就是碰巧做这个实验发现了问题吗?哈哈,希望哪天能碰到作者当面问一下。
回答最初的问题:本篇文章不知道与 BUTD 有何关联呢?原来是结合了 BU 和 TD 的操作,两者当有相似功效。