Flink部署
前言
大家好, 我是上白书妖!
知识源于积累,登峰造极源于自律
今天我根据以前所以学的一些文献,笔记等资料整理出一些小知识点,有不当之处,欢迎各位斧正
Flink部署 (两种模式 )
一 . Standalone模式 (Flink自带的)
① 安装
解压缩 flink-1.7.2-bin-hadoop27-scala_2.11.tgz(如果你两个模式都想试一下就这个压缩包,实际上你要真正搭建独立模式只需要flink-1.7.2后面不需要接hadoop27-scala_2.11的压缩包),进入conf目录中。
1)修改 flink/conf/flink-conf.yaml 文件:
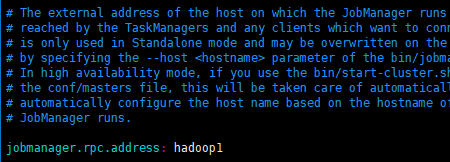
2)修改 /conf/slave文件:
![]()
3)分发给另外两台机子:
![]()
4)启动:
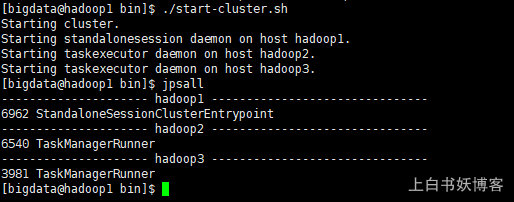
5) 访问http://localhost:8081可以对flink集群和任务进行监控管理。
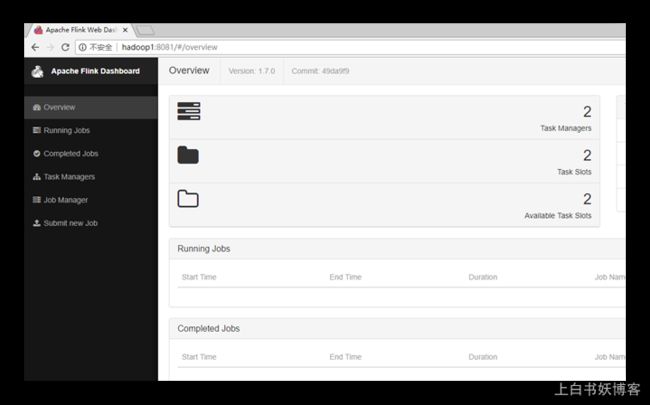
② 提交任务
- 准备数据文件
2) 把含数据文件的文件夹,分发到taskmanage 机器中
![]()
由于读取数据是从本地磁盘读取,实际任务会被分发到taskmanage的机器中,所以要把目标文件分发。
3) 执行程序
./flink run -c com.shangbaishuyao.flink.app.BatchWcApp /ext/flinkTest-1.0-SNAPSHOT.jar --input /applog/flink/input.txt --output /applog/flink/output.csv
4) 到目标文件夹中查看计算结果
注意:计算结果根据会保存到taskmanage的机器下,不会在jobmanage下
5) 在webui控制台查看计算过程
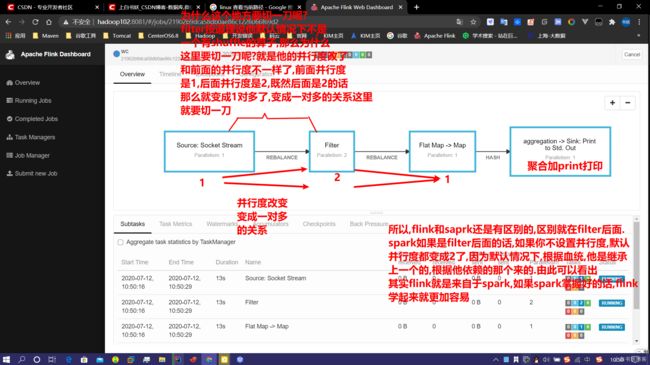
二 . Yarn模式 (yarn模式又有两种情况)
Flink配置概览:
![]()
上白书妖补充:
Flink程序运行在yarn上首先我们得把yarn跑起来,
必须保证在hadoop2.2以上的版本,
而且集群中必须有安装hdfs服务,这个我安装的hadoop里面都是有的,
一开始实现要启动hadoop集群
以Yarn模式部署Flink任务时,
要求Flink是有Hadoop支持的版本,
Hadoop环境需要保证版本在2.2以上,
并且集群中安装有HDFS服务。
Flink Yarn 模式有两种情况:
Session-Cluster 和 Per-Job-Cluster
Flink on Yarn 模式
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster(会话集群)和Per-Job-Cluster模式
什么是Session-Cluster呢?
就是多个job或者多个application共享一份集群资源,共享一份yarn session的进程或者共用一个进程中的资源,那个进程叫yarn session
什么是Per-Job-Cluster呢?
每一个job对应一个yarn session

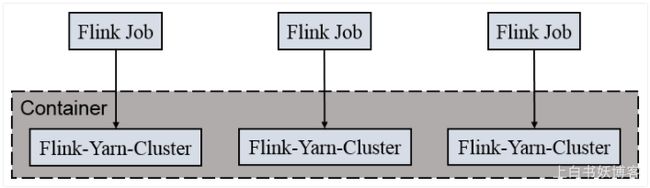
1) Session-cluster 模式:(一个作业是失败很可能影响下一个作业的提交)
一个作业的失败很可能会影响下一个作业的正常提交,因为他一个作业的失败很可能他把所有的资源都占完了,占完了而且你一直都没有停止,没有停止那么其他的作业就无法提交了
如图所示: 五个Flink Job都是跑在一个Flink的yarn session当中的,这个Flink yarn session可以理解为就是一份资源,这个资源从哪里生成来的呢?是从我们的yarn的ResourceManager中生成来的,生成过来之后他启动一个进程,这个进程我们把它称之为叫yarn session的进程,这个yarn session中包含了一些资源,这些资源允许我们的多个flink job共享这个里面的资源去运行;但是有这种情况,什么情况呢?
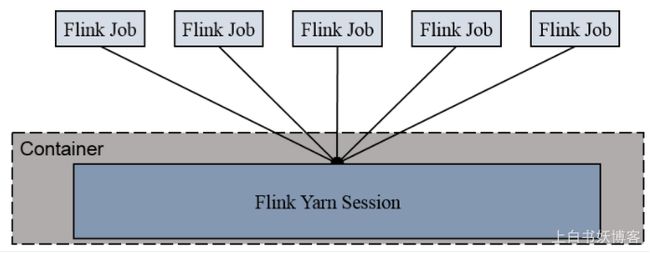
假设我提交两个flink job提交给这一个yarn session之后,发现我yarn session中的共享资源被占完了,就是满了.什么叫满了呢?就是没有空余的slot(槽)(因为我们flink的任务是运行在slot上面的)
如图所示:
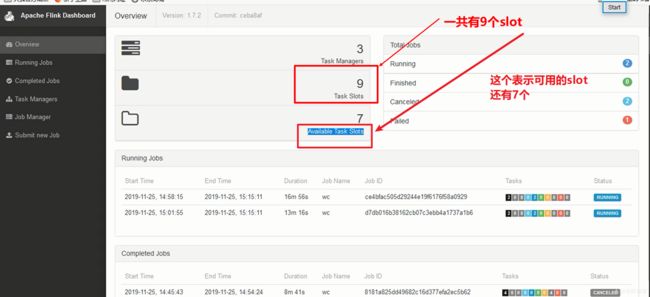
所以,如果我当前yarn session中运行了两个job之后已经没有剩余的slot了,请问后面五个flink job还能提交上去吗?不能,他们会在等待,等待有人释放了slot,然后他们在去抢这些资源======>这就是Session-cluster 模式
2) Per-Job-Cluster模式:(一个作业的失败不会影响下一个作业的提交)
这种模式是每一个job会对应一个yarn session集群,所以这个job所对应的yarn session集群他不会和其他的job共享的,他是相互独立的,只要你这台机器总的资源是够大的,那么你就可以源源不断的一直提交新的job,所以两种模式,这一种用的最多,也是最方便的
如图所示:
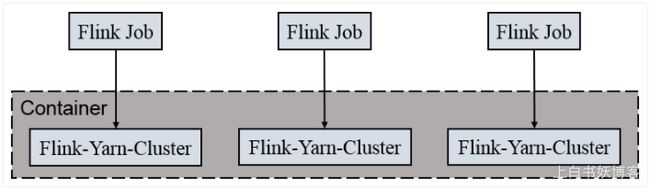
为什么说Per-Job-Cluster模式最方便呢?
因为session-cluster模式在flink job没提交之前我得先把yarn session集群准备好,(多个flink共享一个yarn session集群)所以我在flink job集群提交之前就得把yarn session集群准备好,或者说他早就存在已经有了,我再提交 ;所以一般来说session-cluster这种模式我首先得启动yarn session这个集群
什么是yarn session集群呢?
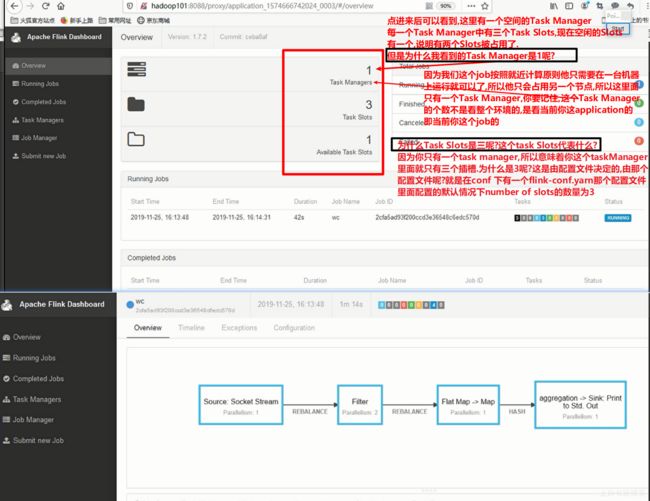
Yarn session集群就是由yarn管理的一个flink的包含了JobManager,TaskManager的这么一个集群,如图所示:
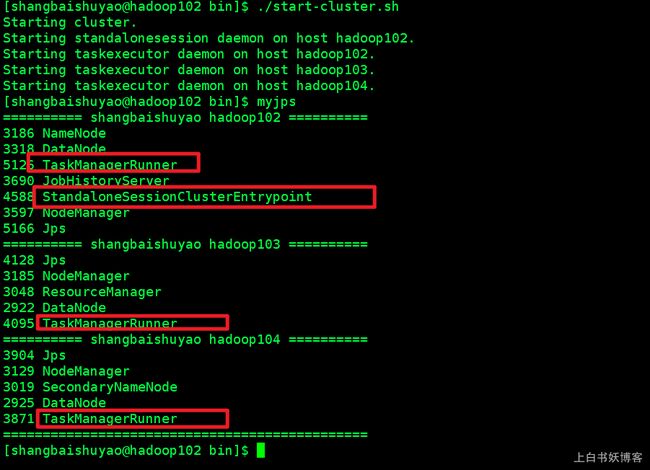
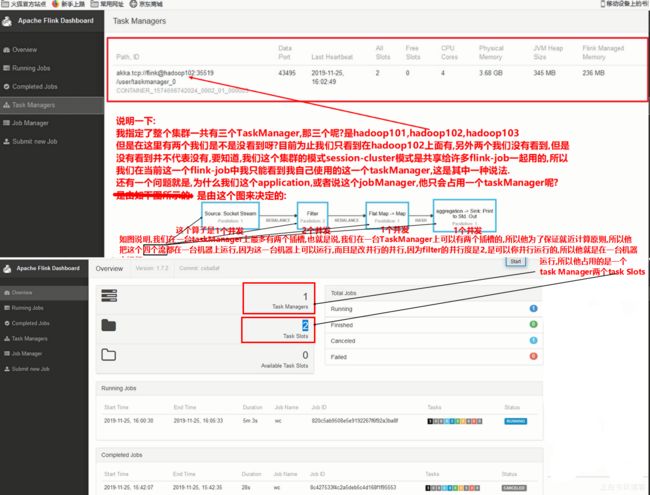
我独立模式下,一个JobManager里面包含了三个TaskManager,那为什么是三个TaskManager呢?因为我的每台机器上都只有一个TaskManager呀!
请问这些TaskManager跟Hadoop的yarn有关系吗?没有关系.他被yarn管理吗?不会.他的资源来自于yarn吗?不是,是直接来自于操作系统
所以什么叫yarn session的集群?
yarn session集群就是由yarn来管理的 一个在hadoop内部的一个小的Flink的运行集群,包含了JobManager和多个TaskManager
Per-Job-Cluster 模式启动过程
1) 启动yarn-session
①启动之前必须先启动hadoop集群
②./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
命令解释:
-n(--container):TaskManager的数量。
-s(--slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
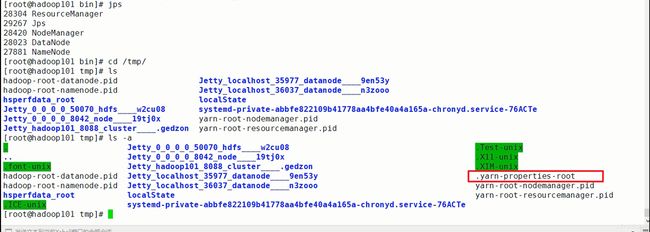
启动之后在本机(其他机器没有)的临时目录(/tmp 目录)下会生成一个文件:.yarn-properties-user(用户),这个文件是我刚刚执行yarn-session的时候生成的一个文件
#Generated YARN properties file
#Mon Jun 17 09:22:08 CST 2019
parallelism=6
dynamicPropertiesString=
applicationID=application_1532332183347_0726
如图所示:
上白书妖补充解释
所有的flink操作都会读取这个默认的配置文件.yarn-properties-root,这个配置文件,因为这个配置文件下隐藏了两个很重要的点,就是①所有可用的插槽数②我们的application的ID号
2) 执行任务 提交到刚刚启动的yarn-session中
./flink run -c com.shangbaishuyao.flink.app.BatchWcApp /ext/flink0503-1.0-SNAPSHOT.jar --input /applog/flink/input.txt --output /applog/flink/output5.csv
上白书妖补充:
不要加-m yarn-cluster,为什么不用加呢?就是因为这个配置文件中有,那这个参数是什么意思呢?不要加-m yarn-cluster因为我们这个jobmanager就是由hadoop管理的application,所以我们已经不需要去指定了,他就是我们的jobmanager.
如图所示:
不要加-m yarn-cluster,为什么不用加呢?就是因为这个配置文件中有,那这个参数是什么意思呢?

如果在本机不需要使用参数 -yid ,因为/tmp/目录中的文件已经指定了。
./flink list 查看正在运行的任务
./flink list --all 查看 所有Flink job的列表
其他机器需要指定yarn-session的ID:
./flink list --all -yid application_1573192540434_0002
./flink stop jobId 只能停止哪些已经实现stopable接口的source
./flink cancal 后面接jobId号可以关闭任务
./flink cancel 命令也是一样
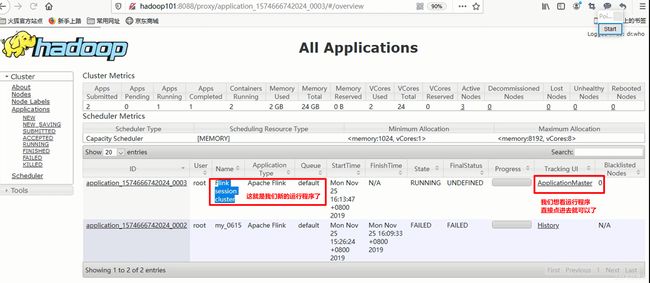
3) 去yarn控制台查看任务状态
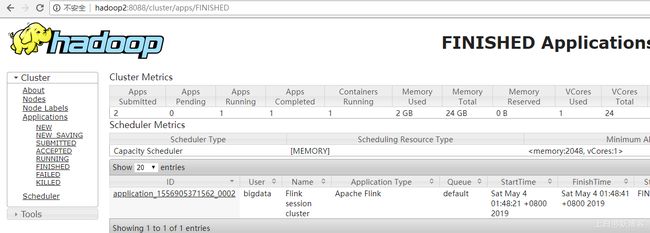
上白书妖补充:
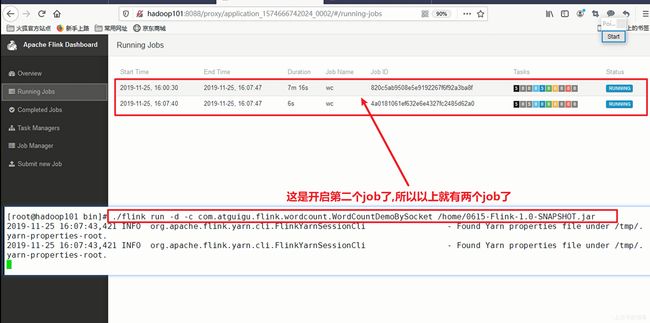
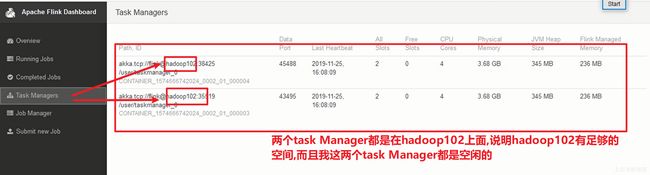
Per-Job-Cluster模式启动过程
上白书妖补充:
每一个flink job会对应自己独有的yarn session集群,每个提交的作业都会根据自身的情况都会单独向hadoop的yarn中的ResourceManager去申请资源,申请资源来启动yarn session集群 .
直到作业执行完成,这个yarn session集群会回收这个资源,一个作业的失败与否并不会影响下一个作业的提交。这也是为什么企业生产环境中一定是用这个模式。上面这种yarn session模式.
一个作业的失败很可能会影响下一个作业的正常提交,因为他一个作业的失败很可能他把所有的资源都占完了,占完了而且你一直都没有停止,没有停止那么其他的作业就无法提交了。所以我们怎么做呢?就是不需要先启动yarn-session,而是直接提交Job,直接./flink run去提交,提交时参数差不多都一样,-c指定那个类,-p设置并行度,默认的并行度是2(所以默认并行度我们可以不指定) ,这里-m是必须要加的,上面的-m不要加,但这种模式是必须要加的,-m yarn-cluster表示我们现在要提交到yarn里面去,如果不加-m他会默认优先提交给standalone,可是你没有standalone,所以会报错,所以必须要加-m yarn-cluster,最后指定我们的jar包就可以了。如下命令所示:
./flink run -c com.shangbaishuyao.flink.app.BatchWcApp -p 2 -m yarn-cluster /ext/flink0503-1.0-SNAPSHOT.jar --input /applog/flink/input.txt --output /applog/flink/output5.csv
一个Job会对应一个yarn-session集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
1)不需要先启动yarn-session,直接提交Job
./flink run -c com.shangbaishuyao.flink.app.BatchWcApp -p 2 -m yarn-cluster /ext/flink0503-1.0-SNAPSHOT.jar --input /applog/flink/input.txt --output /applog/flink/output5.csv
上白书妖补充:
网上说了许多,除了这两种模式之外还有两种模式.网上说的是有四种模式.其实除了这两种模式之外的另外两种模式都是flink客户端的模式.即我们的./flink run就是我们的客户端,这个命令就是客户端,因为我们客户端就是提交.所以这个客户端也有两种模式.这里不做探讨,
我们这里重点讲解的是Flink的程序在yarn模式上运行的第二种pre-Job-cluster的模式,这种一定要掌握.这种非常简单,启动都不需要启动,只要把yarn启动完就可以了,这也是为什么Flink操作简单的原因.依稀记得使用spark和yarn运行的时候就比这个复杂,还要修改hadoop和spark的配置文件,很是繁琐.Flink就简单多了

Kubernetes部署
上白书妖补充:
Kubernetes部署属于谷歌的,是业内比较流行的部署方式,他是基于docker镜像,即运行在docker镜像里面的,docker是类似于虚拟化的一项技术,他是基于容器来隔离的,那虚拟化主要做什么事情呢?你知道为什么要虚拟化呢?两个原因. 一.做应用程序的资源隔离 二.充分运用我这台物理机的所有资源
假设我就给你一台物理机,同时跑二十个Tomcat,每个Tomcat里面跑各自的应用程序,这样我整个物理机的资源应该被充分利用了,满足了充分运用我这台物理机的所有资源.
但是有一个没满足,就是我的资源没有隔离,当其中某一个Tomcat出现程序错误了,出现内存溢出或者其他一些原因,他源源不断的要占用其他的内存,因为他除了占用自己的堆内存之外,它还可能调用另外一个程序,有另外一个程序再占用系统资源,这个时候你就会发现,他就会影响其他19个Tomcat的运行,其他19个Tomcat可能都卡死了,这就是你资源没有隔离好,你确实充分利用了这台物理机的资源但是你没有做好资源隔离.
虽然虚拟化技术隔离隔离的很好,但是他是一个重量型解决方案,为什么是重量型解决方案?
因为你这操作系统也占了资源,Linux操作系统本身就占据着资源,所以有人就想有没有轻量级解决方案,又能隔离资源又能充分利用物理机资源呢?就是docker.因为docker是基于操作系统的虚拟化而不是硬件的虚拟化.但是虚拟化技术几乎都是基于硬件的虚拟化技术.把硬件切成一块一块的.而我们的docker是基于操作系统的.有一个统一的操作系统.在操作系统里面隔离成一小块跑一个容器,再隔离出一小块再跑一个容器.容器里面看起来是一个操作系统,但是他本质上不是一个真正意义上的操作系统.但是你是用起来还是和操作系统一样.他本质就是一个进程.
Docker的好处是:隔离了资源.充分利用了所有资源
Docker 的坏处是:他隔离资源并没有真正意义上隔离很好.docker于docker之间网络,磁盘都是可以共享的.使用起来还是不错的.因为docker里面有个非常重要的叫kubernetes(k8s):他是一个集群,它功能强大,即可管理我们的docker容器,又可以做资源分配的集群.由于他可以做资源分配,所以我们flink就可以放在他上面运行.
所以你要从什么角度去看kubernetes(k8s).
如果你要从大数据的分析引擎的角度去看k8s的话.那么他和我们hadoop的yarn是一样的东西.
如果我站在虚拟化的角度去看k8s的话,k8s和OpenStack(云计算)是一样的东西.OpenStack是什么呢?
阿里云底层使用的就是OpenStack,要知道k8s是用来管理容器的.阿里云是用来管理虚拟机的
你在网上操作哪些阿里云主机都是一台台虚拟机,这些虚拟机特别多,几十亿台,所以他需要一个统一管理的,分布式管理的一个工具叫OpenStack.那么我门的容器是不是也有几十亿个容器啊?
也会需要一个统一的管理工具,这个统一管理工具就是k8s.
总结:
虚拟化技术是一个重量型解决方案
Docker类似于虚拟化的一项技术,他是轻量级解决方案
为什么要虚拟化呀?
容器化部署时目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。
1)搭建Kubernetes集群(略)
2)配置各组件的yaml文件
在k8s上构建Flink Session Cluster,需要将Flink集群的组件对应的docker镜像分别在k8s上启动,包括JobManager、TaskManager、JobManagerService三个镜像服务。每个镜像服务都可以从中央镜像仓库中获取。
3)启动Flink Session Cluster
// 启动jobmanager-service 服务
kubectl create -f jobmanager-service.yaml
// 启动jobmanager-deployment服务
kubectl create -f jobmanager-deployment.yaml
// 启动taskmanager-deployment服务
kubectl create -f taskmanager-deployment.yaml
4)访问Flink UI页面
集群启动后,就可以通过JobManagerServicers中配置的WebUI端口,用浏览器输入以下url来访问Flink UI页面了:
http://{JobManagerHost:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy
上白书妖补充:
Flink和Spark本质上的区别:
Spark质上是纯批处理,Flink本质上是纯流处理
Yarn-Session中所说的资源叫什么?
在hadoop框架中,资源叫Container(容器),在Flink的yarn-session中资源叫Slot(槽)