使用DL模型预测台风/雷达回波/降水的datasets构建学习笔记
基于pytorch的台风降水datasets类构建学习笔记
- dl模型花里胡哨一堆,但跑了这么多模型才发现特征工程的重要性,处理好气象数据对于结果还是非常重要的。
- 在处理气象时空序列问题常采用滑动窗口的方法来从时序数据中切出数据集。
基本的台风数据集构建
这也是我入门时接触的一种基于pytorch定制基于台风序列数据的datasets类。
下面方法来自追风比赛上的baseline模型
首先这个大佬的思路是把序列文件摊开,然后用步长为1的滑动窗口去切割序列,首先要面对如下三个问题。
1. 时间点丢失,即整个时间点的三个通道的数据全部丢失;
2. 通道丢失,某个时间点的一个或两个数据通道文件丢失;
3. 区域丢失,某时间点的三个数据通道文件都存在,但是数据本身存在不正常(大面积为0)。
他的方法处理缺少数据是使用上一个时间点去填充缺失点数据。
接着就是定制的datasets类:
# 用于将加载的数据保存在内存中。因为每次要加载12张图像,会花费比较长的时间。
self.allframes = [None] * len(self.files)
tids = []
for i in range(len(self.allframes)):
self.allframes[i] = []
tids.append(int(re.findall(r'Hour_(\d+)', self.files[i])[0]))
def __len__(self):
# 实际可遍历的时间点数要小于总时间点数,因为一次加载的时间跨度为42小时(用最后6小时的数据去预测未来36小时的情况)
return len(self.files) - (self.fnum // 2) * (self.freq + 1) + 1
def __getitem__(self, idx):
# 列出12帧数据的时间点ID,比如 A_Hour_189 的时间点ID为189
# 那要加载数据ID为 [189, 190, 191, 192, 193, 194, 200, 206, 212, 218, 224, 230]
tid = self.tids[idx]
ids1 = list(range(tid, tid + (self.fnum // 2)))
ids2 = list(range(tid + (self.fnum // 2) + self.freq - 1, tid + (self.fnum // 2) + self.freq + (self.fnum // 2) * self.freq - 1, self.freq))
ids = ids1 + ids2
return ids, frames_crop上面就是定制datasets类,废话不多说直取核心,__init__部分加载摊开的序列数据文件名列表,__len__部分为去除最后不满足滑窗长度数据后的序列数据个数,__getitem__返回序列号和滑窗长度的数据格式为 scwh。
当然这种步长为1的滑窗会忽略掉不同时段的数据差异,并且会造成数据泄露?我的理解是target的值作为feature参与到了input的训练中,这里我理解不深,网上查阅后大概的意思就是在数据比赛中这是一种投机的技巧?在数据eda阶段,有的feature会与target高相关,所以作为feature是不合适的。
-
接下来总结我关注的三个长期关于雷达回波外推的数据处理方法,一个是国防科技大一课题组从17年开始的各种主流dl模型在回波外推应用,另一个是清华一课题组从predrnn开始的工作,最后一个就是经典的施行建三个模型的数据处理。
-
首先是国防科大课题组的处理
-

这是他们17年的处理方法,还是比较朴素的。

这是19年最新的方法,取滑窗长度25然后步长为3,去切每个雨天的数据,这个相比于把整个序列摊开去切不会出现input里有有个不同天的序列,然后就普通的操作clip到0-75dbz然后归一化。将数据集随机分成7:2:1训练测试和验证。 -
下面关注清华课题组的从predrnn到e3dlstm的datasets处理方法,由于git上的三个模型里都没有找到关于气象数据处理的INputhandle,且他们的操作基于tensorflow较之torch相当于定制了datasets+dataloader比较麻烦,当初入门的时候一上来就干这个真是不堪回首,所以来参考这个:
-

-
滑窗长度为20,步长为猜测估计为1-2,resize成100x100,这里有个问题预测图片太小在实际工作中不具有指导意义,下面总结高分辨率的两篇文章这个为800x800:
-

-
他采用步长为1的滑窗去切割,而另一篇国家气象局的文章中采用了相对专业的滤波操作:
-

-
而shi博士的滤波操作为采用几个月的数据进行k-mean然后滤去杂波。
接下来就是shi博士15-17年的几个经典模型的datasets操作,由于比较复杂我尝试去理解一下。hozzone在用pytorch复现其模型时直接用了类似于pytorch中datasets+dataloader的组合:
train_hko_iter = HKOIterator(pd_path=cfg.HKO_PD.RAINY_TRAIN,
sample_mode="random",
seq_len=IN_LEN+OUT_LEN)shi博士针对hko雷达数据定制了hkoiterator类,在训练中采用随机抽样,一个样本为滑窗长度(input+target)
for itera in tqdm(range(1, max_iterations+
lr_scheduler.step()
train_batch, train_mask, sample_datetimes, _ = \
train_hko_iter.sample(batch_size=batch_size)在抽样的时候调用了hkoiterator类的sample方法,简单清晰。
下面是hkoiterator类的说明文档:
“”"Random sample: sample a random clip that will not violate the max_missing frame_num criteria
Sequent sample: sample a clip from the beginning of the time.
Everytime, the clips from {T_begin, T_begin + 6min, …, T_begin + (seq_len-1) * 6min} will be used
The begin datetime will move forward by adding stride: T_begin += 6min * stride
Once the clips violates the maximum missing number criteria, the starting
point will be moved to the next datetime that does not violate the missing_frame criteria
它的模型类似于pytorch的dataload类中顺序取样和随机取样,在最原始的mxnet,hko-7项目中顺序取样的滑窗步长为5也就是input的长度,它保证了input部分的不重叠。如果它在取样的过程中出现超过阈值的缺测数据会跳到下个点开始。
这个操作由下面的方法来完成:
def _next_exist_timestamp(self, timestamp):
next_ind = bisect.bisect_right(self._df.index, timestamp)
if next_ind >= self._df.size:
return None
else:
return self._df.index[bisect.bisect_right(self._df.index, timestamp)]虽然没见过真实的hko-7数据,但基本能猜到什么样子。
下面的方法来判定是否超过最大缺测数:
def _is_valid_clip(self, datetime_clip):
"""Check if the given datetime_clip is valid def sample(self, batch_size, only_return_datetime=False):
"""Sample a minibatch from the hko7 dataset based on the given type and pd_filesample函数完成抽样,在顺序抽样模式下给入一个begin_timestep,而在随机抽样模式下直接随机给入起始点:
rand_ind = np.random.randint(0, self._df.size, 1)[0]
random_datetime = self._df.index[rand_ind]然后判断是否是一个有效的timestep,之后返回数据:
return frame_dat, mask_dat, datetime_clips, new_start这上面的代码如今来看不是很复杂,但在本人入门连python都不会的时候直接就上手这个现在想想真是惨不忍睹,这说明了指导是非常重要的不然那叫一个撕心裂肺的难啊。
接下来尝试分析一下一个台湾老哥的台风降水预测,他采用了flow-gru和muli-handattention模块的convgru以及改造后的transformer模型,模型部分不是很复杂而看看他是怎么处理定制的datasets类的,我尽力猜猜看
- 插入一个针对convlstm模糊问题改进的vae-lstm模型小总结

- 这个作者认为convlstm到后期变模糊的原因是因为hidden之间的距离太大导致,优化的时候可选范围过大,在拟合真实的概率分布的时候范围过大不易拟合,其加入vae的思想将hidden从正态分布中抽样:

- 他的思路是构建一个vae的encoder和一个decoder以及一个基于lstm的encoder+decoder:
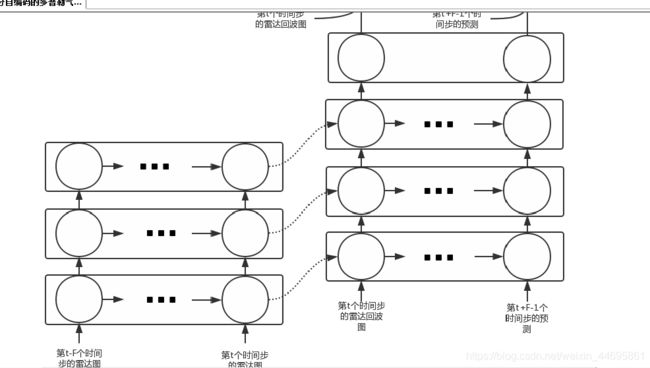
- 然后用了resnet残差的思想,走远了。来看台湾老哥的操作.
- 这两个工作都对2017年天池cikm的数据集进行了预测,但这个vae老哥的效果并不是很好对convlstm的效果改进非常有限。
- 首先台湾老哥对typhoon_list建立可操作的序列文件夹
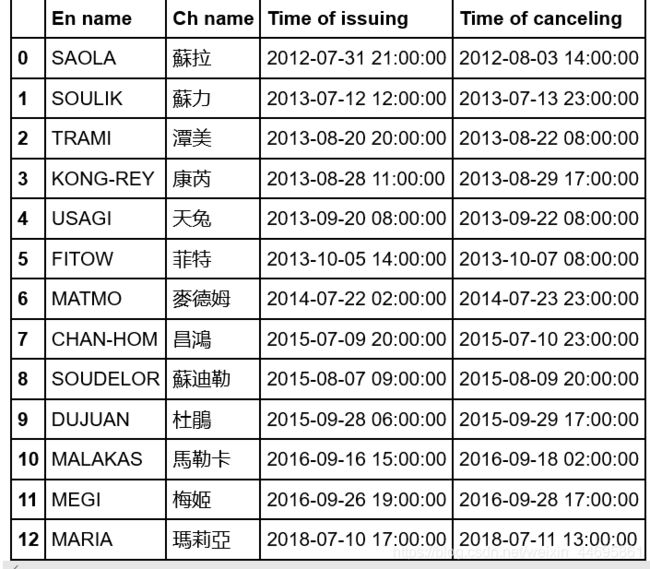
ty_track_path = os.path.join(args.weather_raw_data_folder, year+'.Data', year+'_TrackData', year+'.'+tyname+'.Track.txt')- 老哥往txt里写dataframe这个操作没看懂,然后我猜整个操作时重新把序列按照雷达回波或者其他什么的数据按照时间步长一一对应返回索引csv
new_ty_track.to_csv(outputname)- 然后这个老哥把其他变量融合了一下,我是根据这个猜的:
_ = check_data_and_create_miss_data()
data1 = pd.read_pickle(os.path.join(args.radar_wrangled_data_folder, 'RAD', '2012.SAOLA.201208021530.pkl'),compression=args.compression)
data2 = pd.read_pickle(os.path.join(args.radar_wrangled_data_folder, 'RAD', '2012.SAOLA.201208021620.pkl'),compression=args.compression)
- 继续猜,他对缺测的雷达回波数据线性内插,然后做了些qpe和rad的eda,所以qpe是什么鬼东西没看懂。
testdataset = TyDataset(args=args, train=False, train_num=train_num, transform=transform)
在train文件中锁定目标 Tydataset定制类,看看老哥又是如何操作的呢
'''
Args:
train(boolean): Return training dataset or validating dataset.
args(easydict): An edict for saving
transform (callable, optional): Optional transform to be applied on a sample.
'''锁定类的文档,接受之前的typhoon_list
ty_list = pd.read_csv(args.ty_list, index_col='En name').drop('Ch name', axis=1).iloc[:-2]
ty_list['Time of issuing'] = pd.to_datetime(ty_list['Time of issuing'])
ty_list['Time of canceling'] = pd.to_datetime(ty_list['Time of canceling'])
ty_list.index.name = 'Typhoon'定义类属性,input的size(400,400):
self.I_x = args.I_x
self.I_y = args.I_y
self.I_shape = args.I_shape
self.F_x = args.F_x
self.F_y = args.F_y不想看了,开始随便猜,下面这个是随机选一个台风事件作为data序列进行训练
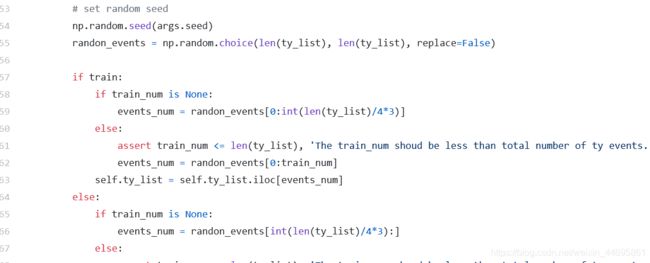
-
然后用了个骚操作应该是在dataframe上直接操作返回了滑动窗口组成的序列pkl文件,input长6target18,滑窗长24,骚操作如下三行:
-
events_windows = ((frame_e-frame_s).apply(lambda x:x.days)*24*6 + (frame_e-frame_s).apply(lambda x:x.seconds)/600 + 1).astype(int) last_idx = np.cumsum(events_windows) - 1 frist_idx = np.cumsum(events_windows) - events_windows -
简单的跑了下他的骚操作
-
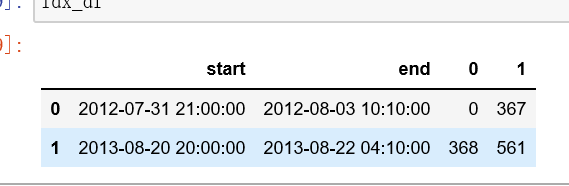
-
2个台风过程切出来了500个左右的序列样本。
-
有意思的是它的雷达数据是存在pkl中的:
-
input_data[j,c,:,:] = pd.read_pickle(data_path, compression=self.compression).loc[self.I_y[0]:self.I_y[1], self.I_x[0]:self.I_x[1]].to_numpy() -
之后就用到了先前处理过的txt文件,跟一个归一化操作:
-
height = (height-np.min(height))/(np.max(height)-np.min(height)) -
return 一个字典:
-
self.sample = {'inputs': dBZ_to_pixel(input_data), 'targets': dBZ_to_pixel(target_data), 'ty_infos': ty_infos, 'height': height}