Flink-面试题
1.实操:熟练书写Flink的WordCount代码
package com.atguigu.flink.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author WEIYUNHUI
* @date 2023/6/10 14:17
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Wordcount {
private String word ;
private Integer count ;
@Override
public String toString() {
return "(" +
"word='" + word + '\'' +
", count=" + count +
')';
}
}
package com.atguigu.flink.wordcount;
import com.atguigu.flink.pojo.Wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author WEIYUNHUI
* @date 2023/6/10 11:15
*
* 使用WebUI监控作业的执行情况
*
* 仅限于在IDEA中测试使用,
* 将来程序打包提交到Flink集群执行时,会自动提供WEBUI监控界面。
*/
public class Flink07_WebUIWordCount {
public static void main(String[] args) throws Exception {
//加载配置
Configuration conf = new Configuration();
//conf.setString("rest.address" , "localhost");
conf.setInteger("rest.port", 5678);
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
//设置并行度
env.setParallelism(1);
// 2.读取数据
// DataStreamSource => DataStream
DataStreamSource ds = env.socketTextStream("127.0.0.1", 8888);
// 3.转换处理
// 3.1 切分数据,处理成 Wordcount
SingleOutputStreamOperator flatMapDs = ds.flatMap(
//lambda写法
(String line, Collector out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(new Wordcount(word, 1));
}
}
)//.returns(Wordcount.class) ;
.returns(Types.POJO(Wordcount.class));
// 3.2 按照单词分组
KeyedStream keyByDs = flatMapDs.keyBy(
// wordcount -> wordcount.getWord()
Wordcount::getWord
);
// 3.3 汇总
// 使用Tuple中的第二个元素进行汇总
SingleOutputStreamOperator sumDs = keyByDs.sum("count");
// 4. 输出结果
sumDs.print();
// 5. 启动执行
env.execute();
}
}
2.Flink中的App,Job,TaskManager,JobManager分别是什么?
- App
-
指的是一个Flink应用程序,通常由一个或多个Flink Job组成。Flink应用程序是由Flink程序员编写的数据处理逻辑,可以在Flink集群上运行。
-
-
Job
-
指的是Flink应用程序中的一个具体的数据处理任务,由一个或多个算子组成。每个Job都有一个独立的JobGraph,用于描述Job中的算子和它们之间的依赖关系。
-
-
TaskManager
-
指的是在Flink集群中运行的工作节点,负责执行Job中的具体任务。每个TaskManager可以运行多个任务,每个任务由一个或多个Task组成。
-
-
JobManager
-
指的是Flink集群中的主节点,负责协调和管理整个Flink应用程序的运行。JobManager负责接收和处理Job提交请求,将JobGraph转换为物理执行计划,并将执行计划分发给TaskManager执行。JobManager还负责监控任务的执行状态,处理任务失败和重试等问题。
-
3.三种部署模式的区别是什么?
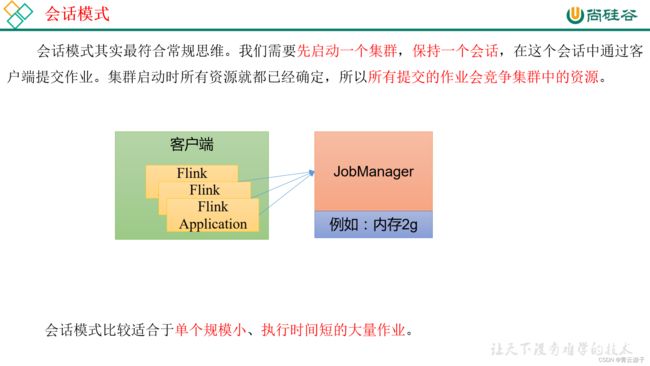
- 会话模式
- Session Mode
- 启动一个集群,作业都往这一个集群提交
- 缺点: 如果提交的作业中有长时间执行的大作业,占用了该Flink集群的所有资源,则后续无法提交新的job
- 适用于单个规模小,执行时间短的大量作业
- 单作业模式(Per-Job Mode)
- 每个提交的作业启动一个集群
- 应用代码在客户端执行

-
应用模式(Application Mode)
-
每个提交的作业启动一个集群
-
应用代码在JobManager执行
-
与单作业模式的区别: 应用模式下,用户的main函数是在JobManager中执行的
-
-

4.掌握Yarn模式的部署和使用
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
5.掌握KafkaSource的基本使用
package com.atguigu.flink.datastream.source;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.internals.Topic;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
/**
* @author WEIYUNHUI
* @date 2023/6/13 9:13
*
* Kafka Connector :
* 1. 从kafka中消费数据
* 1.1 消费者对象:
* KafkaConsumer
* 1.2 消费者相关配置:
* key/value的反序列化器:
* key.deserializer => org.apache.kafka.common.serialization.StringDeserializer
* value.deserializer => org.apache.kafka.common.serialization.StringDeserializer
* 集群地址:
* bootstrap.servers => hadoop102:9092,hadoop103:9092,hadoop104:9092
* 消费者组:
* group.id => 随便
* offset自动提交:
* enable.auto.commit => true / false
* offset自动提交的间隔:
* auto.commit.interval.ms => 5000
* offset重置:
* auto.offset.reset => latest(尾) | earliest(头)
* 重置的情况:
* 1. 新的消费者组 , 之前没有消费过数据, 也就没有对应的offset
* 2. 旧的消费者组 , 之前有消费过数据,但是对应的offset已经在kafka中不存在(可能的原因是Kafka默认7天会清理数据)
*
* 1.3 Kafka提供的消费者的配置类 ConsumerConfig
*
* 2. 往kafka生产数据
*/
public class Flink03_KafkaSource {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/*
封装要从哪个主题那个分区的offset进行消费
TopicPartition topicPartition = new TopicPartition("topicA", 3);
HashMap offsets = new HashMap<>();
offsets.put(topicPartition , 40L) ;
*/
KafkaSource kafkaSource =
KafkaSource.builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092")
.setGroupId("flink1")
.setTopics("topicA")
.setValueOnlyDeserializer(new SimpleStringSchema()) //仅针对于没有key的消息
//.setDeserializer() //针对于key和value
// 默认使用记录的offset进行消费 ,如果涉及到重置offset, 选择重置到尾
//.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
// 默认使用记录的offset进行消费 ,如果涉及到重置offset, 选择重置到头
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// 指定Offset消费
//.setStartingOffsets(OffsetsInitializer.offsets(offsets))
//如果其他的设置没有对应的方法, 统一使用.setProperty( 配置项 , 配置值)
// .setProperty("enable.auto.commit" , "true" )
.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG , "true")
//.setProperty("auto.commit.interval.ms" , "6000")
.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG , "6000")
.build();
DataStreamSource ds = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
ds.print();
try {
env.execute();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
6.Flink中常见算子及功能是什么?
(1)Map:对输入数据进行转换并输出。
(2)FlatMap:将输入数据拆分为多个输出数据。
(3)Filter:根据指定条件过滤输入数据。
(4)KeyBy:按指定键将输入数据分组。
(5)Reduce:对分组后的数据进行聚合计算。
(6)Aggregations:包括sum、min、max、avg等聚合操作。
(7)Window:对输入数据按时间窗口进行分组。
(8)Join:将两个数据流按指定键进行连接。
(9)Union:将多个数据流合并为一个数据流。
7.算子链是什么?优缺点?


- 算子链是什么
- 为了更高效地分布式执行,Flink会尽可能地将算子(operator)的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。这就是我们所说的算子链。
- 从上图中可以看到,算子合并成算子链后,相当于是一个算子,只用了一个线程
-
优点
-
不合并的情况下,每个算子各占一个线程,合并后,两个算子可以共用一个线程
-
减少线程之间的切换
-
减少数据在缓冲区的交换
-
减少了延迟的同时提高整体的吞吐量
-
减少消息的序列化/反序列化
-
-
缺点
-
无
-
8.算子链的必要条件是什么?如何禁用?如何开启新的算子链?
- 必要条件
- 算子之间没有shuffle操作,也就是分发方式为forward
- 算子之间的并行度相同
- 如何禁用
-
在算子上设置disableChaining()方法
-
DataStreamstream = env.fromElements(1, 2, 3) .map(new MyMapFunction()).disableChaining();
-
-
如何开启新的OperatorChain
-
在算子上设置startNewChain()方法
-
需要注意的是,如果使用startNewChain()方法开启新的OperatorChain,需要保证前一个算子已经是独立的算子,否则新的OperatorChain不会生效。
-
DataStreamstream = env.fromElements(1, 2, 3) .flatMap(new MyFlatMapFunction()).startNewChain();
-
9.Flink的运行时架构是什么?
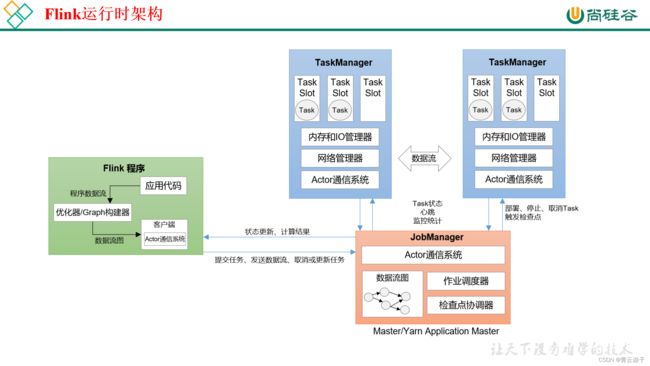
Flink程序在运行时主要有TaskManager,JobManager,Client三种角色。
-
JobManager是集群的老大,负责接收Flink Job,协调检查点,故障恢复等,同时管理TaskManager。 包含:
-
Dispatcher:分发器
-
ResourceManager:资源管理器
-
JobMaster
-
-
TaskManager是执行计算的节点,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络。内部划分slot隔离内存,不隔离cpu。同一个slot共享组的不同算子的subtask可以共享slot。
-
Client是Flink程序提交的客户端,将Flink Job提交给JobManager。
10.Flink核心概念
-
Task、Subtask的区别
-
Subtask:算子的一个并行实例。
-
Task:subtask运行起来之后,就叫Task。
-
-
算子链:Operator Chain
-
Flink自动做的优化,要求One-to-one,并行度相同。
-
代码disableOperatorChaining()禁用算子链。
-
-
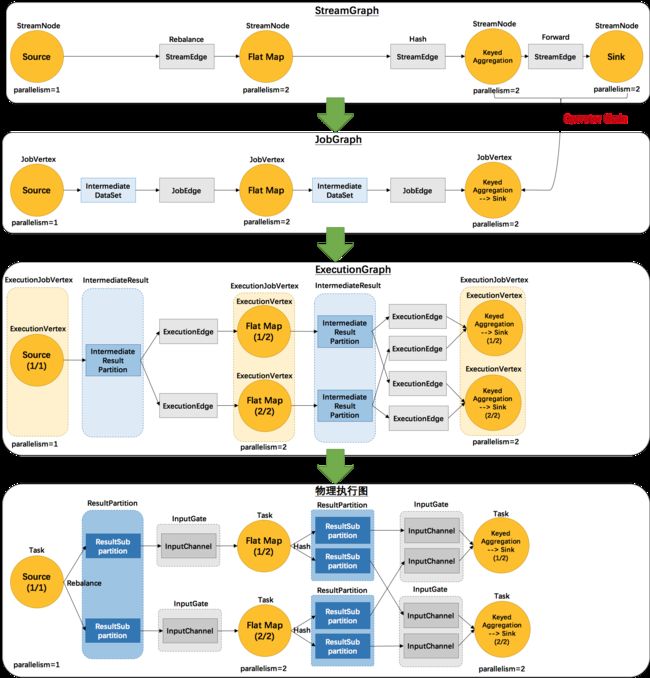
Graph生成与传递
-
Graph生成与传递 在哪里生成
传递给谁 做了什么事 StreamGraph Client Client JobGraph Client JobManager 算子链路优化 ExecutionGraph JobManager JobManager 并行度的细化 物理执行图
-
-
-
并行度和Slot的关系
-
Slot是静态的概念,是指TaskMangaer具有的并发执行能力。
-
并行度是动态的概念,指程序运行时实际使用的并发能力。
-
设置合适的并行度能提高运算效率,太多太少都不合适。
-
-
Slot共享组了解吗,如何独享Slot插槽
-
默认共享组是default,同一共享组的task可以共享Slot。
-
通过slotSharingGroup()设置共享组。
-
给自己单独设置组,就可以独享Slot插槽
-
11.什么是slot?
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。
很显然,TaskManager的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一个TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。

12.任务槽数量的设置
在Flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中,可以设置TaskManager的slot数量,默认是1个slot。
taskmanager.numberOfTaskSlots: 8需要注意的是,slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争。这也是开发环境默认并行度设为机器CPU数量的原因。
13.如何独享Slot插槽
如果希望某个算子对应的任务完全独占一个slot,或者只有某一部分算子共享slot,我们也可以通过设置“slot共享组”手动指定:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup("1");这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的slot上。在这种场景下,总共需要的slot数量,就是各个slot共享组最大并行度的总和。
14.slot共享的条件?
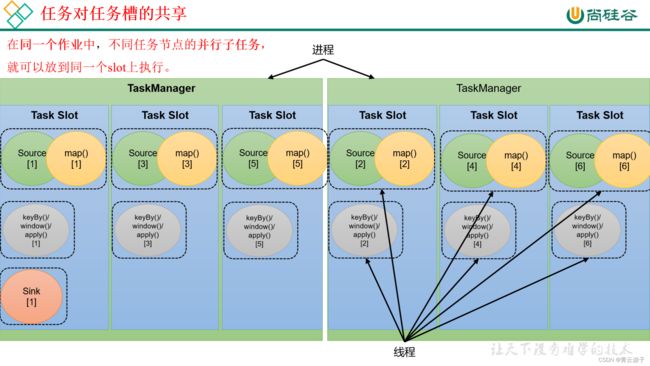
在同一个作业中,不同任务节点的并行子任务,就可以放到同一个slot上执行。
默认情况下,Flink是允许子任务共享slot的。如果我们保持sink任务并行度为1不变,而作业提交时设置全局并行度为6,那么前两个任务节点就会各自有6个并行子任务,整个流处理程序则有13个子任务。如上图所示,只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点source→map,它的6个并行子任务必须分到不同的slot上,而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。
slot共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
15.任务槽和并行度的关系
点击查看
16.如果希望实现算子的生命周期方法,应该如何做?
在Flink中,可以通过实现RichFunction接口来实现算子的生命周期方法。RichFunction接口继承自Function接口,除了Function接口中的方法外,还包括以下生命周期方法:
open(Configuration parameters):初始化方法,在算子开始执行之前调用,可以用来进行一些初始化操作,如建立数据库连接、获取配置参数等。
close():清理方法,在算子执行结束之后调用,可以用来释放资源,如关闭数据库连接、清理缓存等。
getRuntimeContext():获取运行时上下文对象,可以用来获取一些运行时信息,如并行度、任务名称等。
在实现RichFunction接口的算子中,可以重写这些生命周期方法,例如:
public class MyMapFunction extends RichMapFunction {
@Override
public void open(Configuration parameters) throws Exception {
// 在算子开始执行之前进行初始化操作
// 建立数据库连接、获取配置参数等
}
@Override
public void close() throws Exception {
// 在算子执行结束之后进行清理操作
// 关闭数据库连接、清理缓存等
}
@Override
public String map(Integer value) throws Exception {
// 算子的核心逻辑
return value.toString();
}
} 17.Union和Connect的区别是什么?
Flink中Union和Connect都是用于将两个或多个流合并在一起的操作,但它们的区别在于:
Union操作将多个流合并成一个流,合并后的流中的元素保持它们原来的顺序,即合并后的流中的元素按照它们在各自的源流中的顺序排列。
Connect操作将两个流合并成一个ConnectedStreams对象,但两个流的元素类型可以不同。在Connect操作后,可以使用CoMap,CoFlatMap等算子对两个流进行联合处理。在处理过程中,Connect操作会将两个流中的元素分别放到不同的Tuple2对象中,这样就可以对它们进行不同的操作。
因此,Union操作适用于两个或多个类型相同的流的合并,而Connect操作适用于两个类型不同的流的合并,并且需要在后续处理中对其进行区分。
18.实操:熟练掌握KafkaSink和JDBCSink
KafkaSink
JdbcSink
19.滚动窗口,会话窗口,和滑动窗口的特点是什么?
滚动窗口:滚动窗口是一种固定大小的窗口,它将数据流划分为大小相等、不重叠的窗口。每次滑动一个窗口大小,处理一个新的窗口数据。滚动窗口的特点是窗口大小固定,数据处理频率固定,适用于对数据流进行统计分析等操作。
滑动窗口:滑动窗口是一种大小固定、可以重叠的窗口类型。它将数据流划分为大小相等、部分重叠的窗口,每次滑动一个指定的跨度,处理一个新的窗口数据。滑动窗口的特点是可以灵活控制窗口大小和滑动跨度,适用于对数据流进行实时监控等操作。
会话窗口:会话窗口是一种基于数据流中数据间隔时间的窗口类型。当数据流中两个数据的时间间隔超过指定时间时,会话窗口将前面的数据作为一个窗口进行处理。会话窗口的特点是窗口大小不固定,数据处理频率不固定,适用于对交互式用户行为等进行分析。
20.窗口构造的API是什么?
KeyedStream.windowXXX():这个API是针对KeyedStream的,用于对分组后的数据流进行窗口化处理。
DataStream.windowAllXXX():这个API是针对非分组的数据流进行窗口化处理的。
21.Flink中的时间语义有哪些?
Flink中支持的时间语义包括:
Event Time(事件时间):事件时间是事件发生的实际时间,这个时间通常记录在事件本身的数据中。在Flink中,可以通过调用DataStream.assignTimestampsAndWatermarks()方法来分配事件时间戳和水位线。
Processing Time(处理时间):处理时间是Flink系统处理事件的时间,通常使用系统时钟来记录。在Flink中,不需要指定处理时间戳和水位线,系统会自动使用当前时间作为时间戳。
这些时间语义可以通过Flink的API进行设置和使用,在数据流处理中,不同的时间语义会影响到事件的处理和窗口的计算。例如,使用事件时间可以解决乱序事件的问题,而使用处理时间则可以提高处理速度。
22.Watermark的意义是什么?
在Flink中,Watermark是用于处理乱序事件的一种机制,它是一种特殊的事件,用于告诉Flink系统在处理数据时,哪些数据可以被认为是已经到达的,哪些数据还未到达。
Watermark通常由一个特定的算子生成,并在数据流中传递。每当Flink系统接收到一个Watermark时,它会将该Watermark与当前所有窗口的结束时间进行比较,如果某个窗口的结束时间早于Watermark的时间戳,则该窗口被认为是已经完成的,可以触发相应的计算操作。
Watermark的意义在于解决乱序事件的问题。在数据流中,由于网络传输、延迟等原因,事件的到达顺序可能会发生变化。如果不加以处理,这些乱序事件可能会导致计算结果的不准确性。通过使用Watermark,可以告诉Flink系统哪些事件已经到达,哪些还未到达,从而保证计算结果的正确性。
总之,Watermark在Flink中扮演着非常重要的角色,它是处理乱序事件的关键机制,可以提高计算结果的准确性和可靠性。
23.Watermark是什么?
(1)Watermark 是一种衡量 Event Time 进展的机制,是一个逻辑时钟。
(2)Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark 机制结合Window 来实现。
(3)基于事件时间,用来触发窗口、定时器等。
(4)Watermark主要属性就是时间戳,可以理解一个特殊的数据,插入到流里面。
(5)Watermark是单调不减的。
(6)数据流中的 Watermark 用于表示 Timestamp 小于 Watermark 的数据,都已经到达了,如果后续还有Timestamp 小于 Watermark 的数据到达,称为迟到数据。
24.如何构造WaterMark的生成策略?
在Flink的DataStreamAPI中,有一个单独用于生成水位线的方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间。具体使用时,直接用DataStream调用该方法即可,与普通的transform方法完全一样。
DataStream stream = env.addSource(new ClickSource());
DataStream withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks();assignTimestampsAndWatermarks()方法需要传入一个WatermarkStrategy作为参数,这就是所谓的“水位线生成策略”。WatermarkStrategy中包含了一个“时间戳分配器”TimestampAssigner和一个“水位线生成器”WatermarkGenerator。
- TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
-
WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator接口中,主要又有两个方法:onEvent()和onPeriodicEmit()。
-
onEvent:每个事件(数据)到来都会调用的方法,它的参数有当前事件、时间戳,以及允许发出水位线的一个WatermarkOutput,可以基于事件做各种操作。
-
onPeriodicEmit:周期性调用的方法,可以由WatermarkOutput发出水位线。周期时间为处理时间,可以调用环境配置的.setAutoWatermarkInterval()方法来设置,默认为200ms。env.getConfig().setAutoWatermarkInterval(60 * 1000L);
public interface WatermarkStrategy extends TimestampAssignerSupplier,WatermarkGeneratorSupplier{
@Override TimestampAssigner createTimestampAssigner(TimestampAssignerSupplier.Context context);
@Override WatermarkGenerator createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}25.多并行度下watermark的推进策略是什么?
1)分类:
间歇性:来一条数据,更新一次watermark。
周期性:固定周期更新watermark。
官方提供的api是基于周期的,默认200ms,因为间歇性会给系统带来压力。
2)生成原理:
Watermark=当前最大事件时间 - 乱序时间 - 1ms
3)传递:
Watermark是一条携带时间戳的特殊数据,从代码指定生成的位置,插入到流里面。
一对多:广播。
多对一:取最小。
多对多:拆分来看,其实就是上面两种的结合。
26.如何处理乱序的场景?
(1)Watermark的乱序等待时间。
(2)使用窗口时,可以允许迟到。
(3)迟到特别久的,放到侧输出流处理。
27.什么是Flink中的定时器?如何制定定时器?
Flink中的定时器可以通过以下两种方式进行设置:
在KeyedStream上使用windowXXX()方法:可以在KeyedStream上使用windowXXX()方法来定义窗口,其中可以设置window()方法的参数来指定窗口的大小和滑动间隔。在窗口中,可以使用process()方法来注册ProcessWindowFunction,并使用Context对象来设置定时器。例如,可以使用Context.timer()方法来注册事件时间或处理时间的定时器。
在ProcessFunction或CoProcessFunction中使用onTimer()方法:可以在ProcessFunction或CoProcessFunction中使用onTimer()方法来注册事件时间或处理时间的定时器。在onTimer()方法中可以执行一些操作,例如触发窗口计算、清除状态等。可以使用TimerService对象来注册事件时间或处理时间的定时器。例如,可以使用TimerService.registerEventTimeTimer()方法来注册事件时间定时器,使用TimerService.registerProcessingTimeTimer()方法来注册处理时间定时器。
28.实操:熟练完成TopN练习
点击查看
29.什么是状态?
状态(State)是指用于保存和维护数据流处理中的状态信息的一种机制。状态可以用于保存中间结果、累加器、计数器等信息,以便在后续的计算中使用。Flink中的状态是有状态的流处理的核心机制之一,它可以帮助我们在处理无限数据流时维护状态信息。
30.Flink中的状态分类?如何声明和使用状态?
RawState: 用户自己声明的变量。
ManagedState: flink提供的状态类型
KeyedState: 对KeyedStream进行处理,生命的状态都是KeyedState,每个key都有自己的状态。
各玩各的,互不干扰。
单个值: ValueState
Map集合: MapState
List集合: ListState
聚合功能: 输入类型=输出类型 ReducingState
输入类型=输出类型 AggregatingState
在处理函数对象中声明属性,在open()方法中从context中获取状态,赋值。
OperateState: 一个算子的Task上,所有处理的数据共用一个状态。
List集合:
ListState
元素的分配方式: 均匀分配
UnionListState
元素的分配方式: 每个Task获取全量
用于更新配置信息: BroadCastState
31.熟练掌握常见状态的API操作
读: value()
写: add(), addAll(), update()
清空: clear()
32.什么是状态后端?如何设置状态后端?
每传入一条数据,有状态的算子任务都会读取和更新状态,由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问。状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)。
状态后端主要负责两件事:1)本地的状态管理;2)将检查点(checkpoint)状态写入远程存储
33.状态后端的类型
在flink中给我们提供了三种不同的状态后端。

34.如何配置状态后端?
- 配置文件
- 配置文件可以配置整个集群的状态后端:conf/flink-conf.yaml文件
- 下面的名字表示checkpoint往哪里存储,默认写到文件系统持久化,一般直接保存在hdfs上面即可。

- 代码中针对单独job,设置状态后端
-
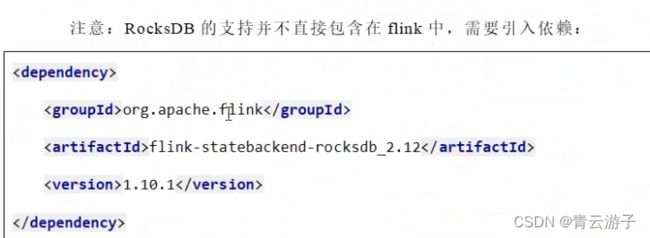
package com.atguigu.apitest.state; import com.atguigu.apitest.beans.SensorReading; import org.apache.flink.api.common.restartstrategy.RestartStrategies; import org.apache.flink.api.common.time.Time; import org.apache.flink.contrib.streaming.state.RocksDBStateBackend; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.runtime.state.memory.MemoryStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class StateTest4_FaultTolerance { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 1. 状态后端配置 //env.setStateBackend( new MemoryStateBackend()); env.setStateBackend( new FsStateBackend("")); //env.setStateBackend( new RocksDBStateBackend("")); // 2. 检查点配置 env.enableCheckpointing(300); // 高级选项 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setCheckpointTimeout(60000L); env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(100L); env.getCheckpointConfig().setPreferCheckpointForRecovery(true); env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0); // 3. 重启策略配置 // 固定延迟重启 env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000L)); // 失败率重启 env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10), Time.minutes(1))); // socket文本流 DataStreaminputStream = env.socketTextStream("localhost", 7777); // 转换成SensorReading类型 DataStream dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); dataStream.print(); env.execute(); } } 如果想要引入最后一种状态后端方式,RocksDBStateBackend,需要引入第三方库,2.12是scala版本,1.10.1是flink版本
-
-