Stream流和ParallelStream并行流详解及对比
目录
前言
一、Stream流是什么?
二、获取Stream流的方式
三、Stream流中的常用方法
1. forEach(遍历/终结方法)
2. filter(过滤)
3. map(映射转换)
4. count(统计个数/终结方法)
5. limit(截取前几个元素)
6. skip(跳过前几个元素)
7. concat(组合合并流)
8. distinct(筛选)
9. flatMap(映射,打开后再转换)
10. 定制排序:sorted
11. 检测匹配(终结方法)
12. 查找元素(终结方法)
13. 查找最大最小值(终结方法)
14. 规约(终结方法)
15. 收集(终结方法)
16. iterate(迭代)
17. peek(查看)
四、parallelStream并行流简介及对比
1. parallelStream并行流简介
2. 对比
总结
前言
最近在工作中梳理代码时遇到了大量的Stream流,因此在查阅了大量的资料并进行深入的思考后决定进行一个系统的整理,希望能给大家带来帮助。
一、Stream流是什么?
Java 8 是一个非常成功的版本,这个版本新增的Stream,配合同版本出现的 Lambda ,给我们操作集合(Collection)提供了极大的便利。
那么什么是Stream?
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
Stream可以由数组或集合创建,对流的操作分为两种:
- 中间操作,每次返回一个新的流,可以有多个。
- 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。
另外,Stream有几个特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
- stream不可复用,对一个已经进行过终端操作的流再次调用,会抛出异常。
二、获取Stream流的方式
java.util.stream.Stream 是Java 8新加入的流接口。(并不是一个函数式接口)
获取一个流非常简单,有以下几种常用的方式:
- 所有的 Collection 集合都可以通过 stream 默认方法获取流(顺序流);
- 所有的 Collection 集合都可以通过parallelStream获取并行流
- Stream 接口的静态方法 of 可以获取数组对应的流。
- Arrays的静态方法stream也可以获取流
具体方式如下:
1. 根据Collection获取流
public static void main(String[] args) {
List list = new ArrayList<>();
Stream stream1 = list.stream();
Set set = new HashSet<>();
Stream stream2 = set.stream();
Vector vector = new Vector<>();
// ...
}
2. 根据Map获取流
public static void main(String[] args) {
Map map = new HashMap<>();
Stream keyStream = map.keySet().stream();
Stream valueStream = map.values().stream();
Stream> entryStream = map.entrySet().stream();
}
3. 根据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法of ,使用很简单:
public static void main(String[] args) {
//使用 Stream.of
String[] array = { "张三", "李四", "王五"};
Stream stream = Stream.of(array);
//使用Arrays的静态方法
Arrays.stream(array)
} 三、Stream流中的常用方法
Stream流中的常用方法如下图所示:

这些方法可以被分成两种:
延迟方法:返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为延迟方法。)
终结方法:返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调用。本小节中,终结方法包括 count 和 forEach 方法。
详细的方法介绍如下:
1. forEach(遍历/终结方法)
本方法主要用于进行遍历,可简化for循环遍历。参数传入一个函数式接口:Consumer
public static void main(String[] args) {
Stream stream = Stream.of("张三", "李四", "王五");
stream.forEach(name‐> System.out.println(name));
}
2. filter(过滤)
本方法主要用于进行过滤,可以通过 filter 方法将一个流转换成另一个子集流,从而进行所需的相关过滤。
public static void main(String[] args) {
//创建一个流
Stream stream = Stream.of("张三", "李四", "王五", "赵六", "田七");
//对流中元素过滤,过滤出姓张的人
Stream stream2 = stream.filter(name -> {
return name.startsWith("张");
});
//遍历过滤后的流
stream2.forEach(name -> System.out.println(name));
}
3. map(映射转换)
如果需要进行映射转换,可以使用 map 方法将流中的元素映射到另一个流中。该接口需要一个 Function 函数式接口参数,java.util.stream.Function 函数式接口中唯一的抽象方法为
R apply(T t);
这可以将一种T类型转换成为R类型,而这种转换的动作,就称为“映射"。map使用方法如下:
/**
* stream流的map方法
* map方法可以将流中的元素映射到另一个流中
* map方法的参数是一个Function函数式接口
*/
public void mapTest(){
//创建一个流,里面是字符串类型的整数
Stream stream1 = Stream.of("21", "32", "25", "57", "42");
//把stream1流中的整数全部转成int类型
Stream stream2 = stream1.map((String s) -> {
return Integer.parseInt(s);
});
//遍历
stream2.forEach((i)-> System.out.println(i));
}
4. count(统计个数/终结方法)
类似集合 Collection 当中的 size 方法一样,Stream流提供 count 方法来统计其中的元素个数,该方法返回一个long值代表元素个数(不再像集合是int值)。基本使用方法如下:
public class Demo09StreamCount {
public static void main(String[] args) {
Stream original = Stream.of("张三", "李四", "王五",“张三丰”);
//筛选姓张的人
Stream result = original.filter(s ‐> s.startsWith("张"));
//输出个数
System.out.println(result.count()); // 输出:2
}
}
5. limit(截取前几个元素)
limit 方法主要用于对流进行截取,只取用前n个。参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用方法如下:
public class Demo10StreamLimit {
public static void main(String[] args) {
Stream original = Stream.of("张三", "李四", "王五");
//截取前两个元素
Stream result = original.limit(2);
System.out.println(result.count()); // 2
}
}
6. skip(跳过前几个元素)
skip 方法主要用于跳过前几个元素,获取一个截取之后的新流。如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用方法如下:
public class Demo11StreamSkip {
public static void main(String[] args) {
Stream original = Stream.of("张三", "李四", "王五");
//跳过前两个,返回一个新的流
Stream result = original.skip(2);
System.out.println(result.count()); // 1
}
}
7. concat(组合合并流)
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
public class Demo12StreamConcat {
public static void main(String[] args) {
Stream streamA = Stream.of("张三");
Stream streamB = Stream.of("李四");
//合并成一个新的流
Stream result = Stream.concat(streamA, streamB);
}
}
8. distinct(筛选)
去除流中重复的元素(使用hashcode和equals方法来对比)
public class Demo11StreamSkip {
public static void main(String[] args) {
Stream original = Stream.of("张三", "张三", "李四");
//筛选重复元素
Stream result = original.distinct();
System.out.println(result.count()); // 2
}
}
9. flatMap(映射,打开后再转换)
flatMap与map作用类似,内部传入一个Function函数式接口,跟map的区别就是这个会把流中的元素打开,再组合成一个新的流。
// map和flatMap的练习
public class StreamDemo {
@Test
public void test(){
List list = Arrays.asList("aa","bb","cc","dd");
// 1 map输出全为大写
list.stream().map(s -> s.toUpperCase()).forEach(System.out::println);
// 2.map流里还有其他流,需要两个遍历才可以得到里面内容
Stream> streamStream = list.stream().map(StreamDemo::fromStringToStream);
streamStream.forEach(s -> {
s.forEach(System.out::println);
});
// 3.flatMap流里还有其他流,使用flatMap可以直接把里面的流打开,一次遍历即可
Stream characterStream = list.stream().flatMap(StreamDemo::fromStringToStream);
characterStream.forEach(System.out::println);
}
/**
* 将字符串中的多个字符构成的集合转换为对应的stream
* @param str
* @return
*/
public static Stream fromStringToStream(String str){
ArrayList list = new ArrayList();
// 将字符串转成字符数组,并遍历加入list集合
for(Character c : str.toCharArray()){
list.add(c);
}
// 返回list集合的stream流
return list.stream();
}
}
10. 定制排序:sorted
本方法主要用于排序,可以使用Comparator接口进行定制排序。具体使用方法如下:
public void test2(){
List integers = List.of(124, 2, 15, 12, 51, -5, 5);
// 按照自然排序
integers.stream().sorted().forEach(System.out::println);
List integers2 = List.of(124, 2, 15, 12, 51, -5, 5);
// 定制排序(大到小),需要传入Comparator接口(如果流中的是引用类型,只能用定制排序)
// 简写:integers2.stream().sorted((e1,e2) -> e2-e1).forEach(System.out::println);
integers2.stream().sorted((e1,e2) -> {
return e2-e1;
}).forEach(System.out::println);
}
11. 检测匹配(终结方法)
本类方法会返回一个Boolean值,具体分类如下:
- 是否全部匹配:allMatch
- 是否至少匹配一个:anyMatch
- 是否没有匹配的:noneMatch
public void test3(){
List integers = List.of(124, 2, 15, 12, 51, -5, 5);
// 判断是否全部大于5
boolean b = integers.stream().allMatch(i -> i > 5);
// 结束输出false
System.out.println(b);
List integers2 = List.of(124, 2, 15, 12, 51, -5, 5);
// 检测是否匹配至少一个元素
boolean b1 = integers2.stream().anyMatch(i -> i > 5);
// 输出true
System.out.println(b1);
List integers3 = List.of(124, 2, 15, 12, 51, -5, 5);
// 检查是否没有匹配的元素
boolean b2 = integers3.stream().noneMatch(i -> i > 1000);
// 输出true,全部不匹配
System.out.println(b2);
}
12. 查找元素(终结方法)
查找第一个元素:findFirst,返回Optional类型
查找其中一个元素:findAny,返回Optional类型
public void test4(){
List integers = List.of(124, 2, 15, 12, 51, -5, 5);
// 输出第一个元素
Optional first = integers.stream().findFirst();
// 输出结果是Optional[124]
System.out.println(first);
List integers2 = List.of(124, 2, 15, 12, 51, -5, 5);
// 返回其中一个元素
Optional any = integers2.stream().findAny();
System.out.println(any);
}
13. 查找最大最小值(终结方法)
max(comparator c)
min(comparator c)
public void test5(){
List list = new ArrayList<>();
list.add(new Person("张三",25,3000));
list.add(new Person("李四",27,2545));
list.add(new Person("王五",35,4515));
list.add(new Person("赵六",55,9877));
//查找年龄最大的人
Optional max = list.stream().max((e1, e2) -> e1.getAge() - e2.getAge());
//返回赵六,55岁年龄最大
System.out.println(max.get());
}
14. 规约(终结方法)
reduce(T identity,BinaryOperator) 第一个参数是初始值,第二个参数是一个函数式接口。
reduce(BinaryOperator) 参数是一个函数式接口
public void test(){
List integers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 求集合里数字的和(归约)reduce第一个参数是初始值。
Integer sum = integers.stream().reduce(0, Integer::sum);
System.out.println(sum);
List list = new ArrayList<>();
list.add(new Person("张三",25,3000));
list.add(new Person("李四",27,2545));
list.add(new Person("王五",35,4515));
list.add(new Person("赵六",55,9877));
// 求所有人的工资和(归约)
// 不用方法引用写法:Optional reduce = list.stream().map(person -> person.getSalary()).reduce((e1, e2) -> e1 + e2);
Optional reduce = list.stream().map(Person::getSalary).reduce(Integer::sum);
// 输出Optional[19937]
System.out.println(reduce);
}
15. 收集(终结方法)
collect(Collector c):将流转化为其他形式,接收一个Collector接口的实现
public void test(){
List list = new ArrayList<>();
list.add(new Person("张三",25,3000));
list.add(new Person("李四",27,2545));
list.add(new Person("王五",35,4515));
list.add(new Person("赵六",55,9877));
// 把年龄大于30岁的人,转成一个list集合
List collect = list.stream().filter(person -> person.getAge() > 30).collect(Collectors.toList());
// 遍历输出(输出王五和赵六)
for (Person person : collect) {
System.out.println(person);
}
List list2 = new ArrayList<>();
list.add(new Person("张三",25,3000));
list.add(new Person("李四",27,2545));
list.add(new Person("王五",35,4515));
list.add(new Person("张三丰",55,9877));
// 把姓张的人,转成Set集合
Set set = list2.stream().filter(person -> person.getName().startsWith("张")).collect(Collectors.toSet());
// 输出张三和张三丰
set.forEach(System.out::println);
}
16. iterate(迭代)
可以使用Stream.iterate创建流值,即所谓的无限流。
//Stream.iterate(initial value, next value)
Stream.iterate(0, n -> n + 1)
.limit(5)
.forEach(x -> System.out.println(x));
//输出0 1 2 3 417. peek(查看)
peek接收的是一个Consumer函数,peek 操作会按照 Consumer 函数提供的逻辑去消费流中的每一个元素,同时有可能改变元素内部的一些属性
public void test(){
List collect = Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("查看刚过滤出的值:" + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("查看转大写之后的值:" + e))
.collect(Collectors.toList());
// 遍历过滤后的集合
for (String s : collect) {
System.out.println(s);
}
}
输出如下:
查看刚过滤出的值:three
查看转大写之后的值:THREE
查看刚过滤出的值:four
查看转大写之后的值:FOUR
----------
THREE
FOUR
四、parallelStream并行流简介及对比
1. parallelStream并行流简介
本文只进行简单介绍及对比,后续文章中会对parallelStream并行流进行详细介绍和分析。
Java8中提供了能够更方便处理集合数据的Stream类,其中parallelStream()方法能够充分利用多核CPU的优势,使用多线程加快对集合数据的处理速度。
parallelStream()方法的源码如下:
/**
* @return a possibly parallel {@code Stream} over the elements in this
* collection
* @since 1.8
*/
default Stream parallelStream() {
return StreamSupport.stream(spliterator(), true);
} 2. 对比
stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:
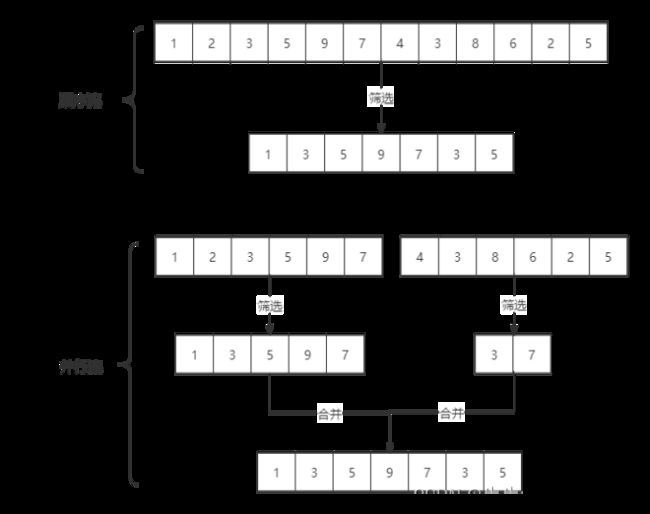
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional findFirst = list.stream().parallel().filter(x->x>6).findFirst();
总结
本文详细介绍了Stream流的基本概念和用法,最后简单介绍了parallelStream并行流及与Stream流的对比。通过上述内容基本对工作中可能遇到的概念及常用方法进行了梳理,希望本文可以给读者带来帮助。