深度学习笔记之残差网络(ResNet)
深度学习笔记之残差网络[ResNet]
- 引言
-
- 引子:深度神经网络的性能问题
- 核心问题:深层神经网络训练难
- 残差网络的执行过程
- 残差网络结构为什么能够解决核心问题
- 残差网络的其他优秀性质
引言
本节将介绍残差网络( Residual Network,ResNet \text{Residual Network,ResNet} Residual Network,ResNet),本篇不是论文解读,仅针对论文种提到的问题进行描述,并介绍残差网络的原理。
论文链接: Deep Residual Learning for Image Recognition \text{Deep Residual Learning for Image Recognition} Deep Residual Learning for Image Recognition
引子:深度神经网络的性能问题
我们不否认,深度神经网络相比浅层,能够学习到更深层次的、更加丰富的特征信息。
但是一个神经网络模型层数越深,并不代表神经网络的性能越优秀。神经网络隐藏层数量越多,意味着反向传播过程中针对深层神经元(距离输入层更近的部分)梯度消失的可能性越高。为了预防/缓解这种情况,我们通常会使用:
- 在模型训练之前,随机初始化权重的分布 要稳定,尽量避免出现个别初始化权重过大/过小的情况;
与权重初始化相关的一篇文章:权重初始化方式——零初始化 - 使用批标准化( Batch Normalization \text{Batch Normalization} Batch Normalization)。通过增加一些 Normalization Layers \text{Normalization Layers} Normalization Layers来约束各隐藏层输出关于权重梯度的偏差和方差。
其次,深度神经网络使得网络的复杂程度增大,在训练过程中容易出现过拟合 ( Overfitting ) (\text{Overfitting}) (Overfitting)。
这里观察论文中的图 1 1 1,它描述的是不同深度的神经网络对于同一数据集 ( CIFAR-10 ) (\text{CIFAR-10}) (CIFAR-10)训练和测试过程中错误率 ( Error Rate ) (\text{Error Rate}) (Error Rate)的变化情况:
题外话:错误率像‘阶梯形式’的下降过程,主要是通过减小学习率得到的效果。

通过上述图像观察可知,深层网络(红色线)的错误率下降情况明显不如浅层网络(黄色线),这里我们并不排除过拟合产生的影响,但也不全是过拟合产生的效果:
- 如果仅是过拟合现象导致的结果,那么无论是深层网络 ( 56-Layer ) (\text{56-Layer}) (56-Layer)还是浅层网络 ( 20-Layer ) (\text{20-Layer}) (20-Layer),它的训练过程产生的错误率应该是相近的;而仅在测试过程中存在较大差距。
- 但实际情况是:无论在训练过程还是测试过程深层网络与浅层网络之间 均存在较大差距。这只能说明:在针对该数据集的学习过程中,深层网络模型在性能方面劣于浅层网络模型。
核心问题:深层神经网络训练难
分析上述示例,为什么神经网络层数增加后,精度反而会变差 ? ? ?
-
暂时抛开神经网络的学习过程,仅从逻辑角度思考:如果某浅层网络对于数据集存在一个比较不错的拟合效果,那么对应深层网络(向浅层网络中插入一些新的层)的拟合效果也不应该变得很差。观察下图:
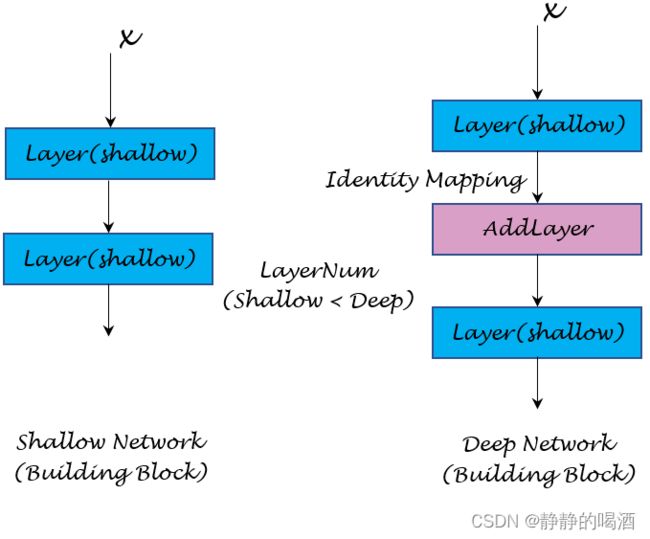
其中左图表示浅层网络 ( Shallow Network ) (\text{Shallow Network}) (Shallow Network)的某部分 ( Buliding Block ) (\text{Buliding Block}) (Buliding Block);而右图表示在对应浅层网络位置插入一个新的网络层而构成的深层网络 ( Deep Network ) (\text{Deep Network}) (Deep Network)。
当然,整个网络并非仅加入了这一层,这仅仅描述网络某部分的变化;并且图中添加层的位置也不唯一,任意位置均可。以上图中这种插入方式为例,我们可以将这个新网络层 ( AddLayer ) (\text{AddLayer}) (AddLayer)看作成未插入之前两隐藏层之间的恒等映射 ( Identity Mapping ) (\text{Identity Mapping}) (Identity Mapping)。也就是说,它仅仅是对原始网络层做了一个简单的传递工作—— AddLayer \text{AddLayer} AddLayer插入之后,其输出与浅层网络的对应输出几乎没有变化。从而也不影响后续的传递过程。
-
逻辑角度观察该情况时是过于理想的。实际情况下,由于神经网络的反向传播过程,它只会将更多有效梯度传递到较浅的网络层(距离输出层近的那些网络层),而较深的网络层梯度的传递效果较差(梯度变化的效果较小 / / /过小)。见下图:
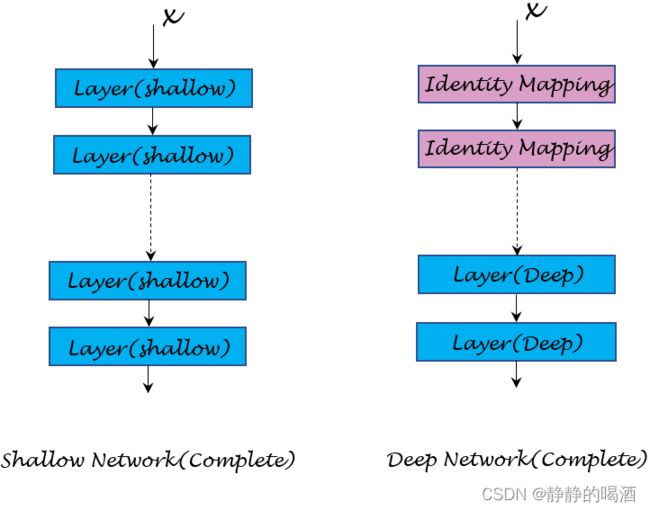
对应那些较深的网络,它们获取的梯度很小,甚至是几乎没有变化。这意味着:有没有这个层影响不大。而满足这种条件的无效层就可看作是逻辑角度中的恒等映射。
第二种情况仅仅说明‘神经网络’学习过程中的Identity Mapping \text{Identity Mapping} Identity Mapping和逻辑角度认知的Identity Mapping \text{Identity Mapping} Identity Mapping之间存在偏差。但它依然按照逻辑角度认知执行的。 -
但在执行真正的学习过程,使用算法对最优权重迭代的过程中(论文中使用的是随机梯度下降 ( Stochastic Gradient Descent,SGD ) (\text{Stochastic Gradient Descent,SGD}) (Stochastic Gradient Descent,SGD))基于第二种情况无法找到和浅层效果相当的精确解。
个人理解:上面说的那么多,想表达的意思是:深度模型的学习性能差绝不仅仅是因为‘过拟合/梯度消失’产生的结果:而是在原始神经网络已经有比较不错的拟合效果的条件下,强行地增加了神经元/网络层的数量,从而使网络深层部分梯度没有有效传达导致这些层/神经元成为了恒等映射。这个恒等映射是存在偏差的。个人认为主要原因是模型权重初始化的问题。我们的本意想让初始化的参数通过反向传播算法将其优化为有益的权重信息;但是这些深层网络的权重因梯度消失的原因,并没有得到有效的优化/甚至是没有被优化。这反而使这些未优化好的权重成为了噪声/累赘,从而导致了模型性能降低。可以对比一下,假设将‘浅层网络’内增加一系列对浅层网络输出完全不产生任何影响,并且不传播梯度的0 0 0层,这么一比较自然会出现差距:

该部分有个人想法的小伙伴欢迎一起探讨。
残差网络的执行过程
残差网络提出一种通过人为构造恒等映射 的方式,使它能让更深的网络更容易地训练,并且学习效果越好。
- 首先观察正常情况下/没有执行残差连接 ( Residual Connection ) (\text{Residual Connection}) (Residual Connection)的神经网络前馈计算过程:
这里依然使用其中一个部分( Building Block ) (\text{Building Block}) (Building Block)进行描述。
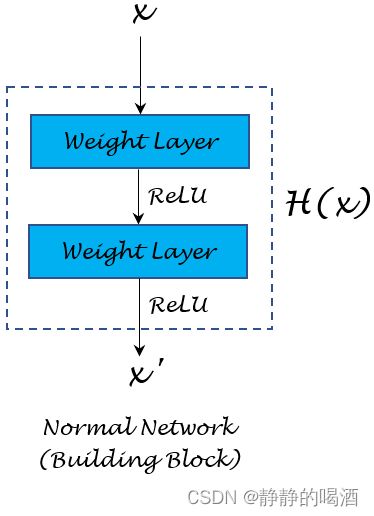
假设输入部分 x x x与输出部分 x ′ x' x′大小、形状相同。那么上述 Building Block \text{Building Block} Building Block的整个前馈计算过程可描述为:
x ′ = H ( x ) x' = \mathcal H(x) x′=H(x)
很明显, x ′ x' x′可理解为 基于 x x x 的抽象特征信息;而神经网络学习的对象就是 x x x自身。该方式的缺陷在上面介绍过了:无论增加多少个隐藏层,其本质上依然是对 x x x特征的抽象描述。梯度消失、过拟合、模型性能降低等等隐患都可能存在。 - 而残差网络的核心在于:神经网络并不对 x x x进行抽象描述,而是对 H ( x ) − x \mathcal H(x) - x H(x)−x进行抽象描述。它的神经网络前馈计算过程表示如下:

同理,整个前馈计算过程可描述为:
x ′ = H ( x ) = F ( x ) + x x' = \mathcal H(x) = \mathcal F(x) + x x′=H(x)=F(x)+x
依然是同样的神经网络层,但该神经网络层学习出的函数是 F ( x ) = H ( x ) − x \mathcal F(x) = \mathcal H(x) - x F(x)=H(x)−x,区别于正常神经网络中的 H ( x ) \mathcal H(x) H(x)自身。从该式子中也可以看出,这里的神经网络层学习的对象是 输出特征 x ′ x' x′与输入特征 x x x之间的残差。
残差网络结构为什么能够解决核心问题
我们将上述的残差块 ( Block ) (\text{Block}) (Block)补全,成为一个完整的残差网络:
这里就把最深层和最浅层的残差块表示出来,其余的都省略啦。

为什么能够出现神经网络层数越深,神经网络的训练效果越好的情况呢 ? ? ?我们对比一下残差网络与正常神经网络的前馈计算过程。
有一点是相同的:残差网络中的网络层同样会存在梯度消失的情况。也就是说,残差网络和正常网络的深层网络它的梯度传递效果都会出现这种问题。
但相比于正常网络中深层网络作为噪声/累赘,由于残差网络学习的对象是残差信息而非数据特征本身,每一个残差块的输出由两部分构成:
- 上一层的输出信息(如果是第一个残差块,该信息就是样本输入特征);
- 残差信息。
假设残差网络对样本进行拟合时,并且出现了梯度消失现象。此时,关于深度最深的残差块(第一个残差块),我们可以分析一下它的状态:
-
该残差块中的神经元因梯度消失——并没有更新出有效的梯度。这意味着,残差块中神经网络的输出信息中有效信息不多——更多是以随机初始化的噪声为主;
-
但残差块的输出信息不仅包含神经网络的输出,而且还包含样本输入特征——这意味着:即便是最深的残差块,它同样会输出有效的信息。如果我们能够将样本输入特征的分布和第一个残差块的输出分布,比较一下,可以发现它们的分布几乎没有差别。这说明,样本输入特征占据了主导作用。
如果从网络图的角度观察,如果某残差块学习出了一堆噪声,我们完全可以忽视这个残差块。看作是从下一个残差块开始进行前馈计算,以此类推:

-
并且随着前馈计算由深层传向浅层,随着权重特征越来越丰富,对应的上一层输出比重也会逐渐减小。
并且,在前馈计算过程中,由于每一个残差块都会使用神经网络拟合上一层的残差信息,随着神经网络的加深,我们学习结果的偏差只会越来越小。这个操作和集成学习中的 Gradient Boosting \text{Gradient Boosting} Gradient Boosting思想存在相似之处。两者的主要区别在于:
- Gradient Boosting \text{Gradient Boosting} Gradient Boosting在每次迭代过程中,使用基学习器学习标签的残差信息;
- 而残差网络在每一个残差块的前馈计算过程中,对上一个残差块输出特征中的残差信息进行学习。
残差网络的其他优秀性质
-
对于梯度的保持比较优秀。如果对正常的神经网络进行梯度计算,那么该层输出 x ′ x' x′表示为如下形式:
为了简化表达,这里仅描述一层F [ G ( x ) ] = σ [ W T G ( x ) + b ] \mathcal F[\mathcal G(x)]=\sigma \left[\mathcal W^T\mathcal G(x) + b \right] F[G(x)]=σ[WTG(x)+b],下同。这里的G ( x ) \mathcal G(x) G(x)表示该网络层的输入,也就是之前网络层的输出,将其看做成一个复杂函数。
x ′ = F [ G ( x ) ] x' = \mathcal F[\mathcal G(x)] x′=F[G(x)]
关于损失函数在该层上的梯度可表示为:
这里仅对∂ x ′ ∂ x \begin{aligned}\frac{\partial x'}{\partial x}\end{aligned} ∂x∂x′进行表示,下同。
∂ x ′ ∂ x = ∂ F [ G ( x ) ] ∂ G ( x ) ⋅ ∂ G ( x ) ∂ x = { σ ′ [ W T G ( x ) + b ] ⋅ W } ⋅ ∂ G ( x ) ∂ x \begin{aligned} \frac{\partial x'}{\partial x} & = \frac{\partial \mathcal F[\mathcal G(x)]}{\partial \mathcal G(x)} \cdot \frac{\partial \mathcal G(x)}{\partial x} \\ & = \left\{\sigma' \left[\mathcal W^T\mathcal G(x) + b \right] \cdot \mathcal W\right\} \cdot \frac{\partial \mathcal G(x)}{\partial x} \end{aligned} ∂x∂x′=∂G(x)∂F[G(x)]⋅∂x∂G(x)={σ′[WTG(x)+b]⋅W}⋅∂x∂G(x)
如果是残差网络,它的残差块输出 x ′ x' x′表示为如下形式:
x ′ = F [ G ( x ) ] + G ( x ) x' = \mathcal F[\mathcal G(x)] + \mathcal G(x) x′=F[G(x)]+G(x)
关于损失函数在该残差块上的梯度可表示为:
∂ x ′ ∂ x = ∂ { F [ G ( x ) ] + G ( x ) } ∂ G ( x ) ⋅ ∂ G ( x ) ∂ x = { 1 + σ ′ [ W T G ( x ) + b ] ⋅ W } ⋅ ∂ G ( x ) ∂ x \begin{aligned} \frac{\partial x'}{\partial x} & = \frac{\partial \{\mathcal F[\mathcal G(x)] + \mathcal G(x)\}}{\partial \mathcal G(x)} \cdot \frac{\partial \mathcal G(x)}{\partial x} \\ & = \left\{1 + \sigma' \left[\mathcal W^T \mathcal G(x) + b\right] \cdot \mathcal W\right\} \cdot \frac{\partial \mathcal G(x)}{\partial x} \end{aligned} ∂x∂x′=∂G(x)∂{F[G(x)]+G(x)}⋅∂x∂G(x)={1+σ′[WTG(x)+b]⋅W}⋅∂x∂G(x)
很明显,系数 1 + σ ′ [ W T G ( x ) + b ] ⋅ W > σ ′ [ W T G ( x ) + b ] ⋅ W 1 + \sigma' \left[\mathcal W^T \mathcal G(x) + b\right] \cdot \mathcal W > \sigma' \left[\mathcal W^T \mathcal G(x) + b\right] \cdot \mathcal W 1+σ′[WTG(x)+b]⋅W>σ′[WTG(x)+b]⋅W,从而梯度数值更大了。也就是说,它将正常的神经网络梯度与残差梯度融合在一起了,使其在反向传播过程中能够将权重梯度传播到更新到更深层的权重中。 -
残差网络与其他优化方式不冲突。使用残差网络,我们依然可以在残差块中依然可以使用像 Dropout \text{Dropout} Dropout、批标准化 Batch Normalization \text{Batch Normalization} Batch Normalization等方式对其内部神经元、以及输出特征进行优化处理。
相关参考:
ResNet论文逐段精读【论文精读】