智能对话之对话管理综述

随着互联网的发展,各大线上平台都拥有大量的用户粉丝,那么用户与商家的会有大量的沟通,尤其在电商平台或者机器人市场有很大的需求,然而人工客服效率低以及成本高,难以满足客户的需求,智能对话是一个必然的趋势。
1950年提出的图灵测试,一个机器人和自然人交流,如果这个自然人以为是和自然人交流,那么就是说通过了图灵测试,这可以看做是”最早“的”智能对话了。
一、对话系统的发展阶段
目前对话系统可以分为三个阶段:
第一个阶段是在1966年MIT提出的ELIZA系统,是基于规则和模板的对话系统,主要用于心理治疗。70年代引入了有限状态自动机FSA来模拟状态之间的转移,这种方式灵活性和扩展性都比较低,而且严重依赖专家的经验;
第二个阶段是在大数据时代背景下的基于数据驱动的统计方法,同时强化学习也被广泛的应用于对话系统中,比如2005年剑桥大学使用POMDP应用对话系统,这个系统基于语音识别的结果使用户贝叶斯推断来维护每轮对话的状态,然后基于对话状态选择一个对话策略来生成一个比较自然的回复。这个系统和通过和用户模拟器或者真实人交互来不停的优化系统,进一步降低错误,这也体现了强化学习的伟大;
第三个阶段是基于深度学习的模型,模型结构采用基于统计方法的,由于深度学习的表示能力更强,每个模块使用深度学习的CNNs或者RNNs来替换。对话状态是通过直接计算最大条件概率,而不是贝叶斯的后验概率,深度强化学习DQN去优化对话策略。第三阶段的模型通过比第二阶段的模型表现的好,但是需要大量的高质量的数据作为支撑。
二、对话系统的任务类型
2.1、闲聊:顾名思义,不多讲
2.2、任务型对话:通过多轮对话,辅助用户完成某个任务,比如订机票
2.3、问答系统:针对用户的问题,给出准确的答案,类似搜索引擎做的事情
三、任务型对话系统的系统架构
3.1、pipeline模式
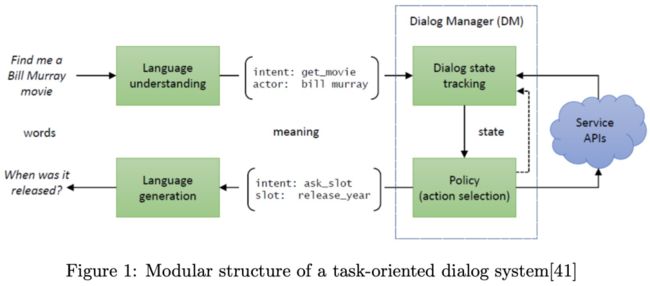
如上图Figure1所示,pipeline模式主要是对对话系统的整体结构做了四个模块的拆分NLU、DST、DM和NLG,每个模块独立工作,并且模块之间进行交互
NLU(自然语言理解):主要是理解用户的意图以及槽位填充(也就是NER);
DST(对话状态跟踪):用于记录用户的历史聊天记录,保证整个对话的继承性;
DP(对话策略):基于用户当前状态给出下一个状态的行为,这个策略和目的有关系,一般任务型对话希望对话的轮数越少越好;
NLG(自然语言生成):把当前的用户状态转换为自然语言输出给用户。
这种模式不太灵活,每个模块是独立的,很难整体优化,难以适应新的场景,一个模块的更新有可能导致整个系统的调整。
3.2、end-to-end模式
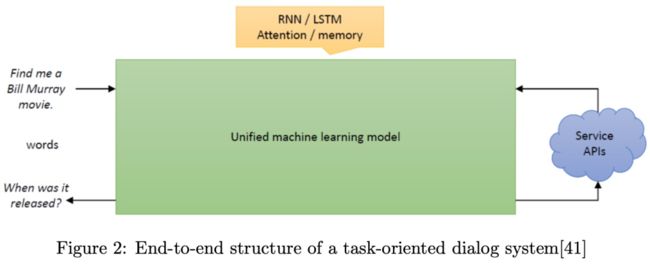
这种end-to-end的模式直接根据用户的输入与用户输出进行建模,灵活且扩展性高,但是需要大量的高质量数据,这种方式仍然处于学术探索阶段,工业界很少使用。
四、传统对话系统的不足
4.1、Poor scalability
4.2、Insufficient tagged data
4.3、Low training efficiency
本文主要是针对以上三点不足,梳理目前的一些经典改进方案
4.1、Poor scalability
扩展性差主要的解决方法是:如何处理用户意图的变化;如何处理槽位值的变化;如何处理系统动作的变化。
1)如何处理用户意图的变化
传统的意图识别是有监督的学习方式,如果新的意图没有出现在之前的训练数据中,那么就不能识别出这种意图;如果要识别这种意图,就需要把新意图对应的数据加入到模型中进行重新训练,这导致模型的扩展和维护很困难。
《A Teacher-Student Framework for Maintainable Dialog Manager》
这个paper提出teacher-student知识蒸馏的方式来解决上述问题,把已经训练好的模型和逻辑规则作为teacher,把新模型作为student。针对之前的意图,老模型会直接输出每个意图的概率;对于新意图,使用逻辑规则来标注数据并且训练新模型,这样就不需要重新训练新模型了,下图是在数据集DSTC2上做的实验:
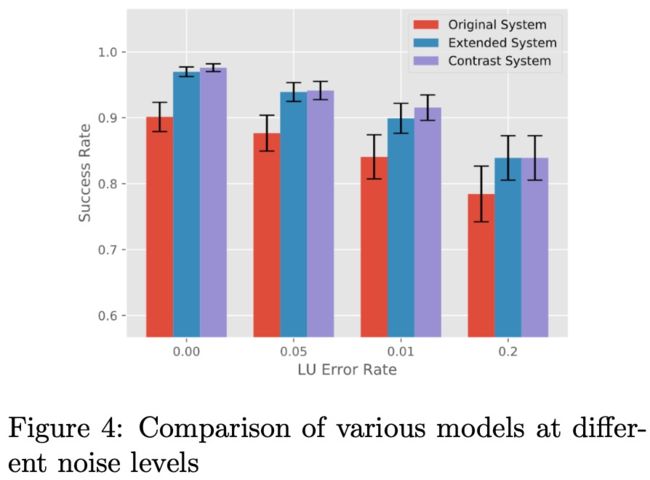
Extended System表示新模型,Contrast System表示所有意图的综合模型。实验表明新模型在新的意图上有一些的提升。
《Zero-Shot Learning of Intent Embeddings for Expansion by Convolutional Deep Structured Semantic Models》
上述方案的模型需要进一步训练的,CDSSM基于语义相似度模型来匹配用户的新意图,不需要标注数据,也不需要重新训练模型。CDSSM把用户的意图和意图描述分别编码成高维向量,根据用户的意图描述生成的向量识别用户的意图。
《Learning End-to-End Goal-Oriented Dialog with Maximal User Task Success and Minimal Human Agent Use》
此论文提供了另一种思路,人机协作的方式。系统识别用户新意图(不在训练数据中)的时候需要人工客服介入帮助识别意图,模型有一个辅助的神经元解析器来决定是采用人工客服的建议还是系统自动识别的意图。
2)如何处理槽位值的变化
对话系统中的槽位其实就是命名实体,然而大部分都是非枚举实体,比如“时间”,“地理位置”等等,在传统的DST中,这些槽位和槽位的值一般默认是不变的,然而这样扩展性比较差。
google研究员提出了一种解决方案,使用双向RNN为每个槽位维护最可能的k个槽位值并且对他们进行排序,为了跟踪不在候选集的槽位值,可以使用序列标注模型或者语义相似度匹配模型。
上述是对槽位值的变更的方案,那么如果槽位有变化,如何跟踪呢?
《Towards zero-shot frame semantic pars- ing for domain scaling》
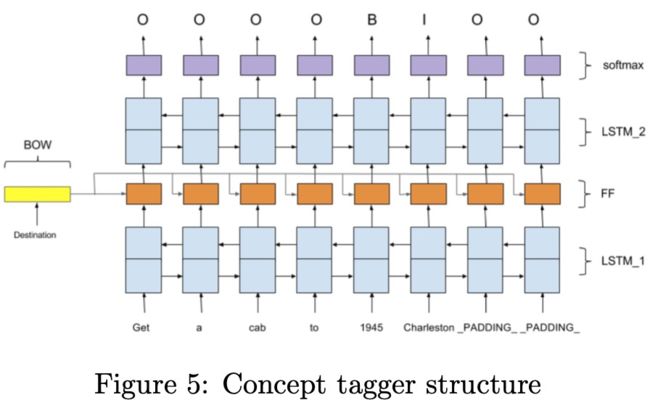
首先对槽位的描述和新的槽位使用Bi-LSTM进行编码,槽位值就是序列的标签,如上图Figure5所示。
《Transferable Multi-Domain State Gen- erator for Task-Oriented Dialogue Systems》
最近seq2seq模型,注意力机制以及copy机制对生成任务有一个比较大的提升。香港科技大学提出的TRADE模型在MultiWOZ数据集上提升了非枚举槽位值的准确率。模型结构如下图Figure6所示:
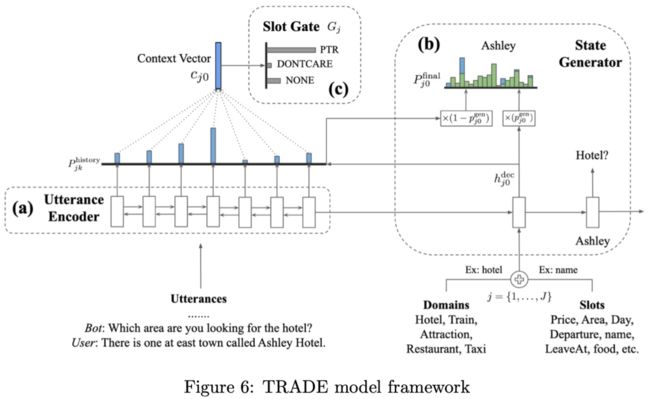
每次检测槽位值时,该模型对域和槽位的不同组合执行语义编码,并将结果用作RNN解码器的初始输入位置。解码器通过复制网络直接产生槽位值。这样,非枚举槽位值和更改槽位值都可以由同一个模型生成。因此,可以在域之间共享槽位值,从而使模型得到广泛应用。
最近的研究倾向于将多领域DST视为一项机器阅读和理解任务,并将TRADE等生成模型转化为判别模型。非枚举槽位值可以理解为机器阅读理解任务,比如SQuAD,把对话的历史和问题的片段文本作为槽位值。通过阅读理解任务可以选择多个可枚举的槽位值,从候选值中选择正确的值作为预测槽位值。利用更多预训练模型,如ELMO和BERT,MultiWOZ数据集还可以进一步得到优化。
3)如何处理系统动作的变化
问答系统中,很多情况下用户会问到系统没有预定义好的问题,这样通过会回答出用户难以接受和理解的答案。微软2015年在DQN的基础上提出了DRRN模型来解决上述问题,下面将介绍这个paper的思想:
《Deep reinforcement learning with a natural language action space》
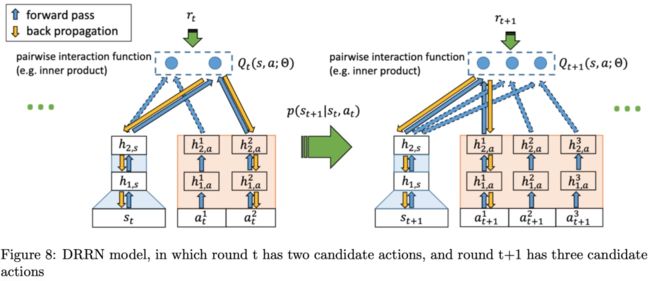
上图Figure8是DRRN的网络结构,作者把对话任务看做是一个文本游戏任务。每一轮action都是一个单一的句子,action的数量是不确定的。作者提出了一种新的深度强化关联网络(DRRN)模型,通过语义相似度匹配将当前对话状态与可选系统动作进行匹配,得到Q函数。具体地说,在一轮对话中,每个长度不确定的动作文本通过神经网络编码,得到一个长度固定的系统动作向量。句子内容由另一个神经网络编码,得到一个固定长度的对话状态向量。这两个向量通过一个相互作用的函数,比如点积,产生最终的Q值。实验表明,DRRN在文本游戏“拯救约翰”和“死亡机器”中的表现优于传统的DQN。
《Incremental Learning from Scratch for Task-Oriented Dialogue Systems》
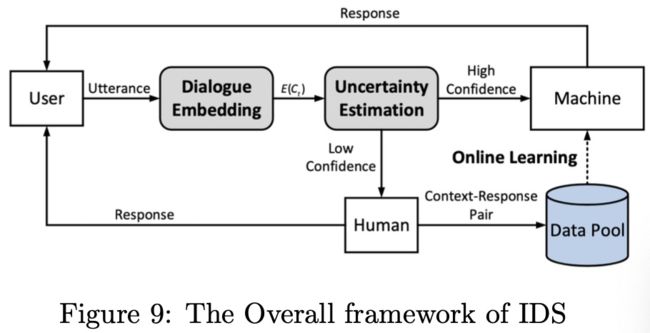
在这篇论文中,作者希望从整个对话系统的角度来解决这个问题,并提出了增量对话系统(IDS),如图Figure9所示。IDS首先通过对话嵌入模块对对话历史进行编码以获得上下文向量,然后使用基于VAE的不确定性估计模块根据上下文向量评估,根据置信水平来判断当前系统给出正确答案是否正确。与主动学习类似,如果置信水平高于阈值,DM将对所有可用的action进行评分计算,然后基于softmax函数预测概率分布。如果置信度低于阈值,则要求标记人员标记当前轮的响应(选择正确的响应或创建新的响应)。以这种方式获得的新数据被添加到数据池中,以在线更新模型。通过这种人性化的教学方法,IDS不仅支持在不受限制的动作空间中学习,而且能够快速收集高质量的数据,非常适合实际生产。
4.2、Insufficient tagged data
基于任务的对话系统通常不同领域的标注数据越多效果越好,但是标注数据的代价往往很大,学者提出一些三种方式来解决此问题:1)使用机器来自动化标注;2)挖掘对话框架来尽可能的使用无标注数据;3)优化数据收集策略来高效的获取高质量数据。下面分别介绍一下这三种方式的具体思路:
1)Automatic Tagging
《Auto- Dialabel: Labeling Dialogue Data with Unsupervised Learning》
![]()
此paper的网络结构如上图Figure10所示,主要思路是通过层次聚类算法来自动聚类对话数据中的意图和槽位,假设相同意图那么也应该有相同的特征。首先特征抽取可以使用词向量、POS、LDA等,然后所有特征使用自编码器编码为相同维度的向量并且拼接起来,使用RBF计算类内距离,合并类内距离小于某个阈值的类。
2)Dialog Structure Mining
对于对话系统,高质量的标注数据往往比较缺乏,很多研究者越来越多的关注隐性的对话结构或者无标注的对话数据,下面介绍两篇paper说明一下具体的做法。
《Unsupervised Dia- log Structure Learning》
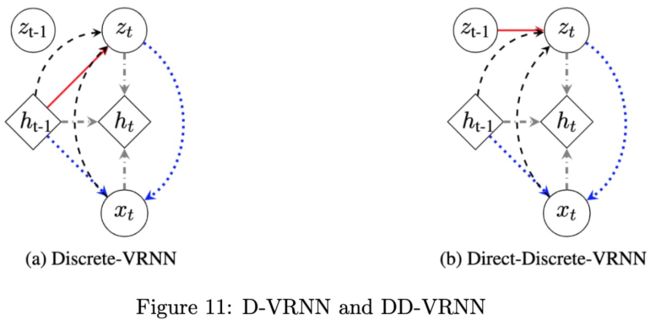
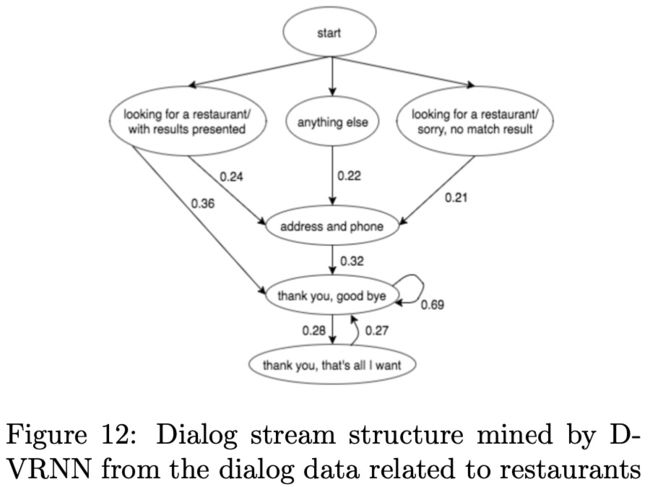
如上图Figure11所示,作者使用RNN的变种VRNN来自动学习对话数据中的隐藏结构,具体是使用Discrete-VRNN (D-VRNN)和DirectDiscrete-VRNN (DD-VRNN)来获取动态信息,xt表示第t轮对话,ht表示对话历史的隐藏变量,zt表示表示对话结构的隐藏变量(是一维的one-hot形式),使用VAE来估计隐藏变量zt的后验概率,最后通过极大似然求解。
实验证明VRNN优于HMM,VRNN把对话结构信息加入到强化学习的reward函数,加快了强化学习模型的收敛,下图Figure12是D-VRNN隐藏变量zt的转移概率。
《Rethink- ing action spaces for reinforcement learn- ing in end-to-end dialog agents with la- tent variable models》
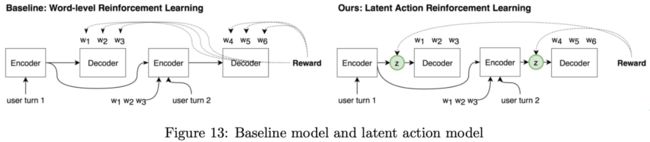
CMU学者使用VAE方法把动作表示为隐藏变量,然后直接使用这些隐藏变量来选择action,提出了一个end-to-end的方法,如上图Figure13所示。baseline的模型是一个基于word的强化学习模型(每个word当作一个action),该模型使用编码器编码对话历史,并且使用解码器生成一个回复,reward函数直接比较真实值与预测值差;而latent模型在编码器和解码器增加了一个后验概率,并且使用离散隐藏变量来表示对话的action,而不需要人工干预。实验表明latent模型比baseline模型在回复多样性和任务完成率上都好。
3)Data Collection
《Bootstrapping a neural conversational agent with dialogue self-play, crowd- sourcing and on-line reinforcement learn- ing》
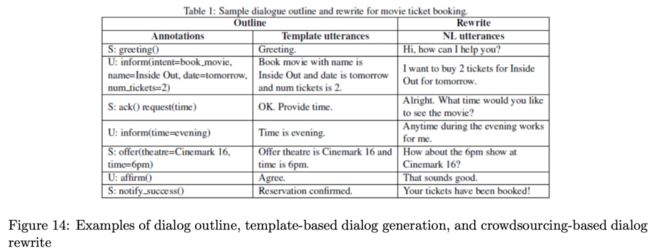
Google研究员提出了一种快速收集数据的方式,如上图Figure14。首先在一个语义标签的对话框架下使用两个规则模拟器来进行交互生成对话大纲,然后基于模板把这些语义标签转换为自然语言对话,最后基于众包再丰富对话数据的表达。这种方式不可能覆盖所有的场景,而且严重依赖模拟器。
其实还有两种更容易理解的方式:human-to-machine (H2M) and human-to-human (H2H),H2H需要两个人进行自然对话收集数据,称为Wizard-of-Oz框架,比如数据集WOZ和MultiWOZ就是采用这种方式收集的,这种方式设计场景和清洗数据代价比较大。H2M是人与机器对话获取数据的方式,通过强化学习来进行在线收集数据从而改善对话管理模型,著名的数据集DSTC2&3就是采用这种方式收集的,这种方式比较依赖DM模型的初始性能,噪音也比较大。
4.3、Low training efficiency
1)Model-Free RL - HRL
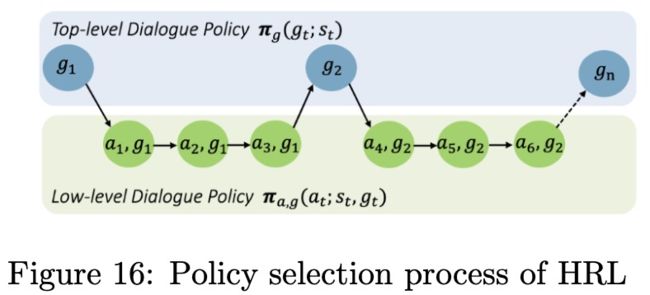
《Composite task-completion dialogue policy learning via hierarchical deep reinforcement learn- ing》
层次强化学习是把一个复杂的任务分解为多个子任务来避免传统flat强化学习维度灾难问题,此paper按照时间顺序把一个复杂任务分解为多个子任务,例如分解为预定机票、预定酒店、租车。作者把DM模块分为两个部分Top-level和Low-level,其中Top-level基于对话状态选择子任务;Low-level完成子任务的特定对话action。如Figure16所示:
2)Model-free RL - FRL
《Feudal reinforcement learning for di- alogue management in large domains》
FRL可以解决高维问题,HRL是在时间上做了一个分解,而FRL通过限制每个子任务的动作空间来减少子策略的复杂度,不是把一个任务进行拆分为子任务,它是使用状态空间的抽象函数来抽取对话状态的有用特征,这种抽象使的FRL可以在不同的领域进行迁移,扩展性高。
剑桥大学学者首次把FRL引入到对话系统,通过相关的槽位来拆分动作空间,决策过程如图Figure17所示:
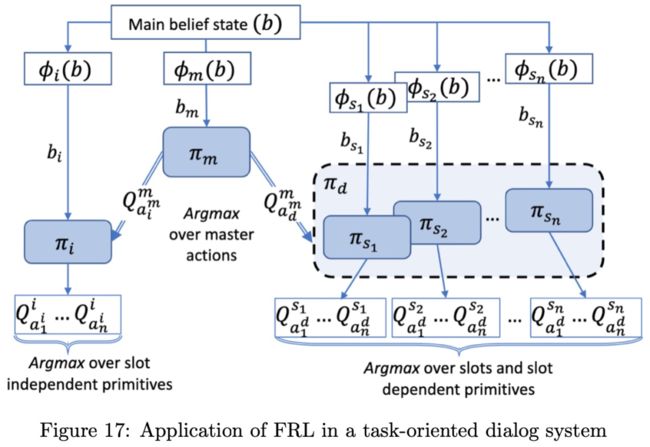
决策过程分为如下两步:
step1:接下来的action决定把哪些槽位作为参数;
step2:根据step1的决策选择对应该槽位的low-level策略和接下来的action
一般而言,HRL和FRL都可以把高维复杂的action空间分解,HRL需要专家知识;而FRL依赖action的逻辑结构,不需要考虑子任务之间手动限制。
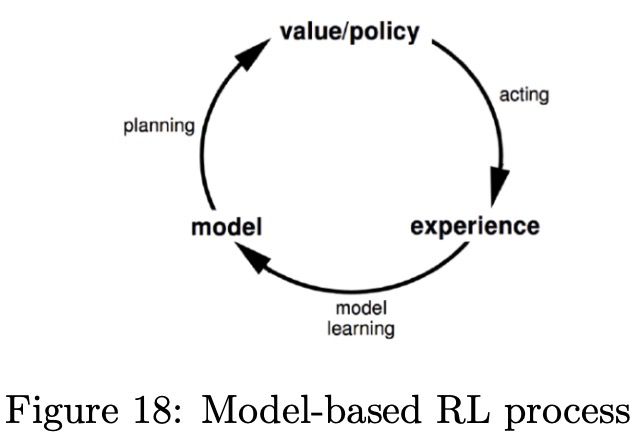
3)Model-Based RL
基于模型的强化学习是环境的状态已知情况下的强化学习,模型与环境进行交互来学习状态的转移概率和回报reward,结构如下图Figure18所示:
《Deep dyna-q: Integrating planning for task-completion dialogue policy learning》
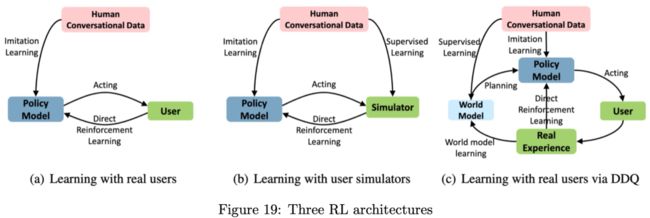
微软首次应用Deep Dyna-Q (DDQ)在对话系统中,如上图Figure19(c)所示。在训练DDQ模型之前,需要少量的对话数据来预训练policy模型和the world model,然后可以重复下面的步骤开始训练:
step1:Direct RL:与真实用户在线交互,并且更新policy模型和存储对话数据;
step2:World model training:基于收集到的真实对话数据更新the world model;
step3:Planning:使用与the world model交互的对话数据来训练policy模型与Figure19(a)对比,DDQ减少了数据获取所需要的人机交互;与Figure19(b)对比,DDQ避免了与用户模拟器的无效交互;DDQ是通过the world model来完成模拟真实用户交互的。
the world model的结构如下图Figure20所示:

the world model的输入是当前对话状态和系统的action动作,输出是用户的下一个action、回报reward和对话终止符合。
微软后来针对DDQ做了一些改进,具体如下:
《Discriminative deep dyna-q: Robust planning for dialogue policy learning》
使用对抗训练来提高the world model生成数据的权威。
《Switch-based active deep dyna-q: Efficient adaptive planning for task-completion dialogue policy learning》
考虑了什么时候使用真实用户交互什么时候使用the world model生成数据。
《Budgeted Policy Learning for Task-Oriented Dialogue Systems》
讨论了一个统一的对话框架。
4)Human-in-the-Loop
《Agent-agnostic human-in-the-loop re- inforcement learning》
在强化学习的过程中,如果可以引入人类的知识和经验来生成高质量的数据,势必会提高模型的性能。此paper提出一种人机协作的方式来训练模型,人可以在有监督预训练模型出现偏差的时候进行纠错,算法实现如下图Figure21所示:

亚马逊研究员也提出了类似上述的框架,在每轮对话中,系统推荐给专家四个候选回复,专家从中选择一个或者专家生成一个作为最终的回复,使用此方式,开发人员可以快速更新对话系统的能力。
《Agent-aware dropout dqn for safe and efficient on-line dialogue policy learning》
之前的方法都是被动接受人的标注数据来学习的,然而一个好的系统应该可以主动向人类提问并且寻求帮助,此paper在传统的强化学习框架下增加了老师的角色,提出了一种冠军学习架构,如下图Figure22所示:
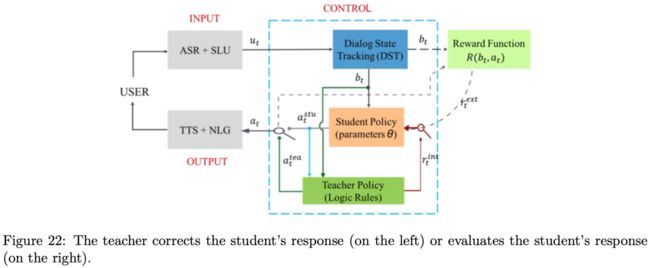
教师可以纠正对话系统的响应(学生,由图左侧的开关表示),并以内在奖励的形式评估学生的响应(图右侧的开关)。为了实现主动学习,作者提出了对话决策确定性的概念。学生policy网络通过dropout的方式进行多次抽样,以获得期望行动的估计近似最大概率。然后用最大概率法计算多轮对话的移动平均值,作为学生政策网络的决策确定性。如果计算出的确定度低于目标值,系统将根据计算出的决策确定度和目标值之间的差异来确定是否需要教师纠正错误并提供奖励函数。如果计算的确定性高于目标值,系统将停止向教师学习,并自行作出判断。
主动学习的关键是估计对话系统自身决策的确定性。除了dropout策略网络外,还有其他方法,包括使用隐藏变量作为条件变量来计算策略网络的Jensen-Shannon散度,并根据当前系统的对话成功率进行判断。
五、智能机器人对话AI团队的对话管理框架
为了系统的稳定性和可解释性,工业界刚开始会使用基于规则的对话管理模型。当前对话系统主要面临两个主要问题:(1)如何获取特殊场景的大量数据;(2)使用算法如何挖掘这些数据的价值。阿里达摩院智能机器人对话AI团队把当前对话系统总结为如下四个步骤,如图Figure23所示:
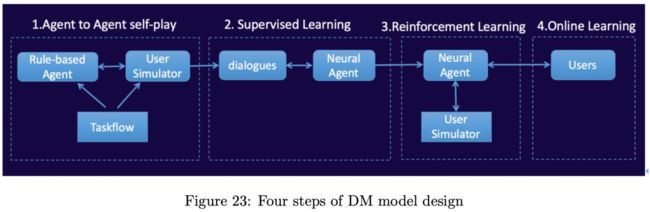
step1:首先,团队快速开发一个称为TaskFlow的基于规则的对话引擎的对话studio开发工具,再开发一个类似对话流程的用户模拟器,然后用户模拟器和TaskFlow持续交换来获取大量的对话数据;
step2:使用监督学习来训练一个神经网络,从而建立一个与基于规则对话引擎类似功能的初试对话模型。该模型可以结合语义相似度和end-to-end生成模型来扩展,对话任务使用之前提到的HRL来分解巨大的动作空间;
step3:在开发阶段,系统通过改善后的用户模拟器或者其他训练好的AI模型进行持续交互,并且通过off-policy ACER强化学习算法持续优化对话系统能力;
step4:最后用户可以使用UI界面来使用对话系统产品,同时系统也可以获取用户真实的交互数据,从而进一步改善系统性能。
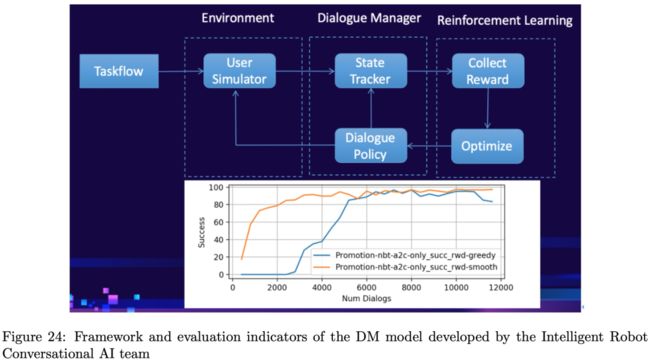
目前,基于RL的DM模型在中等复杂的模拟任务上可以完成用户模拟器的对话的80%,如预订会议室,如图Figure24所示:
六、总结
本文介绍了对话管理模型的最新进展,主要集中解决如下三个问题:
(1)Poor scalability
(2)Insufficient tagged data
(3)Low training efficiency
1)为了解决可伸缩性问题,处理用户意图、对话体和系统动作空间变化的常用方法包括语义相似性匹配、知识蒸馏和序列生成;
2)为了处理标记不足的数据,方法包括自动机器标记、有效的对话框结构挖掘和有效的数据收集策略;
3)针对传统DM模型训练效率低的问题,采用HRL和FRL等方法对动作空间进行分层;
4)采用基于模型的RL方法对训练环境进行建模,提高训练效率;
5)在dialog系统训练框架中引入人在环也是当前研究的热点;
6)最后讨论了由阿里巴巴达摩学院智能机器人会话人工智能团队开发的DM模型的最新进展。