SAM【1】:Segment Anything
文章目录
- 前言
- 1. Abstraction & Introduction
-
- 1.1. Abstraction
- 1.2. Introduction
- 2. Segment Anything Model
-
- 2.1. Segment Anything Task
-
- 2.1.1. Task
- 2.1.2. Pre-training
- 2.1.3. Zero-shot transfer
- 2.2. Segment Anything Model Methods
-
- 2.2.1. Image Encoder
- 2.2.2. Prompt Encoder
- 2.2.3. Mask Decoder
- 2.2.4. Losses and training
- 2.3. Segment Anything Data Engine
-
- 2.3.1. 辅助人工标注阶段
- 2.3.2. 人工半监督标注
- 2.3.3. 全自动标注阶段
- 3. Demo
- 总结
前言
Segment Anthing 是 Meta 开源的第一个分割大模型,最近在 CV 领域掀起了一阵大模型热潮。短短几天时间内,各种二创、测评层出不穷。同时,Meta 公布了模型的 Demo,让研究人员可以抢先体验 SAM 的神奇和强大之处。
视觉大模型与自然语言大模型类似,它的主要目的是通过一个模型来解决用户的所有问题。受制于图像数据更广泛的图片类型和任务,目前 SAM 主要解决的是最传统也是应用最广泛的分割任务。SAM 通过将 NLP 的 prompt 范式引入了 CV 领域,进而为 CV 基础模型提供更广泛的支持与深度研究;通过构造合适的prompt,可以实现对新样本zero-shot的能力,某些时候甚至可以做到模型设计时没有考虑到的任务。
本文主要是对 SAM 的方法做一个分析,同时也是为后续大模型的学习打下一个良好的基础。如果仅想了解 SAM 的模型架构和方法,可以直接看本文的 2.2 小节
原论文链接:Segment Anything
1. Abstraction & Introduction
1.1. Abstraction
本文提出了图像分割新的任务、模型和数据集。该模型的设计和训练是灵活的,因此它可以将 zero-shot(零样本)转移到新的图像分布和任务。实验评估了它在许多任务上的能力,发现它的 zero-shot 性能令人印象深刻——通常与之前的完全监督结果竞争,甚至更好。
1.2. Introduction
在网络数据集上预训练的大语言模型具有强大的 zero-shot 和 few-shot 的泛化能力,这些基础模型可以推广到超出训练过程中的任务和数据分布,这种能力通过 prompt engineering 实现
视觉任务上也对这种基础模型进行了探索,比如 CLIP 和 ALIGN 利用对比学习,将文本和图像编码进行了对齐,通过提示语生成 image encoder,就可以扩展到下游任务,比如生成图像
此项研究的目的,那就是开发一个可提示的(promptable)模型,在大型数据集上通过特定的任务对其进行预训练,使之具有很强的泛化性,即能够通过提示(prompt)解决新数据集上的一系列下游分割任务
为了实现上述目标,本文提出了 3 个需要解决的问题:
- 什么样的任务可以具有
zero-shot的泛化性? - 对应的网络结构是怎样的?
- 什么样的数据集能够驱动此类任务和模型?
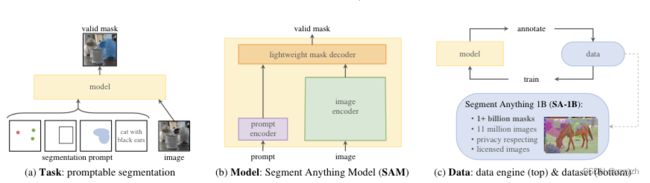
总的来说,本文提出了以下几点解决办法并探讨了相关的一些其他问题:
- Task
- 建立一个可提示的分割任务,使得对于 point、box、mask、text(暂时还没有实现)等任意形式的分割提示,都可返回一个有效的分割掩膜
- 即使输入的提示比较模棱两可,模型都能输出较合理的分割结果
prompt engineering- 提示工程是指设计提示的过程,这些提示可以帮助解决特定的下游分割任务
- 通过使用在可提示的分割任务的预训练中获得的知识,可以设计提示来指导模型为图像中的特定对象或区域生成有效的分割掩码
- Model
- 从任务需求出发,需要模型满足以下三点内容:
- 能够支持灵活的提示信息
- 能做到实时计算掩码以达到交互式使用的目的
- 具备歧义意识。
- 论文提出了一种满足上述三点要求的模型架构:模型需要支持灵活的提示并能实时计算交互生成的掩膜,因此作者设计了一个 image encoder 和一个 fast prompt encoder,然后通过一个轻量化的 prompt encoder 进行结合并预测输出分割掩膜
- 从任务需求出发,需要模型满足以下三点内容:
- Data Engine & Dataset
- 强泛化性的模型需要丰富多样性的大规模数据集,论文通过建立一个 Data Engine 来弥补图像 mask 不足的问题,分成三步:
- 人工辅助(帮助标注,类似交互式分割)
- 半自动(通过提供提示,自动生成对象 mask)
- 全自动(通过规则格网作为提示,进行自动生成)
- 新构建了数据集 SA-1B,包括超过 1.1 千万的影像和 10 亿掩膜,是现有数据集规模的 400 多倍(开放获取)
- 强泛化性的模型需要丰富多样性的大规模数据集,论文通过建立一个 Data Engine 来弥补图像 mask 不足的问题,分成三步:
2. Segment Anything Model
2.1. Segment Anything Task
2.1.1. Task
prompt 可以是一组前景/背景点、一个粗糙的框或掩码、自由形式的文本(指示在图像中分割什么的任何信息),根据提示返回一个有效的分割掩码。有效意味着,即使用户的 prompt 是模棱两可的,模型也可以输出多个合理的分割掩码供用户选择。
该任务导向了一种自然的预训练算法和一种通过提示将 zero-shot 转移到下游分割任务的通用方法。

2.1.2. Pre-training
本文从交互式分割中得到启发
交互式分割:交互式分割是指一种典型的计算机视觉任务,在该任务中,算法经过训练,根据用户输入将图像分割成不同的区域或对象。这意味着该算法能够从用户那里获取提示或线索来完善其分割结果。换句话说,用户可以与算法进行交互,引导其获得更准确的分割结果。
SAM 需要结合一系列提示(点、边界框、掩膜或文本等)进行模型预训练,并将模型输出结果与真实结果进行对比。与交互式分割不同,本任务针对任意的提示都可预测一个有效的掩膜,因此需要选择特定的模型和训练损失函数。
2.1.3. Zero-shot transfer
训练前任务赋予了模型在推理时对任何提示做出适当反应的能力,因此下游任务可以通过工程设计适当的提示来解决。
SAM 可以对任何提示作出响应,所以一个下游任务可以被转换成一个设计 prompt 的任务
2.2. Segment Anything Model Methods
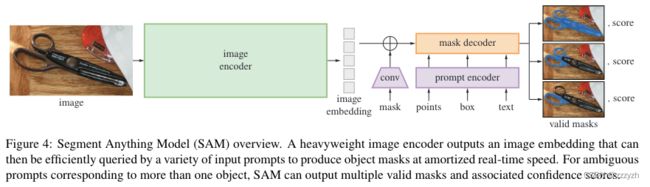
2.2.1. Image Encoder
本文使用了一个 MAE 预训练的视觉变换器(ViT),该变换器被最小化以处理高分辨率输入。有关 ViT 的详细讲解可以参考我的另一篇 blog:CV-Model【6】:Vision Transformer
该图像编码器每幅图像运行一次,可以在提示模型之前应用。根据图像编码器参数量的大小,预训练模型权重从大到小可以分为:vit-h,vit-l,vit-b。
SAM 中的图像编码器采用标准的 ViT 作为图像编码器,原始图像通过等比缩放和短边 padding 操作获得尺寸为 1024 × 1024 1024 \times 1024 1024×1024 的输入图像。然后采用 kernel size 为 16 16 16,stride 为 16 16 16 的卷积将图像离散化为 64 × 64 × 768 ( W , H , C ) 64 \times 64 \times 768 (W, H, C) 64×64×768(W,H,C) 的向量(image embedding)。向量在 W W W 和 C C C 上被顺序展平后再进入多层的 Transformer Encoder。为了减少通道维度,ViT 输出的向量再通过两层的卷积( kernel 分别为 1 1 1 和 3 3 3,每层输出接入 Layer_norm2d)压缩到特征维度为 256 256 256
实现代码如下所示:
self.neck = nn.Sequential(
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
bias=False,
),
LayerNorm2d(out_chans),
nn.Conv2d(
out_chans,
out_chans,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(out_chans),
)
MAE 是一种可扩展的计算机视觉自监督学习方法,遮住 95% 的像素后,仍能还原出物体的轮廓,实现方法:先将输入图像的随机部分予以屏蔽(Mask),再重建丢失的像素
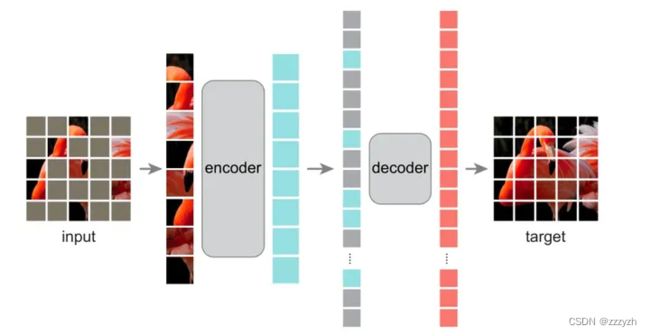
在 MAE 中原始图像如 ViT 切割成不重叠的 patch,保留部分 patch 进入ViT 架构的 encoder 进行学习 patch 的表示,学习到的 patch 表示和 mask(灰色)的表示(所有的 mask 用统一的 embedding,但是 pos embedding 不同)按照原始的 patch 顺序输入到 ViT 架构的 decoder,得到复原图像。loss 为 mask 部分复原前后的 l2_loss。训练完成后我们只使用 encoder 来提取图像特征。
从原始模型可以看出,图像的表征 embedding 是不变的,也就可以在已经编码好的图像 embedding 多次进行不同的 prompt 输入得到期望的结果,这个对交互式分割的场景是非常有用的。
2.2.2. Prompt Encoder
基于分割的任务需求,SAM 支持的prompt可以分为以下两类:
稀疏类(sparse prompt)
包含 point,bbox,free text
一个点被表示为该点的位置编码和两个学习的嵌入之一的总和,这两个嵌入表明该点是在前景还是背景
位置编码为图像中的每个位置分配一个唯一的数字向量,该向量对其位置进行编码。然后,将这些向量与图像的其他特征(例如颜色或纹理)相结合,以创建网络可用于预测的表示形式。它们本质上是一组在训练过程中学到的权重,使网络能够更有效地将输入映射到输出。在这种情况下,作者使用学到的嵌入来表示不同类型的提示
如果提供一个 point 作为 prompt,因为原始的图像可能有多个部件组成,所以这个点会属于多个部件,这种情况下会默认返回三种 mask 结果(全部,部分,子部分);如果提供多个 points 作为 prompt,模型会依次读入给定的 point,并从上一次的三个 mask 结果选择分数最高的预测作为下一次预测的提示
点具体的编码方式如下所示:
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
# self.not_a_point_embed为待学习的embedding
point_embedding[labels == -1] += self.not_a_point_embed.weight
# self.point_embeddings为待学习的embedding
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
一个 box 由一对嵌入表示(box 左上角的点与右下角的点):
- 左上角的位置编码与代表左上角的学习嵌入相加
- 右下角的位置编码与代表右下角的学习嵌入相加
box 具体的编码方式如下所示:
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
为了表示 free text,我们使用来自 CLIP 的文本编码器(一般来说,任何文本编码器都是可能的)
Text prompt 这部分开源的代码没有涉及,在论文中提到的做法如下:
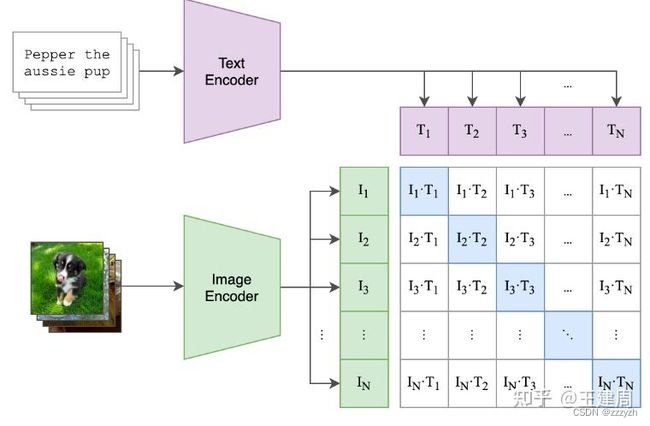
- 分别采用
CLIP (ViT-L/14@336px)预训练好的 text encoder 作为文本编码器,image encoder 作为图像编码器取代 SAM 的图像编码器(ViT-L/14@336px输出的特征维度为 768,而 point 和 bbox 的特征维度为256,所以还存在全连接进行特征维度对齐),将文本特征向量和图像特征向量进行l2 norm为下一步使用作准备 - 构造训练数据,使的上一步产生的 text embedding 和 image embedding 在 mask decoder 模块进行对齐
- 将 Data Engine 第二阶段产生的图片拿出来(这个阶段标注的准确率较高,后边会提及),这些图片存在对应的文本描述,描述文本经过
CLIP得到 text embedding - 将 mask 的主体最小外接矩形随机 1 − 2 1-2 1−2 倍外扩裁剪后,并缩放到
336px作为CLIP的图像输入(会过滤最小外接矩形小于100px的图像) - 为了增强对图像主体特征的提取能力,会将步骤 2 2 2 的图像外扩部分以 50 50% 50 的概率用 0 0 0 替代,如果采用这种策略,
ViT的最后一层,也会 mask 掉这些被填充为 0 0 0 的位置的特征 - 经过步骤 2 2 2 和 3 3 3 得到图片经过
CLIP得到 image embedding
- 将 Data Engine 第二阶段产生的图片拿出来(这个阶段标注的准确率较高,后边会提及),这些图片存在对应的文本描述,描述文本经过
- 在推理阶段,text 直接采用第一步的
CLIP原始 text encoder(需要注意的是,文中没有说明 image encoder 是采用CLIP的 image encoder,还是采用前边MAE预训练的ViT)
稠密类(dense prompt)
包含 mask
密集的提示(即 mask)与图像有空间上的对应关系
以比输入图像低 4 4 4 倍的分辨率输入掩码,然后用两个尺寸为 2 × 2 2 \times 2 2×2、跨度为 2 2 2 的卷积再下采样 4 4 4 倍,输出通道分别为 4 4 4 和 16 16 16。最后用一个 1 × 1 1 \times 1 1×1 卷积将通道维度映射为 256 256 256。每层由 GELU 激活函数和层归一化分开。然后,掩码和图像嵌入被逐一加入元素。
如果不提供粗略分割的输入,会用默认可学习的 embedding 代表空分割 prompt 的特征。
mask 具体的编码方式如下所示:
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
2.2.3. Mask Decoder
mask decoder 的核心是用 transformer 学习和 prompt 对齐后的 image embedding 以及额外 4 4 4 个 token 的 embedding。这 4 个 token embedding 分别是 iou token embedding 和 3 个分割结果 token 的 embedding,经过 transformer 学习得到 token 的embedding 会用于最终的任务头,得到目标结果
transformer 的输入有 3 个:
- token embedding
- prompt tokens embedding 和 output tokens embedding 求和
# iou_token 1个;mask_tokens为4个,分别是3个输出结果对应的token,和一个分割sparse embedding的token
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
# BX(num_point+2*bbox+5) X256
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
- src
- image embedding 和 dense prompt embedding 求和
# Expand per-image data in batch direction to be per-mask
# 对每一个token 都需要一个一样的image embedding
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
- pos_src
- 图像的位置编码,注意这里的位置编码类似
DETR,是二维编码, x x x 和 y y y 方向分别编码再拼接 - 而不是传统
ViT将 patch 拉成一维后编码,这样会损失 y y y 轴方向的信息
- 图像的位置编码,注意这里的位置编码类似

具体的实现过程为:
- 在 prompt embeddings 中插入一个可学习的 token,用于 decoder 的输出
- prompt tokens + output tokens 进行 self attn
- 用得到的 token 和 image embedding 进行 cross attn(token 作为 Q)
- point-wise MLP 更新 token
- 用 image embedding 和步骤 3 中的 token 进行 cross attn(image embedding 作为 Q)
- 重复上述步骤 2 2 2 次,再将
attn通过残差进行连接,最终输出 masks 和 iou scores
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
# query 为token embedding,会随着前向发生变化,query pe为最原始的token embedding
q = queries + query_pe
# keys 为src,key pe 为image pos embedding
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
transformer 返回的 3 3 3 个 mask token 的 embedding 经过 3 3 3 层 mlp 后,与对齐后的图像 embedding 叠加得到 3 3 3 个最终的分割结果;iou token 经过 mlp 得到 3 3 3 个分割结果置信度得分
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# Generate mask quality predictions
iou_pred = self.iou_prediction_head(iou_token_out)
2.2.4. Losses and training
模型损失函数为 focal loss 和 dice loss 的线性组合,以避免类别不平衡或数据噪声的影响
2.3. Segment Anything Data Engine
本文的设计思路与 LLM 类似,主要是加大模型容量,在这种前提下海量的训练数据对模型的效果就至关重要。但是不同于自然语言或者其他的图像任务,分割任务没法从原始的图像通过自监督来实现,而分割标注又是一个成本极高的工作。所以本文设计了 3 个阶段去产生训练数据
2.3.1. 辅助人工标注阶段
通过基于 SAM 的交互式标注工具进行标注并优化,标注时没有给掩膜赋予标签信息。
在这个阶段,SAM首先通过常见公开的分割数据集进行训练,提供非精确的掩膜信息,并对掩膜进行优化,然后仅采用优化后新生成的标注数据进行再次训练。标注时人工采用点击前景点、背景点作为 SAM 的 prompt 输入,对分割的结果进行标注和修正,随着标注数据的增多,会采用新标注的数据来重训 SAM 模型,这个阶段模型反复重训了 6 次。
2.3.2. 人工半监督标注
首先自动检测显著的目标,然后人工校正未被标注的目标,达到增加样本多样性的目的。
用检测框作为 SAM 的 prompt 输入(目标检测难度比分割小的多),输出的分割结果中,人工只需要关注置信度得分低的分割图进行修正,并补充 SAM 遗漏的结果。同样在这个阶段,随着标注数据的增多,SAM 模型会持续的重训,一共进行 5 次训练。
2.3.3. 全自动标注阶段
第三个阶段类似我们产生伪标签训练的过程,用前边数据训练好的 SAM 在海量数据上产生分割的结果,然后再通过规则过滤掉部分可能错误的结果,具体过程如下:
- 对图像生成 ( 32 , 32 ) (32, 32) (32,32) 个网格点,并为每个点预测一组可能对应于有效对象的掩模
- 如果一个点落在子部分、部分上,模型返回该子部分、部分和整体的 object
- 通过预测的
iou筛选 mask 的 confident,获得具有高可信度的 mask- 选取一个 stable 的 mask(稳定的 mask,在相似的 mask 中,概率阈值在 0.5 − δ 0.5 - \delta 0.5−δ 和 0.5 + δ 0.5 + \delta 0.5+δ 之间)
- 通过
NMS过滤 confident 和 stable 中重复的 mask- 当在图像中检测到物体时,由于检测算法或物体外观的不同,可能会多次检测到该物体。NMS 用于移除这些冗余检测,仅保留最准确的检测
- NMS 的主要思想是基于置信度和重叠度来选择最佳的目标框。具体来说,NMS 算法的实现过程如下:
- 对于每个类别,根据置信度从大到小排序所有目标框
- 选择置信度最高的目标框,将其加入最终的结果集合中
- 计算其余目标框与已选择的目标框的重叠度(通常使用 IoU 算法),将重叠度大于一定阈值的目标框删除
- 重复上述过程,直到所有目标框都被处理完毕。
3. Demo
- Positive point


- Negative point

- Box

- Everything

总结
本文最主要的贡献就是构建了一个非常大规模、高质量的分割数据集和一个具有强泛化性的支持可提示任务的模型,并具有以下特点:
- 该模型可作为计算机视觉的基准模型(foundation model)并用于下游任务
- 通过创建
SAM与其他组件的接口,使得SAM具有较强的可集成性 SAM具有泛化性和通用性,并能够实时处理提示信息
参考博客
参考博客