逐步解析力扣146. LRU算法(哈希表+双向链表,LinkedHashMap源码解析,Redis内存淘汰机制)
LRU
LRU(Least Recently Used,最近最久未使用)是一种常见的页面置换算法,在计算中,所有的文件操作都要放在内存中进行,然而计算机内存大小是固定的,所以我们不可能把所有的文件都加载到内存,因此我们需要制定一种策略对加入到内存中的文件进项选择。
LRU的设计原理就是,当数据在最近一段时间经常被访问,那么它在以后也会经常被访问。这就意味着,如果经常访问的数据,我们需要然其能够快速命中,而不常访问的数据,我们在容量超出限制内,要将其淘汰。
实现自己的lru算法:
leetcode 146. LRU 缓存
哈希表 + 双向链表
图解原理:
1.先给双向链表设置头尾节点dummy head/dummy tail,因为链表长度capacity是2,接着往缓存里放两个kv塞满

2.每次get操作代表该数据最近被使用过,这里做了get(1)操作,所以要把1节点放到链表头部

3.这时候再put数据,这么尾部的节点就被删除,put进来的节点放到头部

代码:
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
因为是双向链表,节点类就要设置prev/next
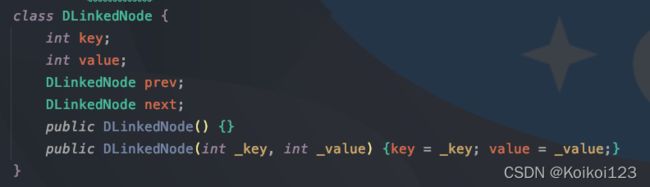
其他字段:
- 缓存
cache用哈希表,注意这里的kv,value存的是节点类 - 容量
capacity表示最大容量,size表示插入时候的大小,用来与capacity进行比较 - 默认的头尾节点
head/tail
然后构造函数没啥好说的
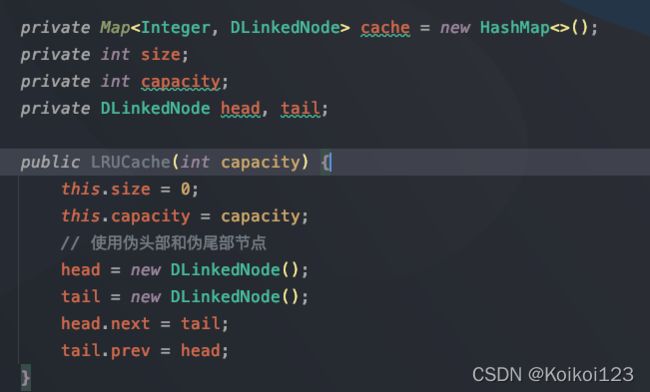
get操作:就是简单的取map,但是LRU多了两个步骤:1.删除当前节点,2.移动该节点到链表头部。
复习下链表的增删节点:其实就是把prev和next的指针分别指向新的节点,removeNode方法把当前节点的prev节点的next指针指向tail节点,把当前节点的next节点的prev指针指向当前节点的prev节点,addToHead同理
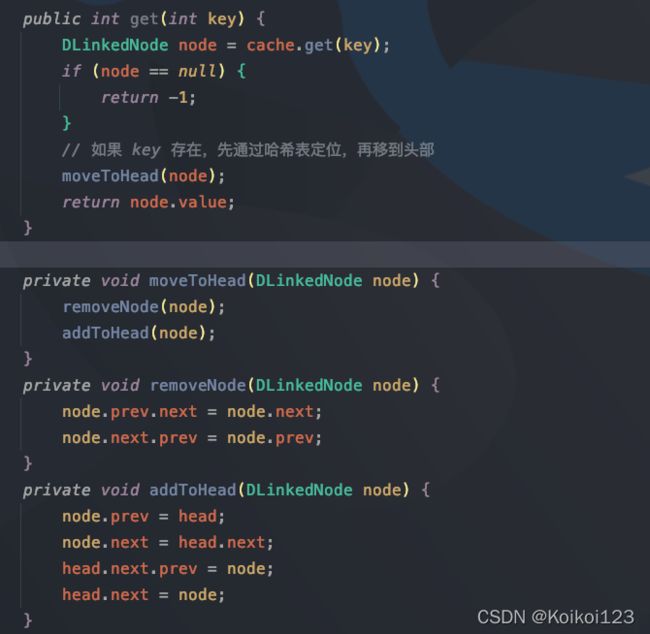
put操作:先判断存不存在,存在就覆盖+移节点至头部;不存在就新增+移节点至头部+判断长度,长度超容量了就删尾部节点
LinkedHashMap源码解析
java中LinkedHashMap直接实现了LRU,需要看源码来了解其实现机制
众所周知 HashMap 底层是数组+红黑树+链表,是无序的,而 LinkedHashMap 刚好就比 HashMap 多这一个功能,可以按两种顺序排列:
- 按照插入的顺序
- 按照读取的顺序(读取节点后会移到链表头部)
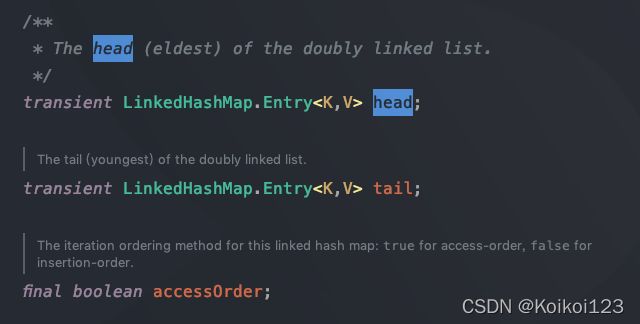
其内部基于LRU,也是建立双向链表来维护顺序
每次插入/删除后,都会调用下图这三个函数来进行双向链表的维护

先看构造函数,容量和负载因子没啥好说的,说一下布尔值accessOrder,默认为false,如果要按照上面说的两种排序中的读取顺序排序,可以将其设为 true
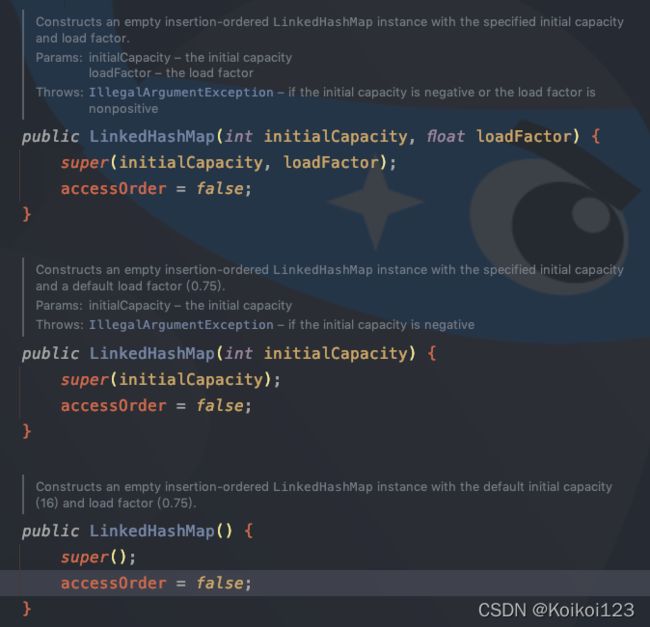
这里是设置为true后走读取顺序走的方法
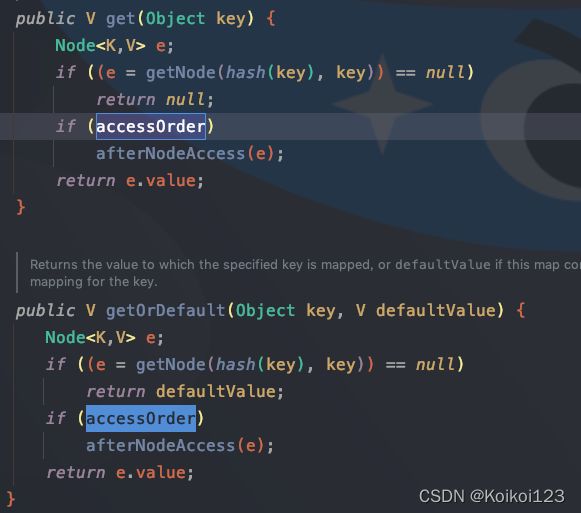
afterNodeAccess()源码
//标准的如何在双向链表中将指定元素放入队尾
// LinkedHashMap 中覆写
//访问元素之后的回调方法
/**
* 1. 使用 get 方法会访问到节点, 从而触发调用这个方法
* 2. 使用 put 方法插入节点, 如果 key 存在, 也算要访问节点, 从而触发该方法
* 3. 只有 accessOrder 是 true 才会调用该方法
* 4. 这个方法会把访问到的最后节点重新插入到双向链表结尾
*/
void afterNodeAccess(Node<K,V> e) { // move node to last
// 用 last 表示插入 e 前的尾节点
// 插入 e 后 e 是尾节点, 所以也是表示 e 的前一个节点
LinkedHashMap.Entry<K,V> last;
//如果是访问序,且当前节点并不是尾节点
//将该节点置为双向链表的尾部
if (accessOrder && (last = tail) != e) {
// p: 当前节点
// b: 前一个节点
// a: 后一个节点
// 结构为: b <=> p <=> a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 结构变成: b <=> p <- a
p.after = null;
// 如果当前节点 p 本身是头节点, 那么头结点要改成 a
if (b == null)
head = a;
// 如果 p 不是头尾节点, 把前后节点连接, 变成: b -> a
else
b.after = a;
// a 非空, 和 b 连接, 变成: b <- a
if (a != null)
a.before = b;
// 如果 a 为空, 说明 p 是尾节点, b 就是它的前一个节点, 符合 last 的定义
// 这个 else 没有意义,因为最开头if已经确保了p不是尾结点了,自然after不会是null
else
last = b;
// 如果这是空链表, p 改成头结点
if (last == null)
head = p;
// 否则把 p 插入到链表尾部
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeRemoval()源码,同理

重头戏是afterNodeInsertion(),源码如下
// 在插入一个新元素之后,如果是按插入顺序排序,即调用newNode()中的linkNodeLast()完成
// 如果是按照读取顺序排序,即调用afterNodeAccess()完成
// 那么这个方法是干嘛的呢,这个就是著名的 LRU 算法啦
// 在插入完成之后,需要回调函数判断是否需要移除某些元素!
// LinkedHashMap 函数部分源码
/**
* 插入新节点才会触发该方法,因为只有插入新节点才需要内存
* 根据 HashMap 的 putVal 方法, evict 一直是 true
* removeEldestEntry 方法表示移除规则, 在 LinkedHashMap 里一直返回 false
* 所以在 LinkedHashMap 里这个方法相当于什么都不做
*/
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
// LinkedHashMap是默认返回false的,我们可以继承LinkedHashMap然后复写该方法即可
// 例如 LeetCode 第 146 题就是采用该种方法,直接 return size() > capacity;
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
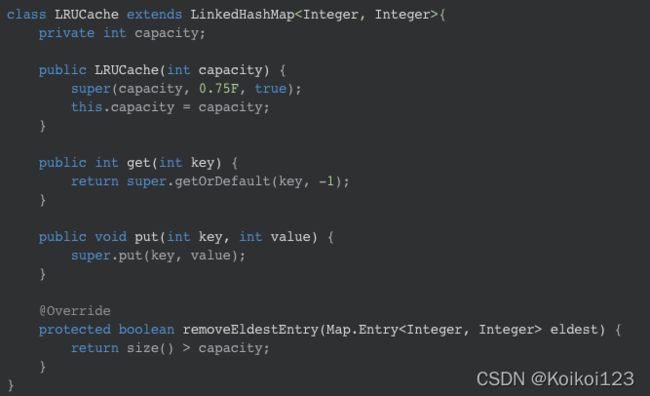
通过上述代码,我们就已经知道了只要复写 removeEldestEntry() 即可,而条件就是 map 的大小不超过 给定的容量,超过了就得使用 LRU 了
不过需要注意的是,java的实现是把head作为最久未使用,tail作为最新,和上面自己实现的链表是相反的
Redis内存淘汰机制


可以看出redis也是基于LRU的改动来实现内存淘汰