《Pytorch深度学习和图神经网络(卷 1)》学习笔记——第八章
本书之后的内容与当前需求不符合不再学习
信息熵与概率的计算关系…
联合熵、条件熵、交叉熵、相对熵(KL散度)、JS散度、互信息
无监督学习
监督训练中,模型能根据预测结果与标签差值来计算损失,并向损失最小的方向进行收敛。无监督训练中,无法通过样本标签为模型权重指定收敛方向,要求模型有自我监督的功能。
比较典型的,自编码和对抗神经网络。前者将输入数据当作标签来指定收敛方向,而后者用两个或多个子模型同时进行训练,利用多个模型之间的关系来达到相互监督的效果。
自编码神经网络
一种以重构输入信号为目标的神经网络,可以自动从无标注的数据中学习特征。
输入层(高维特征样本)——编码——隐藏层(低维特征)——解码——输出层(高维特征样本)
作用和意义
虽然模型对单个样本没有意义,但对整体样本集缺很有价值,能学习到样本的分布情况,既能够对数据集进行特征压缩,实现提取数据主成分的功能,又能与数据集的特征相拟合,实现生成模拟数据的功能。
如果自编码中的激活函数用线性函数就是PCA模型了。
编码器的概念在深度学习中应用非常广泛,如目标识别、语义分割中的骨干网模型。分类任务中,输出层之前的网络结构可以理解为一个独立的编码器模型。
延伸出了变分、条件变分自编码神经网络。
变分自编码神经网络
编码过程中改变样本的分布,假设我们知道样本的分布函数,就可以从函数中随便取出一个样本,然后进行网络解码层前项传导,生成一个新样本。为了得到这个样本分布函数,模型的训练不是样本本身,而是通过增加一个约束项将编码器生成为服从高斯分布的数据集,然后按照高斯分布的均值和方差规则任意取相关的数据,将数据输入解码器还原成样本。
条件变分自编码神经网络
变分存在一个问题:它只能生成与输入图片相同类别的样本,并不知道生成的样本属于哪个类别。
条件变分就是在训练、测试时,加入一个标签向量(one-hot类型),理解为加了一个条件,让网络学习图片分布时加入了标签因素,这样可以按照标签的数值来生成指定的图片。
实例19:用变分自编码神经网络模型生成模拟数据
import torchvision
import torchvision.transforms as tranforms
data_dir = './fashion_mnist/'
tranform = tranforms.Compose([tranforms.ToTensor()])
train_dataset = torchvision.datasets.FashionMNIST(data_dir, train=True, transform=tranform,download=True)
print("训练数据集条数",len(train_dataset))
val_dataset = torchvision.datasets.FashionMNIST(root=data_dir, train=False, transform=tranform)
print("测试数据集条数",len(val_dataset))
import pylab
im = train_dataset[0][0]
im = im.reshape(-1,28)
pylab.imshow(im)
pylab.show()
print("该图片的标签为:",train_dataset[0][1])
############数据集的制作
import torch
batch_size = 10
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
from matplotlib import pyplot as plt
import numpy as np
def imshow(img):
print("图片形状:",np.shape(img))
npimg = img.numpy()
plt.axis('off')
plt.imshow(np.transpose(npimg, (1, 2, 0)))
classes = ('T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle_Boot')
sample = iter(train_loader)
images, labels = sample.__next__()
print('样本形状:',np.shape(images))
print('样本标签:',labels)
imshow(torchvision.utils.make_grid(images,nrow=batch_size))
print(','.join('%5s' % classes[labels[j]] for j in range(len(images))))
############
#########################################################################################################################
#定义myLSTMNet模型类,该模型包括 2个RNN层和1个全连接层
class myLSTMNet(torch.nn.Module):
def __init__(self,in_dim, hidden_dim, n_layer, n_class):
super(myLSTMNet, self).__init__()
#定义循环神经网络层
self.lstm = torch.nn.LSTM(in_dim, hidden_dim, n_layer,batch_first=True)
self.Linear = torch.nn.Linear(hidden_dim*28, n_class)#定义全连接层
self.attention = AttentionSeq(hidden_dim,hard=0.03)
def forward(self, t): #搭建正向结构
t, _ = self.lstm(t) #进行RNN处理
t = self.attention(t)
t=t.reshape(t.shape[0],-1)
# t = t[:, -1, :] #获取RNN网络的最后一个序列数据
out = self.Linear(t) #进行全连接处理
return out
class AttentionSeq(torch.nn.Module):
def __init__(self, hidden_dim,hard= 0):
super(AttentionSeq, self).__init__()
self.hidden_dim = hidden_dim
self.dense = torch.nn.Linear(hidden_dim, hidden_dim)
self.hard = hard
def forward(self, features, mean=False):
#[batch,seq,dim]
batch_size, time_step, hidden_dim = features.size()
weight = torch.nn.Tanh()(self.dense(features))
# mask给负无穷使得权重为0
mask_idx = torch.sign(torch.abs(features).sum(dim=-1))
# mask_idx = mask_idx.unsqueeze(-1).expand(batch_size, time_step, hidden_dim)
mask_idx = mask_idx.unsqueeze(-1).repeat(1, 1, hidden_dim)
weight = torch.where(mask_idx== 1, weight,
torch.full_like(mask_idx,(-2 ** 32 + 1)))
weight = weight.transpose(2, 1)
weight = torch.nn.Softmax(dim=2)(weight)
if self.hard!=0: #hard mode
weight = torch.where(weight>self.hard, weight, torch.full_like(weight,0))
if mean:
weight = weight.mean(dim=1)
weight = weight.unsqueeze(1)
weight = weight.repeat(1, hidden_dim, 1)
weight = weight.transpose(2, 1)
features_attention = weight * features
return features_attention
#实例化模型对象
network = myLSTMNet(28, 128, 2, 10) # 图片大小是28x28
#指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
network.to(device)
print(network)#打印网络
criterion = torch.nn.CrossEntropyLoss() #实例化损失函数类
optimizer = torch.optim.Adam(network.parameters(), lr=.01)
for epoch in range(2): #数据集迭代2次
running_loss = 0.0
for i, data in enumerate(train_loader, 0): #循环取出批次数据
inputs, labels = data
inputs = inputs.squeeze(1)
inputs, labels = inputs.to(device), labels.to(device) #
optimizer.zero_grad()#清空之前的梯度
outputs = network(inputs)
loss = criterion(outputs, labels)#计算损失
loss.backward() #反向传播
optimizer.step() #更新参数
running_loss += loss.item()
if i % 1000 == 999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
#使用模型
dataiter = iter(test_loader)
images, labels = dataiter.__next__()
inputs, labels = images.to(device), labels.to(device)
imshow(torchvision.utils.make_grid(images,nrow=batch_size))
print('真实标签: ', ' '.join('%5s' % classes[labels[j]] for j in range(len(images))))
inputs = inputs.squeeze(1)
outputs = network(inputs)
_, predicted = torch.max(outputs, 1)
print('预测结果: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(len(images))))
#测试模型
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in test_loader:
images, labels = data
images = images.squeeze(1)
inputs, labels = images.to(device), labels.to(device)
outputs = network(inputs)
_, predicted = torch.max(outputs, 1)
predicted = predicted.to(device)
c = (predicted == labels).squeeze()
for i in range(10):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
sumacc = 0
for i in range(10):
Accuracy = 100 * class_correct[i] / class_total[i]
print('Accuracy of %5s : %2d %%' % (classes[i], Accuracy ))
sumacc =sumacc+Accuracy
print('Accuracy of all : %2d %%' % ( sumacc/10. ))
完成! cost= tensor(1492.7400)

第一行是原始的样本数据,第二行是使用变分编码重建后生成的图片。可以看到不会完全一致,表明模型不是一味地学习样本个体,而是通过数据分布的方式学习样本的分布规则。
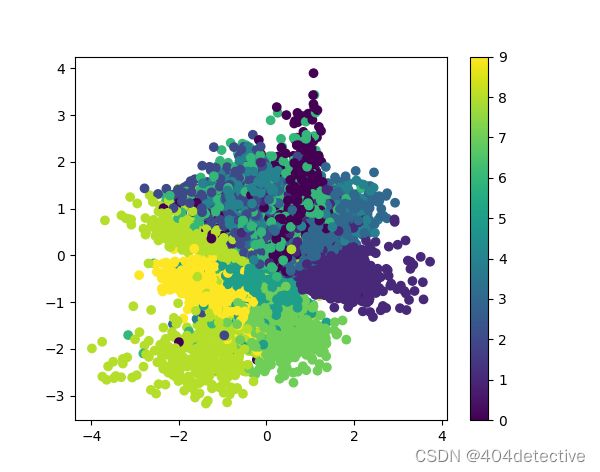
可以看出数据集中同一类样本的特征分布还是比较集中的,说明变分自编码神经网络有降维的功能,也可以用于分类任务的数据降维处理。
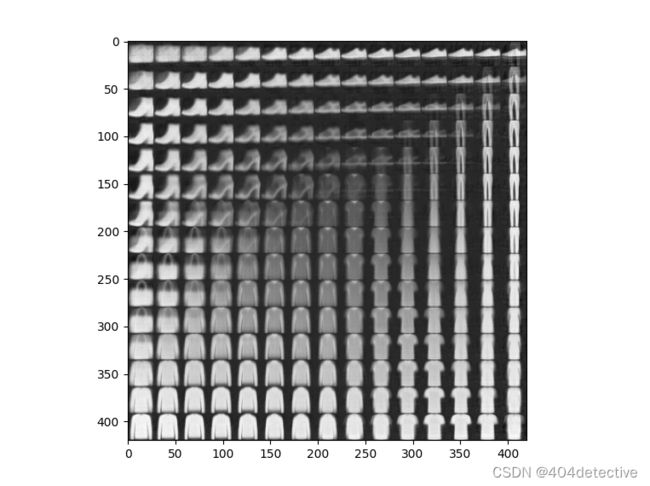
从图中可以看出鞋子手提包服装之间的过渡,模型生成的分布样本很有规律,左下注重图像较宽较高,右上角较宽较矮,左上角下方宽上方窄,右下角窄和高。
实例20:用条件变分自编码神经网络生成可控模拟数据
在这里插入代码片
对抗神经网络
一般由两个模型组成
生成器模型:用于合成与真实样本相差无几的模拟样本
判别器模型:用于判断某个样本是来自真实世界的还是模拟生成的
两者之间存在矛盾,一起训练生成器模拟的会更真实,判别器模型对样本的判断会更加准确。生成器用来处理生成式任务,判别器用来处理分类任务。
根据网络结构不同,其训练方法各种各样,但原理一样。有的方法会在一个优化步骤中对两个网络进行优化,有的会对两个网络采取不同的优化步骤。最终达到纳什均衡,即判别器对生成器模型输出数据的鉴别结果为50%真,50%假。
通常情况,随着训练次数增多,判别器总能可以将生成器的输出与真实样本区分开。因为生成器是低维向高维空间的映射,生成的样本分布难以充满整个真实样本的分布空间,即两个分布完全没有重叠的部分,或者可以忽略。如在二维空间中,随机取两条曲线,上面的点可以代表二者的分布,让判别器无法分辨,需要两个分布融合在一起,但这样不可能,就算存在交叉点,也比曲线低一个维度,只是一个点,没有长度,代表不了分布情况,所以可以忽略。先训练判别器到足够好,生成器就无法得到训练,训练不好,生成器梯度不准,抖动就大,训练到中间状态才是最好的,很难把握。
WGAN模型——解决GAN难以训练的问题
引入Wasserstein距离,理论上解决梯度消失问题,拉近生成与真实分布,既解决了训练不稳定的问题,又提供了一个可靠的训练进程指标,该指标确实与生成样本的质量高度相关。
不足…
WGAN-gp模型——更容易训练的GAN模型
gp是梯度惩罚,能显著提高训练速度,解决原始WGAN模型生成器中梯度二值化问题,与梯度消失爆炸问题。
条件GAN
在生成器和判别器加入标签向量(one_hot),可以按照标签的数值来生成指定的图片。
带有W散度的GAN——WGAN-div
区别在于判别器损失的惩罚项部分,生成器部分算法完全一样。
实例21:用WGAN-gp模型生成模拟数据
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
import torch.autograd as autograd
import matplotlib.pyplot as plt
import os
import numpy as np
import matplotlib
#引入本地代码库
def to_img(x):
x = 0.5 * (x + 1)
x = x.clamp(0, 1)
x = x.view(x.size(0), 1, 28, 28)
return x
def imshow(img,filename=None):
npimg = img.numpy()
plt.axis('off')
array = np.transpose(npimg, (1, 2, 0))
if filename!=None:
matplotlib.image.imsave(filename, array)
else:
plt.imshow(array )
# plt.savefig(filename) 保存图片
plt.show()
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5]) ])
data_dir = './fashion_mnist/'
train_dataset = torchvision.datasets.FashionMNIST(data_dir, train=True,
transform=img_transform,download=True)
train_loader = DataLoader(train_dataset,batch_size=1024, shuffle=True)
val_dataset = torchvision.datasets.FashionMNIST(data_dir, train=False,
transform=img_transform)
test_loader = DataLoader(val_dataset, batch_size=10, shuffle=False)
#指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
class WGAN_D(nn.Module):
def __init__(self,inputch=1):
super(WGAN_D, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(inputch, 64,4, 2, 1), # batch, 64, 28, 28
nn.LeakyReLU(0.2, True),
nn.InstanceNorm2d(64, affine=True) )
self.conv2 = nn.Sequential(
nn.Conv2d(64, 128,4, 2, 1), # batch, 64, 14, 14
nn.LeakyReLU(0.2, True),
nn.InstanceNorm2d(128, affine=True) )
self.fc = nn.Sequential(
nn.Linear(128*7*7, 1024),
nn.LeakyReLU(0.2, True), )
self.fc2 =nn.Sequential(
nn.InstanceNorm1d(1, affine=True),
nn.Flatten(),
nn.Linear(1024, 1) )
def forward(self, x,*arg):#batch, width, height, channel=1
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
x = x.reshape(x.size(0),1, -1)
x = self.fc2(x)
return x.view(-1, 1).squeeze(1)
class WGAN_G(nn.Module):
def __init__(self, input_size,input_n=1):
super(WGAN_G, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size*input_n, 1024),
nn.ReLU(True),
nn.BatchNorm1d(1024) )
self.fc2 = nn.Sequential(
nn.Linear(1024,7*7*128),
nn.ReLU(True),
nn.BatchNorm1d(7*7*128) )
self.upsample1 = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, padding=1, bias=False), # batch, 64, 14, 14
nn.ReLU(True),
nn.BatchNorm2d(64) )
self.upsample2 = nn.Sequential(
nn.ConvTranspose2d(64, 1, 4, 2, padding=1, bias=False), # batch, 64, 28, 28
nn.Tanh(), )
def forward(self, x,*arg):
x = self.fc1(x)
x = self.fc2(x)
x = x.view(x.size(0), 128, 7, 7)
x = self.upsample1(x)
img = self.upsample2(x)
return img
# Loss weight for gradient penalty
lambda_gp = 10
def compute_gradient_penalty(D, real_samples, fake_samples,y_one_hot):
eps = torch.FloatTensor(real_samples.size(0),1,1,1).uniform_(0,1).to(device)
# Get random interpolation between real and fake samples
X_inter = (eps * real_samples + ((1 - eps) * fake_samples)).requires_grad_(True)
d_interpolates = D(X_inter,y_one_hot)
fake = torch.full((real_samples.size(0), ), 1, device=device)
# Get gradient
gradients = autograd.grad( outputs=d_interpolates,
inputs=X_inter,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penaltys = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * lambda_gp
return gradient_penaltys
def train(D,G,outdir,z_dimension ,num_epochs = 30):
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.001)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.001)
os.makedirs(outdir, exist_ok=True)
# train
for epoch in range(num_epochs):
for i, (img, lab) in enumerate(train_loader):
num_img = img.size(0)
# =================train discriminator
real_img = img.to(device)
y_one_hot = torch.zeros(lab.shape[0],10).scatter_(1,
lab.view(lab.shape[0],1),1).to(device)
for ii in range(5):
d_optimizer.zero_grad()
# compute loss of real_img
real_out = D(real_img,y_one_hot)# closer to 1 means better
# compute loss of fake_img
z = torch.randn(num_img, z_dimension).to(device)
fake_img = G(z,y_one_hot)
fake_out = D(fake_img,y_one_hot)# closer to 0 means better
gradient_penalty = compute_gradient_penalty(D,
real_img.data, fake_img.data,y_one_hot)
# Loss measures generator's ability to fool the discriminator
d_loss = -torch.mean(real_out) + torch.mean(fake_out) + gradient_penalty
d_loss.backward()
d_optimizer.step()
# ===============train generator
# compute loss of fake_img
for ii in range(1):
g_optimizer.zero_grad()
z = torch.randn(num_img, z_dimension).to(device)
fake_img = G(z,y_one_hot)
fake_out = D(fake_img,y_one_hot)
g_loss = -torch.mean(fake_out)
g_loss.backward()
g_optimizer.step()
fake_images = to_img(fake_img.cpu().data)
real_images = to_img(real_img.cpu().data)
rel = torch.cat([to_img(real_images[:10]),fake_images[:10]],axis = 0)
imshow(torchvision.utils.make_grid(rel,nrow=10),
os.path.join(outdir, 'fake_images-{}.png'.format(epoch+1) ) )
print('Epoch [{}/{}], d_loss: {:.6f}, g_loss: {:.6f} '
'D real: {:.6f}, D fake: {:.6f}'
.format(epoch, num_epochs, d_loss.data, g_loss.data,
real_out.data.mean(), fake_out.data.mean()))
torch.save(G.state_dict(), os.path.join(outdir, 'generator.pth' ) )
torch.save(D.state_dict(), os.path.join(outdir, 'discriminator.pth' ) )
def displayAndTest(D,G,z_dimension):
# 可视化结果
sample = iter(test_loader)
images, labels = sample.__next__()
y_one_hot = torch.zeros(labels.shape[0],10).scatter_(1,
labels.view(labels.shape[0],1),1).to(device)
num_img = images.size(0)
with torch.no_grad():
z = torch.randn(num_img, z_dimension).to(device)
fake_img = G(z,y_one_hot)
fake_images = to_img(fake_img.cpu().data)
rel = torch.cat([to_img(images[:10]),fake_images[:10]],axis = 0)
imshow(torchvision.utils.make_grid(rel,nrow=10))
print(labels[:10])
if __name__ == '__main__':
z_dimension = 40 # noise dimension
D = WGAN_D().to(device) # discriminator model
G = WGAN_G(z_dimension).to(device) # generator model
train(D,G,'./w_img',z_dimension)
displayAndTest(D,G,z_dimension)
Epoch [0/30], d_loss: -4.276822, g_loss: -33.672523 D real: 39.030716, D fake: 33.672523
一轮就训练了半天。
训练不动,没结果可放。
本书之后的内容与当前需求不符合不再学习