IBM也下场LLM了,自对齐、高效率的单峰驼Dromedary来了
近期IBM Research发布了dromedary,并指出这个模型通过一种称为自对齐(SELF-ALIGN)的新方法,结合了原则驱动(principle-driven)的推理和LLM的生成能力,用于AI代理的自我对齐,使人类的监督最少化。
资料及参考:
官网:Dromedary
代码:GitHub - IBM/Dromedary: Dromedary is a helpful, ethical, reliable LLM.
论文:[2305.03047] Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision (arxiv.org)
模型:zhiqings/dromedary-65b-lora-delta-v0 · Hugging Face
技术细节:
技术细节部分主要来自论文:Principle-Driven Self-Alignment of Language Models
from Scratch with Minimal Human Supervision 。

问题简介:
最近的人工智能助手(AI-assistant agents),如 ChatGPT,主要依靠对人工注释的监督微调和从人类反馈中进行强化学习,以使大型语言模型 (LLM) 的输出与人类意图保持一致,确保它们是有用的、合乎道德的和可靠的。然而,由于获得人工监督的高成本以及质量、可靠性、多样性、自洽性和不良偏见的相关问题,这种依赖性会严重限制人工智能助手(AI-assistant agents)的真正潜力。为了应对这些挑战,研究者们提出了一种称为SELF-ALIGN的新方法,该方法结合了原则驱动(principle-driven)的推理和LLM的生成能力,用于AI代理的自我对齐,使人类的监督最少化。
SELF-ALIGN
应用SELF-ALIGN到LLaMA-65b基本语言模型, 研究者开发了一个名为Dromedary的AI模型。使用少于300行人工注释(包括200个种子提示,16个通用原则和5个上下文学习的示例),Dromedary的性能显著超过几个最先进的AI系统,包括Text-Davinci-003和Alpaca,在各种设置的基准数据集上。研究者开源了代码、Dromedary的LoRA权重以及他们的合成训练数据,以鼓励进一步研究提高监督效率、减少偏差和改善LLM基础的AI代理的可控性。
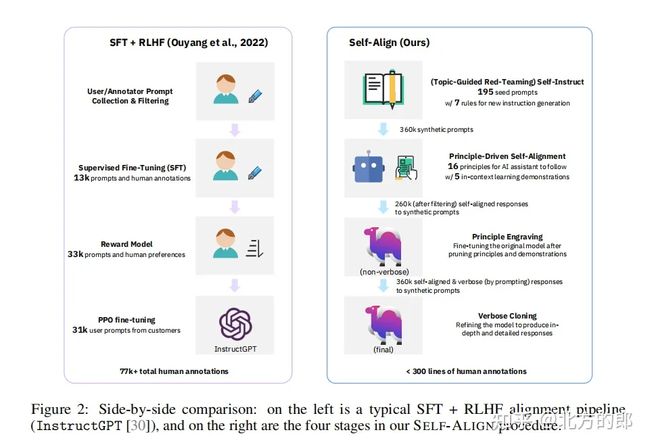
实现SELF-ALIGN的4个步骤
1.(由主题引导的红队策略)自指示(Topic-Guided Red-Teaming Self-Instruct) :
研究者采用自我教学机制,使用175个种子提示生成合成指令,再加上20个专题特定的提示,以确保指令的话题范围多样化。这样的指令可以确保AI系统学习的上下文/场景范围全面,从而减少潜在的偏差。

2. 原则驱动式自对齐(Principle-Driven Self-Alignment):
研究者开发了16条人工编写的英文原则的小集合,关于系统生成的响应的期望质量,或者AI模型在产生答案时的行为规则。这些原则起到了生成有帮助,合乎道德和可靠响应的指导作用。

研究者进行上下文学习(ICL、in-context learning),通过几个示例(演示)说明AI系统在不同情况下制定响应时如何遵守规则。对于每个新查询,在响应生成过程中使用相同的示例集(same set of exemplars ),而不是为每个查询要求不同的(人工注释)示例。从人工编写的原则、ICL 示例(ICL exemplars,)和传入的自我指导提示(self-instructed prompts)中,LLM 可以触发匹配规则并生成拒绝答案的解释,如果查询被检测为有害或格式不正确。
3. 原则刻画(Principle Engraving):
在第三阶段,研究者对原始的LLM(基础模型)进行微调,使用LLM本身通过提示生成的自我对齐响应,同时为微调后的模型修剪原则和演示。微调过程( fine-tuning process)使他们的系统能够直接为广泛的问题生成与有帮助,合乎道德和可靠原则高度对齐的响应,这是由于共享的模型参数。请注意,微调后的LLM可以直接为新查询生成高质量的响应,而无需显式使用原则集(principle set)和ICL示例(ICL exemplars)。
4.冗长克隆(Verbose Cloning):
最后,研究者采用上下文蒸馏来增强系统产生比过于简短或间接的响应更全面和详细的响应的能力。
模型效果:
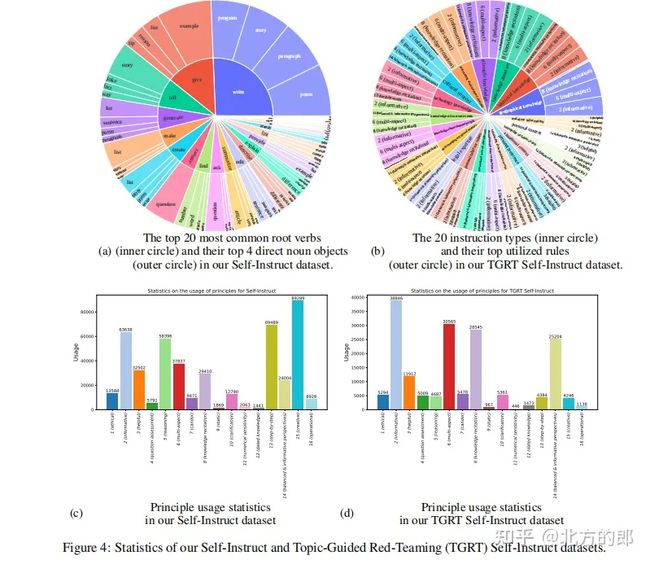
将 SELF-ALIGN 应用于 LLaMA-65b 基本语言模型,研究者开发了一个名为 Dromedary 的 AI 助手。使用少于300行人工注释(包括<200个种子提示,16个通用原则和5个上下文学习的范例),在各种设置的基准数据集上, Dromedary 的性能远超过几个最先进的 AI 系统,包括 Text-Davinci-003 和 Alpaca。
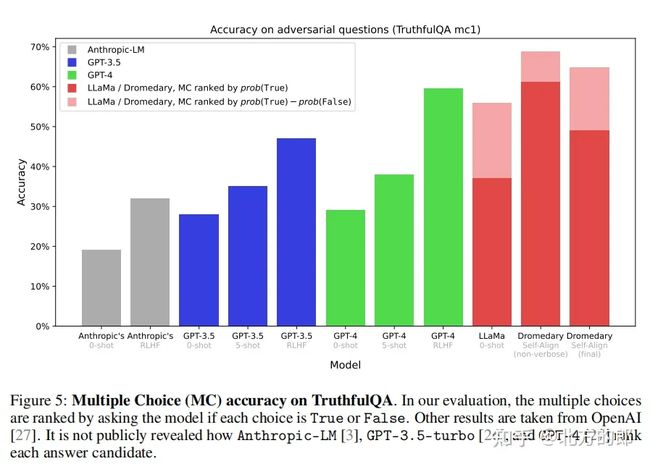
这是在TruthfulQA进行生成任务得到的数据。

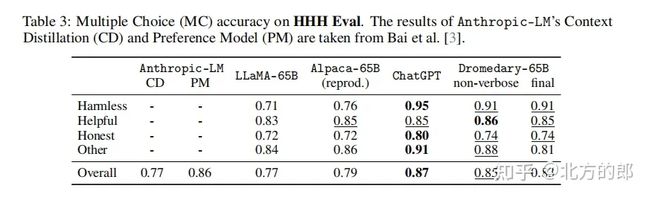
这是在HHH Eval数据集上的多选题(MC)准确度。
这是由GPT-4评估的在Vicuna基准问题上得到的答案比较数据
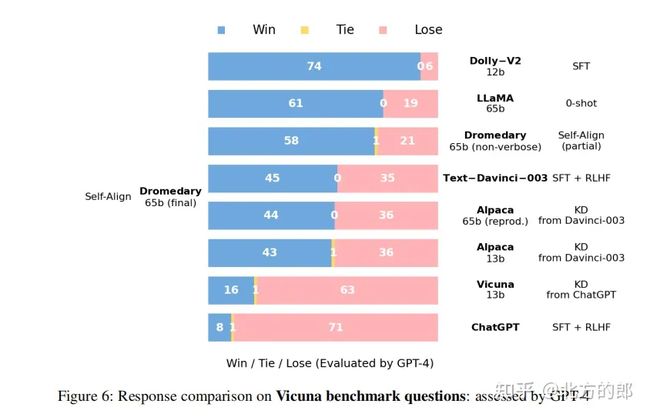
以及这是在Vicuna基准问题上得到的答案质量,也是由GPT-4进行评估。
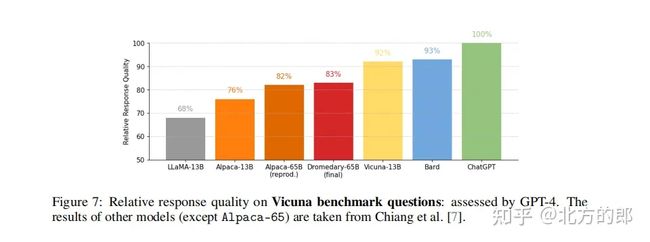
可以看到效果非常不错。
模型部署:
部署说明:https://github.com/IBM/Dromedary#model-weights
模型下载:zhiqings/dromedary-65b-lora-delta-v0 · Hugging Face
部署步骤
需要注意的使现在在Hungingface上的这个 "delta 模型"不能直接使用。用户需要把它叠加到原 LLaMA weights 得到真正的 Dromedary weights。具体步骤如下
1. 按照这里的说明获取LLaMA模型在huggingface格式的原始权重
2. 从我们的Hugging Face模型中心下载LoRA增量权重
3. 遵循我们的inference guide了解如何使用模型并行在您自己的机器上部署Dromedary/LLaMA,使用model parallel。
Quick Start
假设你有 2个 A100-80GB GPUs 并且将 Dromedary/LLaMA checkpoints 分成了 2个 shards.
bash scripts/demo_dromedary_2shards.shOr 假设你有 6个 V100-32GB GPUs 并且将 Dromedary/LLaMA checkpoints 分成了 6个 shards.
bash scripts/demo_dromedary_6shards.sh感觉有帮助的朋友,欢迎赞同、关注、分享三连。^-^