微信朋友圈信息流的系统设计
引言
信息推流(以下简称“Feed流”)这种功能在我们手机APP中几乎无处不在(尤其是社交/社群产品中),最常用的就是微信朋友圈、新浪微博等。
对Feed流的定义,可以简单理解为只要大拇指不停地往下划手机屏幕,就有一条条的信息不断涌现出来。就像给牲畜喂饲料一样,只要它吃光了就要不断再往里加,故此得名Feed(饲养)。
大多数带有Feed流功能的产品都包含两种Feed流:
- 基于算法:即动态算法推荐,比如今日头条、抖音短视频。
- 基于关注:即社交/好友关系,比如微信、知乎。
这两种Feed流,它们背后用到的技术差别会比较大。不同于“推荐”页卡那种千人千面算法推荐的方式,通常“关注”页卡所展示的内容先后顺序都有固定的规则,最常见的规则是基于时间线来排序,也就是展示“我关注的人所发的帖子、动态、心情,根据发布时间从晚到早依次排列”。
本文将重点讨论的是“关注”功能对应的技术实现:先总结常用的基于时间线Feed流的后台技术实现方案,再结合具体的业务场景,根据实际需求在基本设计思路上做一些灵活的运用。
读扩散
读扩散也称为“拉模式”,这应该是最符合我们认知直觉的一种技术实现方式。原理如下图:
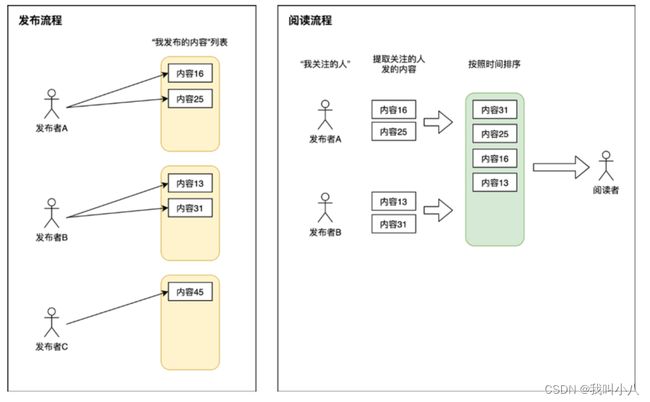
如上图所示: 每一个内容发布者都有一个自己的发件箱(“我发布的内容”),每当我们发出一个新帖子,都存入自己的发件箱中。当我们的粉丝来阅读时,系统首先需要拿到粉丝关注的所有人,然后遍历所有发布者的发件箱,取出他们所发布的帖子,然后依据发布时间排序,展示给阅读者。
这种设计: 阅读者读一次Feed流,后台会扩散为N次读操作(N等于关注的人数)以及一次聚合操作,因此称为读扩散。每次读Feed流相当于去关注者的收件箱主动拉取帖子,因此也得名——拉模式。
这种模式:
- 好处是:底层存储简单,没有空间浪费;
- 坏处是:每次读操作会非常重,操作非常多。
设想一下: 如果我关注的人数非常多,遍历一遍我所关注的所有人,并且再聚合一下,这个系统开销会非常大,时延上可能达到无法忍受的地步。
因此: 读扩散主要适用系统中阅读者关注的人没那么多,并且刷Feed流并不频繁的场景。
拉模式还有一个比较大的缺点: 就是分页不方便,我们刷微博或朋友圈,肯定是随着大拇指在屏幕不断划动,内容一页一页的从后台拉取。如果不做其他优化,只采用实时聚合的方式,下滑到比较靠后的页码时会非常麻烦。
写扩散
大多数Feed流产品的读写比大概在100:1,也就是说大部分情况都是刷Feed流看别人发的朋友圈和微博,只有很少情况是自己亲自发一条朋友圈或微博给别人看。因此读扩散那种很重的读逻辑并不适合大多数场景。
我们宁愿让发帖的过程复杂一些,也不愿影响用户读Feed流的体验,因此稍微改造一下前面方案就有了写扩散。写扩散也称为“推模式”,这种模式会对拉模式的一些缺点做改进。原理如下图:
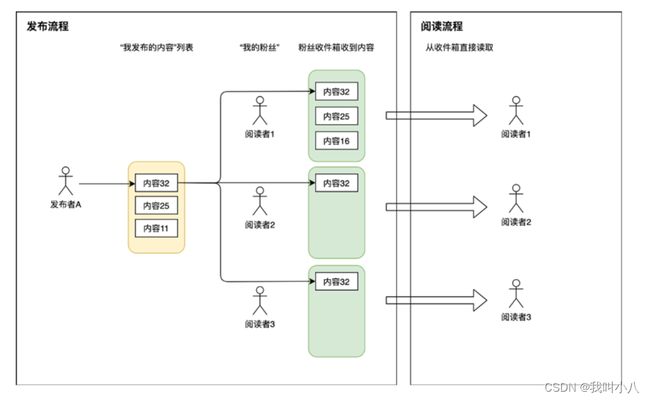
如上图所示: 系统中每个用户除了有发件箱,也会有自己的收件箱。当发布者发表一篇帖子的时候,除了往自己发件箱记录一下之外,还会遍历发布者的所有粉丝,往这些粉丝的收件箱也投放一份相同内容。这样阅读者来读Feed流时,直接从自己的收件箱读取即可。
这种设计: 每次发表帖子,都会扩散为M次写操作(M等于自己的粉丝数),因此成为写扩散。每篇帖子都会主动推送到所有粉丝的收件箱,因此也得名推模式。
这种模式可想而知: 发一篇帖子,背后会涉及到很多次的写操作。通常为了发帖人的用户体验,当发布的帖子写到自己发件箱时,就可以返回发布成功。后台另外起一个异步任务,不慌不忙地往粉丝收件箱投递帖子即可。
写扩散的好处在于通过数据冗余(一篇帖子会被存储M份副本),提升了阅读者的用户体验。通常适当的数据冗余不是什么问题,但是到了微博明星这里,完全行不通。比如目前微博粉丝量Top2的谢娜与何炅,两个人微博粉丝过亿。
设想一下: 如果单纯采用推模式,那每次谢娜何炅发一条微博,微博后台都要地震一次。一篇微博导致后台上亿次写操作,这显然是不可行的。
另外: 由于写扩散是异步操作,写的太慢会导致帖子发出去半天,有些粉丝依然没能看见,这种体验也不太好。
通常写扩散适用于好友量不大的情况,比如微信朋友圈正是写扩散模式。每一名微信用户的好友上限为5000人,也就是说你发一条朋友圈最多也就扩散到5000次写操作,如果异步任务性能好一些,完全没有问题。
读写混合
在设计后台存储的时候,我们如果能够区分一下场景,在不同场景下选择最适合的方案,并且动态调整策略,就实现了读写混合。以微博为例子,原理图如下:
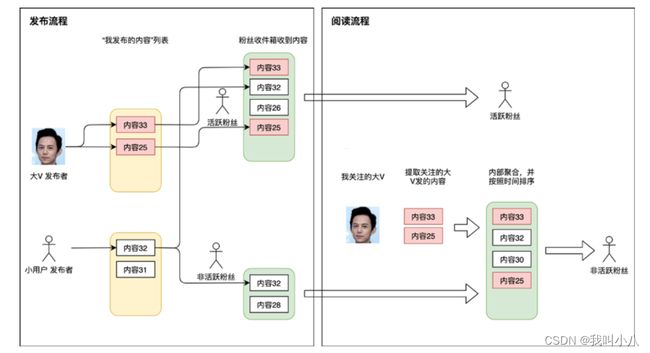
当何炅这种粉丝量超大的人发帖时,将帖子写入何炅的发件箱,另外提取出来何炅粉丝当中比较活跃的那一批(这已经可以筛掉大部分了),将何炅的帖子写入他们的收件箱。当一个粉丝量很小的路人甲发帖时,采用写扩散方式,遍历他的所有粉丝并将帖子写入粉丝收件箱。
对于那些活跃用户登录刷Feed流时: 他直接从自己的收件箱读取帖子即可,保证了活跃用户的体验。
当一个非活跃的用户突然登录刷Feed流时:
- 一方面需要读他的收件箱;
- 另一面需要遍历他所关注的大V用户的发件箱提取帖子,并且做一下聚合展示。
在展示完后: 系统还需要有个任务来判断是否有必要将该用户升级为活跃用户。
因为有读扩散的场景存在,因此即使是混合模式,每个阅读者所能关注的人数也要设置上限,例如新浪微博限制每个账号最多可以关注2000人。
如果不设上限: 设想一下有一位用户把微博所有账号全部关注了,那他打开关注列表会读取到微博全站所有帖子,一旦出现读扩散,系统必然崩溃(即使是写扩散,他的收件箱也无法容纳这么多的微博)。
读写混合模式下,系统需要做两个判断:
- 1)哪些用户属于大V,我们可以将粉丝量作为一个判断指标;
- 2)哪些用户属于活跃粉丝,这个判断标准可以是最近一次登录时间等。
这两处判断标准就需要在系统发展过程中动态地识别和调整,没有固定公式了。
可以看出: 读写结合模式综合了两种模式的优点,属于最佳方案。
然而他的缺点是:系统机制非常复杂,给程序员带来无数烦恼。通常在项目初期,只有一两个开发人员,用户规模也很小的时候,一步到位地采用这种混合模式还是要慎重,容易出bug。当项目规模逐渐发展到新浪微博的水平,有一个大团队专门来做Feed流时,读写混合模式才是必须的。
分页问题
上面几节已经叙述了基于时间线的几种Feed流常见设计方案,但实操起来会比理论要麻烦许多。
接下来专门讨论一个Feed流技术方案中的痛点——Feed流的分页。
不管是读扩散还是写扩散,Feed流本质上是一个动态列表,列表内容会随着时间不断变化。传统的前端分页参数使用page_size和page_num,分表表示每页几条,以及当前是第几页。
对于一个动态列表会有如下问题:
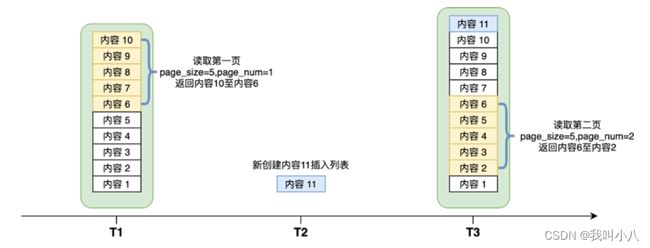
如上图所示: 在T1时刻读取了第一页,T2时刻有人新发表了“内容11”,在T3时刻如果来拉取第二页,会导致错位出现,“内容6”在第一页和第二页都被返回了。事实上,但凡两页之间出现内容的添加或删除,都会导致错位问题。
为了解决这一问题: 通常Feed流的分页入参不会使用page_size和page_num,而是使用last_id来记录上一页最后一条内容的id。前端读取下一页的时候,必须将last_id作为入参,后台直接找到last_id对应数据,再往后偏移page_size条数据,返回给前端,这样就避免了错位问题。
采用last_id的方案有一个重要条件:就是last_id本身这条数据不可以被硬删除。
设想一下:
- 1)上图中T1时刻返回5条数据,last_id为内容6;
- 2)T2时刻内容6被发布者删除;
- 3)那么T3时刻再来请求第二页,我们根本找不到last_id对应的数据了,也就无法确认分页偏移量。
通常碰到删除的场景: 我们采用软删除方式,只是在内容上置一个标志位,表示内容已删除。
由于已经删除的内容不应该再返回给前端,因此软删除模式下,找到last_id并往后偏移page_size条,如果其中有被删除的数据会导致获得足够的数据条数给前端。
这里解决方案有2个:
- 找不够继续再往下找;
- 与前端协商,允许返回条数少于page_size条,page_size只是个建议值。甚至大家约定好了以后,可以不要page_size参数。
总结
几乎所有基于时间线和关注关系的Feed流都逃不开三种基本设计模式:
- 读扩散;
- 写扩散;
- 读写混合。
具体到实际业务中,可能会有更复杂的场景,比如 微博朋友圈场景中会有广告接入、特别关注、热点话题等可能影响到Feed流排序的因素。这些场景就只能根据业务需求,做相对应的变通了。