无线感知论文阅读笔记 | SenSys 2022 | M4esh: mmWave-based 3D Human Mesh Construction for Multiple Subjects
原文链接:https://mp.weixin.qq.com/s?__biz=Mzg4MjgxMjgyMg==&mid=2247486324&idx=1&sn=7849c33f416a18116d1af92677
SenSys 2022 | M4esh: mmWave-based 3D Human Mesh Construction for Multiple Subjects
无线感知论文阅读笔记 | SenSys 2022 | M4esh: mmWave-based 3D Human Mesh Construction for Multiple Subjects


Abstract
-
动机
- 感知人体的姿态和形状对于许多应用至关重要
- 传统摄像头: face challenges like occlusions and poor lighting
- ⇒ \Rightarrow ⇒ 利用RF信号构建人体网格
-
Proposed method: M 4 ^4 4esh system
- 利用商用毫米波(mmWave)雷达进行多目标3D人体网格构建
- 检测和跟踪主体: 在2D能量图上预测主体边界框
- 解决主体之间的相互遮挡问题: 利用前几帧主体边界框的位置、速度和大小信息
-
Evaluations :
- Accurately localizes and generates meshes
1 Introduction
-
背景
- RF sensing 具有优势
- RF signals can construct human mesh
-
困难和挑战
-
RF-Avatar:设备过于笨重
-
mmMesh:
uses mmWave to build single human mesh
❌ cannot estimate subject number, 无法处理 multi-subject scenarios
-
挑战1: 多个主体 的 检测 + mesh 重建
-
挑战2: 主体之间的相互遮挡
-
-
Proposed M 4 ^4 4esh
- M4esh uses mmWave for multi-subject mesh construction
- 1 多主体 :使用2D框Detects and tracks subjects
- 2 主体间的遮挡 :使用过去帧 Handles inter-subject occlusion
- 3 细节重建 :Proposes coarse-to-fine mesh estimation strategy
- Evaluations demonstrate effectiveness
2 SYSTEM OVERVIEW
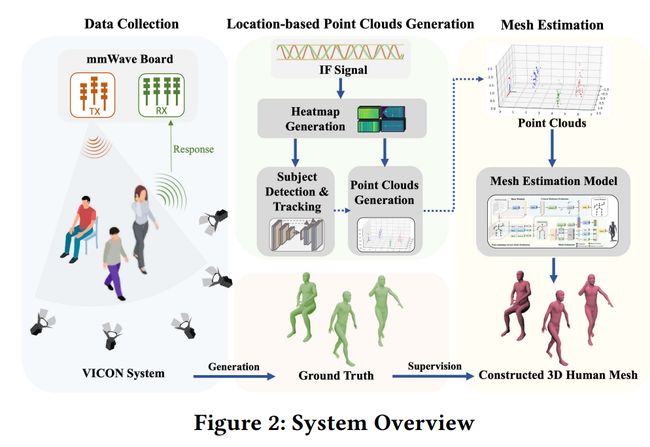
2.1 Data Collection
- 收集毫米波信号和真实人体网格
- 毫米波雷达混合发射和反射信号生成IF信号
- 运动捕捉系统记录主体姿态生成真实网格
2.2 Location-based Point Clouds Generation
- 根据主体位置生成点云,而不是整个能量图
- 从IF信号生成热图
- 在热图上检测和跟踪主体
- 根据主体位置生成点云
2.3 Mesh Construction
- 从点云构建mesh
- 使用从粗到细策略学习点云局部结构
- 将骨骼拓扑作为先验知识学习关节关系
3 METHODOLOGY
- 3.1: 根据每个主体的位置生成点云
- 3.2: 基于每个主体获得的点云,估计人体网格
- 3.3: 简要总结了所提出的框架中解决短期主体遮挡问题的设计
3.1 Location-based Point Clouds Generation

- 点云是网格估计的有效输入
- 整体点云生成存在偏差问题 (上图)
- 提出 基于位置的点云生成方法 (下图)
- 先定位主体
- 再在主体周围生成点云
- ⇒ \Rightarrow ⇒ 减少环境噪声
- 生成过程 :
- 距离FFT热图
- 应用 MVDR (最小方差无畸变响应)算法得到位置能量图
- 在位置能量图检测和跟踪主体
- 根据主体距离 裁剪Doppler频谱图
- 在裁剪图生成点云
- 根据主体位置过滤点云
- MVDR算法 :
- 可估计任意方向的能量
- 去噪并突出主体位置
- 应用在不同距离和角度,得到位置能量图

3.1.1 MVDR-based Locational Energy Map Generation.
- 目标:使用MVDR算法生成位置能量图
- 数据自适应波束成形解决方案
- 可估计任意方向的能量
- 去噪并突出主体
- 过程
-
输入为IF信号矩阵
-
进行距离FFT,得到新的矩阵
-
对不同距离bin和角度应用MVDR
✅ 计算不同位置的反射功率
✅ 得到位置能量图
-
- MVDR公式推导
- 定义位置坐标(x,r)
- 定义 range bin索引
- 定义信号功率公式
- steering vector from the angle of the location ( x , r ) (x,r) (x,r): S ( x , r ) = [ 1 , exp ( − j π sin θ ( x , r ) ) , … , exp ( − j π ( N p − 1 ) sin θ ( x , r ) ) ] T , = [ 1 , exp ( − j π x r ) , … , exp ( − j π ( N p − 1 ) x r ) ] T , \begin{aligned} S_{(x, r)} & =\left[1, \exp \left(-j \pi \sin \theta_{(x, r)}\right), \ldots, \exp \left(-j \pi\left(N_p-1\right) \sin \theta_{(x, r)}\right)\right]^T, \\ & =\left[1, \exp \left(-j \pi \frac{x}{r}\right), \ldots, \exp \left(-j \pi\left(N_p-1\right) \frac{x}{r}\right)\right]^T,\end{aligned} S(x,r)=[1,exp(−jπsinθ(x,r)),…,exp(−jπ(Np−1)sinθ(x,r))]T,=[1,exp(−jπrx),…,exp(−jπ(Np−1)rx)]T,
- 推导过程 略
3.1.2 Subjects Detection and Tracking.

- 在位置能量图上检测和跟踪主体
- 使用带有ConvLSTM的U-Net作为网络结构
- 输出 包括:
- 中心点图 L p = − 1 N ∑ h w { ( 1 − Y ^ h w ) α log ( Y ^ h w ) if Y h w = 1 ( 1 − Y h w ) β ( Y ^ h w ) α log ( 1 − Y ^ h w ) Otherwise L^p=\frac{-1}{N} \sum_{h w} \begin{cases}\left(1-\hat{Y}_{h w}\right)^\alpha \log \left(\hat{Y}_{h w}\right) & \text { if } Y_{h w}=1 \\ \left(1-Y_{h w}\right)^\beta\left(\hat{Y}_{h w}\right)^\alpha \log \left(1-\hat{Y}_{h w}\right) & \text { Otherwise }\end{cases} Lp=N−1∑hw⎩ ⎨ ⎧(1−Y^hw)αlog(Y^hw)(1−Yhw)β(Y^hw)αlog(1−Y^hw) if Yhw=1 Otherwise
- 大小图 L s = 1 N ∑ k = 1 N ∣ Y ^ p i s − Y p i s ∣ L^s=\frac{1}{N} \sum_{k=1}^N\left|\hat{Y}_{p_i}^s-Y_{p_i}^s\right| Ls=N1∑k=1N Y^pis−Ypis
- 速度图 L v = 1 N ∑ k = 1 N ∣ Y ^ p i v − Y p i v ∣ L^v=\frac{1}{N} \sum_{k=1}^N\left|\hat{Y}_{p_i}^v-Y_{p_i}^v\right| Lv=N1∑k=1N Y^piv−Ypiv
- 可视性图 L v i s = 1 N ∑ k = 1 N ∣ Y ^ p i v i s − Y p i v i s ∣ L^{v i s}=\frac{1}{N} \sum_{k=1}^N\left|\hat{Y}_{p_i}^{v i s}-Y_{p_i}^{v i s}\right| Lvis=N1∑k=1N Y^pivis−Ypivis
- 对每个输出使用不同的loss Loss = γ p ∗ L p + γ s ∗ L s + γ v ∗ L v + γ v i s ∗ L v i s =\gamma^p * L^p+\gamma^s * L^s+\gamma^v * L^v+\gamma^{v i s} * L^{v i s} =γp∗Lp+γs∗Ls+γv∗Lv+γvis∗Lvis
- 在中心点图上提取峰值作为检测结果
- 跟踪过程:
- 当前检测与前一帧预测位置关联
- 若无对应关联,则生成新轨迹
- 若多帧无检测,则终止轨迹
3.1.3 Point Clouds Generation.
- 基于预测的主体边界框生成点云
- 位置能量图缺失相位信息,不能直接用于生成点云
- 使用频谱图和边界框范围信息
- 过程 :
- 对IF信号进行多普勒FFT,得到频谱图
- 根据边界框范围裁剪频谱图
- 在裁剪图上提取高能像素点
- 估计点的方位角和仰角
- 得到中间点云
- 根据边界框范围过滤点云
- 与整体点云生成方法比较:
- 为每个主体生成足够点
- 抑制环境噪声
3.2 Coarse-to-Fine Human Mesh Estimation

- 获得每个主体点云后,输入mesh估计模型
- mesh estimation 模型的设计思路:
-
1 简单全局推理无法考虑点云局部结构
-
2 提出从粗到细的网格估计框架
✅ 先用整体点云估计粗略骨架
✅ 在粗略骨架基础上学习关节周围点云局部结构
✅ 编码关节之间关系,提高精度
-
- 模型组成:四个模块
- Base Module:提取每个点特征
- Coarse Skeleton Estimator:估计粗略骨架
- Pose-aware Joint Estimator:学习关节局部结构
- Mesh Estimator:输出最终mesh
3.2.1 Base Module.
- 输入:点云中所有点的特征向量
- 输出:每个点的high-level特征表示
- 方法:将特征向量输入共享权重MLP
3.2.2 Coarse Skeleton Estimator.
- 输入:基模块输出的每个点表示
- 输出:主体的粗略骨架
- 方法:
- MLP提取每个点的高级特征
- 注意力块聚合所有点特征 f t = ∑ i ∈ N t L ( c t i ) ⋅ c t i f_t = \sum_{i\in N_t} L(c_t^i) \cdot c_t^i ft=∑i∈NtL(cti)⋅cti
- LSTM生成全局特征 g t g_t gt
- SMPL模块输出粗略骨架
3.2.3 Pose-aware Joint Estimator.
- 输入:粗略骨架和基模块特征
- 输出:姿态感知关节表示
- 方法:
- 将粗略骨架关节作为分组中心
- 对每个关节,点云输入MLP和注意力块生成关节特征
- 连接全局特征和每个关节特征
- 在骨架图上应用GCN编码拓扑结构 H = f ( A X Θ ) H = f(AX\Theta) H=f(AXΘ)
- 输出姿态感知关节表示
3.2.4 Mesh Estimator.
- 输入:粗略骨架全局特征,姿态感知关节特征
- 输出:人体网格
- 方法:
- 注意力块聚合所有关节特征
- LSTM处理生成全局特征
- 连接全局特征预测全局参数
- 每个关节特征输入LSTM
- 预测每个关节的6D旋转
- SMPL模块结合全局和局部参数输出网格
3.2.5 Model Loss.
- Loss = 权重和*预测值与标签的L1距离之和
- Loss = ∑ K ∈ { V , S , B , V c , S c , B c , } α K ∗ ∑ t T ∥ K t − G T ( K t ) ∥ L 1 =\sum_{K \in\left\{V, S, B, V_c, S_c, B_c,\right\}} \alpha_K * \sum_t^T\left\|K^t-\mathcal{G} \mathcal{T}\left(K^t\right)\right\|_{L_1} =∑K∈{V,S,B,Vc,Sc,Bc,}αK∗∑tT∥Kt−GT(Kt)∥L1
- 预测的项包括顶点、骨架、形状等
3.3 Summary of Designs to Address the Short-term Subject Occlusion Problem
解决主体遮挡问题的设计总结
(1) 添加递归结构
- 在检测跟踪模型和网格估计模型中
- 卷积LSTM支持预测被遮挡的框
- LSTM模块处理遮挡的网格估计
(2) 预测可见性分数
- 表示主体被遮挡的百分比
- 监督模型学习主体间几何关系
(3) 输出速度预测被遮挡的框
- 与前一帧框位置一起用于推断
(4) SMPL模块输出完整网格
- 即使被部分或完全遮挡
(5) 训练时输入真实标签
- 学习检测被遮挡主体的框
- 学习生成被遮挡主体的网格
4 EXPERIMENTS
4.1 Testbeds
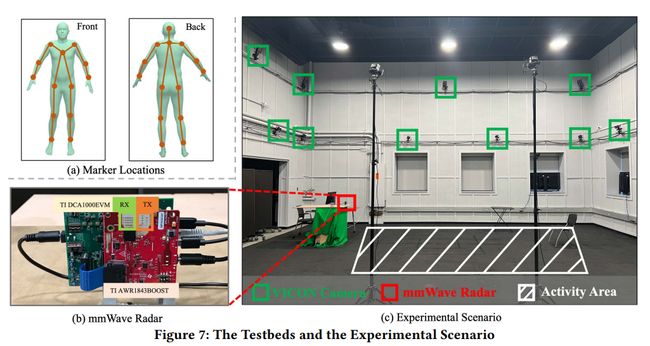
4.1.1 VICON System.
- 21台VICON相机
- 红外光和标记
- 生成高精度骨架
4.1.2 mmWave Testbed
- TI AWR 1843 BOOST 毫米波雷达
- 3T4R
- max range 11m
4.2 Data Collection and Prepossessing
4.2.1 Data Collection.
- 18 users, multi-subject 活动
- 510分钟的数据
4.2.2 Ground Truth Mesh Construction.
- 使用SMPL模型
- 从VICON获得姿态,计算形状
- 调整匹配真实身高
4.3 Model Settings and Model Training
- 编码器中采用了6个下采样层
- BS =16
- 超参数设置
- 前2200帧训练,剩余的500帧用于评估
4.4 Baselines and Metrics
4.4.1 Baselines.
- RF-Avatar
- mmMesh
- Holistic PC
4.4.2 Metrics.
- 平均顶点误差(V)
- Average Vertex Error
- 平均关节点误差(S)
- Average Joint Localization Error (S)
- 对齐关节点误差(PA-S)
- Procrustes-Aligned Mean Per Joint Position Error (PA-S)
- 平均关节旋转误差(Q)
- Average Joint Rotation Error (Q)
- 网格定位误差(T)
- Mesh Localization Error (T)
4.5 Experiment Results
4.5.1 Qualitative Results for the Scenarios without Mutual Occlusion
- 效果最佳

4.5.2 Quantitative Results for Scenarios without Mutual Occlusion

- 我们的模型各指标优于基准
- 优于Holistic PC,证明位置点云生成效果
- 优于mmMesh,证明网格估计模型设计效果
- 大大优于RF-Avatar
- 设计了姿态感知关节估计器
- 输入是3D点云而非2D图
- 使用预测框影响很小,检测稳健
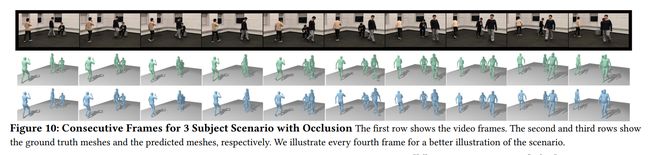
4.5.3 Qualitative Results for the Scenarios with Mutual Occlusion
- RF-Avatar未检测遮挡主体
- 我们检测了所有主体边界框

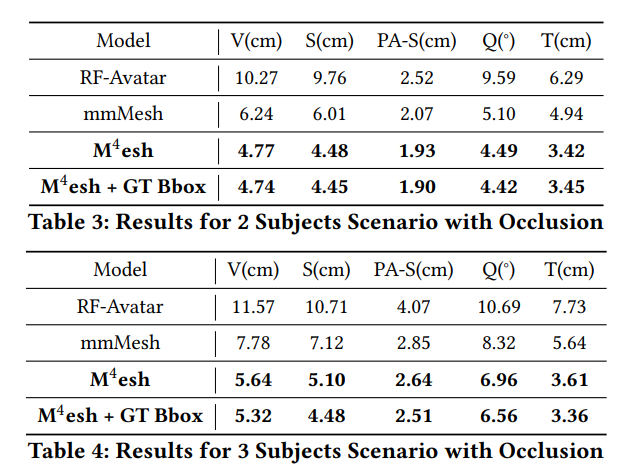
4.5.4 Quantitative Results for Scenario with Mutual Occlusion
4.5.5 Results of Bounding Box Prediction
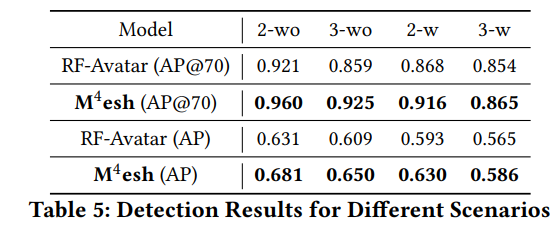
- AP和AP@70均优于RF-Avatar
- 证明检测网络效果
4.5.6 Results of the Cross-trial Experiment
- 两场景下交叉试验结果优于基准
- 证明模型泛化能力好

4.5.7 Results of Experiment with Blockage
- 遮挡下模型准确率降低
- 信号受阻,是可预期的
- 但仍优于基准
4.5.8 Results of Cross-environment Experiment
- 在不同环境预测精度仍高
- 证明模型环境泛化能力

4.5.9 System Complexity and Latency
- 参数量:2.29M,轻量
- 延迟:202.1ms,实时
4.5.10 Limitations
- 只能处理短时遮挡
- 假设运动方向不变
- 方向改变时效果差
5 RELATED WORK
毫米波定位
- 比WiFi、声音定位分辨率高
- 需要距离和角度信息
- 距离:自相关、相位、FMCW频移
- 角度:波束成形、波束扫描
- 现有工作将人体视为一点
- 本文利用检测算法得到人体范围
毫米波传感
- 毫米波雷达的应用:
- 振动测量
- 运动估计和捕捉
- 成像
- 果实质量评估
- 室内映射
- 材料探测
- 声音相关传感
- 在人体传感方面的应用:
- 人体跟踪和识别
- 活动识别
- 生命体征监测
- 主体检测
- 本文:人体网格估计
无线信号姿态估计
- 许多工作使用无线信号估计人体姿态
- 部分工作实现3D姿态估计
- 本文:估计包含姿态和形状的3D人体网格
使用无线信号构建人体网格
- 很少工作探索使用无线信号构建人体网格
- RF-Avatar是先驱工作,证明了RF信号包含丰富信息
- RF-Avatar使用专用设备,限制应用
- mmMesh 使用商用设备实现单主体网格估计
- mmMesh无法扩展到多主体场景
- 缺少检测模块预测主体数量
- 点云生成方法存在偏差
- 本文:使用商用毫米波雷达,在多主体场景取得更好效果
计算机视觉中的人体网格估计
- 统计体模型SMPL等促进了该任务的发展
- 基于图像和视频的许多方法已提出
- 这些方法容易受照明、遮挡等因素影响
- 本文:毫米波解决方案可处理上述问题,并减轻隐私问题
6 Conclusion
- 研究使用商用毫米波雷达构建多主体人体mesh
- propose M 4 m e s h M^4mesh M4mesh
- 在能量图上检测和跟踪主体
- 利用前帧信息预测当前遮挡框
- 提出从粗到细网格估计策略
- 实验
- 在实际测试平台上实现准确定位和网格估计
- 证明了方法的有效性