YOLOv5基础知识
定位和检测:
定位是找到检测图像中带有一个给定标签的单个目标·
检测是找到图像中带有给定标签的所有目标
图像分割和目标检测的区别:
图像分割即为检测出物体的完整轮廓,而目标检测则是检测出对应的目标。(使用框框把物体框出来),此外,目标检测还分为多种类型,可以只检测一个物体,也可以同时检测多个物体。
目标检测性能指标
检测精度
- Precision, Recall, F1 score
- lou (Intersection over Union)
- P-R curve ( Precison-Recall curve)·AP(Average Precision)
- mAP (mean Average Precision)
检测速度
- 前传耗时
- 每秒帧数FPS (Frames Per Second)
- 浮点运算量(FLOPS)
混淆矩阵
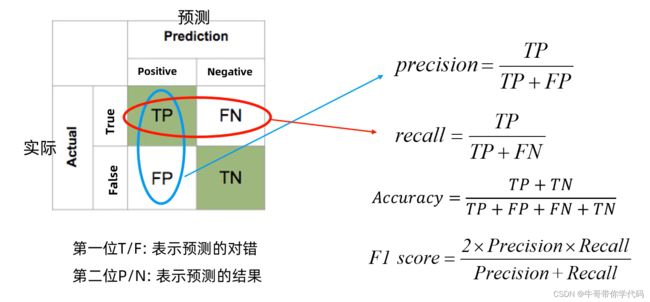
精度Precision(查准率)是评估预测的准不准(看预测列)
召回率Recall(查全率)是评估找的全不全(看实际行)
YOLO——you only look once

YOLO算法基本思想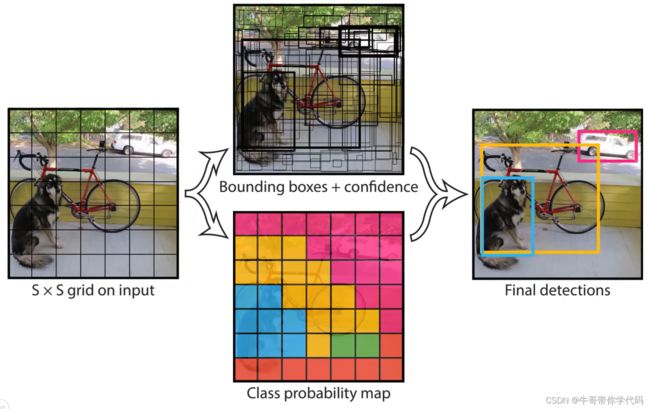
损失函数(Loss function)
损失函数包括:
- classification loss,分类损失
- localization loss,定位损失(预测边界框与GT之间的误差)
- confidence loss,置信度损失(框的目标性; objectness of the box)
总的损失函数(三类损失之和):
classification loss + localization loss + confidence loss
YOLOv5使用二元交叉嫡损失函数计算类别概率和目标置信度得分的损失。
YOLOv5使用CIOu Loss作为bounding box回归的损失。
类别预测(class prediction)
大多数分类器假设输出标签是互斥的。如果输出是互斥的目标类别,则确实如此。因此,YOLO应用softmax函数将得分转换为总和为1的概率。而YOLOv3/v4/v5使用多标签分类。例如,输出标签可以是“行人”和“儿童”,它们不是非排他性的。(现在输出得分的总和可以大于1)
YOLOv3/v4/v5用多个独立的逻辑(logistic)分类器替换softmax函数,以计算输入属于特定标签的可能性。
在计算分类损失进行训练时,YOLOv3/v4/v5对每个标签使用二元交叉嫡损失。这也避免使softmax函数而降低了计算复杂度。
边界框回归是许多2D/ 3D计算机视觉任务中最基本的组件之一。
一个改进机会是使用根据loU计算的度量损失取代替代回归损失(例如l1和l2-norms(平方损失))
灵活配置不同复杂度的模型
应用类似EfficientNet的channel和layer控制因子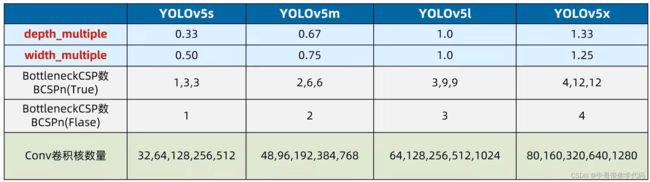
YOLOv5的四种网络结构是depth_multiple和width_multiple两个参数,来进行控制网络的深度和宽度。其中depth_multiple控制网络的深度(BottleneckCSP数),width_multiple控制网络的宽度(卷积核数量)。

predicted bounding box (black rectangle)
ground truth box (green rectangle)
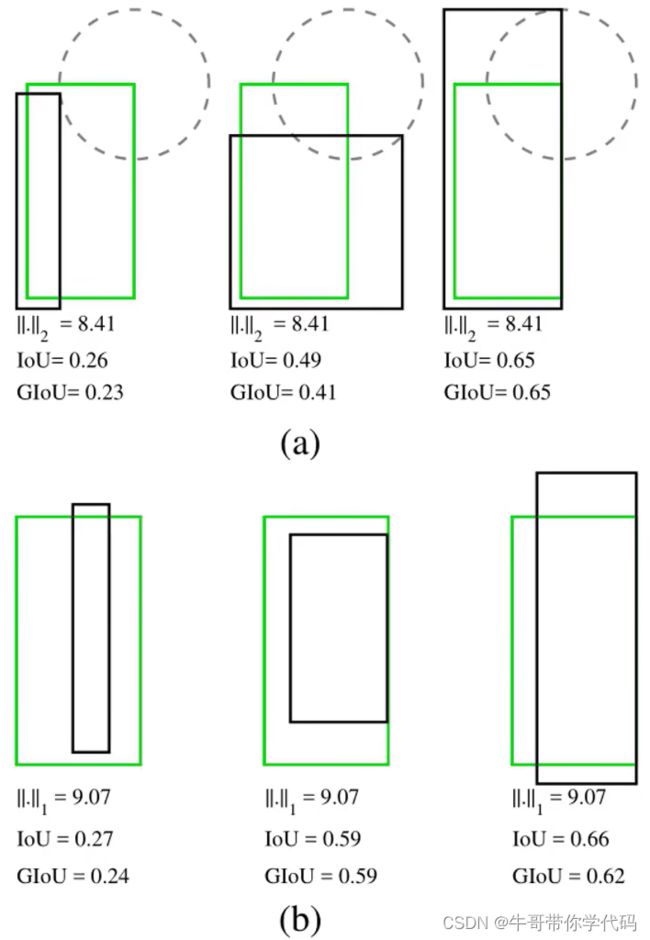
loU用作性能度量和损失函数的问题:
如果两个物体不重叠,则loU值将为零,并且不会反映两个形状彼此之间的距离。
在物体不重叠的情况下,如果将loU用作损失,则其梯度将为零并且无法进行优化。
major weakness:
If |AnB|= 0,IoU(A,B)=0.
想法:推广loU到非重叠情形,并且确保:
(a)遵循与loU相同的定义,即将比较对象的形状属性编码为区域(region)属性;
(b)维持loU的尺寸不变性;
(c)在重叠对象的情况下确保与loU的强相关性。
GloU(generalized intersection over union)

the smallest convex shapes C enclosing both A and B
空间金字塔池化 (SPP——spatial pyramid pooling)
YOLOv5-SPP
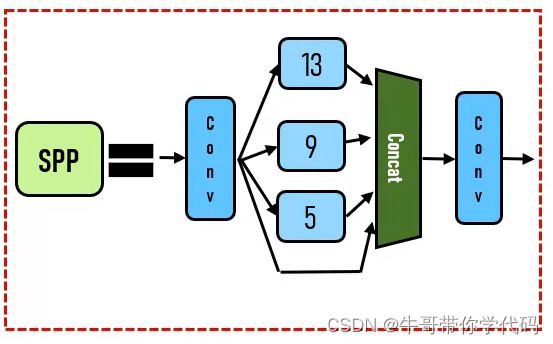
在 CSP 上添加 SPP 块,因为它能显著增加接收场,分离出最重要的上下文特征,而且几乎不会降低网络运行速度。
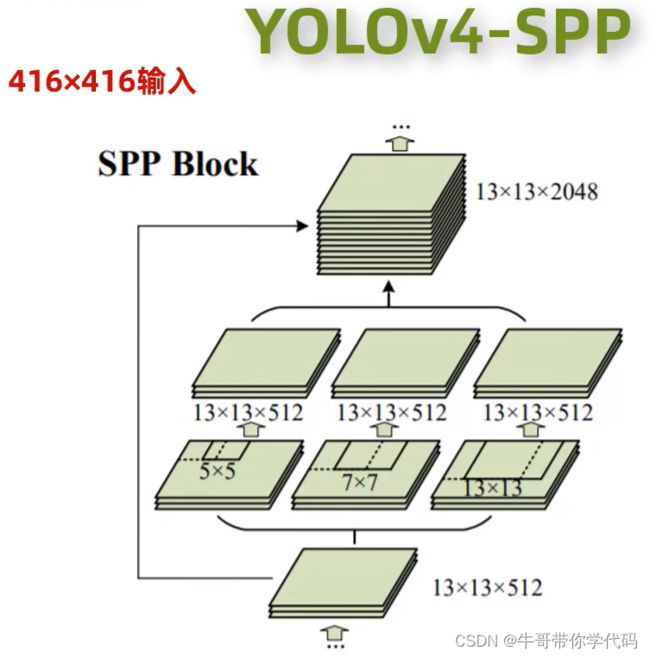
相比较而言的YOLOv4的SPP模块如上
PAnet(path-aggregation network路径聚合网络)
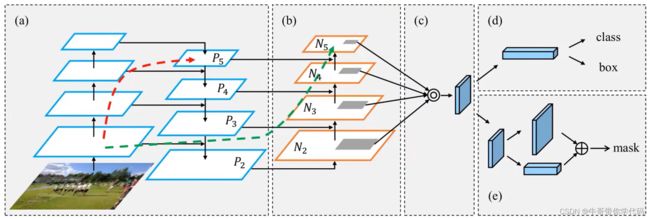
对 一般的特征金字塔网络,他的特征图大小为不同的尺度,可以对于不同尺度做融合,但是当在较下面的维度和右侧的红色箭头指向的维度进行融合时,不利于进行融合。(如图a)
对于PAnet而言,他会增加一个bottom-up的模型(如图b),使得下面的较为精细的尺度特征图能够较为容易的传递到上层。然后在相同的尺度上进行融合,最后进行拼接操作(如图c)。由于PAnet中的a和b存在尺度特征图的上升和下降的信息流传递,使得PAnet的信息也较spp更为丰富。
目标框回归
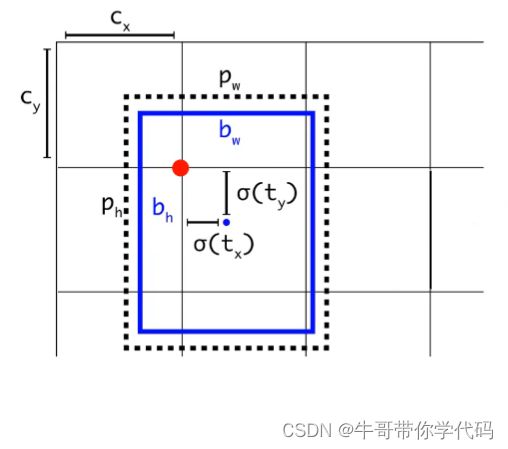
Anchor给出了目标宽高的初始值,需要回归的是目标真实宽高与初始宽高的偏移量
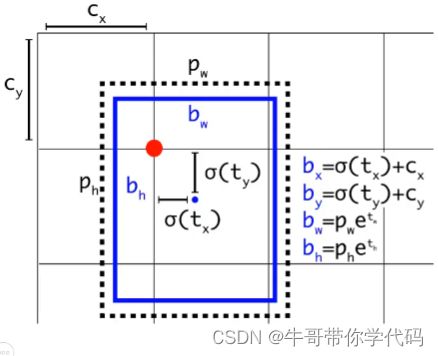
预测框中心点相对于对应网格(grid cell)左上角位置的相对偏移值
为了将边界框中心点约束在当前网格中,使用sigmoid函数处理偏移值,使预测偏移值在(0,1)范围内YoLOv/v4目标框回归公式:
根据边界框预测的4个offsets tx,ty,tw,th,可以按如下公式计算出边界框实际位置(坐标值)和宽高值:
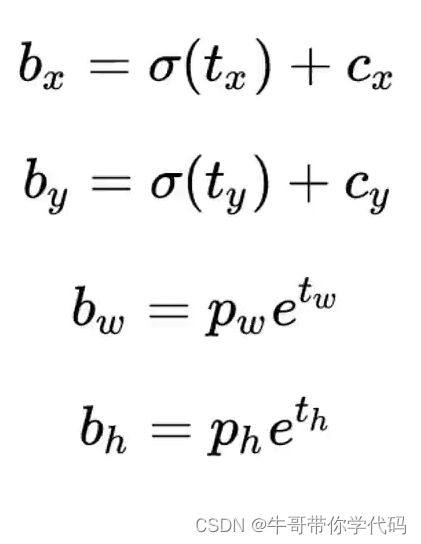
YOLOv5跨网格匹配策略
YOLO5采用了跨邻域网格的匹配策略,从而得到更多的正样本anchor,可加速收敛
从当前网格的上、下、左、右的四个网格中找到离目标中心点最近的两个网格,再加上当前网格共三个网格进行匹配。