C++递归算法
简介
递归(英语:Recursion),在数学和计算机科学中是指在函数的定义中使用函数自身的方法,在计算机科学中还额外指一种通过重复将问题分解为同类的子问题而解决问题的方法。
递归
递归的基本思想是某个函数直接或者间接地调用自身,这样原问题的求解就转换为了许多性质相同但是规模更小的子问题。求解时只需要关注如何把原问题划分成符合条件的子问题,而不需要过分关注这个子问题是如何被解决的。
递归在数学中非常常见。例如,集合论对自然数的正式定义是:1 是一个自然数,每个自然数都有一个后继,这一个后继也是自然数。
递归代码最重要的两个特征:结束条件和自我调用。自我调用是在解决子问题,而结束条件定义了最简子问题的答案。
int func(传入数值) {
if (终止条件) return 最小子问题解;
return func(缩小规模);
}为什么要写递归?
1.结构清晰,可读性强。例如,分别用不同的方法实现归并排序:
// 不使用递归的归并排序算法
template
void merge_sort(vector a) {
int n = a.size();
for (int seg = 1; seg < n; seg = seg + seg)
for (int start = 0; start < n - seg; start += seg + seg)
merge(a, start, start + seg - 1, std::min(start + seg + seg - 1, n - 1));
}
// 使用递归的归并排序算法
template
void merge_sort(vector a, int front, int end) {
if (front >= end) return;
int mid = front + (end - front) / 2;
merge_sort(a, front, mid);
merge_sort(a, mid + 1, end);
merge(a, front, mid, end);
} -
显然,递归版本比非递归版本更易理解。递归版本的做法一目了然:把左半边排序,把右半边排序,最后合并两边。而非递归版本看起来不知所云,充斥着各种难以理解的边界计算细节,特别容易出 bug,且难以调试。
-
练习分析问题的结构。当发现问题可以被分解成相同结构的小问题时,递归写多了就能敏锐发现这个特点,进而高效解决问题。
递归的缺点
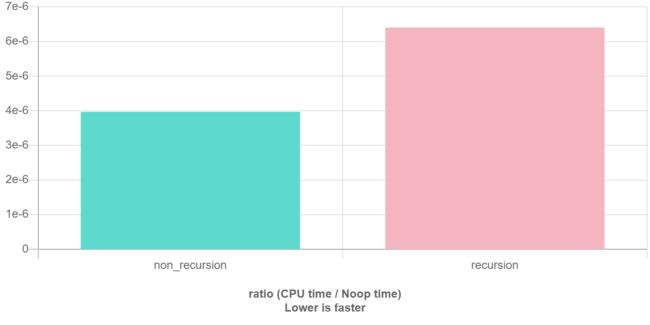
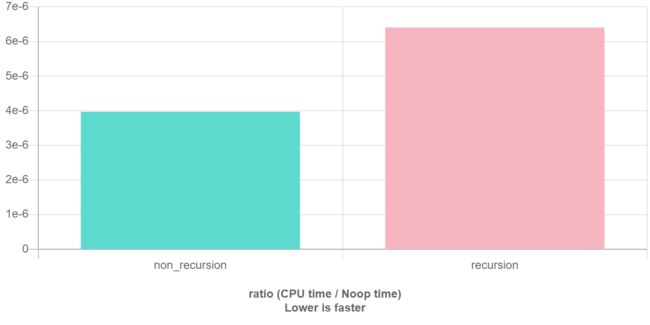
在程序执行中,递归是利用堆栈来实现的。每当进入一个函数调用,栈就会增加一层栈帧,每次函数返回,栈就会减少一层栈帧。而栈不是无限大的,当递归层数过多时,就会造成 栈溢出 的后果。
显然有时候递归处理是高效的,比如归并排序;有时候是低效的,比如数孙悟空身上的毛,因为堆栈会消耗额外空间,而简单的递推不会消耗空间。比如这个例子,给一个链表头,计算它的长度:
// 典型的递推遍历框架
int size(Node *head) {
int size = 0;
for (Node *p = head; p != nullptr; p = p->next) size++;
return size;
}
// 我就是要写递归,递归天下第一
int size_recursion(Node *head) {
if (head == nullptr) return 0;
return size_recursion(head->next) + 1;
}