软件框架 -转
转自zhuweisky
框架和类库等概念的出现都是源于人们对复用的渴望。“不要重复发明轮子”,成了软件界的一句经典名言。从最初的单个函数源代码的复用,到面向对象中类的复用(通常以类库的形式体现),再到基于组件编程中二进制组件(.NET中是以IL程序集形式存在的)的复用,人们复用软件的抽象层次越来越高。现在,框架复用是抽象层次的又一提升,框架的复用不仅仅是功能的复用,更是设计的复用。
1.1 框架与类库的区别
我们先来简单说说什么是类库(Class Library)?望文生义,类库就是一些类的集合,只要我们将一些可以复用的类集中放到一个Library中,我们就可以称其为一个类库。类库中的许多元素(如类、结构、接口、枚举、委托等)之间可能有一些关联,但这些关联通常用于支持一个类概念或接口概念的完整表达。如果我们从一个更高的视角来审视类库,可以发现类库中的一个个“完整的概念”之间是无关的或是关系松散的。
再来说框架,框架的第一含义是一个骨架,它封装了某领域内处理流程的控制逻辑,所以我们经常说框架是一个半成品的应用。由于领域的种类是如此众多,所以框架必须具有针对性,比如,专门用于解决底层通信的框架,或专门用于医疗领域的框架。框架中也包含了很多元素,但是这些元素之间关系的紧密程度要远远大于类库中元素之间的关系。框架中的所有元素都为了实现一个共同的目标而相互协作。
没有一个万能的框架可以应用于所有种类的领域和应用,框架的目标性非常强,它专注于解决某一特定领域的问题,并致力于为这一特定领域提供通用的解决方案。
框架与类库的区别主要表现在以下几个方面:
(1)从结构上说,框架内部是高内聚的,而类库内部则是相对松散的。
(2)框架封装了处理流程的控制逻辑,而类库几乎不涉及任何处理流程和控制逻辑。
正是由于框架对处理流程的控制逻辑进行了封装,才使得框架成为一个应用的骨架。框架中的处理流程和控制逻辑需要经过精心的设计,因为所有使用了该框架的应用程序都会复用该设计。
(3)框架具有IOC(控制反转)能力,而类库没有。
IOC,即俗称的好莱坞模式(Don’t call us, we will call you)。对于类库中的元素来说,通常都是由我们的应用来调用它;而框架具有这种能力――在适当的时候调用我们应用中的逻辑。这种能力是通过框架扩展点(或称为“插槽”)来做到的――具体的应用通过扩展点注入自己的逻辑,而在适当的时候,框架会调用这个扩展点中已注册的逻辑。实际上,.NET中的事件(event)发布、预定机制就是IOC的一个代表性例子。
(4)框架专注于特定领域,而类库却是更通用的。
框架着力于一个特定领域的解决方案的完整表达,而类库几乎不针对任何特定领域。比如,本书中提到的通信框架只适用于需要在TCP/UDP基础上直接构建通信的应用程序,而像正则表达式这样的类库却可以使用在各种不同的应用中。
(5)框架通常建立在众多类库的基础之上,而类库一般不会依赖于某框架。
1.2 通用框架与应用框架
如果要对框架进行进一步分类,则可以根据框架针对的领域是否具有通用性而将它们分为通用框架(General Framework)和应用框架(Application Framework)。通用框架可以在不同类型的应用中使用,而应用框架只被使用于某一特定类型的应用中。
比如,ORM框架NHibernate就是一个通用框架,该框架可以用于所有需要解决O/R映射的各种类型的应用中。而某个金融框架则是一个应用框架,它仅仅被用于金融类型的应用中。
可以这么说,通用框架所解决的是所有类型的应用都关心的“普遍”问题,而应用框架解决的是某一特定类型的应用关心的问题。所以,如果我们需要将某种类型的应用的核心业务逻辑流程提升到一个框架中,所得到的这个框架就是一个应用框架。与通用框架相比,应用框架需要了解更多目标业务领域内的领域知识。
在实现具体的应用程序时,可以采用一个应用框架与多个通用框架相结合的方式,这样有利于快速、高质量的应用程序开发。比如,某个金融领域的一个应用,可以采用金融框架作为应用框架来解决与金融业务逻辑相关的问题,采用Nhibernate解决数据访问,采用ESFramework解决应用中各分布式系统之间的通信。
下图描述了类库、框架和应用之间的层次关系。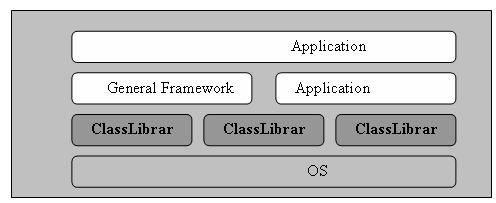
当然,一个应用也可以完全不采用任何框架,而是直接从最基础的底层API(如.NET Framework)开始构建。对于微型的系统,这种方式或许可行。但对于复杂大型的应用,困难度就可想而知了。
1.3 框架之于应用
当一个应用系统选定了框架之后,我们需要做的就是在框架提供扩展点的地方添加应用的具体逻辑,也就是使用“血”和“肉”来填充这个骨架从而得到一个“有机体”。
由于框架通常都是在实践中经过反复使用和检验的,所以质量有一定的保证,这使得我们用更少的时间、更少的编码来实现一个更稳定的系统成为可能。当然,框架也不是“银弹”,它不能解决软件复杂性的根本问题,但是我们却通过它向这个终极的理想目标又迈进了一步。
有一点需要注意,框架使得我们的系统在有所支撑的同时,它也给出了限制。因为通常当我们确定采用了某一个框架之后,我们就必须在这个框架限制的“框框”之内来构建我们的应用。大多数时候,这不是一个问题,但是如果因为框架的限制而严重影响了我们系统目标的实现的时候,我们就需要考虑是否应该放弃这个框架,或者换一个其它的同类型的框架。
1.4 框架设计
框架使得我们开发应用的速度更快、质量更高、成本更低,这些好处是不言而喻的。然而,面对万千变化日趋复杂的软件需求,设计和实现一个高度灵活可复用的框架又谈何容易!
框架源于应用,却又高于应用。
框架往往是这样产生的:我们拥有了开发某种类型应用的大量经验,我们总结这种类型的应用中共性的东西,将其提炼到一个高的层次中,以备复用。这个“高层次”的东西便是框架的原型。随着我们经验的不断积累,框架也会不断地完善、发展。
框架是一个实践的产物,而不是在实验室中理论研究出来的。所以设计一个框架最好的方法就是从一个具体的应用开始,以提供同一类型应用的通用解决方案为目标,不断地从具体应用中提炼、萃取框架!然后在应用中使用这个框架,并在使用的过程中不断地修正和完善。
有一点需要特别注意,正如所有的软件架构设计的要点在于权衡(在这方面有点像艺术),框架的设计也不例外,正如前面提到,框架在为应用提供了一个骨架的同时,也给我们的应用圈定了一个框框,我们只能在这个有限的天地内来发挥。所以,一个好的框架设计应当采用了一个非常恰当的权衡决策,以使框架在为我们应用提供强大支持的同时,而又对我们的应用作更少的限制。权衡,从来就不是一件简单的事情,但是有很多框架设计的经验可以供我们参考。
1.4.1 框架设计经验、原则
(1)框架不要为应用做过多的假设!
关于框架为应用做过多的假设,一个非常具体的现象就是,框架越俎代庖,把本来是应用要做的事情揽过来自己做。这是一种典型的吃力不讨好的做法。框架越俎代庖,也许会使得某一个具体应用的开发变得简单,却会给其它更多想使用该框架的应用增加了本没有必要的束缚和负担。
(2)使用接口,保证框架提供的所有重要实现都是可以被替换的。
框架终究不是应用,所以框架无法考虑所有应用的具体情况,保证所有重要的组件的实现都是可以被替换的,这一点非常重要,它使得应用可以根据当前的实际情况来替换掉框架提供的部分组件的默认实现。使用接口来定义框架中各个组件及组件间的联系,将提高框架的可复用性。
(3)框架应当简洁、一致、且目标集中。
框架应当简洁,不要包含那些对框架目标来说无关紧要的东西,保证框架中的每个组件的存在都是为了支持框架目标的实现。包含过多无谓的元素(类、接口、枚举等),会使框架变得难以理解,尝试将这些对于框架核心目标不太重要的元素转移到类库中,可以使得框架更清晰、目标更集中。
(4)提供一个常用的骨架,但是不要固定骨架的结构,使骨架也是可以组装的。
比如说,如果是针对某种业务处理的框架,那么框架不应该只提供一套不可变更的业务处理流程,而是应该将处理流程“单步”化,使得各个步骤是可以重新组装的,如此一来,应用便可以根据实际情况来改变框架默认的处理流程。这种框架的可定制化能力可以极大地提高框架的可复用性。
(5)不断地重构框架。
如果说设计和实现一个高质量的框架有什么秘诀?答案只有一个,重构、不断地重构。重构框架的实现代码、甚至重构框架的设计。重构的驱动力源于几个方面,比如对要解决的本质问题有了更清晰准备的认识,在使用框架的时候发现某些组件职责不明确、难以使用,框架的层次结构不够清晰等。
1.4.2 如何称得上一个优秀的框架?
一个优秀框架的最主要的特点是:简单。这种简单性不是轻而易举就可以获得的,正如优秀的框架不是一蹴而就的,达到这种简单性需要对框架不断地抽丝、不断地提炼和完善。简单的真正原因在于它抓住了要解决的问题的本质。一个优秀的框架通常都具有如下特点:
(1)清晰的、简洁的、一致的。
“清晰”指的是框架的结构是清晰的、框架的层次是清晰明朗的、框架中各个类和组件的职责是清晰明确的。
“简洁”指的是框架中没有无关紧要多余的元素,而且各个类和组件的职责目标是非常集中的,这正是“高内聚、低耦合”设计原则的体现。
“一致”通常会带来这样的好处,框架的使用者在熟悉了框架的一部分后,会非常容易地理解框架的另一部分。“一致”通常体现在命名的规则一致、命名的含义一致、组件的装配方式和使用方式一致等。
(2)易于使用的
只有易于使用的框架才会走得更远。
正是因为易于使用,框架使用者们才有可能试用这个框架,在试用满意后才有可能决定采用这个框架。一个框架功能即使再强大,如果难以使用,那么框架使用者们很可能根本就不会有试用这个框架的念头。
框架的生命力源于框架一直在不断地完善和发展,如果没有人使用这个框架,这个框架便没有了发展和完善的源动力。正如友好的用户界面是优秀应用程序不可或缺的重要部分,易于使用也是优秀框架的一个重要特性。
(3)高度可扩展的、灵活的
框架通过高度可扩展性来应对应用程序的万千变化。
没有任何一个框架可以预料所有应用的需求,万能的框架是不存在的。企图设计、实现一个万能框架的想法是荒诞的。框架必须具有“以不变应万变”的能力,框架可以通过为应用预留恰当的、足够的扩展点来做到这一点。
框架的灵活体现在框架可以根据不同的应用进行不同的组装和配置,就像框架是专门为当前的应用所订制的一样。
(4)轻量的
“轻量”,说的通俗点,就是只为自己需要使用的服务付费,而不需要为自己不需要的服务买单。一个重量级的框架有一个很明显的特征就是,如果你需要一套完整的套餐服务,那是没有问题的,框架可以很好的满足你;但是,如果你只需要这份套餐中的一小块点心,对不起,框架仍然会强加一个完整的套餐给你,你必须付一整份套餐的费用。
优秀的框架应当支持使用者“按需所取”的原则,框架使用者可以随意“点菜”进行组装来满足自己的需求。
(5)弱侵入性的
所谓“弱侵入性”,采用了框架的应用程序可以尽可能的以普通的方式来编写应用逻辑,而不必为了适应框架不得不使用一些特殊的手法。
这可能有点难以理解,我们可以举个例子来简单说明。在.NET中,实现AOP(面向方面编程)机制的两种主要方式是使用Proxy和动态代理。使用Proxy实现的AOP框架通常要求那些需要使用AOP截获功能的类必须继承自ContexBoundObject;而采用动态代理实现的AOP框架则没有任何如此侵入性的要求,我们仍可以以最普通的方式来编写应用逻辑类,这类框架会在运行时根据配置动态地生成目标对象的代理对象来实现AOP截获。所以我们可以说,采用动态代理方式实现的AOP框架相比采用Proxy实现的AOP框架,具有更弱的侵入性。
弱侵入性意味着框架对应用逻辑的干扰更少,由于应用逻辑类都是普通的类,这非常方便应用逻辑在另外一个程序中复用,而另外的程序可能采用了一个完全不同的框架。
我的架构经验小结(一)-- 常用的架构模型 经过这几年的积累,在系统架构方面逐渐积累了一些自己的经验,到今天有必要对这些经验作个小结。在我的架构思维中,主要可以归类为三种架构模型:3/N层架构、“框架+插件”架构、地域分布式架构。
一.三种架构模型
1.3/N层架构
这是经典的多层架构模型,对于稍微复杂一点或特别复杂的系统,不使用分层架构是很难想象的。下图是经典的3层架构: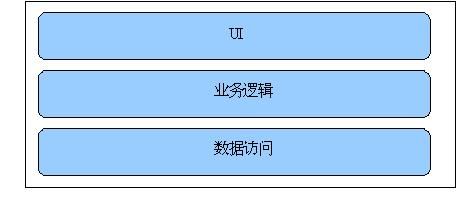
如今,凡是个程序员都能侃侃而谈3/N层架构,这确实是解决系统复杂性的一种主流模式,但是,只要采用了3/N层架构是不是就一定能解决系统的复杂性了?不一定,关键在于你在你的系统中如何实作你的3/N层结构。
在采用了3/N层架构后,我们还是要解决以下非常重要的问题:系统的可扩展性(能从容地应对变化)、系统的可维护性(因为系统并不是使用一次就被抛弃)、方便部署(在需求变化时,方便部署新的业务功能)、还有等等其它系统质量属性。然而系统的可扩展性和可维护性是大多数软件系统必须解决的重中之重,这是由于当前需求复杂多变的软件环境决定的。就像实现功能需求是最基本的,采用3/N层架构也只是万里长征的第一步。
我采用“框架+插件”架构来解决与系统的可扩展性、可维护性和部署相关的难题。
2. “框架+插件”架构
经典的3/N层架构是对系统进行“纵向”分层,而“框架+插件”架构对系统进行“横向”分解。3/N层架构和“框架+插件”架构处于一个平等的位置,它们没有任何依赖关系。
但是我经常将它们结合在一起使用,我们的系统在经过3/N层架构的纵向分层和“框架+插件”架构的横向分层后,可以被看作一个“网格”结构,其中的某些网格可以看作是“扩展点”,我们可以在这些扩展点处挂接“插件”。也就是说我们可以在3/N层架构的每一层都挂接适当的插件来完成该层的一些功能。如: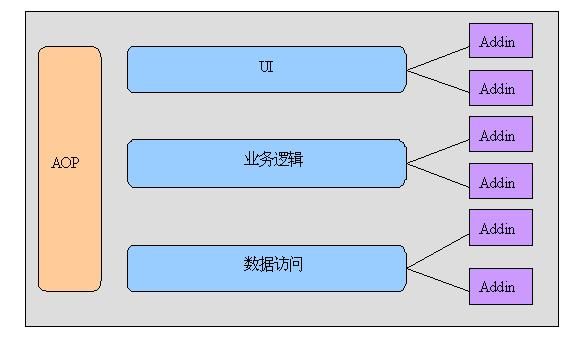
插件最主要的特点是可以实现“热插拔”,也就是说可以在不停止服务的情况下,动态加载/移除/更新插件。所以,采用插件技术可以实现以下功能:
(1)在UI层,我们可以在运行时,替换掉某些用户界面、或加载与新的业务相关的用户界面。在业务逻辑层,我们可以在运行时加载、替换或者删除某项业务服务。在数据访问层,通过使用插件技术我们可以动态地添加对新的数据库类型(如MySQL)的支持。
插件的“热插拔”功能使得我们的系统有非常好的可扩展性。
(2)如果我们需要升级系统,很多情况下,只要升级我们的插件(比如业务插件)就可以了,我们可以做到在服务运行的时候进行插件的自动升级。
(3)要想将系统做成“框架+插件”的结构,要求我们需要在系统的各层进行“松耦合”设计,只有松耦合的组件才可以被做成“插件”。
在3/N层架构中融合“框架+插件”架构,最难的是对业务逻辑层的松耦合处理,这需要我们细致分析业务需求之间的关联,将耦合度紧密的业务封装在一个组件中,如此得到的相互独立的业务组件便可以有机会成为插件。这个过程可能需要不断的重构、设计的重构。
我们知道,相比于那些紧密耦合的组件,松耦合的组件更加清晰明确、更加容易维护。另外,在该架构模型中引入了AOP框架进行Aspect焦点的集中编程(比如处理日志记录、权限管理等方面),使得Aspect代码不会掺杂在正常的业务逻辑代码中,使得代码的的清晰性、可维护性进一步增强。
从上述介绍可以看出,采用3/N层架构和“框架+插件”架构相结合,我们可以增强系统的可扩展性、可维护性和简单部署升级的能力。
3.地域分布式架构
我无意中发明了“地域分布式架构”这个词,呵呵,不知道意思是否表达得准确。地域分布式架构主要针对类似LBS(基于位置的服务)的需要进行地域分布的应用。 地域分布式架构基于上述的3/N层架构和“框架+插件”架构,它们的关系如下: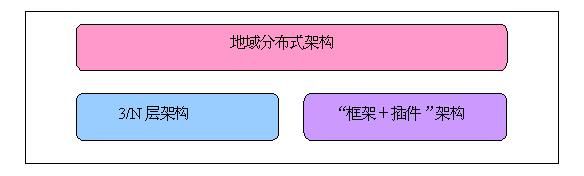
现在我对地域分布式架构作个简单的介绍。假设我们需要为全国的各个大城市提供我们的业务功能服务,假设每个城市的客户量很大,而且每个城市访问的数据可能是不一样的(如每个城市的地图数据)、访问的功能也不尽相同(如有的城市提供天气查询服务,而另一些城市不提供)。客户除了跟我们的系统请求服务之外,可能还想通过我们的系统与他的好朋友进行即时通信,而它们好朋友可能与他在同一个城市,也可能位于另外一个城市。
好了,我们看地域分布式架构是如何解决类似上述的需求的。
首先,地域分布式架构将用户管理和业务功能服务分开,分别由应用服务器(AS)和功能服务器(FS)负责,然后将它们部署到不同的节点上。AS和FS都采用了3/N层架构和“框架+插件”架构相结合的架构,比如,FS通过功能插件提供功能服务。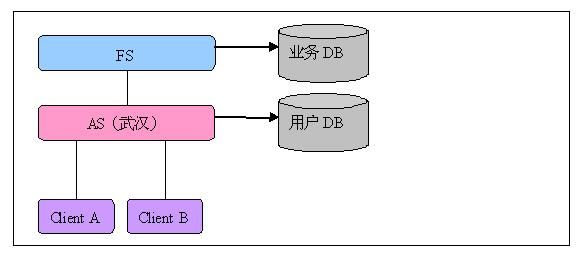
比如,对于武汉这个地域,我们部署了一台AS和一台FS,客户端通过连接到AS进行服务请求。假设有一天,我们在武汉的客户急剧增加,这是压力最大的是FS,因为所有的业务计算都是在FS上完成的。
这时,地域分布式架构将允许我们在不停止任何服务的情况下,动态的添加FS服务器,新添加的FS服务器会自动注册到AS。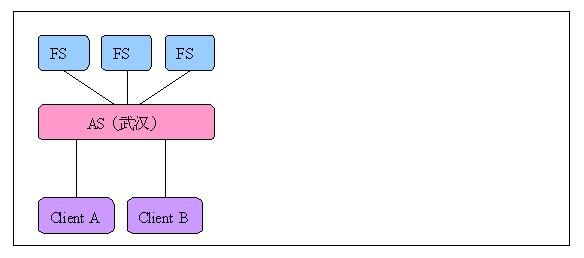
AS可以监控每个FS的负载(如CPU消耗、内存消耗),再有客户端请求到来时,AS会将请求交给负载最低的FS处理,这就实现了FS的负载均衡。
如果Client A需要与Client B进行即时通信,那么这些通信消息将通过AS中转。
上面看到的是我们的系统在武汉的部署,而在其他城市部署情况也一样。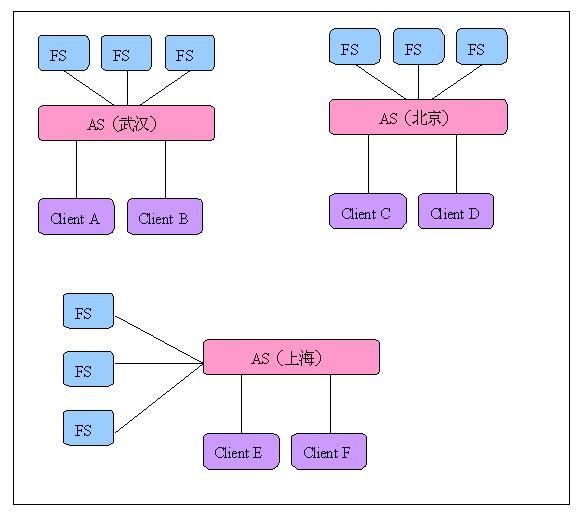
在这种情况下,AS和AS之间是相互独立的,但是经常会发生AS之间需要相互通信的情况,比如:Client A需要与Client E进行即时通信,或者Client A需要请求上海地区独有的服务,等等。
地域分布式架构使用跨区域的应用服务器(IRAS)来解决AS之间的通信问题。所有AS在启动的时候,将自动向IRAS注册。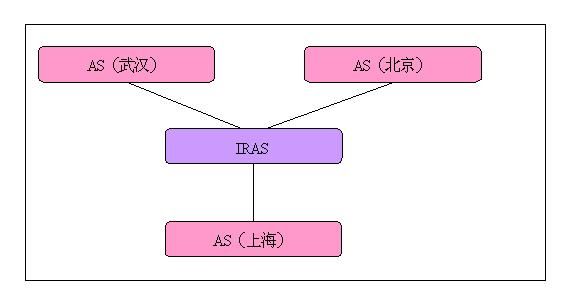
如果,我们想在长沙市也提供我们的服务,那么我们只需要在长沙部署我们的AS和FS,这样就可以融入到上图表示的整个地域分布式架构中。
关于地域分布式架构,就简单的介绍这么多,更多的内容,读者可以自己去分析挖掘。
二.对架构模型的支持
如果没有自己的一套工具对上述的架构模型作支持,那么你可能会认为我是在这里胡扯、夸夸其谈。在这几年的开发中,我积累了几套框架和类库用于对上述架构模型提供支持。
(1) DataRabbit 提供了基于关系和基于ORM(轻量)的数据访问,通过插件的方式来支持新的数据库类型。
(2) ESFramework 解决了分布式系统(如上述的地域分布式架构)之间的底层通信(直接基于TCP和UDP)。
(3) AddinsFramework 为“框架+插件”架构模型提供支持。
(4) ESAspect 通过Proxy方式实现的AOP框架,对方面编程提供支持。
(5) EsfDRArchitecture 为地域分布式架构模型提供支持。比如支持,FS的动态添加/移除;FS的负载均衡;AS与FS、AS与IRAS之间的通信;跨区域的服务请求等等。 可以参见http://zhuweisky.cnblogs.com/archive/2006/03/15/350408.html了解更多。
上面介绍的很多内容在我以往的blog文章中都有提及,读者可以针对我早期的blog来进一步了解这些内容。
在 我的架构经验小结(一)-- 常用的架构模型 一文中简单介绍了我常采用的几种架构模型,本文将稍微深入地介绍其中的一种 -- 三层架构模型。
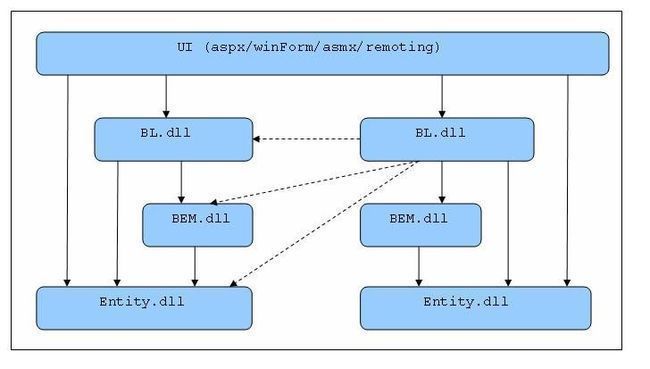
一.三层架构图
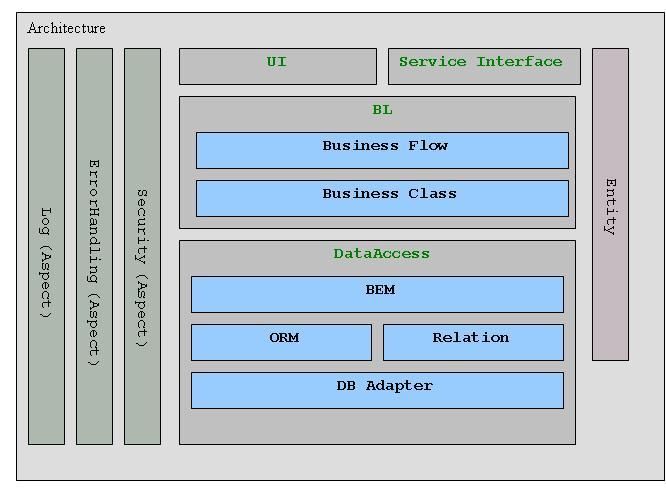
二.系统各层次职责
1.UI(User Interface)层的职责是数据的展现和采集,数据采集的结果通常以Entity object提交给BL层处理。与UI平行的Service Interface层用于将业务发布为服务(如WebServices)。
2.BL(Business Logic)层的职责是按预定的业务逻辑处理UI层提交的请求。
(1)Business class 子层负责基本业务功能的实现。
(2)Business Flow 子层负责将Business class子层提供的多个基本业务功能组织成一个完整的业务流。(Transaction通常在Business Flow 子层开启。)
3.DataAccess层的职责是提供全面的数据访问功能支持,并向上层屏蔽所有的SQL语句以及数据库类型差异。
(1)DB Adapter子层负责屏蔽数据库类型的差异。
(2)ORM子层负责提供对象-关系映射的功能。
(3)Relation子层提供ORM无法完成的基于关系(Relation)的数据访问功能。
(4)BEM(Business Entity Manager)子层采用ORM子层和Relation子层来提供业务需要的基础数据访问能力。
三.Aspect
Aspect贯穿于系统各层,是系统的横切关注点。通常采用AOP技术来对横切关注点进行建模和实现。
1.Securtiy Aspect:用于对整个系统的Security提供支持。
2.ErrorHandling Aspect:整个系统采用一致的错误/异常处理方式。
3.Log Aspect:用于系统异常、日志记录、业务操作记录等。
四.规则
1.系统各层次及层内部子层次之间都不得跨层调用。
2.Entity object 在各个层之间传递数据。
3.需要在UI层绑定到列表的数据采用基于关系的DataSet传递,除此之外,应该使用Entity object传递数据。
4.对于每一个数据库表(Table)都有一个Entity class与之对应,针对每一个Entity class都会有一个BEM Class与之对应。
5.在数量上,BEM Class比Entity class要多,这是因为有些跨数据库或跨表的操作(如复杂的联合查询)也需要由相应的BEM Class来提供支持。
6.对于相对简单的系统,可以考虑将Business class 子层和Business Flow 子层合并为一个。
7.UI层和BL层禁止出现任何SQL语句。
五.错误与异常
异常可以分为系统异常(如网络突然断开)和业务异常(如用户的输入值超出最大范围),业务异常必须被转化为业务执行的结果。
1.DataAccess层不得向上层隐藏任何异常(该层抛出的异常几乎都是系统异常)。
2.要明确区分业务执行的结果和系统异常。比如验证用户的合法性,如果对应的用户ID不存在,不应该抛出异常,而是返回(或通过out参数)一个表示验证结果的枚举值,这属于业务执行的结果。但是,如果在从数据库中提取用户信息时,数据库连接突然断开,则应该抛出系统异常。
3.在有些情况下,BL层应根据业务的需要捕获某些系统异常,并将其转化为业务执行的结果。比如,某个业务要求试探指定的数据库是否可连接,这时BL就需要将数据库连接失败的系统异常转换为业务执行的结果。
4.UI层除了从调用BL层的API获取的返回值来查看业务的执行结果外,还需要截获所有的系统异常,并将其解释为友好的错误信息呈现给用户。
六.项目目录结构
1.目录结构:以EAS系统为例。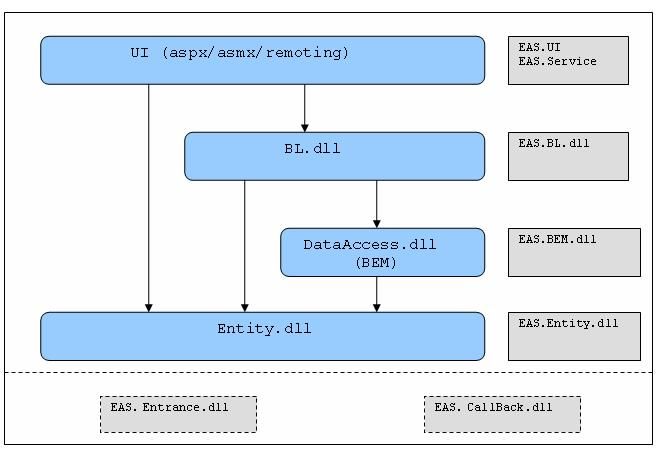
2.命名空间命名:每个dll的根命名空间即是该dll的名字,如EAS.BL.dll的根命名空间就是EAS.BL。每个根命名空间下面可以根据需求的分类而增加子命名空间,比如,EAS.BL的子空间EAS.BL.Order与EAS.BL.Permission分别处理不同的业务逻辑。
七.发布服务与服务回调
以EAS系统为例。
1.如果EAS系统提供了WebService(Remoting)服务,则EAS必须提供EAS.Entrance.dll。EAS.Entrance.dll封装了与EAS服务交换信息的通信机制,客户系统只要通过EAS.Entrance.dll就可以非常简便地访问EAS提供的服务。
2.如果EAS需要通过WebService(Remoting)回调客户系统,则必须提供仅仅定义了接口的EAS.CallBack.dll,客户系统将引用该dll,实现其中的接口,并将其发布为服务,供EAS回调。
3.当WebService的参数或返回值需要是复杂类型,则该复杂类型应该在对应的EAS.Entrance.dll或EAS.CallBack.dll中定义,WebService定义的方法中的复杂类型应该使用Xml字符串代替,而Xml字符串和复杂类型对象之间的转换应当在EAS.Entrance.dll或EAS.CallBack.dll中实现。
我的架构经验小结(三)-- 深入三层架构
在 我的架构经验小结(二)-- 关于三层架构 一文中,已经比较深入的介绍过三层架构方面的一些经验了,现在,我们来使用一个更小的比例尺来近距离观察我所理解的三层架构。
一.三层架构图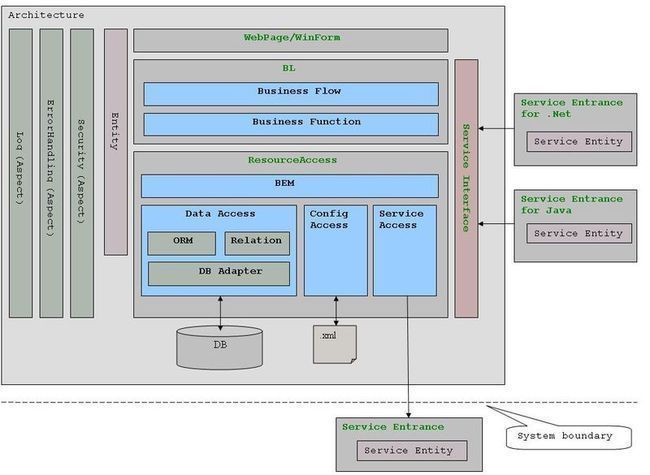
二.系统各层次职责
1.UI(User Interface)层的职责是数据的展现和采集,数据采集的结果通常以Entity object提交给BL层处理。Service Interface侧层用于将业务或数据资源发布为服务(如WebServices)。
2.BL(Business Logic)层的职责是按预定的业务逻辑处理UI层提交的请求。
(1)Business Function 子层负责基本业务功能的实现。
(2)Business Flow 子层负责将Business Function子层提供的多个基本业务功能组织成一个完整的业务流。(Transaction只能在Business Flow 子层开启。)
3.ResourceAccess层的职责是提供全面的资源访问功能支持,并向上层屏蔽资源的来源。
(1)BEM(Business Entity Manager)子层采用DataAccess子层和ServiceAccess子层来提供业务需要的基础数据/资源访问能力。
(2)DataAccess子层负责从数据库中存取资源,并向BEM子层屏蔽所有的SQL语句以及数据库类型差异。
DB Adapter子层负责屏蔽数据库类型的差异。
ORM子层负责提供对象-关系映射的功能。
Relation子层提供ORM无法完成的基于关系(Relation)的数据访问功能。
(3)ServiceAccess子层用于以SOA的方式从外部系统获取资源。
注:Service Entrance用于简化对Service的访问,它相当于Service的代理,客户直接使用Service Entrance就可以访问系统发布的服务。Service Entrance为特定的平台(如Java、.Net)提供强类型的接口,内部可能隐藏了复杂的参数类型转换。
(4)ConfigAccess子层用于从配置文件中获取配置object或将配置object保存倒配置文件。
4.Entity侧层跨越UI/BEM/ResourceManager层,在这些层之间传递数据。Entity侧层中包含三类Entity,如下图所示:
三.Aspect
Aspect贯穿于系统各层,是系统的横切关注点。通常采用AOP技术来对横切关注点进行建模和实现。
1.Securtiy Aspect:用于对整个系统的Security提供支持。
2.ErrorHandling Aspect:整个系统采用一致的错误/异常处理方式。
3.Log Aspect:用于系统异常、日志记录、业务操作记录等。
四.规则
1.系统各层次及层内部子层次之间都不得跨层调用。
2.Entity object 在各个层之间传递数据。
3.需要在UI层绑定到列表的数据采用基于关系的DataSet传递,除此之外,应该使用Entity object传递数据。
4.对于每一个数据库表(Table)都有一个DB Entity class与之对应,针对每一个Entity class都会有一个BEM Class与之对应。
5.有些跨数据库或跨表的操作(如复杂的联合查询)也需要由相应的BEM Class来提供支持。
6.对于相对简单的系统,可以考虑将Business Function子层和Business Flow 子层合并为一个。
7.UI层和BL层禁止出现任何SQL语句。
五.错误与异常
异常可以分为系统异常(如网络突然断开)和业务异常(如用户的输入值超出最大范围),业务异常必须被转化为业务执行的结果。
1.DataAccess层不得向上层隐藏任何异常(该层抛出的异常几乎都是系统异常)。
2.要明确区分业务执行的结果和系统异常。比如验证用户的合法性,如果对应的用户ID不存在,不应该抛出异常,而是返回(或通过out参数)一个表示验证结果的枚举值,这属于业务执行的结果。但是,如果在从数据库中提取用户信息时,数据库连接突然断开,则应该抛出系统异常。
3.在有些情况下,BL层应根据业务的需要捕获某些系统异常,并将其转化为业务执行的结果。比如,某个业务要求试探指定的数据库是否可连接,这时BL就需要将数据库连接失败的系统异常转换为业务执行的结果。
4.UI层(包括Service层)除了从调用BL层的API获取的返回值来查看业务的执行结果外,还需要截获所有的系统异常,并将其解释为友好的错误信息呈现给用户。
六.项目组织目结构
以BAS系统为例。
1.主目录结构:
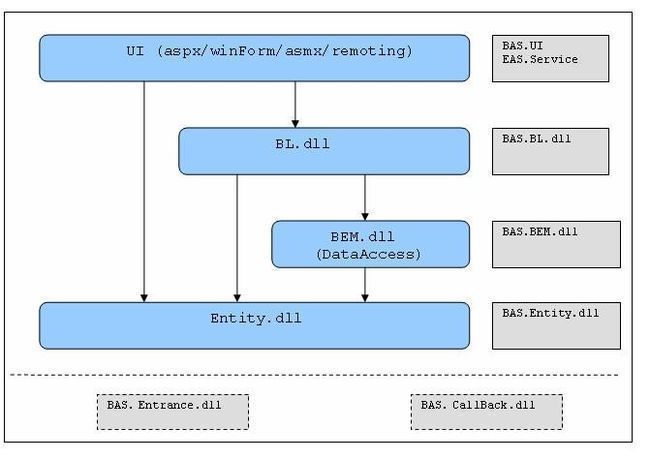
2.命名空间命名:每个dll的根命名空间即是该dll的名字,如EAS.BL.dll的根命名空间就是EAS.BL。每个根命名空间下面可以根据需求的分类而增加子命名空间,比如,EAS.BL的子空间EAS.BL.Order与EAS.BL.Permission分别处理不同的业务逻辑。
3.包含众多子项目的庞大项目的物理组织:
核心子项目Core的位置: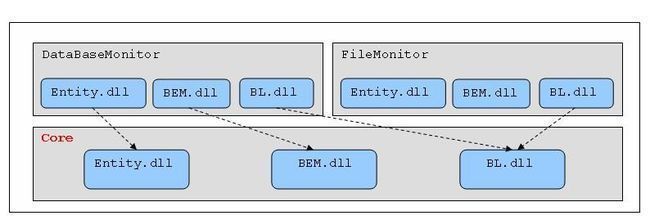
Core子项目中包含一些公共的基础设施,如错误处理、权限控制方面等。
七.发布服务与服务回调
以EAS系统为例。
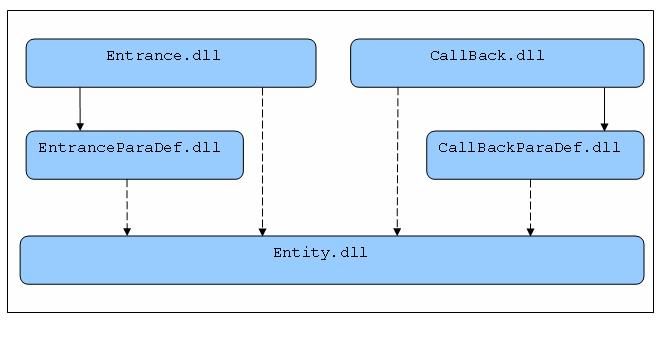
1.同UI层的Page一样,服务也不允许抛出任何异常,而是应该以返回错误码(int型,1表示成功,其它值表示失败)的形式来表明服务调用出现了错误,如果方法有返回值,则返回值以out参数提供。
2.如果BAS系统提供了WebService(Remoting)服务,则BAS必须提供BAS.Entrance.dll。BAS.Entrance.dll封装了与BAS服务交换信息的通信机制,客户系统只要通过BAS.Entrance.dll就可以非常简便地访问BAS提供的服务。
3.如果BAS需要通过WebService(Remoting)回调客户系统,则必须提供仅仅定义了接口的BAS.CallBack.dll,客户系统将引用该dll,实现其中的接口,并将其发布为服务,供BAS回调。
4.当WebService的参数或返回值需要是复杂类型――即架构图中的Service Entity,则Service Entity应该在对应的BAS.EntranceParaDef.dll或BAS.CallBackParaDef.dll中定义。WebService定义的方法中的复杂类型应该使用Xml字符串代替(注意,Entrance和CallBack接口对应服务的方法的参数是强类型的),而Xml字符串和复杂类型对象之间的转换应当在BAS.Entrance.dll或BAS.CallBack.dll中实现。
我的架构经验小结(四)-- 实战中演化的三层架构
在06、07年的时候,我写过一些关于三层架构方面的东西(参见这里),现在看来,觉得有很多实用性的内容需要补充到里面去。我们还是先从架构图看起,然后一一解释,你就会发现相比于两年前,这个架构做了哪些变化和调整。
一.三层架构图
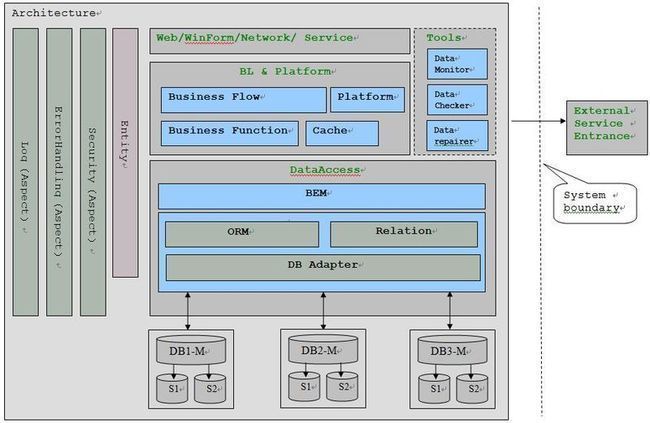
二.系统各层次职责
1.UI(User Interface)层的职责是数据的展现和采集,数据采集的结果通常以Entity object提交给BL层处理。
Web表示我们常用的B/S应用,WinForm表示我们常用的C/S应用。
Network层以Socket的方式提供服务给客户端。
Service层用于将业务或数据资源发布为服务(如WebServices)。
2.BL(Business Logic)&Platform层的职责是按预定的业务逻辑处理UI层提交的请求,并对核心资源进行管理。
(1)Business Function 子层负责基本业务功能的实现。
(2)Business Flow 子层负责将Business Function子层提供的多个基本业务功能组织成一个完整的业务流。
(3)Platform子层用于统一管理有状态的数据和资源。
(4)注意:Transaction只能在BusinessFlow/Platform层开启。
(5)BL最好是没有状态的,而必需的状态管理可以放到Platform中的某些模块/子系统进行。如此可增强系统的可伸缩性。
(6)Cache子层用于缓存系统常用的数据信息,Cache对于提供系统的并发量和吞吐能力起到至关重要的作用。Cache可以分为以下几类:
| StaticCache |
HotCache |
SyncEntityCache |
RefreshCache |
SubObjectCache |
StaticCache:如果某数据表中的数据是静态的、不会发生变化的,那就非常容易,我们只需要在系统启动的时候,将其加载到内存,以后每次从内存读取数据即可。
HotCache:如果数据表中的记录非常多,并且修改方面只会有Insert操作,那么我们可以使用HotCache,把那些经常使用的记录缓存在内存中,并且可设定超时机制删除内存中长期不使用的记录。
SyncEntityCache:如果我们的某个数据表中的数据会发生变化(增删改),但是变化的频率比较低,但是我们的系统对这个表的数据的实时性的敏感度也特别高,那这时候我们就需要用到【实时同步的实体缓存】,这个缓存中的数据在任何时候都与数据表中的数据是完全一致的。
RefreshCache:如果数据表中的数据会发生变化(增删改),但是变化的频率非常低,而恰巧我们的系统对数据实时性的敏感度也不是特别高,那我们可以使用定时刷新的缓存。
SubObjectCache:如果某个数据表的修改经常是Insert和Update操作,但是无论如何Update,每条记录有些固定栏位的值都是不会发生变化的,那我们可以把这些不会发生变化的栏位封装在一个【子对象SubObject】中,然后在内存中缓存这些子对象。
3.DataAccess层的职责是提供全面的资源访问功能支持,并向上层屏蔽资源的来源。
BEM(Business Entity Manager)子层负责从数据库中存取资源。
DB Adapter子层负责屏蔽数据库类型的差异。
ORM子层负责提供对象-关系映射的功能。
Relation子层提供ORM无法完成的基于关系(Relation)的数据访问功能。
4.Entity侧层跨越UI/BL&Platform/DataAccess层,在这些层之间传递数据。Entity侧层中包含三类Entity,如下图所示:
5.DB层可以采用数据库分散放置、读写分离策略来支持超大并发。图中数据库名称,M代表Master(主库),S代表Slave(从库)。
6.Tools层,架构图中还一个虚线表示的Tools层,之所以用虚线,是因为它并不真的是系统交付的一部分,它并不实现系统的逻辑功能。但它的存在是如此的重要,特别是在我们的开发和测试阶段。它的主要作用有:
(1)DataMonitor:能将数据库中最重要的信息方便的呈现给工程师,比如重要表和超大表的记录数等。
(2)DataChecker:直接对数据库中的数据进行完整性、一致性检查。使我们能最及时的发现业务逻辑在数据处理方面的重大失误和错漏。
(3)DataRepairer:当发现了数据错误并对程序的bug进行修正后,Tools能够对数据进行补充或修复。以使后续开发和测试能立即继续进行。
三.Aspect
Aspect贯穿于系统各层,是系统的横切关注点。通常采用AOP技术来对横切关注点进行建模和实现。
1.Securtiy Aspect:用于对整个系统的Security提供支持。
2.ErrorHandling Aspect:整个系统采用一致的错误/异常处理方式。
3.Log Aspect:用于系统异常、日志记录、业务操作记录等。
(1)通常我们会记录相邻两层的交互接口所引发的所有异常的详细信息,包括方法调用的堆栈帧、调用方法的参数的具体值。(参考这里)
(2)通常我们会跟踪相邻两层的交互接口的每个方法执行所消耗的时间,用于检查系统的性能瓶颈在哪些地方。(参考这里)
(3)通常我们会记录所有数据库访问异常的详细信息,包括sql语句内容、各参数的具体值。(参考这里)
(4)在测试阶段,通常我们会记录所有每个事务访问数据表的顺序,通过对比这些顺序,我们可以发现可能出现死锁的地方,从而加以调整。(DataRabbit内置支持)
(5)另外,一些重要的作业操作我们也会记录到日志。
四.规则
1.系统各层次及层内部子层次之间都不得跨层调用。
2.使用Entity object 在各个层之间传递数据,而不是关系型的DataSet。只有在特殊情况下,才将UI绑定到DataTable,比如返回的结果集没有Entity与之对应的时候。
3.UI层和BL层禁止出现任何SQL语句。
4.对于每一个数据库表(Table)都有一个DB Entity class与之对应,针对每一个Entity class都会有一个BEM Class与之对应。
5.有些跨数据库或跨表的操作(如复杂的联合查询)也需要由相应的BEM Class来提供支持。
6.对于相对简单的系统,可以考虑将Business Function子层和Business Flow 子层合并为一个。
五.错误与异常
异常可以分为系统异常(如网络突然断开)和业务异常(如用户的输入值超出最大范围),业务异常必须被转化为业务执行的结果。
1. DataAccess层不得向上层隐藏任何异常(该层抛出的异常几乎都是系统异常)。
2. 要明确区分业务执行的结果和系统异常。比如验证用户的合法性,如果对应的用户ID不存在,不应该抛出异常,而是返回(或通过out参数)一个表示验证结果的枚举值,这属于业务执行的结果。但是,如果在从数据库中提取用户信息时,数据库连接突然断开,则应该抛出系统异常。
3. 在有些情况下,BL层应根据业务的需要捕获某些系统异常,并将其转化为业务执行的结果。比如,某个业务要求试探指定的数据库是否可连接,这时BL就需要将数据库连接失败的系统异常转换为业务执行的结果。
4. UI层(包括Service层)除了从调用BL层的API获取的返回值来查看业务的执行结果外,还需要截获所有的系统异常,并将其解释为友好的错误信息呈现给用户。
5. 当WebService的参数或返回值需要是复杂类型――即架构图中的Service Entity,则Service Entity应该在对应的*.EntranceParaDef.dll中定义。WebService定义的方法中的复杂类型应该使用Xml字符串代替,而Xml字符串和复杂类型对象之间的转换应当在*.Entrance.dll中实现。
最后,系统架构的思想是重要的,但是架构不能纸上谈兵、不能脱离实践。
不知您有何补充或建议,请指点一二,呵呵。
框架设计经验谈 -- 不要为框架作过多的假设
框架往往是这样产生的:我们拥有了开发某种类型应用的大量经验,并开发了一些这种类型的应用,我们总结这种类型的应用中共性的东西,将其提炼到一个高的层次中,以备复用。这个“高的层次”的东西便是框架的原型。随着我们经验的不断积累,框架也会不断的向前完善、发展。框架,正如其名,就是一个应用的骨架,选用的框架的好坏直接决定了基于其上构建的应用的质量。在确定了一个框架后,我们在骨架的缝隙里为其添加“血”和“肉”,便成为一个应用。
框架源于应用,却又高于应用。
我今天要说的是,正是因为框架源于应用,所以在提炼框架的时候,我们往往不自觉的为框架作过多的假设。这些假设来源于孵化框架的具体应用中的一些潜在的“规则”或约束。为什么了?因为我们常常希望,使用了框架之后,这个孵化了框架的应用再基于这个框架来重新构建应该非常简单。这种简单性会在两种情况下出现:一是你成功地抽象出了一个非常好的框架;二是你抽象出的框架与孵化框架的应用紧密的耦合在一起。如果没有设计框架的经验,我们陷入第二种情况是必然的。
框架与孵化框架的应用的紧密耦合,换句话说,就是为框架作过多的针对这个具体应用的假设。在这种有过多假设的环境下设计框架导致的最直接的后果是:降低了框架的可复用性。我们提炼框架的目的是为了使之能在各个类似的应用中很好的复用,而依赖于太多的假设来设计框架将大大降低这一美好的目标。
框架为应用作过多的假设的一个非常具体的现象就是,框架越俎代庖,把本来是应用要做的事情揽过来自己做。这是一种典型的吃力不讨好的做法。框架越俎代庖,也许会使得一个应用的开发变得简单,却会给其它更多想使用该框架的应用增加了本没有必要的束缚和负担。
框架只做该做的事情,而哪些事情是该做的,取决于设计者的判断,而判断的正确与否取决于设计者的经验和能力。
我们设计框架时,往往在框架中提供了很多内置的组件,但是,框架不应该强迫应用使用任何一个最要、核心的组件。相反,框架应该允许应用提供组件的自定义实现来替换掉内置的组件。这个可以通过组件的接口设计并暴露之而非常容易的做到。比如,我们的框架可以规定消息头MessageHeader中必须包括哪些字段,但框架不能强制说MessageHeader就只能包括这些字段。这个区别正是接口与实现(类)的区别。框架提供的是一系列的接口和这些接口之间的相互联系,以构成骨架;应用实现这些接口以形成“血”和“肉”来填充这个骨架从而得到一个“有机体”。
空谈了这么多,举两个例子吧,这两个例子都是关于ESFramework的。
第一个例子是,有段时间将ESFramework定位为一个应用框架,期望其能适用于所有的C/S应用,于是,在ESFramework中包含了大把与应用相关的东西,使得ESFramework越来越复杂和庞大。正如,能治百病的药治不了任何病一样,能满足于所有应用的框架几乎不会被任何一个应用采用。对这个错误的解决方案的改成是,将ESFramework定位于一个单纯的通信框架,这会大大拓宽它的复用范围。(更详细描述可以参见 ESFramework 最新进展 -- ESFramework体系)
第二个例子是,在早期版本的ESFramework中有个名为ServiceType的枚举,它将所有的消息进行了分类,说实话,这种分类非常适合IM系统,但对其它C/S系统并不一定合适。而且ESFramework还针对这个ServiceType分类提供了对应的内置的消息处理器(详细情况)。现在看起来,这种做法是多么的笨!在后期的ESFramework版本中,ESFramework对消息如何分类再没有任何干涉,那些本不应该存在的消息处理器也删除了。取而代之的是使用一个DataDealerBagList,应用可以向其中添加任何消息处理器,只要应用将消息处理器与消息类型进行了正确的匹配就可以。
两个例子说完了,最后总结一下,我们的第一个经验是:不要为框架作“过多”的假设,而不是:不要为框架作“任何”假设。一个没有任何假设的框架,从另一个方向看,就是一个万能的、能解决任何问题的框架,我们知道,这样的框架是不存在的,即使存在,也是毫无用处的。
不要为框架作“过多”的假设,那么何谓“过多”了?有很多特性/组件,我们可以一眼就分辨出,它是应该存在于框架中,还是应该交给应用。但是,也有一些特性/组件,它们的所宿地就不是那么清楚了,这时,需要设计者的权衡,这种权衡恰恰是最体现设计者内功的地方。难怪有人说,软件设计也是门艺术,因为随时随地你都可能碰到需要权衡的地方!(每个程序员都希望当架构师,但是架构师并不是那么好当,因为架构师就像一个艺术家一样,需要做非常多恰当的权衡。如果任何人都能作出和你同等水平的决策,那你设计的这个决策便不值钱了。软件的艺术之美源于权衡(Trade-off))
企业开发基础设施--序
所谓企业开发基础设施,指的是为那些几乎所有的企业开发都会遇到的共同的基础性的问题提供服务的设施,比如事务、日志、权限等等。其中很多设施都会以AOP的方式实现,有些则可能以类库的方式提供。我也一直在积累这方面的AOP组件和类库。
曾经做过一些关于日志、权限管理的AOP实现,这几天正在研究“类厂服务”,于是就有了写这个“企业开发基础设施”系列文章的想法,把自己的一些思想拿出来和大家一起讨论,有些思想可能还不是很成熟,但是这终究是一件对自己有益的事情。如果这些文章能对后来者有点滴帮助,那就更值得一写了:)
就先从“类厂服务”开始吧。
(1)类厂服务设施
(2)事件通知服务
企业开发基础设施--类厂服务
在正式进入正题之前,为了方便后面的叙述,先要澄清一些概念,把上下文(Context)搭建起来,然后,我们再在这个上下文中进行讨论。
首先是两个基本定义:族和系列。(这两个概念是我自创的,不知道常用的术语是什么,知道的朋友请留言告诉我:))
(1)族 -- Category,就是指特定的一类物品。比如服装是一种Category,食物又是一种Category。
在程序设计和实现中,一个族对应着一个抽象工厂,而我们的当前系统可能会牵涉到多个族。
(2)系列 -- Style,指某个族中的某个风格。比如可以把服装的品牌当作Style,一个品牌对应一种Style。
为了更容易理解,看看IFactory的继承结构就清楚了:
/// IFactory 抽象工厂接口的基础接口。所有的抽象工厂接口均从此接口继承。
/// </summary>
public interface IFactory
{
/// <summary>
/// 族名称 ,在抽象工厂这一层就可以确定CategoryName了
/// </summary>
string CategoryName{ get ;} // 比如是"服装",还是"食物"
/// <summary>
/// 系列名、风格名,需要到具体工厂那一层才确定的了
/// </summary>
string StyleName{ get ;} // 比如耐克、李宁
}
// 抽象工厂IFoodFactory ,族已经确定
public interface IFoodFactory :IFactory
{
Apple GetApple() ;
Rice GetRice() ;
}
// 具体工厂ChineseFoodFactory ,风格(系列)已经确定
public interface ChineseFoodFactory : IFoodFactory
{
}
public interface JapaneseFoodFactory : IFoodFactory
{
}
其次,需要给出当前系统基本假设
(1)不会引入新的族(Category)。因为只要引入新的族,系统肯定需要进行大的修改。因为原系统对新Category一无所知。
(2)系统不会混用同一族中不同的风格。比如不会有一个人上面穿李宁的运动服,下面却穿耐克的鞋子:)
接下来,我们就能讨论类厂服务了。类场服务的目的主要有两个:
(1)如果系统原先使用Category A族中Style A系列的产品,当系统需要更换到Style B,应该通过修改配置做到(比如把具体工厂A改为具体工厂B),或者仅需要修改相关的几行代码。
(2)隐藏远程工厂与本地工厂的区别。也就是说,系统中不用关心所引用的工厂实例是本地的,还是remoting的。这个也可以通过更改配置来把原来使用本地对象配置为使用远程对象,而我们的系统根本不受影响。
为了获取具体的工厂实例,需要得到诸如该具体工厂类型名、位置等信息,这些信息通过FactoryInformation来封装。
/// FactoryInformation 通过反射创建对应的工厂时,需要这些相关信息
/// (1)当为非远程时,typeName为具体工厂类型名,如果为远程,typeName通常抽象工厂接口类型,如typeof(IFoodFactory)。
/// (2)assemblyName参数对现有族中添加一个新系列提供了支持,可以将新系列放在一个独立dll中,然后,修改配置,
/// 使系统从此使用新系列的对象。
/// </summary>
public class FactoryInformation
{
private string factoryID ; // 类厂唯一标识
private string typeName ; // 类厂的类型全名称
private string assemblyPath ; // 类厂所在配件
private string location ; // http://RemoteServer1/ClassFactory.rem
private bool isInCurrentAssembly = true ; // 是否在当前exe配件中
public FactoryInformation( string factory_ID , string type_Name , string assPath , string loc , bool isInCurAssem)
{
this .factoryID = factory_ID ;
this .typeName = type_Name ;
this .assemblyPath = assPath ;
this .location = loc ;
this .isInCurrentAssembly = isInCurAssem ;
}
#region property
#region IsRemoting
public bool IsRemoting // 是否为远程
{
get
{
if (( this .location == null ) || ( this .location.Trim() == "" ))
{
return false ;
}
return true ;
}
}
#endregion
#region IsInCurrentAssembly
public bool IsInCurrentAssembly // 是否在当前的配件中
{
get
{
return this .isInCurrentAssembly ;
}
}
#endregion
#endregion
}
上面的代码省略了一些省略简单属性。其余的已经完全可以通过注释来解释清楚了,需要指出每个工厂都有一个唯一标志factoryID,根据这个标志,我们可以要求类厂服务基础设施来为我们创建指定的工厂对象。
类厂服务是一个静态类,外貌如下:
{
public static void Initialize(IFactoryInfoGetter fiGetter) ;
public static IFactory GetFactory( string factoryID) ;
}
初始化需要有个IFactoryInfoGetter的参数,IFactoryInfoGetter用于获取指定工厂的FactoryInformation, 通常将所有的FactoryInformation存放于配置文件中。IFactoryInfoGetter接口定义如下:
{
FactoryInformation GetFactoryInformation( string factoryID) ;
}
{
if (ClassFactoryService.factoryInfoGetter == null )
{
return null ;
}
FactoryInformation factoryInfo = ClassFactoryService.factoryInfoGetter.GetFactoryInformation(factoryID) ;
if (factoryInfo == null )
{
return null ;
}
Type factoryType = null ;
// 远程
if (factoryInfo.IsRemoting)
{
factoryType = Type.GetType(factoryInfo.TypeName) ; // 此时factoryType通常为抽象工厂接口类型
return (IFactory)Activator.GetObject(factoryType ,factoryInfo.Location) ;
}
// 本地,在当前配件中
if (factoryInfo.IsInCurrentAssembly)
{
factoryType = Type.GetType(factoryInfo.TypeName) ;
return (IFactory)Activator.GetObject(factoryType , null ) ;
}
// 本地,不在当前配件中,但目标配件已被加载
factoryType = Type.GetType(factoryInfo.TypeName) ;
if (factoryType != null )
{
return (IFactory)Activator.GetObject(factoryType , null ) ;
}
// 本地,不在当前配件中,而且未加载目标配件
Assembly destAssembly = Assembly.LoadFrom(factoryInfo.AssemblyPath) ;
if (destAssembly == null )
{
return null ;
}
factoryType = destAssembly.GetType(factoryInfo.TypeName) ;
return (IFactory)Activator.GetObject(factoryType ,factoryInfo.Location) ;
}
注释已经很好的说明了发生的一切,其中最主要的就是使用了简单的反射技术和Remoting技术。到这里,我们的任务已经完成了,但是有些注意事项需要提出来:
(1)当在远程服务器上发布工厂类时,客户端可以通过下面三种方式得到其类型信息:
a. 把远程对象的接口程序集部署到客户端,即客户端可以得到其对应的抽象工厂接口信息。
b. 把实际的工厂类部署到客户端。
c. 在客户端部署一组"空类" ,这组类实现了抽象工厂接口,并且从MarshalByRefObject继承。可以通过SoapSuds.exe完成。(推荐)
(2)如果类工厂配置为remoting,那么该类工厂产生的所有物品都必须实现MarshalByRefObject。
关于类厂服务,我自己已经实现的就这么多,还有很多思路没有实现出来,等那些新想法成型后再拿出来和大家讨论。
企业开发基础设施--事件通知服务(Remoting双向通信)
本文采用的解决方案中,有两个重要组件:事件服务器EventServer和事件客户端EventClient。EventServer作为中介者,并作为一个独立的系统,通常可以将其作为windows服务运行。EventServer和EventClient之间的关系如下所示:
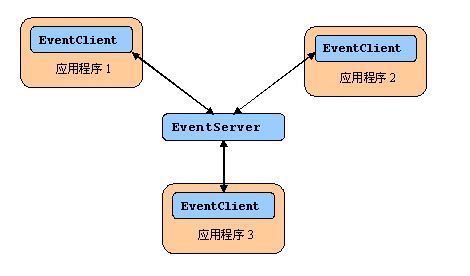
每个需要事件通知的应用程序中,都包含了EventClient组件,应用程序通过EventClient与事件服务器进行交互,而当有事件发生时,EventClient也会触发相应的事件来通知应用程序。
EventServer和EventClient实现了共同的接口IEventNotification:
{
void SubscribeEvent( string eventName ,EventProcessHandler handler) ; // 预定事件
void UnSubscribeEvent( string eventName ,EventProcessHandler handler) ; // 取消预定
void RaiseEvent( string eventName , object eventContent) ; // 发布事件
}
public delegate void EventProcessHandler( string eventName , object eventContent) ;
EventClient与包含它的应用程序之间的交互通过本地事件预定/发布来完成,而与EventServer之间的交互则通过remoting完成。其实现如下:
{
private IEventNotification eventServer = null ;
private Hashtable htableSubscribed = new Hashtable() ; // eventName -- Delegate(是一个链表)
public EventClient( string eventServerUri)
{
TcpChannel theChannel = new TcpChannel( 0 ) ;
ChannelServices.RegisterChannel(theChannel) ;
this .eventServer = (IEventNotification)Activator.GetObject( typeof (IEventNotification) ,eventServerUri);
}
public override object InitializeLifetimeService()
{
//Remoting对象 无限生存期
return null;
}
#region IEventNotification 成员
// handler是本地委托
public void SubscribeEvent( string eventName, EventProcessHandler handler)
{
lock ( this )
{
Delegate handlerList = (Delegate) this .htableSubscribed[eventName] ;
if (handlerList == null )
{
this .htableSubscribed.Add(eventName ,handler) ;
this .eventServer.SubscribeEvent(eventName , new EventProcessHandler( this .OnRemoteEventHappen)) ;
return ;
}
handlerList = Delegate.Combine(handlerList ,handler) ;
this .htableSubscribed[eventName] = handlerList ;
}
}
public void UnSubscribeEvent( string eventName, EventProcessHandler handler)
{
lock ( this )
{
Delegate handlerList = (Delegate) this .htableSubscribed[eventName] ;
if (handlerList != null )
{
handlerList = Delegate.Remove(handlerList ,handler) ;
this .htableSubscribed[eventName] = handlerList ;
}
}
}
public void RaiseEvent( string eventName, object eventContent)
{
this .eventServer.RaiseEvent(eventName ,eventContent) ;
}
#endregion
#region OnRemoteEventHappen
/// <summary>
/// 当EventServer上有事件触发时,EventServer会转换为客户端,而EventClient变成远程对象,
/// 该方法会被远程调用。所以必须为public
/// </summary>
public void OnRemoteEventHappen( string eventName, object eventContent)
{
lock ( this )
{
Delegate handlerList = (Delegate) this .htableSubscribed[eventName] ;
if (handlerList == null )
{
return ;
}
object [] args = {eventName ,eventContent} ;
foreach (Delegate dg in handlerList.GetInvocationList())
{
try
{
dg.DynamicInvoke(args) ;
}
catch (Exception ee)
{
ee = ee ;
}
}
}
}
#endregion
}
需要注意的是,EventClient从MarshalByRefObject继承,这是因为,当EventServer上有事件被触发时,也会通过Remoting Event来通知EventClient,这个时候,EventClient就是一个remoting object。另外,OnRemoteEventHappen方法必须为public,因为这个方法将会被EventServer远程调用。
下面给出EventServer的实现:
{
// htableSubscribed内部每项的Delegate链表中每一个委托都是透明代理
private Hashtable htableSubscribed = new Hashtable() ; // eventName -- Delegate(是一个链表)
public EventServer()
{
}
public override object InitializeLifetimeService()
{
//Remoting对象 无限生存期
return null;
}
#region IEventNotification 成员
// handler是一个透明代理,指向EventClient.OnRemoteEventHappen委托
public void SubscribeEvent( string eventName, EventProcessHandler handler)
{
lock ( this )
{
Delegate handlerList = (Delegate) this .htableSubscribed[eventName] ;
if (handlerList == null )
{
this .htableSubscribed.Add(eventName ,handler) ;
return ;
}
handlerList = Delegate.Combine(handlerList ,handler) ;
this .htableSubscribed[eventName] = handlerList ;
}
}
public void UnSubscribeEvent( string eventName, EventProcessHandler handler)
{
lock ( this )
{
Delegate handlerList = (Delegate) this .htableSubscribed[eventName] ;
if (handlerList != null )
{
handlerList = Delegate.Remove(handlerList ,handler) ;
this .htableSubscribed[eventName] = handlerList ;
}
}
}
public void RaiseEvent( string eventName, object eventContent)
{
lock ( this )
{
Delegate handlerList = (Delegate) this .htableSubscribed[eventName] ;
if (handlerList == null )
{
return ;
}
object [] args = {eventName ,eventContent} ;
IEnumerator enumerator = handlerList.GetInvocationList().GetEnumerator() ;
while (enumerator.MoveNext())
{
Delegate handler = (Delegate)enumerator.Current ;
try
{
handler.DynamicInvoke(args) ;
}
catch (Exception ee) // 也可重试
{
ee = ee ;
handlerList = Delegate.Remove(handlerList ,handler) ;
this .htableSubscribed[eventName] = handlerList ;
}
}
}
}
#endregion
}
EventServer的实现是很容易理解的,需要注意的是RaiseEvent方法,该方法在while循环中对每个循环加入了try...catch,这是为了保证,当一个应用程序无法接收通知或接收通知失败时不会影响到其它的服务器。
关于事件通知服务,可以总结为以下几点:
(1)事件通知服务采用了中介者模式,所有的EventClient只与EventServer(中介者)交互,从EventServer处预定名为eventName的事件,或发布名为eventName的事件。
(2)各个客户应用程序是对等的,它们都可以预定事件和发布事件。
(3)EventServer不会自主地触发事件,它就像一个公共区(缓存预定者)或转发器(广播事件)。
(4)EventServer 将在事件服务器上作为远程对象发布
(5)客户应用程序将通过EventClient来预定事件、发布事件。
最后,需要提出的是关于事件服务器的配置,需要将remoting的权限级别设置为FULL,否则,就会出现事件句柄无法序列化的异常。在我的示例中,EventServer的配置文件如下:
< system .runtime.remoting >
< application >
< service >
< wellknown
mode ="Singleton"
type ="EnterpriseServerBase.XFramework.EventNotification.EventServer,EnterpriseServerBase"
objectUri ="SerInfoRemote" />
</ service >
< channels >
< channel ref ="tcp" port ="8888" >
< serverProviders >
< provider ref ="wsdl" />
< formatter ref ="soap" typeFilterLevel ="Full" />
< formatter ref ="binary" typeFilterLevel ="Full" />
</ serverProviders >
< clientProviders >
< formatter ref ="binary" />
</ clientProviders >
</ channel >
</ channels >
</ application >
</ system.runtime.remoting >
</ configuration >
请特别注意,标志为红色的两句。 并且,在服务端程序启动时,配置Remoting:
由于在服务端回调Client时,Client相对变成"Server",所以,Client也必须注册一个remoting通道。
< application >
< channels >
< channel ref ="tcp" port ="0" >
< clientProviders >
< formatter ref ="binary" />
</ clientProviders >
< serverProviders >
< formatter ref ="binary" typeFilterLevel ="Full" />
</ serverProviders >
</ channel >
</ channels >
</ application >
</ system.runtime.remoting >
并且,在客户端程序启动时,配置Remoting:
组件设计实战--组件之间的关系 (Event、依赖倒置、Bridge)
那么在设计组建之间的关系时到底该选择那种方式,则需要依据实际情况而定。假设,组件A是信息提供者,而组件B是信息消费者。可以有以下几种情况:
(1)A发布事件,B包含A的引用,然后B预定A的事件。(事件方式)
(2)B接口中提供接收信息的方法,A包含B的引用,在适当时候A调用B的接收信息的方法。(依赖倒置方式)
(3)A发布事件,B接口中提供接收信息的方法,通过Bridge将A、B联系起来。(Bridge方式)
下面举个实际的例子,在我们的应用中,有个功能服务管理器IServiceManager(信息提供者),功能服务可以在运行的时候变化,这个变化可以被IServiceManager检测到,而显示功能服务名称的IServiceDisplayer(信息消费者)也需要在功能服务变化的时候,将显示作必要的改变。如果按照“事件”方式,应该如下设计:
{
event CbServiceAdded ServiceAdded ;
}
public delegate void CbServiceAdded( string serviceName) ;
public interface IServiceDisplayer
{
IServiceManager ServiceManager ;
}
按照“依赖倒置”方式设计如下:
{
IServiceDisplayer ServiceDisplayer{ set ;}
}
public interface IServiceDisplayer
{
void AddService( string serviceName) ;
}
按照“Bridge”方式设计如下:
{
event CbServiceAdded ServiceAdded ;
}
public delegate void CbServiceAdded( string serviceName) ;
public interface IServiceDisplayer
{
void AddService( string serviceName) ;
}
public interface IServiceBridge
{
IServiceManager ServiceManager{ set ;}
IServiceDisplayer ServiceDisplayer{ set ;}
void Initialize();
}
public class ServiceBridge :IServiceBridge
{
private IServiceManager serviceManager = null ;
private IServiceDisplayer serviceDisplayer = null ;
#region IServiceBridge 成员
public void Initialize()
{
this .serviceManager.ServiceAdded += new CbServiceAdded(serviceManager_ServiceAdded);
}
public IServiceManager ServiceManager
{
set
{
this .serviceManager = value ;
}
}
public IServiceDisplayer ServiceDisplayer
{
set
{
this .serviceDisplayer = value ;
}
}
#endregion
private void serviceManager_ServiceAdded( string serviceName)
{
this .serviceDisplayer.AddService(serviceName) ;
}
}
三种方式都是可行的,但是在不同的应用情况下,不同的方式导致应用程序中组件之间不同的依赖复杂度,并对整个系统的结构的清晰度产生深刻的影响。那么,原则是什么?
(1)通常情况下,采用“事件”方式。
(2)如果使用“事件”方式时遇到这样的情况:IServiceDisplayer预定的IServiceManager的那部分事件的预定者只有IServiceDisplayer,而不会有其它组件预定这部分事件,则可以考虑将这些事件从IServiceManager中移除,转而采用“依赖倒置”方式。这样做的好处是,大大减少了IServiceManager需要发布的事件的数量。
(3)如果IServiceDisplayer所需的信息不仅仅来自IServiceManager,还来自许多其它组件,则采用第三种方式。
(4)要谨慎使用“依赖倒置”方式,特别是当IServiceManager不需要从IServiceDisplayer获取任何信息时,第二种方式会导致IServiceManager对IServiceManager的依赖,而这个依赖本来是不必要的。
(5)当一个(或多个)信息接受者需要从众多的信息发布者获取事件信息时,使用第三种方式是推荐的选择。
后续的文章会继续对这三种方式作深刻的剖析,当然这要等我的认识进一步深化之后。“依赖倒置”这个名字是我取的,不知道是否有更正式的名称,望告知:)
IoC与DI (转载)
(本文转自梦想风暴的blog)
一个朋友发了封mail问了几个问题,其中的一个是关于IoC和DI的:
Inversion of Control和Dependency Injection 是什么关系,我认为两个词代表的是同一个意思,只是两种不同的表示,对吗?
下面是我对这个问题的一些理解。
准确的说,IoC和DI并不相同,这一点从字面上就可以看出,否则,它们可以叫一个名字。^_^
理解IoC,我们需要知道Control是什么,它又是怎样被Inversion的。其实,IoC是用来说明“程序库”和“框架”区别的最好证据。在使用程序库的时候,控制权是掌握在我们手中的,我们编写的代码调用程序库的实现,完成相应的功能,想想我们使用JDK的情况。使用框架的时候,控制权则掌握在框架手中,我们的代码最终是由框架调用,一个常见的例子是Servlet,我们编写的Servlet代码是放在整个Servlet的框架中,由Web容器进行调用。这就是差异所在。我们更习惯于自己掌控一切,因此,对框架掌握控制权的这种情况,我们用“Inversion”来形容,这也是Martin Fowler在那篇给DI正名的文章中提到,所有框架都是IoC的原因。
Spring的核心容器是一个框架,所以,我们可以说它是IoC,但是就如前面所说,每个框架都有IoC,所以,仅仅用IoC是不足以说明一切的。Spring核心容器完成的是组件组装的过程,这是它和其它普通框架区别最为显著的地方。如果说用IoC描述这个框架,那么,这里所指的Control实际上是组件的组装过程。
站在Spring核心容器的层面上看,它完成组装过程是把组件所依赖的零部件给组件安装上去。站在单个组件层面上看,它所需要的零部件是由外部给它安装的,这个过程就像是把“Dependency”这管药水用注射器“Injection”到组件的身体中去,所以,我们称之为“Dependency Injection”。
完成组件组装的容器也不只是注入一种形式,还有一种常见的方式是“Dependency Lookup”,即每个组件自己去查找自己所需要的内容。至于到哪去找,也有不同的实现方式,有固定到某个地方(比如使用静态方法),有把查找点通过DI的方式注入进来等等。
Martin Fowler的文章已经很清楚的解释了IoC和DI这两个概念,我们只需要去细细品味。