机器学习之Boosting和AdaBoost
1 Boosting和AdaBoost介绍
1.1 集成学习
集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
- 集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
- 集成学习是一种思想,不是某一个算法
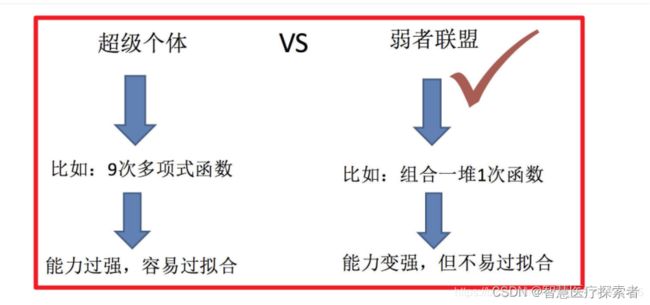
1.1.1 集成学习分类

集成算法大致可以分为:Bagging,Boosting 和Stacking等类型。
- bagging:并行,多个学习器互不相关 可以并行训练
- boosting:串行,后一个学习器依赖于前一个学习器
- stacking:多个学习器的输出作为后面一个学习器的输入
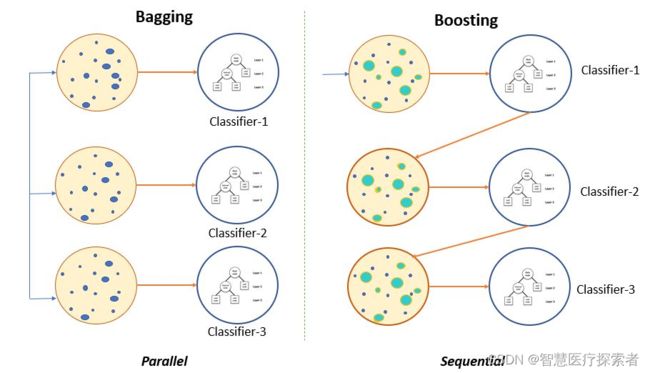
1.1.2 Boosting和Bagging
Boosting和Bagging都是流行的集成学习技术,用于通过多个基学习器的组合来提高机器学习模型的性能。虽然两种方法的目标都是减少过拟合并增加泛化能力,但它们具有不同的方法和特点。
(1)Boosting(提升)
提升是一种迭代的集成技术,在这种方法中,基学习器按顺序训练,每个后续模型都专注于纠正前面模型的错误。它给予训练集中被错误分类的实例更高的权重,迫使下一个模型专注于这些难以处理的情况。
- 基学习器: 通常,提升算法使用弱学习器,这些模型的性能仅比随机猜测略好。例如,使用深度有限的决策树(通常称为“树桩”)或简单的线性模型。
- 加权投票: 在预测时,根据每个基学习器的性能和在先前迭代中的重要性对其进行加权。在后续迭代中,被错误分类的实例得到更高的权重。
AdaBoost(自适应提升)和梯度提升机(GBM)是常见的提升算法。
(2)Bagging(装袋):
装袋是一种集成技术,它使用并行训练多个基学习器,每个学习器在随机选择的训练数据子集上独立训练,有放回地采样。最终的预测通过对所有基学习器的预测进行平均(回归问题)或投票(分类问题)得到。
- 基学习器: 装袋通常对每个模型使用相同的基础学习算法,每个模型在不同的数据子集上独立训练。
- 自助采样: 对于每个基学习器,使用有放回地随机抽样训练数据的子集。这意味着一些实例可能在子集中出现多次,而其他实例可能根本不出现。
随机森林是一种常见的装袋算法,它使用决策树作为基学习器。
(3)两种技术的不同点
基学习器的多样性:
- 提升:通常使用一系列弱学习器,每个模型纠正其前任的错误。这种顺序性为集成引入多样性。
- 装袋:通过对数据的随机采样,每个模型独立训练,获得集成的多样性。
加权投票与简单平均/投票:
- 提升:最终预测通过结合所有模型的预测,并根据其性能进行加权得到。更准确的模型在最终预测中具有更大的影响力。
- 装袋:所有模型对最终预测的贡献相等,因为它们只是被平均(回归问题)或投票(分类问题)。
对过拟合的鲁棒性:
- 提升:如果弱学习器过于复杂以至于记住训练数据,提升更容易过拟合。需要仔细调整参数、限制弱学习器的复杂性并进行早停止来防止过拟合。
- 装袋:装袋通过平均各个模型的偏差和错误有助于减少过拟合。通常能提供更稳定和可靠的预测结果。
性能:
- 提升:如果弱学习器选择得当且训练适当,通常比装袋获得更高的准确性。
- 装袋:虽然不一定与提升一样准确,但通常提供更一致和可靠的结果。
计算复杂度:
- 提升:由于模型是顺序训练且有加权实例,与装袋相比,计算上更昂贵。
- 装袋:模型可以并行训练,因此在处理大型数据集时更加高效。
提升和装袋都是有效的集成方法,选择哪种方法取决于具体问题、数据的性质以及准确性与计算资源之间的权衡。提升更专注于纠正错误,可能导致更高的准确性;而装袋更简单且计算效率更高,提供更稳定且不易过拟合的预测结果。
1.2 Boosting算法
boosting算法是一类将弱学习器提升为强学习器的集成学习算法,它通过改变训练样本的权值,学习多个分类器,并将这些分类器进行线性组合,提高泛化性能。
Boosting系列算法的工作机制类似,大致思路为:先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本的分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值或者组合学习器的精度达到100%,最终将这些基学习器进行线性组合,得到最终的学习器。
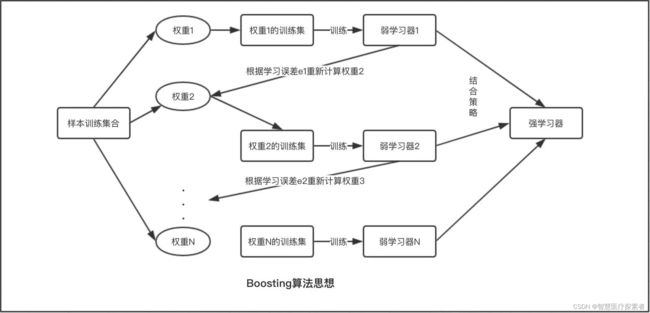
从Boosting的工作机制中我们可以发现,对于提升方法来说有两个关键问题需要解决:
- 在每轮的训练中如何改变训练数据的权值分布
- 如何将弱学习器结合成强学习器
1.3 Adaboost算法
Adaboost(adaptive boosting),又称为自适应提升算法,是最著名的Boosting算法。经典的Adaboost算法只能用于二分类问题,因此,我们在这里只讨论adaboost算法在二分类任务中的应用。其基本思想为:一开始,将训练数据的权重初始化为相等的值,训练出第一个弱分类器(这里的弱学习器一般是单层决策树,也就是决策树桩,它通过一个判断条件直接把数据一分为二),并且计算该分类器的错误率。从第二次训练开始,将会根据上一次训练所得的弱分类器的效果重新调整每个样本的权重,具体做法为降低上一次分对的样本的权重,提高上一次分错的样本的权重,然后训练出下一个弱分类器。如此循环,直到弱分类器数量达到一个给定值或者集成模型预测正确率达到100%,然后把这些弱分类器结合起来,结合策略为给分类误差率小的弱分类器分配较大的权重,给分类误差率大的弱分类器分配较小的权重,构成一个更强的最终分类器(强分类器)。
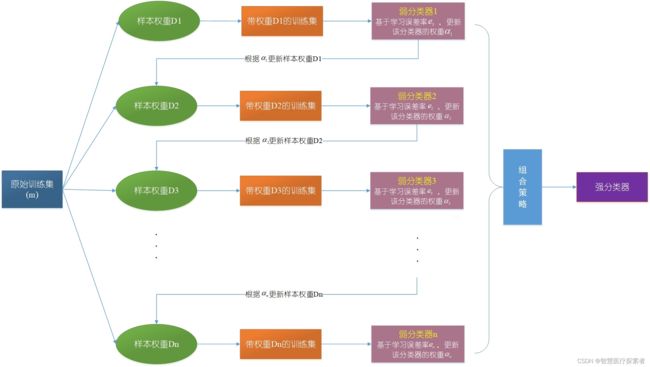
根据Adaboost算法的基本思想我们可以知道:
- Adaboost采用重赋值法来改变训练样本的权值分布,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被前一轮弱分类器正确分类样本的权值。这样一来,那些没有被正确分类的数据就会因为权值的加大而受到后一轮弱分类器的更大关注。于是,分类问题被一系列的弱分类器“分而治之”。
- Adaboost采取线性组合将弱学习器结合成强学习器,给分类误差率小的弱分类器一个较大的权重,使其在最后的表决中起较大的作用,给分类误差率大的弱分类器一个较小的权重,使其在表决中起较小的作用。
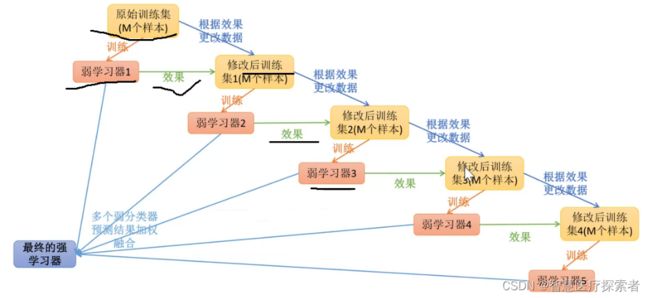
1.3.1 AdaBoost分类问题
以二分类为例,假设给定一个二类分类的训练数据集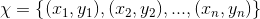 ,其中
,其中 表示样本点,
表示样本点, 表示样本对应的类别,其可取值为{-1,1}。AdaBoost算法利用如下的算法,从训练数据中串行的学习一系列的弱学习器,并将这些弱学习器线性组合为一个强学习器。AdaBoost算法描述如下:
表示样本对应的类别,其可取值为{-1,1}。AdaBoost算法利用如下的算法,从训练数据中串行的学习一系列的弱学习器,并将这些弱学习器线性组合为一个强学习器。AdaBoost算法描述如下:
输入:训练数据集
输出:最终的强分类器G(x)
(1)初始化训练数据的权重分布值:(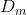 表示第m个弱学习器的样本点的权值),也就是说初始化的权重都是 (1/n)
表示第m个弱学习器的样本点的权值),也就是说初始化的权重都是 (1/n)
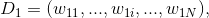
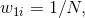

(2)对M个弱学习器,m=1,2,...,M:
a)使用具有权值分布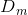 的训练数据集进行学习,得到基本分类器
的训练数据集进行学习,得到基本分类器 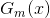 ,其输出值为{-1,1};
,其输出值为{-1,1};
b)计算弱分类器在训练数据集上的分类误差率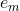 ,其值越小的基分类器在最终分类器中的作用越大
,其值越小的基分类器在最终分类器中的作用越大
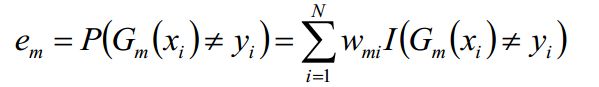
其中,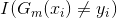 取值为0或1,取0表示分类正确,取1表示分类错误。其中就等于分类错误的权重*分类错误的个数
取值为0或1,取0表示分类正确,取1表示分类错误。其中就等于分类错误的权重*分类错误的个数
c)计算弱分类器的权重系数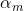 :(这里的对数是自然对数)
:(这里的对数是自然对数)
![]()
一般情况下 em 的取值应该小于0.5,因为若不进行学习随机分类的话,由于是二分类错误率等于0.5,当进行学习的时候,错误率应该略低于0.5。当 em 减小的时候 am 的值增大,而我们希望得到的是分类误差率越小的弱分类器的权值越大,对最终的预测产生的影响也就越大,所以将弱分类器的权值设为该方程式从直观上来说是合理地,具体的证明 am 为上式请继续往下读
d)更新训练数据集的样本权值分布:
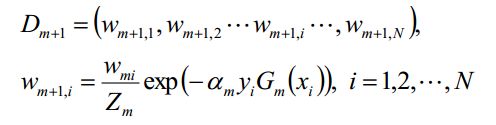
对于二分类,弱分类器的输出值取值为{-1,1},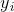 的取值为{-1,1},所以对于正确的分类
的取值为{-1,1},所以对于正确的分类 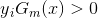 ,对于错误的分类
,对于错误的分类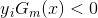 ,由于样本权重值在[0,1]之间,当分类正确时
,由于样本权重值在[0,1]之间,当分类正确时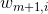 取值较小,而分类错误时取值较大,而我们希望得到的是权重值高的训练样本点在后面的弱学习器中会得到更多的重视。
取值较小,而分类错误时取值较大,而我们希望得到的是权重值高的训练样本点在后面的弱学习器中会得到更多的重视。
其中,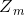 是规范化因子,主要作用是将
是规范化因子,主要作用是将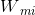 的值规范到0-1之间,使得
的值规范到0-1之间,使得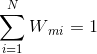 。
。
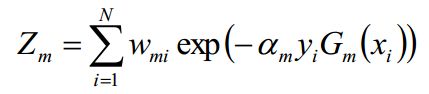
(3)上面我们介绍了弱学习器的权重系数α如何计算,样本的权重系数W如何更新,学习的误差率e如何计算,接下来是最后一个问题,各个弱学习器采用何种结合策略了,AdaBoost对于分类问题的结合策略是加权平均法。如下,利用加权平均法构建基本分类器的线性组合:
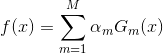
得到最终的分类器:
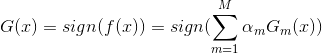
1.3.2 AdaBoost回归问题
AdaBoost回归问题有许多变种,这里我们以AdaBoost R2算法为准
(1)我们先看看回归问题的误差率问题,对于第m个弱学习器,计算他在训练集上的最大误差(也就是每次训练后,计算预测值和真实值的差的最大值):
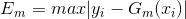
然后计算每个样本的相对误差:(计算相对误差的目的是将误差规范化到[0,1]之间)
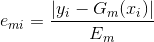 , 显然
, 显然 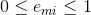
这里是误差损失为线性时的情况,如果我们用平方误差,则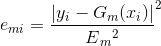 ,如果我们用指数误差,则
,如果我们用指数误差,则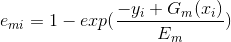
最终得到第k个弱学习器的误差率为: 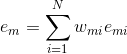 ,表示每个样本点的加权误差的总和即为该弱学习器的误差。
,表示每个样本点的加权误差的总和即为该弱学习器的误差。
(2)我们再来看看弱学习器的权重系数α,如下公式:
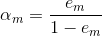
(3)对于如何更新回归问题的样本权重,第k+1个弱学习器的样本权重系数为:
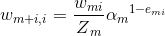
其中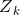 是规范化因子:
是规范化因子: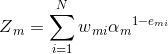
(4)最后是结合策略,和分类问题不同,回归问题的结合策略采用的是对加权弱学习器取中位数的方法,最终的强回归器为: 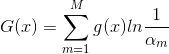 ,其中
,其中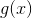 是所有
是所有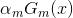 的中位数(m=1,2,...,M)。
的中位数(m=1,2,...,M)。
这就是AdaBoost回归问题的算法介绍,还有一个问题没有解决,就是在分类问题中我们的弱学习器的权重系数是如何通过计算严格的推导出来的。
1.3.3 AdaBoost前向分步算法
在上两节中,我们介绍了AdaBoost的分类与回归问题,但是在分类问题中还有一个没有解决的就是弱学习器的权重系数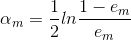 是如何通过公式推导出来的。这里主要用到的就是前向分步算法,接下来我们就介绍该算法。
是如何通过公式推导出来的。这里主要用到的就是前向分步算法,接下来我们就介绍该算法。
从另一个角度讲,AdaBoost算法是模型为加法模型,损失函数为指数函数,学习算法为前向分步算法时的分类问题。其中,加法模型表示我们的最终得到的强分类器是若干个弱分类器加权平均得到的,如下:
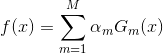
损失函数是指数函数,如下:
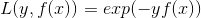
学习算法为前向分步算法,下面就来介绍AdaBoost是如何利用前向分布算法进行学习的:
(1)假设进过m-1轮迭代前向分布算法已经得到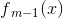 :
:
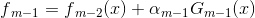
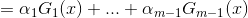
在第m轮的迭代得到,和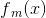 .
.
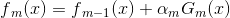
目标是使前向分布算法得到的和使在训练数据集T上的指数损失最小,即
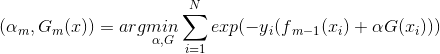
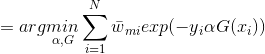
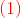
上式即为我们利用前向分步学习算法得到的损失函数。其中,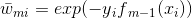 。因为
。因为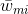 既不依赖
既不依赖 也不依赖于G,所以在第m轮迭代中与最小化无关。但依赖于,随着每一轮的迭代而发生变化。
也不依赖于G,所以在第m轮迭代中与最小化无关。但依赖于,随着每一轮的迭代而发生变化。
上式达到最小时所取的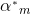 和
和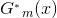 就是AdaBoost算法所得到的和。
就是AdaBoost算法所得到的和。
(2)首先求分类器:
我们知道,对于二分类的分类器G(x)的输出值为-1和1,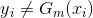 表示预测错误,
表示预测错误,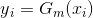 表示正确,每个样本点都有一个权重值,所以对于一个弱分类器的输出则为:
表示正确,每个样本点都有一个权重值,所以对于一个弱分类器的输出则为: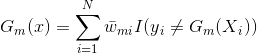 ,我们的目标是使损失最小化,所以我们的具有损失最小化的第m个弱分类器即为:
,我们的目标是使损失最小化,所以我们的具有损失最小化的第m个弱分类器即为:
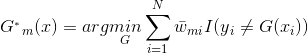 其中,
其中,
为什么用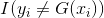 表示一个弱分类器的输出呢?因为我们的AdaBoost并没有限制弱学习器的种类,所以它的实际表达式要根据使用的弱学习器类型来定。
表示一个弱分类器的输出呢?因为我们的AdaBoost并没有限制弱学习器的种类,所以它的实际表达式要根据使用的弱学习器类型来定。
此分类器即为Adaboost算法的基本分类器,因为它是使第m轮加权训练数据分类误差率最小的基本分类器。
(3)然后就是来求,
将代入损失函数(1)式中,得:
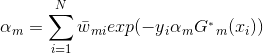
我们的目标是最小化上式,求出对应的。
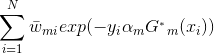
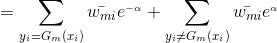
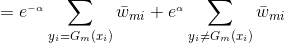
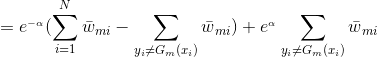
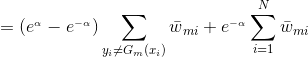
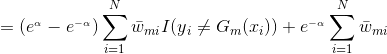
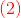
由于,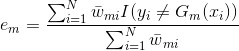
注意:这里我们的样本点权重系数并没有进行规范化,所以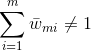
(2)式为: 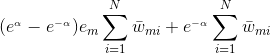
则我们的目标是求:
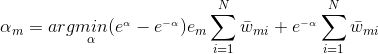
上式求偏导,并令偏导等于0,得:
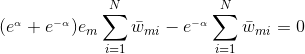 ,进而得到:
,进而得到:
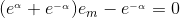 ,求得:
,求得: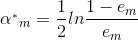 ,其中为误差率:
,其中为误差率:
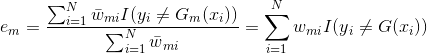
(4)最后看样本权重的更新。
利用前面所讲的,以及权值 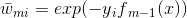
可以得到如下式子:
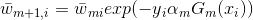
这样就得到了我们前面所讲的样本权重更新公式。
1.3.4 AdoBoost算法的正则化
为了防止过拟合,AdaBoost算法中也会加入正则化项,这个正则化项我们称之为步长也就是学习率。定义为v,对于前面的弱学习器的迭代有:
加入正则化项,就变成如下:
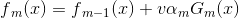
v的取值范围为(0,1]。对于同样的训练集学习效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用学习率和迭代最大次数一起来决定算法的拟合效果。
2 AdaBoost的优缺点
AdaBoost(自适应增强)是一种集成学习方法,它将弱学习器(通常是决策树)组合起来创建一个强分类器。它通过在每次迭代中给予被错误分类的数据点更大的权重来专注于难以分类的实例。AdaBoost具有一些优点和缺点:
2.1 AdaBoost的优点
-
提高准确性:与单个学习算法相比,AdaBoost通常能够实现更好的分类准确性。通过结合多个弱学习器,它可以有效处理复杂的分类问题。
-
多样性:它可以与各种学习算法一起使用作为弱学习器,因此在选择适合当前问题的基础模型时具有灵活性。
-
减少过拟合:AdaBoost减少了过拟合的风险,因为它更专注于错误分类的样本,使得算法在未见过的数据上具有更好的泛化能力。
-
不需要调整许多超参数:与某些其他复杂模型不同,AdaBoost通常只有较少的超参数需要调整,使得使用和实现更加简单。
-
有效处理不平衡数据集:即使在一个类别明显比其他类别更普遍的不平衡数据集上,AdaBoost的表现也很好。
2.2 AdaBoost的缺点
-
对噪声数据敏感:AdaBoost对噪声数据和异常值很敏感。噪声数据可能导致过拟合,从而降低模型的性能。
-
计算复杂度高:由于算法需要迭代训练多个弱学习器,因此可能计算上比较昂贵。
-
需要足够的训练数据:如果训练数据不足或者弱学习器无法优于随机猜测,AdaBoost的性能可能会下降。
-
可能导致过拟合:尽管AdaBoost在一定程度上减少了过拟合,但如果弱学习器过于复杂或者迭代次数(boosting轮数)过高,仍有可能过拟合。
-
对复杂模型的偏好:AdaBoost倾向于偏好复杂的弱学习器,这可能导致较长的训练时间,并且如果控制不当可能导致过拟合。
AdaBoost是一种强大的集成学习技术,通过组合多个弱学习器可以显著提高分类准确性。然而,它需要仔细处理噪声数据,调整boosting轮数,并选择合适的弱学习器才能达到最佳效果。
3 AdaBoost的应用场景
AdaBoost在许多领域和应用场景中都表现出色,特别是在处理分类问题时。以下是一些AdaBoost的常见应用场景:
-
图像识别和计算机视觉: AdaBoost可以用于图像分类、物体检测和人脸识别等计算机视觉任务,通过结合多个弱分类器来提高图像识别的准确性。
-
自然语言处理(NLP): 在文本分类、情感分析和垃圾邮件过滤等NLP任务中,AdaBoost可以用于提高文本分类的性能。
-
医学诊断: 在医学图像处理和诊断中,AdaBoost可用于辅助医生诊断,如肿瘤检测和疾病分类。
-
金融领域: AdaBoost可以应用于信用风险评估、欺诈检测和股票市场预测等金融领域的问题。
-
推荐系统: 在电子商务和在线推荐系统中,AdaBoost可以用于个性化推荐和用户行为预测。
-
语音识别: 在语音识别应用中,AdaBoost可以用于声纹识别和语音分类等任务。
-
生物信息学: 在分析生物数据、DNA序列分类和蛋白质结构预测等生物信息学问题中,AdaBoost可以发挥重要作用。
-
遥感图像分析: AdaBoost可用于遥感图像分类和地物识别,如土地利用分类和环境监测。
-
行为识别: 在行为分析和行为识别应用中,AdaBoost可以用于识别动作、行为和活动等。
虽然AdaBoost在许多场景中表现优秀,但并不是适用于所有问题。在实际应用中,需要根据具体问题的特点和数据集的特征选择合适的机器学习算法及参数调整方法。
4 AdaBoost代码实现
4.1 数据集介绍
乳腺癌数据集,是sklearn中经典的二分类数据集:
包含569个样本,每个样本30个特征,阳性样本357,阴性样本212
4.2 代码实现
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import numpy as np
from tqdm import tqdm
class CancerAdaboost:
def __init__(self, n_estimators):
self.n_estimators = n_estimators
self.clfs = [lambda x: 0 for i in range(self.n_estimators)]
self.alphas = [0 for i in range(self.n_estimators)]
self.weights = None
# 构造弱分类器的决策函数g(X)
def _G(self, fi, fv, direct):
assert direct in ["positive", "nagetive"]
def _g(X):
if direct == "positive":
predict = (X[:, fi] <= fv) * -1 # which <= value assign -1 else 0
else:
predict = (X[:, fi] > fv) * -1 # which > value assign 0 else -1
predict[predict == 0] = 1
return predict
return _g
# 选择最佳的划分点,即求出fi和fv
def _best_split(self, X, y, w):
best_err = 1e10
best_fi = None
best_fv = None
best_direct = None
for fi in range(X.shape[1]):
series = X[:, fi]
for fv in np.sort(series):
predict = np.zeros_like(series, dtype=np.int32)
# direct = postive
predict[series <= fv] = -1
predict[series > fv] = 1
err = np.sum((predict != y) * 1 * w)
# print("err = {} ,fi={},fv={},direct={}".format(err,fi,fv,"postive"))
if err < best_err:
best_err = err
best_fi = fi
best_fv = fv
best_direct = "positive"
# direct = nagetive
predict = predict * -1
err = np.sum((predict != y) * 1 * w)
if err < best_err:
best_err = err
best_fi = fi
best_fv = fv
best_direct = "nagetive"
# print("err = {} ,fi={},fv={},direct={}".format(err,fi,fv,"nagetive"))
return best_err, best_fi, best_fv, best_direct
def fit(self, X_train, y_train):
self.weights = np.ones_like(y_train) / len(y_train)
for i in tqdm(range(self.n_estimators)):
err, fi, fv, direct = self._best_split(X_train, y_train, self.weights)
# 计算G(x)的系数alpha
alpha = 0.5 * np.log((1 - err) / err) if err != 0 else 1
# print("alpha:",alpha)
self.alphas[i] = alpha
# 求出G
g = self._G(fi, fv, direct)
self.clfs[i] = g
if err == 0: break
# 更新weights
self.weights = self.weights * np.exp(-1 * alpha * y_train * g(X_train))
self.weights = self.weights / np.sum(self.weights)
def predict(self, X_test):
y_p = np.array([self.alphas[i] * self.clfs[i](X_test) for i in range(self.n_estimators)])
y_p = np.sum(y_p, axis=0)
y_predict = np.zeros_like(y_p, dtype=np.int32)
y_predict[y_p >= 0] = 1
y_predict[y_p < 0] = -1
return y_predict
def score(self, X_test, y_test):
y_predict = self.predict(X_test)
return np.sum(y_predict == y_test) / len(y_predict)
if __name__ == "__main__":
breast_cancer = load_breast_cancer()
X = breast_cancer.data
y = breast_cancer.target
y[y == 0] = -1
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y)
print(X_train.shape, X_test.shape)
clf = CancerAdaboost(200)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))4.3 结果展示
(1)n_estimators=50,分类结果达到了93%的准确率
0%| | 0/50 [00:00(2)n_estimators=100,分类结果达到了94%的准确率
0%| | 0/100 [00:00(3)n_estimators=200时,分类结果达到了97%的准确率
(426, 30) (143, 30)
100%|██████████| 200/200 [02:09<00:00, 1.54it/s]
0.972027972027972n_estimators数量越大,需要的计算时间也越长,准确率也越高