【学习笔记】目标跟踪领域SOTA方法比较
目录
-
- 前言
- 方法
-
- 1 TraDeS:
- 2 FairMOT:
- 3 SMILEtrack:
- 4 ByteTrack:
前言
常用于行人跟踪的多目标跟踪数据集包括:MOT 15/16/17/20、PersonPath22等…
为更好比较现有SOTA算法的检测性能,本博客将针对在各数据集上表现较优的算法模型进行介绍。(表中画粗数据表明对应算法为该数据集表现最优算法)
| 数据集 | 算法模型 | MOTA | 年份 | 代码 |
|---|---|---|---|---|
| MOT15 | TraDeS | 66.5 | 2021 | https://github.com/JialianW/TraDeS |
| MOT16 | FairMOT | 74.9 | 2022 | https://github.com/ifzhang/FairMOT |
| MOT17 | SMILEtrack | 81.06 | 2022 | https://github.com/WWangYuHsiang/SMILEtrack |
| MOT20 | SMILEtrack | 78.2 | 2022 | https://github.com/WWangYuHsiang/SMILEtrack |
| PersonPath22 | ByteTrack | 75.4 | 2021 | https://github.com/ifzhang/ByteTrack |
注:MOTA(Multiple Object Tracking Accuracy)即多目标跟踪精度,用于衡量跟踪器在检测物体和保持轨迹时的性能
方法
1 TraDeS:
原文
模型结构:
采用JDT(Joint Detection and Tracking)范式,(目标检测 + 数据关联)
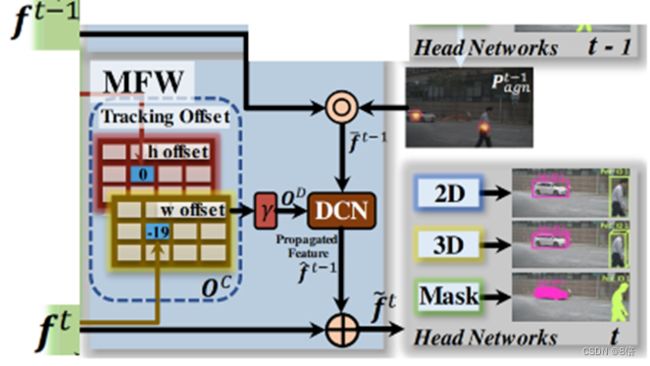
追踪器的整体结构,主要由三部分组成,分别是CenterNet、CVA、MFW
CenterNet:backbone(Φ) + 检测head
CVA:基于代价度量C的关联模块
MFW:基于运动指导的特征整理模块
算法流程:
1、连续两帧输入图像(t、t-1时刻)送入共享权值的CenterNet的Backbone进行基础特征提取(f(t)、f(t-1)),并输入CVA
2、CVA计算两帧图像中目标的偏移,构建运动跟踪信息,进行数据关联。
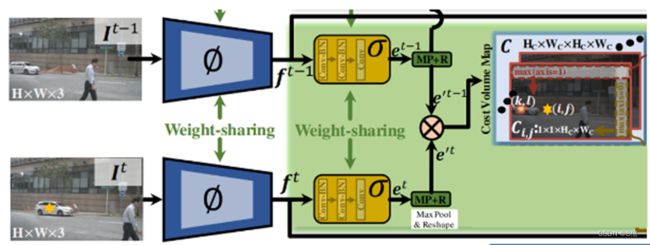
3、MFW使用运动偏移线索将前一帧信息传播到当前帧,辅助当前帧检测。

4、增强特征送入CenterNet的head进行目标检测,再和之前的轨迹进行关联,实现追踪。
1.3 算法性能:

1.4 算法总结:
1、提出了一种新型的基于JDT模式的在线联合检测与跟踪模型。
2、通过将上一帧跟踪的信息反哺给本帧检测,有效提升了算法在遮挡、光线阴暗、运动模糊等条件下对目标的检测能力,为算法实现准确跟踪奠定了基础。
3、TraDeS模型能够快速、高效地实现追踪,同时可以从2维拓展到3维和实例分割追踪上。
2 FairMOT:
原文
2.1 模型结构:
基于JDE(Joint Detection and Embedding)范式,由两个齐次的同质分支组成,分别用于检测对象和提取重识别特征
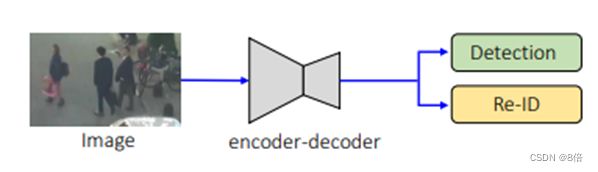
追踪器的整体结构,主要由三部分组成,分别是主干网络、CenterNet、re-ID分支
主干网络:ResNet-34 + 深度层聚合(DLA+),实现基础特征提取
CenterNet:检测head,定位图像中目标,生成目标度分数
re-ID分支:生成能够区分对象的特性。
2.2 算法流程:
1、单帧图像送入主干网络得到基础特征
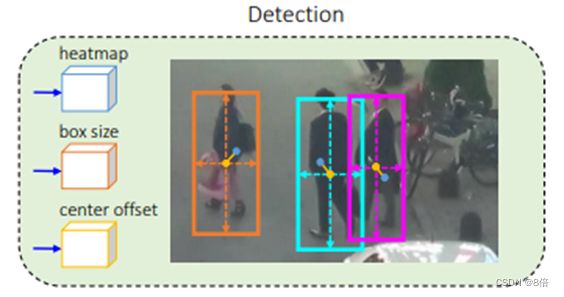
2、特征进入CenterNet检测head,对输出热图根据热图分数执行NMS,以提取峰值关键点并保留热图分数大于阈值的关键点的位置。
3、对保留关键点计算估计中心偏移量与估计检测框尺寸,得到目标预测框。

4、re-ID分支通过128维卷积对特征进行处理,得到ReID特征。
5、在追踪阶段,首先利用卡尔曼滤波估计轨迹位置并计算马氏距离。将结果与根据re-ID特征计算的余弦距离融合后利用匈牙利算法进行匹配。
6、对匹配失败目标进一步使用BOX_IOU进行二次匹配,再次失败目标初始化为新轨迹。
7、更新并保存轨迹
注:初始轨迹根据第一帧信息计算得出
2.3 算法性能:

2.4 算法总结:
1、使用齐次分支结构,解决了目标检测和Re-ID存在的“不公平”关系。
2、证明了基于锚框的检测网络对后续有效学习重识别特征具有局限性。
3、证明了re-ID为有效区分同一类的不同实例,应更多地关注低级外观特征。
4、推理速度快,能够实现视频速率推断。
3 SMILEtrack:
原文

3.1 模型结构:
SMILEtrack采用TBD(Tracking By Detection)范式+SDE(Separate Detection and Embedding)范式,(目标检测)+(目标关联)
追踪器的整体结构,主要由三部分组成,分别是YOLOX、SLM(ISA)、SMC
YOLOX:图像中目标定位检测模块
SLM:目标相似度计算
ISA (Image Slicing Attention Block):图像切片注意力模块
SMC(Similarity Matching Cascade):对检测到的目标基于进行数据关联
3.2 算法流程:
1、连续两帧检测图像送入YOLOX,检测并裁剪得到图像中具体目标。
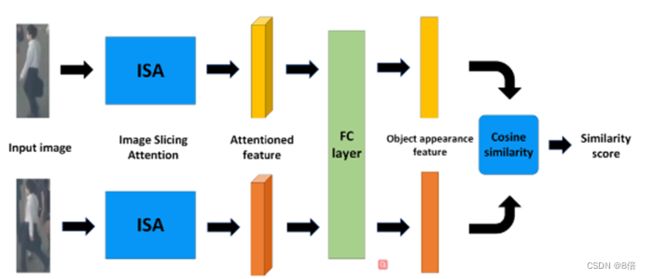
2、两帧图像中目标进入SLM模块,通过其内部共享权重的ISA及全连接聚合后,得到目标外貌特征,并计算其对应余弦相似度得分。
3、对待跟踪目标(t-1)预测本帧运动轨迹(卡尔曼滤波)。
4、SMC模块按照检测框检测分数高低,通过计算目标运动相似度加粗样式矩阵、外貌相似度矩阵依次进行匹配实现跟踪。
5、对于检测分数大于阈值却匹配失败的目标,将其作为新的跟踪对象。
3.3 算法性能:

3.4 算法总结:
1、使用外貌加运动相似度相结合的机制,对目标关联部分提出了改进,有效提升了算法跟踪精度,在MOT17上达到了SOTA。
2、由于基于TBD范式,无法实现端到端检测。
3、运行速度比联合检测和嵌入( JDE )方法慢。
4 ByteTrack:
原文

4.1 模型结构:
基于TBD范式。目标检测 + 数据关联
4.2 算法流程:
1、连续两帧图像输入YOLOX,对图像中存在的目标进行检测。
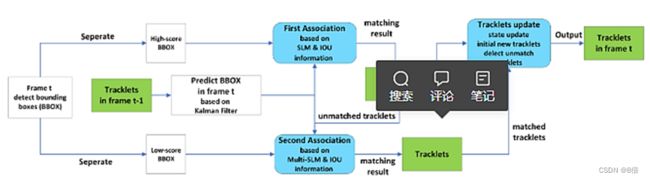
2、按照得分将预测框分为高分结果与低分结果两类,分开处理。进行三级匹配关联。
BYTE 数据关联方法具体的流程:
(1)使用高分框和之前的跟踪轨迹进行匹配
(2)使用低分框和第一次匹配失败跟踪轨迹进行匹配
(3)对于没有匹配上跟踪轨迹,得分又足够高的检测框,对其新建一个跟踪轨迹。对于没有匹配上检测框的跟踪轨迹保留30帧,以便后续再进行匹配。
注:匹配过程仍沿用SORT方法,使用卡尔曼滤波预测出当前帧的运动轨迹,并计算预测框和实际框间的 IOU相似度得分,通过匈牙利算法完成匹配跟踪。
4.3 算法效果:
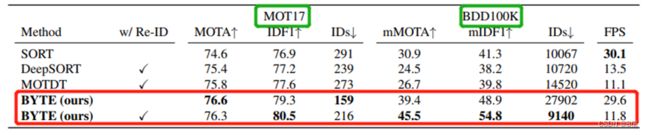
4.4 算法总结:
1、提出了一种简单高效的数据关联方法 BYTE,利用低分检测框包含的目标特性,大幅提升了算法跟踪性能。
2、由于ByteTrack 仅采用运动特征,没有采用外表特征进行匹配,故跟踪的效果十分依赖于检测效果。
3、BYTE算法可与任何目标检测算法连接使用,相比JDE和FairMOT,在工程应用上更为简洁。
4、在MOT17上,MOTA为76.6,检测速度能够达到30FPS,能够有效降低漏检并提高轨迹的连贯性。
------tbc-------
有用请点个哦~~