Dynamic-SLAM2019论文翻译
Dynamic-SLAM:动态环境下基于深度学习的语义单目视觉定位与建图
摘要-传统SLAM框架在动态环境下工作时,由于受到动态对象的干扰,性能较差。为了解决动态环境下的SLAM问题,利用深度学习在目标检测中的优势,提出了一种语义同步定位与建图框架dynamic -SLAM。首先,在卷积神经网络的基础上,构建了一种结合先验知识的SSD对象检测器,在语义层面对新检测线程中的动态对象进行检测;然后,针对现有SSD目标检测网络召回率低的问题,提出了一种基于相邻帧速度不变性的缺失检测补偿算法,大大提高了检测的召回率。最后,构建了基于特征的视觉SLAM系统,该系统通过跟踪线程中的选择性跟踪算法对动态目标的特征点进行处理,显著降低了由于不正确匹配导致的位姿估计误差。与原SSD网络相比,系统召回率由82.3%提高到99.8%。实验结果表明,动态slam的定位精度高于现有系统。该系统利用移动机器人在真实动态环境中成功定位并构建了精确的环境地图。总之,我们的实验证明,与动态环境下最先进的SLAM系统相比,动态SLAM系统在机器人定位和映射方面具有更高的准确性和鲁棒性。
特点
- 构造了一个SSD对象检测器,用于在新检测线程中检测具有先验知识的动态对象
- 提出了基于相邻帧速度不变性的漏检补偿算法
- 为了消除动态目标,提高系统的鲁棒性和精度,提出了选择跟踪算法
- 为实现机器人定位与制图中动态环境的检测,构建了基于特征的结合语义信息的动态slam系统
1.引言
同步定位与地图绘制(Simultaneous Localization and Mapping, SLAM)[1]经过近三十年的发展,已经成为机器人、自动化和计算机视觉领域的一项关键技术。在不同的传感器模式中,相机更便宜,并提供丰富的视觉和环境信息,这在未来有巨大的增长空间。当前 微型飞行器(Micro Aerial Vehicle, MAV)、无人地面飞行器(Unmanned Ground Vehicle, UGV)、自动驾驶、虚拟现实(Virtual Reality, VR)、增强现实(Augmented Reality, AR)等应用都需要SLAM技术提供可靠的定位和制图结果。然而,在视觉SLAM中,特别是在动态环境下(visual SLAMIDE),姿态估计的鲁棒性和准确性仍然存在许多关键的挑战。
为了使视觉SLAM系统在动态环境下正常工作,通常的方法是避免使用动态对象上的特征点。因此,有必要提前计算动态物体的位置。同时,基于深度学习的目标检测和语义分割在这方面也取得了显著的成果。在动态环境下将深度学习技术应用于SLAM是解决该问题的关键。

在本研究中,基于ORB-SLAM2[2]构建的dynamic -SLAM是动态环境下基于深度学习的语义单目视觉SLAM系统。动态slam主要包括一个视觉测程前端,该前端包括两个线程和一个模块,即跟踪线程、目标检测线程和语义校正模块;SLAM后端,主要包括本地建图线程和闭环线程。该框架如图1所示,将在第3节中详细介绍。动态slam可以在复杂的室内和室外动态环境中成功地实时运行。它解决了行人和车辆存在时的定位、BA、闭环、稀疏重建等问题。它可以满足正常真实环境下的定位和建图分配。本文的主要贡献如下:
- 针对现有SSD目标检测网络召回率低的问题,针对SLAM系统提出了一种基于相邻帧速度不变性的漏检补偿算法,大大提高了检测召回率,为后续模块的工作提供了良好的基础。
- 提出了一种简单有效地消除动态目标的选择跟踪算法,提高了系统的鲁棒性和准确性。
- 构建了一个基于特征的可视化动态slam系统。在SSD卷积神经网络的基础上,将深度学习技术构建为一个新的目标检测线程,结合先验知识实现机器人定位与测绘中语义层面的动态目标检测。
2.相关工作
2.1 视觉slam
近十年来,Visual SLAM取得了飞速的发展。由于其成本低、体积小等优点,引起了研究人员的广泛关注。Davison等人是视觉SLAM的先驱。2007年,他首次提出Mono-SLAM[3],实现单目实时SLAM系统。随后,Klein等人提出了PTAM [4] (Parallel Tracking and Mapping),创造性地将整个系统划分为两个线程:跟踪和绘图,成为后续SLAM研究人员的基准。2014年,Engel等[5]提出的LSD-SLAM明确了像素梯度与直接法之间的关系。同时,Forster等[6,7]提出了一种结合特征点和直接跟踪光流法的快速半直接单目视觉测速(Semi-direct monocular Visual Odometry, SVO)方法。后来,DSO[8]、VINS-Mono[9]等框架也采用了直接法。该方法在跟踪和匹配方面节省了计算资源,但对特征的不敏感是其在SLAM中进一步应用的致命弱点。
为了构建一个完整且健壮的SLAM框架,使用特征点是必不可少的。一方面,特征提取和匹配可以保证SLAM跟踪中姿态估计的准确性;另一方面,特征方法可以从视觉图像中提取更有效的信息,如语义、物体识别、特征定位等。实际上,Leutenegger提出的OKVIS[10]视觉惯性测程框架、mr - artal等人提出的ORB-SLAM[11]和ORB-SLAM2[2]都是基于特征跟踪的SLAM的成功应用。
ORB-SLAM2框架是经典SLAM线程模型的继承者。为了完成SLAM系统,它使用ORB[12]特征点和三个主要的并行线程:跟踪线程用于实时跟踪特征点,局部建图线程用于构建局部束调整(Bundle adjustment, BA)图,闭环线程用于校正累积漂移并形成姿态图优化。它可以使系统在大场景、大循环下长时间运行,从而保证轨迹和地图的全局一致性。ORB-SLAM2是性能最好的定位和建图框架之一。但是,在处理动态环境问题方面还存在许多不足,值得进一步探索。
2.2 SSD目标检测网络
目前,基于卷积神经网络的目标检测和语义分割方法在速度和精度上都取得了不断的突破。深度学习在相关任务上的表现已经逐渐超越其他方法,成为主流。
与图像识别相比,对象检测更加困难,因为它不仅需要对图片中的不同对象进行分类,而且还需要给出每个观察的位置。由R-CNN [13]领导的神经网络方法,例如spp-net [14],快速R-CNN [15],更快的R-CNN [16]等,使用卷积神经网络自动学习功能和避免手动设计功能的限制。它们通过候选帧提取、特征提取和分类等操作获得目标检测结果。虽然这些方法具有较高的精度,但由于候选帧提取和目标识别分两步进行,因此非常耗时。相比之下,YOLO (You Only Look Once)[17]算法省略了生成候选区域的中间步骤,直接通过单个卷积神经网络处理每个边界框的回归问题,并预测相应类别的概率,从而达到了较快的速度并保持了较好的准确率。Liu等[18]提出的SSD (Single Shot MultiBox Detector),利用Faster-RCNN中的锚盒来适应不同形状的物体。它是Dynamic-SLAM中的特征点识别器,它使用VGG16的基本网络结构,前五层保持不变,而fc6和fc7层使用
2.3 SLAMIDE问题和深度学习
早在2003年[20],就有一些关于SLAM in Dynamic Environments (SLAMIDE)问题的研究。传统的动态环境下SLAM方法可分为两类:一类是动态目标的检测与跟踪[20];另一个是动态目标的检测和滤波[21]。前者可以概括为移动物体检测和跟踪(DATMO)[22]方法。一些研究人员[23]认为,在获得一组合理的检测特征集后,处理slam问题至少有四种相关的数据关联技术,包括GNN[24]、JPDA[25]、MHT[26]和RANSAC[27]。Charles等人[28]提出了一种将最小二乘与滑动窗口优化和广义期望最大化相结合的框架。Chen等[29]提出了一种仅依赖地标而不依赖先验信息的动态环境系统SLAM。Walcott-Bryant等人[30]提出了动态环境下的动态姿态图(Dynamic Pose Graph, DPG)模型。2018年,Bahraini等人[31]提出了一种利用MultiLevel-RANSAC对多个运动目标进行分割和跟踪的方法。一般来说,大多数视觉研究者仍然关注如何利用特征检测方法从相邻帧中提取动态目标。特征检测方法的一个潜在缺点是,当动态对象移动太慢或太快时,它将失败。Muhamad等[32]对动态环境下的视觉SLAM和Structure from Motion (SfM)问题进行了研究。根据分类,动态SLAM是一种鲁棒的视觉SLAM。
SLAMIDE一直是SLAM领域中一个难以克服的难题。究其原因,传统的SLAM理论完全建立在静态环境假设的基础上。它的挑战主要来自两个方面:一是难以从平面像素定义动态目标;二是动态目标不易被检测和跟踪。
由于深度学习在目标检测方面取得了良好的性能,许多研究者将深度学习与SLAMIDE问题相结合[32]。Zhang等[33]集成了深度CNN模型,提高了地形分割的精度,使其对野生环境的鲁棒性更强。一些类似的RGB-D SLAMIDE研究[34 37]已经通过将最先进的SLAM框架与深度学习网络相结合而发展起来,并取得了可观的成果。由于激光雷达SLAM和RGB-D SLAM传感器可以直接获取深度信息来估计动态物体的位置,因此大多数SLAM研究人员都集中在激光雷达SLAM和RGB-D SLAM上[38]。相比之下,在单目视觉系统中对SLAMIDE的研究非常有限。Barnes等人[39]提出了一种自监督方法来忽略单目摄像机图像中的干扰物,从而在城市动态环境中稳健地估计车辆运动。Bescos等人[40]采用了与我们相似的方法。他们将ORB-SLAM2与Mask RCNN相结合[41]实现动态环境下的单目和立体系统,并结合多视图几何模型和深度学习算法实现RGB-D系统。
3.系统概述和方法
本研究在ORB-SLAM2[2]的基础上构建了dynamic - slam,增加了包含语义的动态目标决策模块,并利用特征点对视觉里程计算法进行了优化。动态slam的鲁棒性是通过分割图像中的静态和动态特征,并将动态部分作为离群值来实现的。基于选择跟踪算法计算的静态特征点进行姿态估计和非线性优化,以避免动态环境目标的干扰。针对现有SSD目标检测网络召回率低的问题,提出了一种基于基本运动模型的漏检补偿算法,大大提高了目标检测模块的准确率。图2绘制了Dynamic-SLAM的简要框架。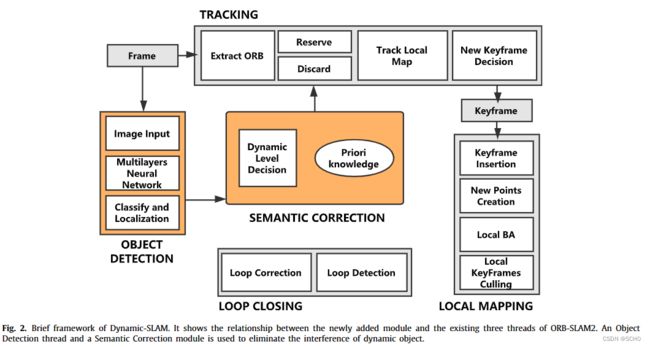
3.1漏检补偿算法
在实验过程中发现,神经网络对SLAM的检测精度还不够,还可以进一步提高。由于图像之间不存在显著的相关性,在常规的目标检测任务中,无法通过上下文信息来提高检测精度。但是在SLAM中,视频帧是以时间序列的形式到达的,可以利用前一帧的检测结果来预测下一帧的检测结果,从而避免下一关键帧的漏检或误检。在目标检测任务的准确性评估中,研究人员通常更关注两个方面:精确度和召回率。对于slamIDE问题中的动态目标检测任务,后者更为重要。在漏检或误检的情况下,相邻两幅图像之间的差异会导致特征点正确匹配的数量急剧变化,从而导致系统的不稳定。根据Davis等人[42]的工作,Recall rate和Miss rate可以定义为:
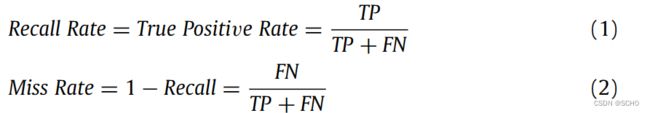
在SSD中,将 χ i j p = { 1 , 0 } \chi ^p_{ij} = \{1,0\} χijp={1,0}作为默认框 i i i与对象类别 p p p的ground truth框 j j j是否匹配的指示器。当漏检发生时, χ ^ i j p = { 1 , 0 } \widehat{\chi} ^p_{ij} = \{1,0\} χ ijp={1,0}等于0,预测框(l)和地面真值框(g)之间的平滑L1定位损失[15]会增加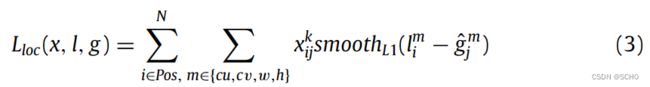
其中 D ( c u , c v , w , h ) D(cu,cv,w,h) D(cu,cv,w,h)给出了边界框(d)的中心点坐标 ( c u , c v ) (cu,cv) (cu,cv)及其宽度和高度。
提出了相邻帧的漏检补偿模型,该模型基于一个合理的假设:动态物体的运动速度在短时间内趋于恒定(即加速度趋于0)。像素平面中的动态对象速度用 v → \overrightarrow{v} v表示,其中 a m a x a_{max} amax也表示动态物体在像素平面上的速度变化率阈值。它们之间应满足以下关系:

运动速度用来描述动态物体在几帧之间的运动位移。在实际应用中,视频序列中相邻两帧的时间差很短,动态物体在运动位移中的变化量变化不大。该模型可用于确定是否发生漏检,并在漏检事件中提供补偿策略。前一帧与当前帧K在短时间内对应的边界框可以用 Δ v → \Delta \overrightarrow{v} Δv来确定。如果它大于 a m a x a_{max} amax,则认为是不匹配,即漏检。当前关键帧K进入SSD网络,输出检测到的对象列表。列表中的每一项为边界框的定位,即被检测物体的位置坐标 K D i {}^KD_i KDi( 0 < i < N K 0
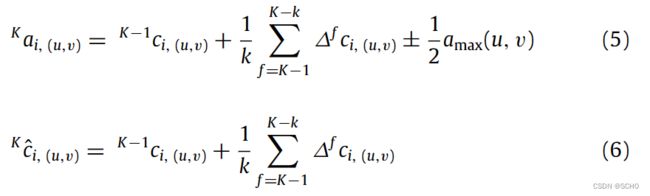
其中k是用于对当前帧进行漏检和补偿的前一帧的个数。算法处理如下
漏检补偿算法的效果如图3所示。它在动态目标的选择和跟踪中起着至关重要的作用。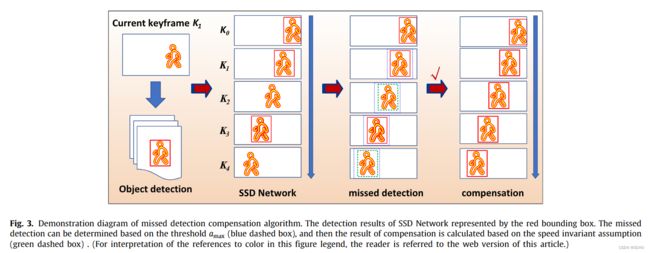
上式中k和 a m a x a_{max} amax的选择会影响漏检补偿的灵敏度。如果k过小,会导致灵敏度过高和误差补偿。通常在确定帧K之前选择3-5帧。同时,如果检测到连续两帧以上的对象缺失,则放弃补偿。这可能会引入少量的误差补偿,但可以显著减少漏检的发生。此外,当 a m a x a_{max} amax过小时,正确的检测结果可能被视为漏检。如果该值太大,系统将不敏感,其中多个动态目标检测区域可能重叠。
3.2基于先验知识的动态目标确定
环境对象的语义学是人们基于经验对环境的解释。在记忆陌生环境的过程中,人们会借助先验知识自动忽略车辆、行人等动态物体。如果SLAM系统不能从语义层面理解周围环境,就不能真正区分动态和静态环境。它只能在短时间内发现移动的物体,无法保证长期的一致性。因此,结合先验知识的目标检测结果可以在语义层面上执行动态目标决策模型。对于Dynamic-SLAM,前端SSD对象检测模块输出的信息是冗余的。它只需要知道检测到的特征点是静态的还是动态的。根据人类的先验知识,物体的动态特性可以从0分(静态)到10分(动态)进行评分。该分数应与预先定义的阈值进行比较。因此,对特征点进行了静态和动态的区分。在此区间内,常见目标的近似得分如图4所示。
实际上,这是一个最大化后验问题。当前一帧的边界框被检测为动态对象时,当前一帧的边界框也被判断为同一点并重新检测,然后进入漏检补偿回路。将 C = K c i : K = 1 , 2 , . . . , K , . . . , N \mathbb{C}={}^Kc_i:K=1,2,...,K,...,N C=Kci:K=1,2,...,K,...,N和 Z = K d i : K = 1 , 2 , . . . , K , . . . N \mathbb{Z}={}^Kd_i:K=1,2,...,K,...N Z=Kdi:K=1,2,...,K,...N作为边界框的实际情况和测量值,根据贝叶斯法则:
P ( C ∣ Z ) = P ( Z ∣ C ) P ( C ∣ ) P ( Z ) ∝ P ( Z ∣ C ) P ( C ∣ ) ( 7 ) P(\mathbb{C} \mid \mathbb{Z})=\frac{P(\mathbb{Z} \mid \mathbb{C}) \mathrm{P}(\mathbb{C} \mid)}{P(\mathbb{Z})} \propto P(\mathbb{Z} \mid \mathbb{C}) \mathrm{P}(\mathbb{C} \mid) \quad (7) P(C∣Z)=P(Z)P(Z∣C)P(C∣)∝P(Z∣C)P(C∣)(7)
然后
![]()
在动dynamic-slam框架中,帧k的确定结果会受到过去多帧的干扰。根据帧k-1展开条件概率:

基于先验知识的动态目标确定解决了神经网络获得的冗余语义信息,在特征点处理中更加实用。
3.3 目标检测模块和选择性跟踪
特征跟踪并不麻烦,但并不是所有的特征都可以用于跟踪,也不是所有动态对象的特征都不能用于跟踪。这里有两种特殊情况:1.一个对象被归类为动态对象,但它在场景中是静态的(例如,停车场中的汽车)。2. 动态对象占据了摄像机的大部分视场(例如,在一个非常拥挤的购物中心)。区分不同场景下的前景动态特征点和背景静态特征点至关重要。
Dynamic-SLAM的具体系统结构如图2所示。对象检测线程通过SSD对象检测网络计算对象的类别和位置。之后,通过语义校正模块将对象进一步划分为动态对象或静态对象,然后将动态对象的位置提供给跟踪线程。跟踪线程对每个关键帧图像进行ORB特征提取,然后将结果与参考帧进行匹配,得到两幅图像特征点之间的对应关系,用于估计相机姿态。
初始化完成后,姿态估计是PnP (Perspective-n-Point)问题。采用以Bundle Adjustment为代表的非线性优化方法[43]来解决该问题。该方法可以充分利用所有匹配结果,得到姿态的最优估计。非线性优化的代价函数定义如下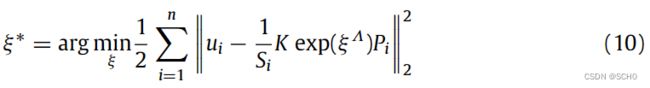
最小重投影误差是观测到的像素坐标ui与当前姿态ξ下三维点Pi的重投影坐标之差。优化的目标是找到一个姿态,使重投影误差最小。
在动态环境下,动态目标上特征点的重投影误差会过高,导致相机姿态不能收敛到最优值。dynamic - slam的语义校正模块的决策结果表示为一个mask图像mask(u,v) ={0,1},它是一个与原始图像宽度和高度相同的二维矩阵,元素值为0的点表示静态像素点,元素值为1的点表示动态像素点。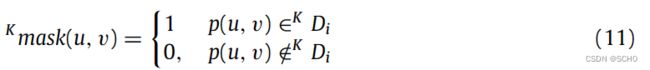
同时,前端视觉里程计将随时读取掩模图像,并根据掩模图像值对特征点进行选择性跟踪操作。
图5给出了选择性跟踪算法的实现过程。动态特征点的像素坐标 K p d i {}^Kp_{di} Kpdi由语义校正模块获得。然后,计算像素区域L内静态特征点的平均像素位移 S ˉ L ( u , v ) \bar{S}_L(u,v) SˉL(u,v),该像素区域 L L L围绕边界框 K D i {}^KD_i KDi的距离为 l l l。最后,计算动态特征点的像素位移并进行确定。
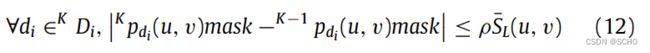
其中ρ为决策系数, S ˉ L \bar{S}_L SˉL为决策阈值,其计算公式如下
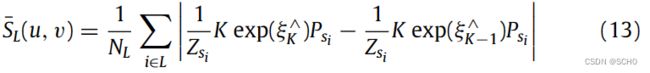
如果动态特征点与静态特征点之间的相对位移在可接受范围内,则允许用于跟踪,否则将被剔除。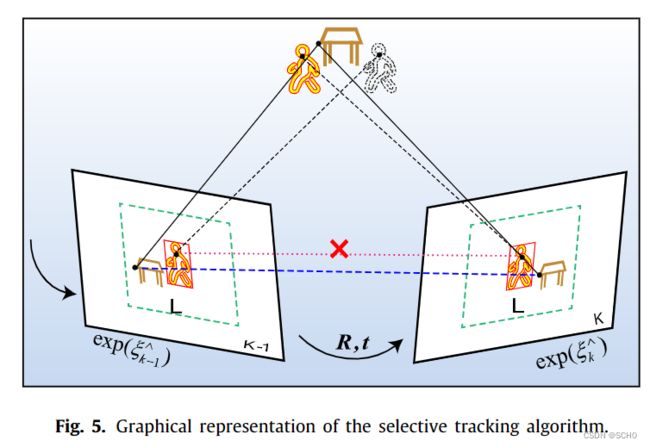
选择性跟踪算法可以充分利用深度学习的检测结果。该方法能很好地解决动态对象处于静态状态或动态对象占据大部分视场时的特征点问题,保证了系统的鲁棒性。该策略在一定程度上牺牲了空间信息,但在机器人低速时是有效的。
为了保证动态SLAM系统的实时性,将目标检测和跟踪分为两个线程。同时,设计了一种新的数据结构类Detection,安全高效,支持并发操作通过检测结果。此外,还使用了一个名为unique lock的互斥锁,以确保两个线程不会发生访问冲突。由于对象检测线程和跟踪线程的处理速度不同步,采用异步读写共享变量的方式实现线程间通信,最大限度地利用CPU时间。
4.实验结果




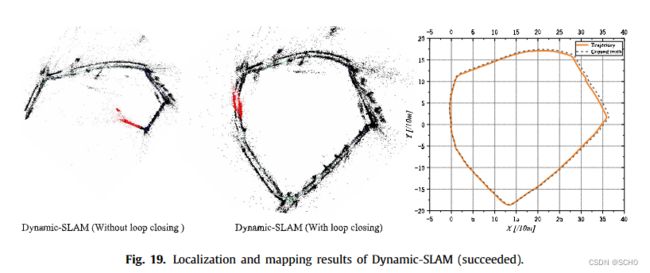
5.结论
本文构建了一个完整的SLAM框架Dynamic- SLAM,这是一个利用深度学习来提高动态环境下的性能的语义单目视觉同步定位与映射系统。这个框架有三个主要贡献。首先,针对现有SSD目标检测网络召回率较低的问题,针对SLAM系统提出了一种基于相邻帧速度不变的漏检补偿算法,大大提高了检测召回率,为后续模块的工作提供了良好的基础。其次,提出了一种选择性跟踪算法,以简单有效的方式消除动态目标,提高了系统的鲁棒性和准确性;最后,构建了基于特征的可视化动态SLAM系统。在SSD卷积神经网络的基础上,将深度学习技术构建为新的目标检测线程,结合先验知识实现机器人定位与测绘中语义层面的动态目标检测。
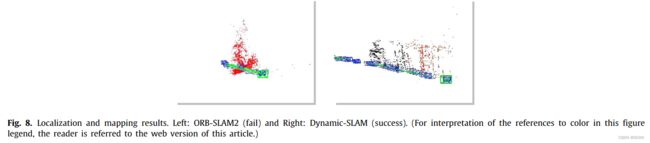
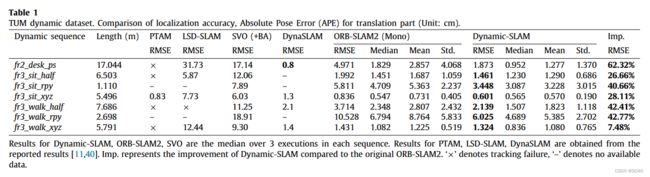
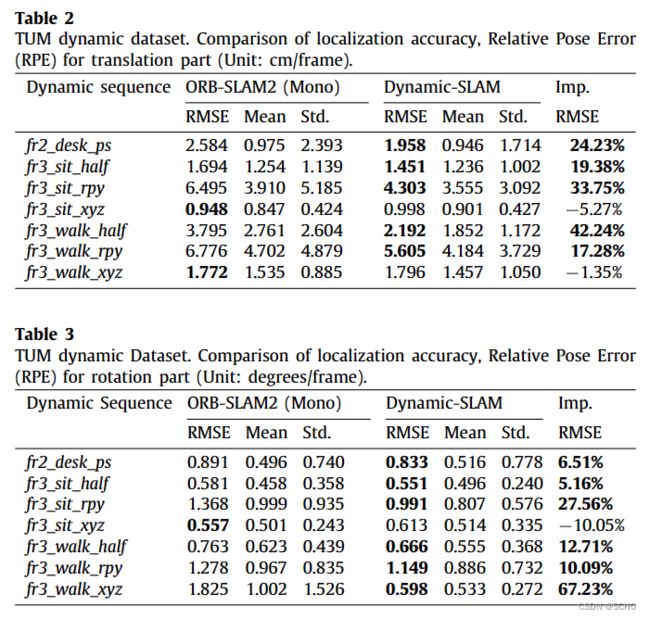
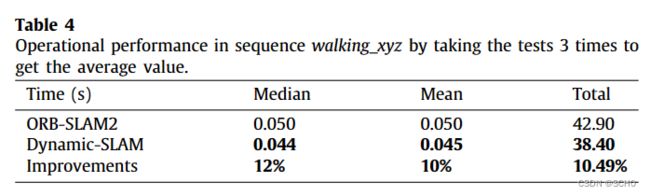
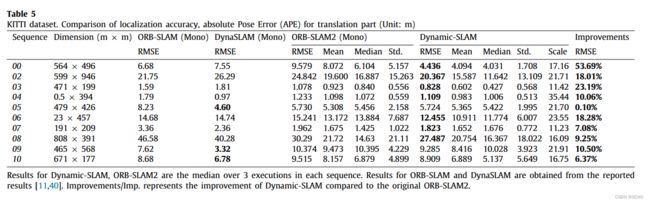
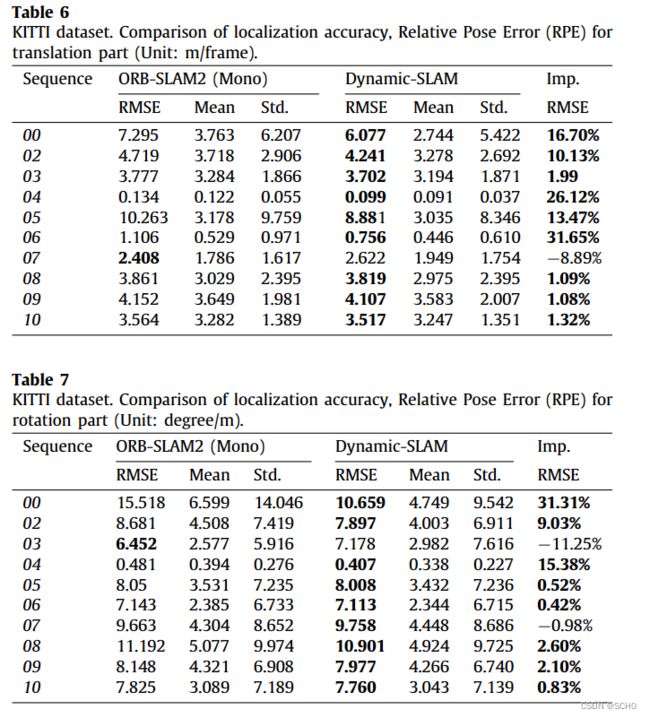
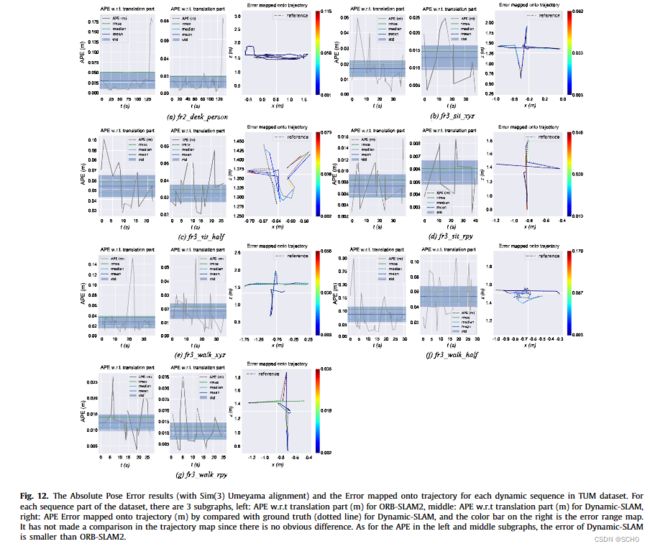
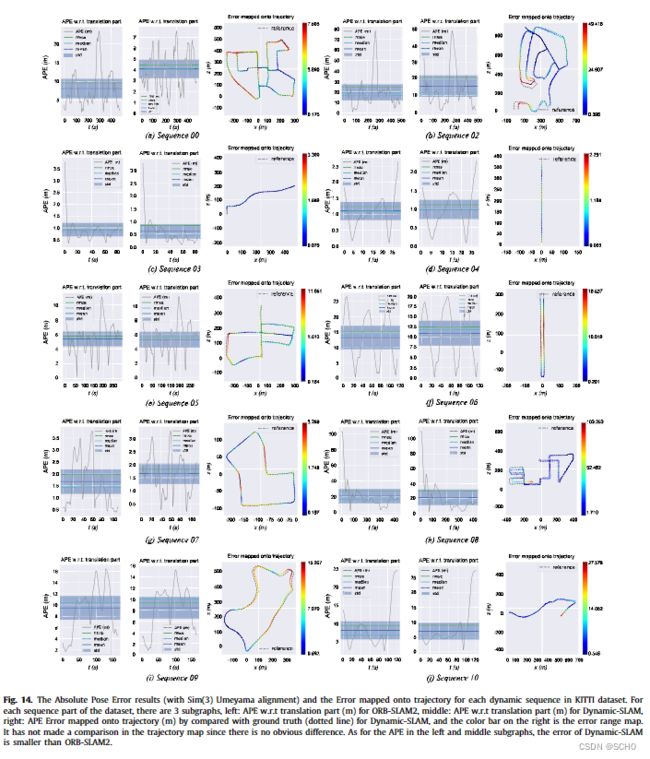
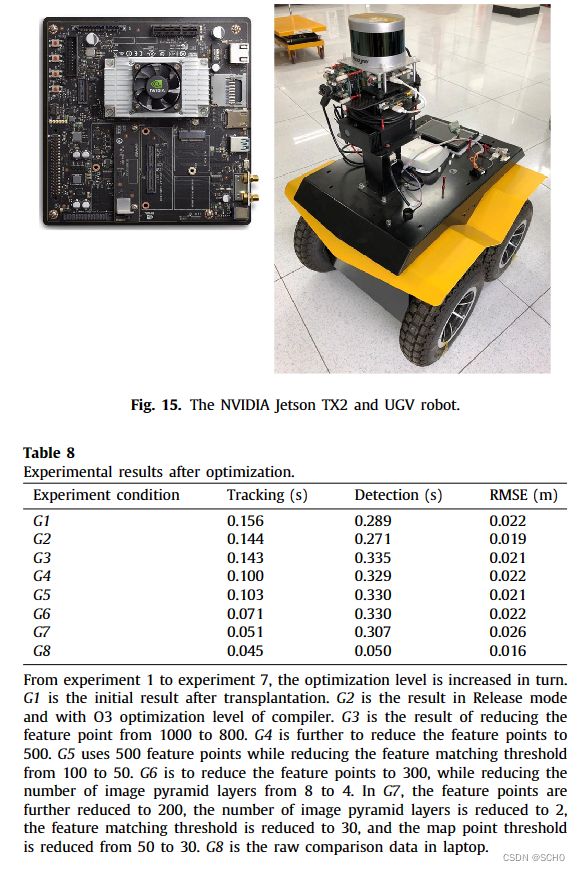
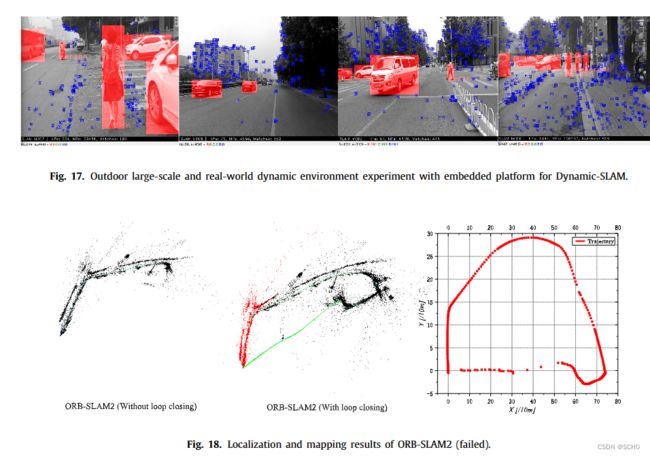
为了评估该框架,设计了六个实验来验证动态slam的优越性、准确性、鲁棒性和可移植性。与原有的SSD检测网络相比,该系统将TUM数据集的检测召回率从82.3%提高到99.8%。在TUM室内动态环境数据集的测试中,dynamic - slam的定位精度比目前最先进的ORB- SLAM2系统提高了7.48% ~ 62.33%,运行性能提高了约10%,也优于PTAM、LSD-SLAM、SVO、DynaSLAM框架。在KITTI室外大尺度动态环境测试中,dynamic - slam成功定位并构建了更精确的环境图,性能优于ORB-SLAM2和DynaSLAM。为了进一步验证算法的实用性,将dynamic - slam移植到嵌入式机器人平台上,成功地实现了实际动态环境下的定位和映射,而orb - slam则失败了。实验结果表明,动态slam在动态环境下具有可靠的优越性、精度和鲁棒性。
综上所述,本文是对SLAM技术在真实动态环境中的探索,成功展示了基于深度学习的人工智能与SLAM融合的广阔前景。在进一步的研究中,深度学习可以更广泛地应用于SLAM,而不仅仅是前端。与此同时,应该挑战更复杂的环境。