DataX(用于不同数据源的导入导出)
一、DataX概述
1.1 DataX简介
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
-
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
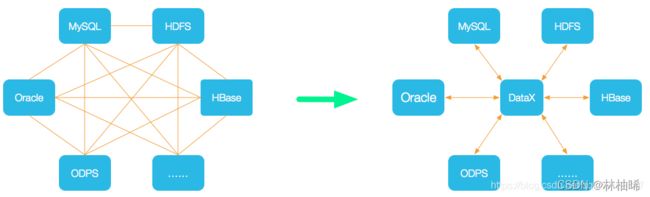
-
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。
Github主页地址:https://github.com/alibaba/DataX
1.2 DataX的框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

-
Reader:
Reader 为数据采集模块,负责采集数据源的数据,将数据发送给Framework。 -
Writer:
Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。 -
Framework:
Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.3 DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。
详情请看:DataX数据源指南
1.4 DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

-
核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
-
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
1.5 六大核心优势
-
可靠的数据质量监控
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
-
-
丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
-
精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": { "channel": 5, "byte": 1048576, "record": 10000 } -
强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
-
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
-
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
-
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
-
-
极简的使用体验
-
易用
下载即可用,支持linux和windows,只需要短短几步骤就可以完成数据的传输。请点击:Quick Start
-
详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
-
传输过程中打印传输速度、进度等

-
传输过程中会打印进程相关的CPU、JVM等
-
-

- 在任务结束之后,打印总体运行情况

二、DataX的快速入门
2.1 环境需求
- Linux
- JDK(1.8以上,推荐1.8)
- Python(2或3都可以)
- Apache Maven 3.x (Compile DataX)
2.2 安装方式
方法1 直接下载DataX工具包
DataX下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本:
$ python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
如果报错
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)
at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95)
at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153)
at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125)
at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)
at com.alibaba.datax.core.Engine.entry(Engine.java:137)
at com.alibaba.datax.core.Engine.main(Engine.java:204)
要运行以下指令
$ rm -rf {YOUR_DATAX_HOME}/plugin/*/._*
方法2 下载DataX源码,自己编译(不推荐)
DataX源码 : https://github.com/alibaba/DataX
(1)、下载DataX源码:
$ git clone [email protected]:alibaba/DataX.git
(2)、通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
然后 拷贝到你喜欢的目录下,像方法1一样,去使用
2.3 查看常用的Reader和Writer插件样本
第一种方式
切换到相应的plugin/reader/或者是plugin/reader/下的插件目录下查看样本
[root@qianfeng01 streamreader]# pwd
/usr/local/datax/plugin/reader/streamreader
[root@qianfeng01 streamreader]# cat plugin_job_template.json
{
"name": "streamreader",
"parameter": {
"sliceRecordCount": "",
"column": []
}
}
[root@qianfeng01 streamwriter]# pwd
/usr/local/datax/plugin/writer/streamwriter
[root@qianfeng01 streamwriter]# cat plugin_job_template.json
{
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
第二种方式:查看datax的github上的对应的文档
第三种方式:使用命令参数-r和-w查看读写插件
[root@qianfeng01 streamwriter]# python {YOUR_DATAX_HOME}/bin/datax.py -r streamreader -w streamwriter
三、案例演示
3.1 Stream->Stream
获取样本并修改:
$ python /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
修改如下: 目的是打印10行 hello,世界
$ vim /usr/local/datax/job/stream2Stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{
type:"long",
value:"1024"
},{
type:"string",
value:"hello,世界"
}
],
"sliceRecordCount": "10"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
并执行job
$ python /usr/local/datax/bin/datax.py /usr/local/datax/job/stream2Stream.json
3.2 mysql -> hdfs
目的:将mysql里的emp表导入到hdfs上的/datax/mysql2hdfs/
获取样本:
$ python /usr/local/datax/bin/datax.py -r mysqlreader -w hdfswriter
修改如下
$ vim /usr/local/datax/job/mysql2Hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"deptno"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng03:3306/sz2103"],
"table": ["emp"]
}
],
"password": "@Mmforu45",
"username": "root",
"where": "deptno = 10 or deptno = 20"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
type:"int",
name:"empno"
},{
type:"string",
name:"ename"
},{
type:"string",
name:"job"
},{
type:"int",
name:"mgr"
},{
name:"hiredate",
type:"date"
},{
name:"dept",
type:"int"
}
],
"defaultFS": "hdfs://qianfeng01:8020",
"fieldDelimiter": "\t",
"fileName": "mysqlToHdfs",
"fileType": "orc",
"path": "/datax/mysql2hdfs",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
运行测试
$ python /usr/local/datax/bin/datax.py /usr/local/datax/job/mysql2Hdfs.json
3.3 mysql->hive
说明:用的其实就是hdfs的写插件
$ vim /usr/local/datax/job/mysql2Hive.json
由于没有在hive中创建表,因此要提前创建相应的目录
hdfs dfs -mkdir /user/hive/warehouse/sz2103.db/orc_emp
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"sal",
"comm",
"deptno"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng03:3306/sz2103"],
"table": ["emp"]
}
],
"password": "@Mmforu45",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
type:"int",
name:"empno"
},{
type:"string",
name:"ename"
},{
type:"string",
name:"job"
},{
type:"int",
name:"mgr"
},{
name:"hiredate",
type:"date"
},{
type:"double",
name:"salary"
},{
type:"double",
name:"comm"
},{
name:"deptno",
type:"int"
}
],
"defaultFS": "hdfs://qianfeng01:8020",
"fieldDelimiter": "\t",
"fileName": "mysqlToHdfs",
"fileType": "orc",
"path": "/user/hive/warehouse/sz2103.db/orc_emp",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
运行测试:
$ python /usr/local/datax/bin/datax.py /usr/local/datax/job/mysql2Hive.json
由于之前没有创建hive表,所以最后要把hive参考配置的字段来设计hive表并创建
create table if not exists orc_emp(
empno int,
ename string,
job string,
mgr int,
hiredate date,
salary double,
comm double,
deptno int
)
row format delimited
fields terminated by "\t"
stored as orc;
3.4 hdfs -> mysql
注意:mysql要提前创建表
获取样本:
$ python /usr/local/datax/bin/datax.py -r hdfsreader -w mysqlwriter
修改如下
$ vim /usr/local/datax/job/hdfs2mysql.json
小贴士:
datax读取的hdfs上的文件: 文件里的数据都应该被当成字符串读取,然后进入到datax里转成datax自己的类型
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{
index:0,
type:"long"
},{
index:1,
type:"string"
},{
index:2,
type:"string"
},{
index:3,
type:"long"
},{
index:4,
type:"date"
},{
index:5,
type:"long"
}
],
"defaultFS": "hdfs://qianfeng01",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "orc",
"path": "/datax/mysql2hdfs/*"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"deptno"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://qianfeng03:3306/sz2103",
"table": ["hdfs2mysql"]
}
],
"password": "@Mmforu45",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
$ python /usr/local/datax/bin/datax.py /usr/local/datax/job/hdfs2mysql.json
3.5 hive->mysql
提前在mysql里创建表
修改如下
$ vim /usr/local/datax/job/hive2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{
index:0,
type:"long"
},{
index:1,
type:"string"
},{
index:2,
type:"string"
},{
index:3,
type:"long"
},{
index:4,
type:"date"
},{
index:5,
type:"double"
},{
index:6,
type:"double"
},{
index:7,
type:"long"
}
],
"defaultFS": "hdfs://qianfeng01",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "orc",
"path": "/user/hive/warehouse/sz2103.db/orc_emp/*"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://qianfeng03:3306/sz2103",
"table": ["hive2mysql"]
}
],
"password": "@Mmforu45",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
$ python /usr/local/datax/bin/datax.py /usr/local/datax/job/hive2mysql.json
3.6 增量导入
使用table和where两个参数或者querySql参数进行增量导入
$ vim /usr/local/datax/job/mysql2hdfs_increment.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"deptno"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng03:3306/sz2103"],
"querySql":["select empno,ename,job,mgr,hiredate,deptno from emp where deptno > '${deptno}'"]
}
],
"password": "@Mmforu45",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
type:"int",
name:"empno"
},{
type:"string",
name:"ename"
},{
type:"string",
name:"job"
},{
type:"int",
name:"mgr"
},{
name:"hiredate",
type:"date"
},{
name:"dept",
type:"int"
}
],
"defaultFS": "hdfs://qianfeng01:8020",
"fieldDelimiter": "\t",
"fileName": "mysqlToHdfs",
"fileType": "text",
"path": "/datax/mysql2hdfs",
"writeMode": "append",
}
}
}
],
"setting": {
"speed": {
"channel": "2"
}
}
}
}
给形参赋值
赋值格式: -p "-DpropertyName=propertyValue -D........"
$ python /usr/local/datax/bin/datax.py /usr/local/datax/job/mysql2hdfs_increment.json -p "-Dstart_value=20 -D"
四、DataX调优方案
1,网络本身的带宽等硬件因素造成的影响;
2,DataX本身的参数;
3,从源端到任务机;
4,从任务机到目的端;
即当觉得DataX传输速度慢时,需要从上述四个方面着手开始排查。
此部分主要需要了解网络本身的情况,即从源端到目的端的带宽是多少(实际带宽计算公式),平时使用量和繁忙程度的情况,从而分析是否是本部分造成的速度缓慢。以下提供几个思路。
1,可使用从源端到目的端scp,python http,nethogs等观察实际网络及网卡速度;
2,结合监控观察任务运行时间段时,网络整体的繁忙情况,来判断是否应将任务避开网络高峰运行;
3,观察任务机的负载情况,尤其是网络和磁盘IO,观察其是否成为瓶颈,影响了速度;
全局
{
"core":{
"transport":{
"channel":{
"speed":{
"channel": 2, ## 此处为数据导入的并发度,建议根据服务器硬件进行调优
"record":-1, ##此处解除对读取行数的限制
"byte":-1, ##此处解除对字节的限制
"batchSize":2048 ##每次读取batch的大小
}
}
}
},
"job":{
...
}
}
局部
"setting": {
"speed": {
"channel": 2,
"record":-1,
"byte":-1,
"batchSize":2048
}
}
}
}
# channel增大,为防止OOM,需要修改datax工具的datax.py文件。
# 如下所示,可根据任务机的实际配置,提升-Xms与-Xmx,来防止OOM。
# tunnel并不是越大越好,过分大反而会影响宿主机的性能。
DEFAULT_JVM = "-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log" % (DATAX_HOME)
Jvm 调优
python datax.py --jvm="-Xms3G -Xmx3G" ../job/test.json
此处根据服务器配置进行调优,切记不可太大!否则直接Exception
以上为调优,应该是可以针对每个json文件都可以进行调优。
nel": 2, ## 此处为数据导入的并发度,建议根据服务器硬件进行调优
“record”:-1, ##此处解除对读取行数的限制
“byte”:-1, ##此处解除对字节的限制
“batchSize”:2048 ##每次读取batch的大小
}
}
}
},
“job”:{
…
}
}
局部
```json
"setting": {
"speed": {
"channel": 2,
"record":-1,
"byte":-1,
"batchSize":2048
}
}
}
}
# channel增大,为防止OOM,需要修改datax工具的datax.py文件。
# 如下所示,可根据任务机的实际配置,提升-Xms与-Xmx,来防止OOM。
# tunnel并不是越大越好,过分大反而会影响宿主机的性能。
DEFAULT_JVM = "-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=%s/log" % (DATAX_HOME)
Jvm 调优
python datax.py --jvm="-Xms3G -Xmx3G" ../job/test.json
此处根据服务器配置进行调优,切记不可太大!否则直接Exception
以上为调优,应该是可以针对每个json文件都可以进行调优。
官方调优:https://developer.aliyun.com/article/71063