计算机视觉实验:人脸识别系统设计
实验内容
设计计算机视觉目标识别系统,与实际应用有关(建议:最终展示形式为带界面可运行的系统),以下内容选择其中一个做。
1. 人脸识别系统设计
(1) 人脸识别系统设计(必做):根据课堂上学习的理论知识(包括特征提取、分类器设计),设计一个人脸识别系统,该系统具有较好的识别率。可在提供的AR人脸图片数据集(120人)、Feret人脸图片数据集(175人)、人脸视频数据集(10人)、真实采集的人脸视频或其他公开数据集上展开实验。
(2) 人脸识别系统提升(至少选择其中1个问题做):面向实际环境的人脸识别系统会考虑更多环节,包括图像预处理、特征提取、特征选择、分类器设计、训练与测试等。人脸识别算法在真实应用中会遇到以下问题,包括噪声干扰、光照变化、遮挡影响、角度变化。请针对以上至少1个问题(如噪声干扰、光照变化、遮挡影响、角度变化)展开探讨,分析是什么原因导致识别性能下降,提出增强人脸识别系统性能的方法,提高系统对异常情况处理的能力,使整个识别系统的适应性和稳定性达到更好的状态。
提示:
- 噪声干扰方面可考虑图像增强算法,包括中值滤波、均值滤波、高斯滤波等;
- 光照变化方面可考虑LBP算法及其扩展版本,或图像增强算法,如直方图均衡化、伽马变换等;
- 遮挡影响方面可考虑对图像分块投票处理,或线性表示残差最小的方式辨别遮挡区域;
- 角度变化方面可考虑增加不同角度的采样图片,或引入仿射变换的考虑;
- 特征提取方面可采用Gabor特征,特征脸,深度特征等方法;
- 分类器设计可采用贝叶斯分类器,神经网络等方法;
- AR人脸数据集和Feret人脸数据集可以用来测试算法在噪声干扰(需要人工添加噪声)、光照变化、遮挡影响、角度变化下的性能。在此基础上可把识别系统应用在真实环境中测试。
- 可根据需要选用人脸检测器或引入仿射变换,本实验提供了Haar检测器和基于仿射变换的人脸检测器。
- 人脸数据集说明:
AR人脸数据集:包含120人,每人26张图片, 图像分辨率宽80,高100,可测试光照变化、遮挡情况下算法性能。
Feret人脸数据集:包含175人,每人7张照片,图像分辨率宽80,高80,可测试不同角度、光照变化下算法性能。
人脸视频数据集:包含10人的视频,每个人有训练视频序列和测试视频序列,可测试不同角度、光照变化、遮挡干扰、噪声干扰下算法性能。
真实人脸数据采集:可根据系统实际情况拍摄。
(3)分析在实验室环境与自然环境下识别算法设计上的区别,如何提高算法创新?(可选)
2. 自选目标识别内容,题目自拟
实验步骤与过程
人脸识别系统设计
人脸识别的关键点在于特征的提取,相比于数据收集与预处理以及分类器的选择,特征提取是最独特的也是各种人脸识别系统的主要区别。常见的人脸特征提取方法有局部二值模式直方图法、Gabor滤波器方法、基于统计的方法(PCA、LDA)、纹理特征方法等。在本次实验中我选择了LDA线性判别方法进行特征提取。同时在进行特征提取前,我使用了Haar人脸检测器对人脸进行检测与定位,然后对人脸进行了对齐。提取完后,使用了KNN分类器对特征进行分类识别。其整体的思路图如图1所示。
|
|
| 图1 人脸识别系统思路图 |
数据集导入
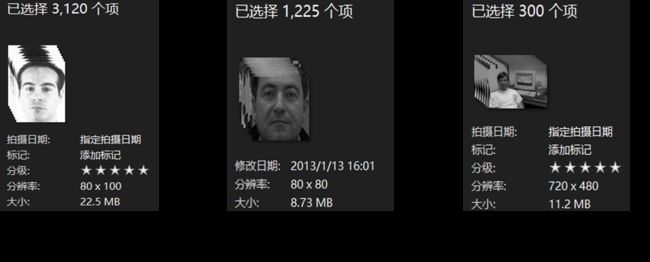
题目中提供了三个数据集,其中AR和feret数据集是标准的人脸数据集,而视频数据集则是从视频中提取得到的数据集。数据集的信息如下图图2所示。
|
|
| 图2 三个数据集的基本信息 |
使用文件遍历的方法,将所有图片通过opencv来读取,最后传入图像预处理模块进行处理。在代码中数据读取模块归属于Face_reg类中的load_dataset函数。此函数接收四个参数,其中path表示数据集路径,trun表示截取文件名的前几位作为类别,mode表示重置模式还是添加模式 1表示重置 0表示添加,format表示数据集文件结构类型 1表示的是AR和feret的结构 0表示视频数据集的结构。
图像预处理
在图像预处理模块中,对图像进行了灰度变换、仿射变换修真角度、人脸定位裁剪、直方图均衡化、图像尺寸调整等操作。其思路如下图图3所示。
|
|
| 图3 图像预处理示意图 |

1. 灰度变换
将彩色图变成灰度图减少计算复杂性并提高识别性能,转后的结果如下图所示,左图为原图,右图为灰度变换后的结果。
|
|
|
| 图4 灰度变换图 |
|


2. 仿射变换修正角度
进行灰度变换后使用仿射变换对人脸进行角度修正。这里的角度修正原理在于根据眼睛的相对坐标调整图像角度,使得主要特征点位置相对固定便于特征提取和匹配。特征点的检测主要使用的是dlib的‘shape_predictor_68_face_landmarks’模型。仿射变换的结果如下图5所示。
|
|
| 图5 仿射变换结果图 |

3. 人脸定位裁剪
对于人脸的检测与定位我使用了已经训练好的Haar人脸检测器。Haar人脸检测器也称为Viola-Jones 检测器,它与2001年时被提出。此检测器通过滑动窗口并通过提取Haar特征来对人脸进行检测与定位。下图图6为检测并提取后的结果图。
|
|
| 图6 人脸定位裁剪结果图 |

4. 直方图均衡化
在一些图像中,往往由于光照变化的原因,使得图像过亮或郭安,使得某些细节无法突出。因此可以对图像进行直方图均衡化处理,让亮度值变得均匀以使得亮度均匀降低亮度变化的影响。下图图7为直方图均衡化后的结果。
|
|
| 图7 直方图均衡化 |

5. 图像尺寸调整
在利用LDA降维时,模型要求特征的数量是一致的,而此处是直接使用图像的一维亮度值作为特征。因此此处需要对图像进行调整,使得输入的图像尺寸是一致的。
特征提取
在特征提取方面,使用了LDA对图像的一维灰度序列进行了降维,最后降至25个特征。除此之外还有考虑过使用LBP特征与Garbor特征,但是最后效果均不佳。下图为整体的思路图。
| |
| 图8 特征提取 |

1. 特征提取
- 扁平化灰度值:图像预处理得到的数据是一个80*80的二维矩阵,而为了更好地提取特征需要将二维矩阵扁平化为一维列表。然后再进行降维操作。
- LBP特征提取:计算LBP特征图后进行扁平化后输入LDA进行降维训练。
- Garbor特征提取:对图像进行Garbor滤波后计算均值以作为特征输入。
2. LDA降维
在上面的特征提取中,由于后两者效果不佳,因此仅选用第一种作为特征进行降维。使用的降维方法是LDA线性判别。其原理在于到一个线性投影,将高维数据映射到低维空间,使得不同类别的样本在投影后的空间中有较大的类间距离(即不同类别之间的距离较大),同时保持同类样本之间的类内距离较小。这样做可以提高分类的准确性。此处在经过不多地调整后最后选择25作为降维的维数,25以下准确率会降低,而25以上则无明显地提升。
分类器设计和训练
1. 分类器设计
在分类器的选择方面,我选择了原理简单的K近邻算法。它具有简单直观、高度灵活的特点,且能拥有较好的效果。它主要通过各个样本点离周围点的距离而确定这个样本的类别。
2. 参数寻优
在人脸识别中,选择适当的K值对分类性能至关重要。如果选择一个过小的K值,分类结果可能会对噪声敏感,导致过拟合。如果选择一个过大的K值,可能会使得分类边界过于模糊,导致欠拟合。因此此处我使用了网格搜索,通过尝试不同的K值(1-10),寻找最佳的K值。最终它可以帮助我们选择一个在训练数据上表现良好且具有较好泛化能力的K值,从而提高人脸识别的分类性能。
人脸识别系统提升
未优化前的结果
在一开始的系统设计中,并未考虑太多的图像预处理。同时也没有对LDA和KNN的参数选择进行考虑。将80%的数据用于训练20%的数据用于评估。其评估结果如下所示。
|
|
| 图9 未优化前的准确率 |

从中可以看到三种数据集的准确率均高于0.8说明具有一定的准确性。而人脸视频数据集整体的准确程度高于另外两个数据集的。观察数据集可以发现其实人脸视频数据集的人脸较为稳定且类别较少,而另外两个数据集的人脸存在更多的变化如表情、遮挡与方向等。因此人脸视频数据集相对而言会有更好地效果。
模型存在的问题
为了找到问题所在,对预测错误的图片进行分析,如下所示。
|
|
| 图10 预测错误的人脸 |

根据以上的问题,可以整理成如下表。并提出相应的解决方案。
| 存在问题 |
解决方案 |
解决效果 |
| 表情变化影响识别 |
同特征表征不全的方案 |
同特征表征不全的效果 |
| 拍摄方向影响识别 |
1.添加LBP特征 2.仿射变换修正角度 |
LBP特征效果不佳, 使准确率降低,故抛弃. |
| 特征表征不全 |
1. 提高LDA输出的维数 2.提取Garbor特征(均值) |
1.维数从9提升至25准确率变为90%以上,25以上维数效果一样. 2.添加Garbor特征后效果不明显 |
| 光线变化影响识别 |
对图像进行直方图均衡化处理以使得亮度均匀 |
对光线问题而误判的人脸有效,但是造成其他图像误判 |
| 墨镜遮挡影响识别 |
同特征表征不全的方案 |
同特征表征不全的效果 |
模型存在的问题
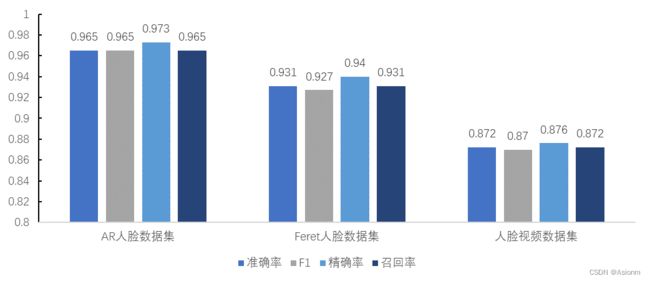
最后系统改进后的结果如下所示。可以看到优化后前两个数据集的效果增加到0.9以上,其准确率大大提高。而对于视频数据集却没有提升,因为优化过程中有一个关键点在于降维所剩下的特征维度。由于LDA要求维度要小于等于类别数量,而人脸视频数据集中只有10个类别,因此维数只能保持在10因此准确率无提示。而其他两种数据集均有提升。
| |
| 图10 优化后的指标 |
基于深度学习的人脸识别系统
在过去的十几年中传统的机器学习算法一直都是人脸识别系统的主流方法,然而随着计算机算力的提升,深度学习方法已成为目前最主流的方法。下面将介绍目前常见的人脸识别模型,同时复现其中的FaceNet模型。
常见的人脸识别模型
1. DeepFace
DeepFace模型发布于2014年,它是一种基于深度学习的人脸识别模型。DeepFace首先使用传统的人脸检测算法定位图像中的人脸位置,然后对检测到的人脸进行对齐,以确保在特征提取过程中具有一致的姿态。对齐后的人脸图像被输入到深度卷积神经网络中进行特征提取。通过卷积层和全连接层,DeepFace学习到了128维的特征向量,用于表示每张人脸图像。在人脸识别阶段,它使用学习到的特征向量进行比较。它计算待识别人脸与已知人脸之间特征向量的相似度,通常使用余弦相似度作为相似度度量。如果待识别人脸的特征向量与某个已知人脸的特征向量之间的相似度超过一定阈值,就可以判定它们属于同一个人。
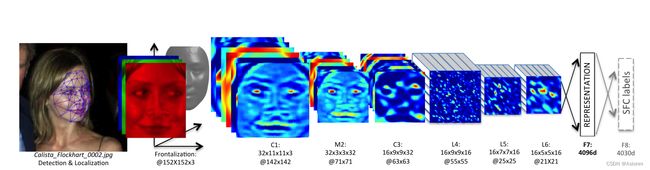
图11 DeepFace结构图
2. FaceNet
FaceNet是Google于2015年发布的基于深度学习的人脸识别模型。它使用深度卷积神经网络提取人脸的高维特征向量,并通过三元组损失函数进行训练来优化特征表示。通过最大化同一个人脸的特征向量之间的相似度,最小化不同人脸的特征向量之间的相似度,FaceNet学习到的特征向量具有辨别不同人脸的能力。在人脸识别阶段,可以通过计算待识别人脸特征向量与已知人脸特征向量之间的距离来进行识别,距离越小表示匹配度越高。

图12 FaceNet模型结构
3. ArcFace
ArcFace是一种用于人脸识别的深度学习模型,发布于2019年。它通过角度余弦距离来优化特征向量的表示。与传统模型不同,ArcFace考虑了特征向量的角度信息,使得同一个人脸的特征向量更接近,不同人脸的特征向量更远离。这种设计使得ArcFace在人脸识别任务中表现出色,并取得了较高的准确率和鲁棒性。
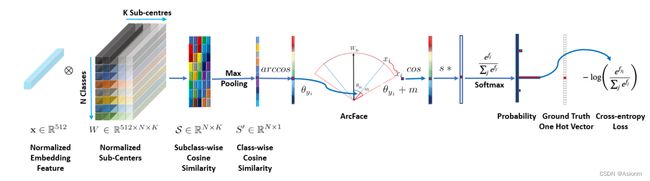
图13 ArcFace模型结构
模型复现
在此处我选择了FaceNet进行复现,其代码主要参考于:GitHub - timesler/facenet-pytorch: Pretrained Pytorch face detection (MTCNN) and facial recognition (InceptionResnet) models
以下为复现的步骤:
1. 环境安装
(1)安装facenet-pytorch
FaceNet提供了对应的python包,可以直接使用pip安装,其安装命令如下:
pip install facenet-pytorch
需要注意,由于FaceNet依赖于pytorch环境,所以需要实现安装pytorch的环境。
(2)导入库文件
完成后可以用下面的语句导入模型,若能导入成功即安装完成。
# 加载人脸检测器和特征提取器
mtcnn = MTCNN()
resnet = InceptionResnetV1(pretrained='vggface2').eval()
2. 人脸录入
FaceNet有提供预训练的模型,由于此处仅作为实验的拓展部分,因此直接加载预训练模型。在加载完成后,我们目前的人脸库为空,因此需要先进行人脸的录入。此处人脸的录入主要为提取一张标准人脸的特征。它首先会对图像进行一些预处理然后检测并裁剪出人脸,并对人脸进行对齐。然后调用模型的函数直接得到其特征,最后存储到一列表中。
3. 人脸识别
当对人脸进行录入后,下一步则是对未知人脸进行识别。其识别的思路与人脸录入类似,首先会对图像进行预处理,然后定位人脸并裁剪对其,最后提取特征进行分类。具体代码见’FaceNet.py’。
可视化平台搭建
对于一个人脸识别系统即使有再好的准确率与效率,若没有相应的应用与可视化平台,那也就无法成为一个较好的系统。因此此处利用vue与flask框架搭建相应的web人脸识别在线网页平台。
可视化系统设计
系统的核心为封装好的face_reg对象,通过api接口的方式使用python的Flask作为后端框架,vue作为前端框架。当用户上传图像后,而将图像传回给后端并调用分类函数对人脸类别进行分类。最后再将结果传回网页页面中。下图为可视化系统的思路。

图14 可视化系统设计思路
后端实现
后端主要用于接收前端传回来的图像并对图像的人脸定位裁剪与预测。同时前端传回来的图片将存储在服务器中,最后后端返回图像的链接与预测的标签至前端中显示。下图为后端设计的思路图。
|
|
| 图15 后端思路图 |

前端实现
前端使用了vue3框架,并且使用到了element-plus组件、axios等工具。前端主要设计了可视化的页面,同时完成了图像上传与接收的逻辑。下图为实现的效果图。
|
|
| 图16 前端可视化效果图 |

参考文献:
[1] Zhao, W., Chellappa, R., Phillips, P. J., & Rosenfeld, A. (2003). Face recognition: A literature survey. ACM Computing Surveys (CSUR), 35(4), 399-458.
[2] Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1701-1708.
[3] Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.
[4] Deng J, Guo J, Xue N, et al. Arcface: Additive angular margin loss for deep face recognition[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 4690-4699.
[5] Jain, A. K., Ross, A., & Prabhakar, S. (2004). An introduction to biometric recognition. IEEE Transactions on Circuits and Systems for Video Technology, 14(1), 4-20.
[6]Zhang, D., & Zhou, Z. H. (2011). Face recognition: A literature survey. ACM Computing Surveys (CSUR), 43(3), 1-52.
[7] Ma, L., Tan, T., Wang, Y., & Zhang, D. (2003). Personal identification based on iris texture analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(12), 1519-1533.
[8] Turk, M., & Pentland, A. (1991). Face recognition using eigenfaces. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 586-591.
[9] Belhumeur, P. N., Hespanha, J. P., & Kriegman, D. J. (1997). Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(7), 711-720.
[10] Viola, P., & Jones, M. (2001). Rapid object detection using a boosted cascade of simple features. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1, I-511.
[11] Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1, 886-893.
[12] LDA算法在人脸识别中的研究与应用丨【百变AI秀】-云社区-华为云
[13] 基于LDA的人脸识别算法研究_51CTO博客_人脸识别算法原理
[14] https://blog.csdn.net/weixin_42163563/article/details/127957504
实验结论或体会
本次实验取得了较好的成果,成功地设计了人脸识别系统并在AR、feret和视频数据集上获得了较高的准确率。通过增加特征维度以及考虑光照变化和角度变化等因素,系统的准确率从0.8提高到了0.9。此外,还设计了人脸识别系统的可视化模块,取得了可观的效果。
然而,系统仍然存在一些需要改进的方面。首先,需要加强系统的泛化性能。当前系统在数据集内的数据上表现出较高的准确率,但当将两个不同的数据集合并时,准确率仅为60%。为了提高系统的泛化性,需要进一步研究和优化算法,以便更好地适应不同数据集的特点和变化。
其次,需要完善系统的功能,使其支持人脸的录入和识别。目前系统主要关注于人脸识别过程,但在实际应用中,人脸的录入是必不可少的一步。因此,需要设计和实现人脸录入的功能,以便用户可以方便地将新的人脸数据添加到系统中,并进行准确的识别。
最后,我们还需要提高人脸检测器的泛化性能。人脸检测是人脸识别系统的前置步骤,它的准确性和鲁棒性对整个系统的性能至关重要。当前系统在不同场景、角度和光照条件下的人脸检测方面仍有一定的改进空间。我们将继续研究和改进人脸检测器,以提高其泛化性能和准确度。
总之,本次实验在人脸识别系统的设计和优化方面取得了积极的进展,但仍面临着一些挑战和改进的空间。通过加强系统的泛化性、完善功能以及提高人脸检测器的性能,有信心进一步提升系统的准确率和稳定性,以满足实际应用的需求。