Elasticsearch安装与分词插件、用户词典、同义词配置等
简介
本文介绍了全文搜索引擎Elasticsearch的安装过程,以及ik中文分词插件、用户词典、同义词的配置。
Elasticsearch安装
值得注意的是,Elasticsearch运行需要Java环境。因此安装前需要提前配置好Java环境。
官网方式
- 下载
进入官网 下载对应版本,本文选择的版本为6.8.13。

- 启动
解压下载的包到磁盘上,进入Elasticsearch目录。
如果是windows,打开bin/目录下的elasticsearch.bat
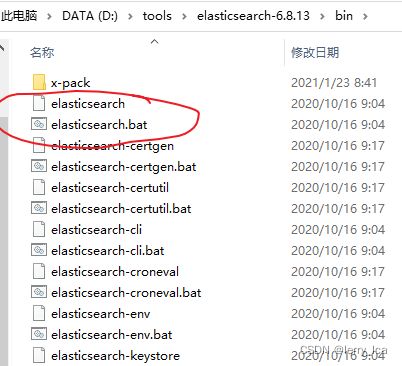
如果是linux,在Elasticsearch根目录下以非root执行bin/elasticsearch命令启动。
Docker方式
- 拉取镜像
docker pull elasticsearch:6.8.13
- 启动容器(ES会随容器启动)
# 容器名为es,映射端口9200和9300,设置非集群单节点
docker run -itd --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.8.13
- 进入容器(编辑配置文件等)
docker exec -it -u elasticsearch es /bin/bash
Elasticsearch配置文件
找到ES根目录config/路径下的elasticsearch.yml进行编辑
# 编辑配置文件,windows系统下直接打开编辑即可
vim config/elasticsearch.yml
# 修改集群名、节点名
cluster.name: my-application
node.name: node-1
# 处理http跨域请求
http.cors.enabled: true
http.cors.allow-origin: "*"
安装可视化工具
es-head
es-head的github地址为https://github.com/mobz/elasticsearch-head
将代码克隆到本地磁盘上,然后进行安装。
cd elasticsearch-head
npm install
npm run start
# 安装好后打开浏览器访问
open http://localhost:9100/
Kibana
ES官方有一款可视化工具Kibana,可去官网下载并学习使用。

这里下载的是windows版本,下载好后,找到Kibana目录的bin/目录下,打开kibana.bat(需要先运行ES,否则无法使用Kibana)

然后,可以在浏览器访问http://localhost:5601打开Kibana的控制台
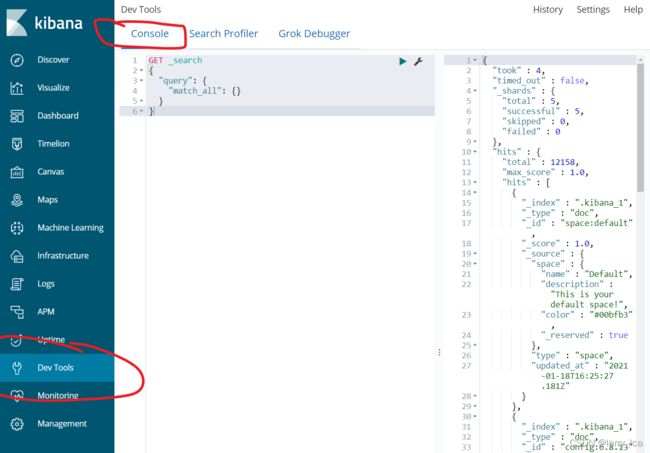
在Kibina的控制台左侧导航栏,找到Dev Tools,右侧的Console控制台即可在此输入命令进行操作
安装中文分词器ik
- 下载地址
# github地址
https://github.com/medcl/elasticsearch-analysis-ik
# 各个版本的编译后
https://github.com/medcl/elasticsearch-analysis-ik/releases
# 6.8.13
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v6.8.13
-
解压或复制到指定位置
将下载好的包解压到ES根目录下的plugins/ik/目录下(需要创建ik目录) -
测试
重启ES,使用ik分词测试。
# 发送http post请求
http://localhost:9200/_analyze
# body为json
{
"analyzer": "ik_max_word", # ik_max_word/ik_smart
"text": "加油奥里给"
}
两种分词方式:ik_max_word 和 ik_smart 什么区别?(更多细节参考github官网)
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
配置自定义词典
- 新建自定义词典文件
到ES根目录下的plugins/ik/config/目录下,新建user_word.dic(默认会有这个,可以不用新建) - 修改ik配置
到ES根目录下的plugins/ik/config/目录下,编辑IKAnalyzer.cfg.xml
IK Analyzer 扩展配置
user_word.dic
其他关于如何热更新ik分词等,参考它的官网即可。
配置同义词库
同义词库用于扩大搜索范围,例如川普、懂王都可以表示特朗普。
- 新建同义词库文件
到ES根目录下的config/目录下新建synonyms.txt,里面的内容可以为如下示例:
川普,懂王,特朗普
这里一行表示一组同义词,用英文逗号分隔,表示简单扩展,可以把同义词列表中的任意一个词扩展成同义词列表所有的词。
关于同义词扩展的方式介绍,可以参考ES官方文档。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/synonyms-expand-or-contract.html es2官方文档(中文)
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/analysis-synonym-tokenfilter.html es6.8官方文档(英文)
- 创建索引
可以在Kibana的命令窗口使用如下语句创建索引student,字段有2个:name和introduction,将使用同义词过滤,同时应用中文ik分词。
PUT students
{
"settings": {
"number_of_shards": 1,
"analysis": {
"filter": {
"my_synonym_filter": {
"type": "synonym",
"updateable": true,
"synonyms_path": "synonyms.txt"
}
},
"analyzer": {
"ik_synonym": {
"tokenizer": "ik_smart",
"filter": [
"my_synonym_filter"
]
},
"ik_synonym_max": {
"tokenizer": "ik_max_word",
"filter": [
"my_synonym_filter"
]
}
}
}
},
"mappings": {
"_doc":{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"introduction": {
"type": "text",
"analyzer": "ik_synonym_max",
"search_analyzer": "ik_synonym"
}
}
}
}
}