【爬虫逆向案例】某易云音乐(评论)js逆向—— params、encSecKey解密
声明:本文只作学习研究,禁止用于非法用途,否则后果自负,如有侵权,请告知删除,谢谢!
【爬虫逆向案例】某易云音乐(评论)js逆向—— params、encSecKey解密
- 1、前言
- 2、行动
- 3、源码
- 4、号外
1、前言
今天逆向的这个网站 某易云音乐 歌曲的评论列表
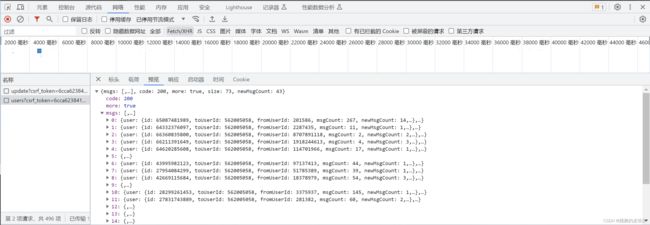
而要拿到评论列表爬虫发送的表单需要两个参数 params 和 encSecKey。这两个玩意是加密的,所以重点就是怎么搞定这两个参数。

2、行动
话不多说,直接分析。
首先我们进入到网易云,随便进入某一首歌详情页。通过抓包分析,很轻松的找到了每一首音乐的评论的位置,现在只需要访问 https://music.163.com/weapi/comment/resource/comments/get?csrf_token= 就可以了。
可以看到这是一个post请求,而且携带的这两个参数这么大一坨,不用多想,绝对是个加密参数。但是大家不要慌,让我们全局搜索一下(跟栈也可以,但我觉得这里直接搜索要快一点),仔细分析一波。
通过搜索任意一个参数可以快速找到加密的位置,可以看到

接下来就是打断点分析。
首先可以确定的是 params= bVe7X.encText,
encSecKey=bVe7X.encSecKey
而 bVe7X 又等于 window.asrsea 这个函数,观察可知这个函数是需要四个参数的,

在控制台中打印一下四个参数,分别是:
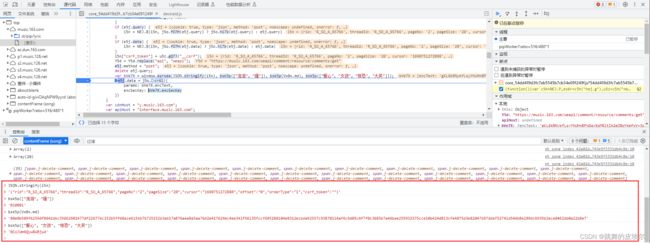
经过多次测试,发现后面三个参数是不变的(如下图),而第一个参数也只有 rid、threadId、cursor 会变,rid 和 threadId 还是一样的,而且是 R_SO_4_ 加上歌曲的 id,cursor 是毫秒的时间戳,那这就简单了。

好了,四个参数已经搞定,接下来就是关键了,进入 window.asrsea 函数
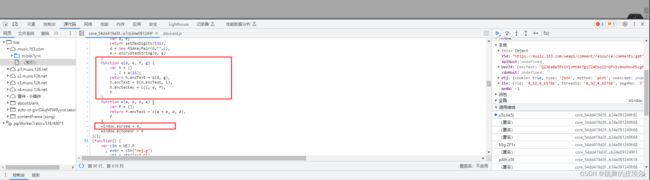
可以看到,d 就是 window.asrsea 这个函数。要传入的四个参数我们已经知道了。
不管那么多,直接复制到 js 文件里看看结果。
为了避免与后面其他的参数起冲突,这里我就改了下名字,然后运行。

意料之中,报错了。

说简单也简单,报错了之后,接下来就是缺什么补什么,这里就大家去 js 页面找自己慢慢去补了哈。

另外,当补到b函数的时候,会说 CryptoJS is not defined,仔细一看原来 b 函数里面有个 AES 加密,能调库就调库,这里就npm install crypto-js,然后导入就可以了

后面的就没有什么大问题了。补完函数后(大概有34个函数左右,400行左右的 js 代码),我们也是顺利的拿到了想要的东西。


虽然过程艰辛,很累的,一味以为拿错了,但结果是好的。接下来就是写代码拿评论了,这里我用的是 execjs 库来执行 js 代码,完整 Python 代码如下:
import json
import time
import execjs
import requests
from fake_useragent import UserAgent
def get_argument(music_id, page):
with open('./comments.js', 'r', encoding='utf-8') as f:
time_now = int(round(time.time() * 1000))
# 第一个 {} 符号被误识别为占位符,导致后面的键值对无法正确替换,可以使用双大括号 {{}} 来表示字面意义上的大括号
aa = '{{"rid":"R_SO_4_{}","threadId":"R_SO_4_{}","pageNo":"{}","pageSize":"20","cursor":"{}","offset":"0","orderType":"1","csrf_token":""}}'.format(
music_id, music_id, page, time_now)
bb = '010001'
cc = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
dd = '0CoJUm6Qyw8W8jud'
argument_data = execjs.compile(f.read()).call('d', aa, bb, cc, dd)
params = argument_data['encText']
encSecKey = argument_data['encSecKey']
return params, encSecKey
def get_comment(params, encSecKey):
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
header = {
"Origin": "https://music.163.com",
"Pragma": "no-cache",
"Referer": "https://music.163.com/song?id=65766",
"Sec-Ch-Ua": "\"Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"115\", \"Chromium\";v=\"115\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": UserAgent().random
}
data = {
"params": f"{params}",
"encSecKey": f"{encSecKey}"
}
response = requests.post(url=url, headers=header, data=data)
data = response.text
return data
def parse_data(data):
json_data = json.loads(data)
comments = json_data['data']['comments']
print('采集评论数据如下:')
for i in comments:
comment = i['content']
print(comment)
if __name__ == '__main__':
while True:
music_id = input('请输入歌曲id:')
page = input('请输入要采集第几页评论:')
params, encSecKey = get_argument(music_id, page)
response_data = get_comment(params, encSecKey)
parse_data(response_data)
is_continue = input('是否继续采集(y/n):')
if is_continue == 'n':
break
我这里是封装成一次采集一页评论,如果需要采集全部评论的需求,自己修改一下就可以了
3、源码
Github:网易云音乐PC端逆向
CSDN:网易云音乐PC端 js 逆向资源
4、号外
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “✍️评论” “收藏” 一键三连哦!
【关注我| 获取更多源码 | 定制源码】大学生毕设模板、期末大作业模板 、Echarts大数据可视化、爬虫逆向等! 「一起探讨 ,互相学习」!(vx:python812146)
以上内容技术相关问题欢迎一起交流学习