GANet: A Keypoint-based Global Association Network for Lane Detection (CVPR 2022)
GANet: A Keypoint-based Global Association Network for Lane Detection - 一种用于车道检测的基于关键点的全局关联网络(CVPR 2022)
- 摘要
- 1. 引言
- 2. 相关工作
-
- 2.1 车道检测方法
- 2.2 可变形建模
- 3. 方法
- References
声明:此翻译仅为个人学习记录
文章信息
- 标题:GANet: A Keypoint-based Global Association Network for Lane Detection (CVPR 2022)
- 作者:Jinsheng Wang*, Yinchao Ma*, Shaofei Huang*, Tianrui Hui, Fei Wang, Chen Qian, Tianzhu Zhang (* Equal contribution)
- 文章链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Wang_A_Keypoint-Based_Global_Association_Network_for_Lane_Detection_CVPR_2022_paper.pdf
- 文章代码:https://github.com/Wolfwjs/GANet
摘要
车道检测是一项具有挑战性的任务,需要预测车道线的复杂拓扑形状并同时区分不同类型的车道。早期的工作遵循自上而下的路线图,将预定义的锚回归到各种形状的车道线中,由于锚的形状固定,因此缺乏足够的灵活性来适应复杂形状的车道。最近,一些工作提出将车道检测公式化为一个关键点估计问题,以更灵活地描述车道线的形状,并以逐点的方式逐渐对属于同一车道线的相邻关键点进行分组,这在后处理过程中效率低且耗时。在本文中,我们提出了一个全局关联网络(GANet)来从一个新的角度来表述车道检测问题,其中每个关键点直接回归到车道线的起点,而不是逐点扩展。具体地说,关键点与其所属车道线的关联是通过全局预测它们与车道的相应起点的偏移来进行的,而不相互依赖,这可以并行进行,以大大提高效率。此外,我们还提出了一种车道感知特征聚合器(LFA),它自适应地捕获相邻关键点之间的局部相关性,以向全局关联补充局部信息。在两个流行的车道检测基准上进行的大量实验表明,我们的方法优于以前的方法,在CULane上的F1得分为79.63%,在具有高FPS的Tusimle数据集上的F1分数为97.71%。
1. 引言
自动驾驶[10]引起了学术界和工业界研究人员的极大关注。为了确保汽车在行驶过程中的安全,自动驾驶系统需要保持汽车沿着道路上的车道线行驶,需要准确感知车道线。因此,车道检测在自动驾驶系统中发挥着重要作用,尤其是在高级驾驶员辅助系统(ADAS)中。
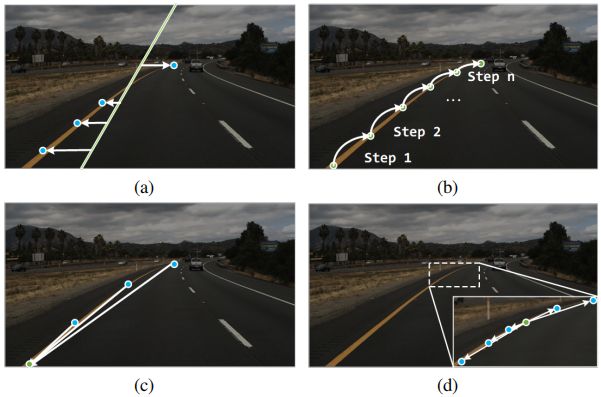
图1. (a) 基于锚点的方法,将预定义的锚点回归为车道形状。(b) 基于关键点的方法,预测关键点到其邻域之间的偏移,以逐个对其进行分组。(c) 我们的GANet的说明,它通过预测每个关键点与其对应车道线的起点之间的偏移量,将每个关键点直接回归到其所属车道。(d) 我们的LFA模块的说明,它将每个关键点与其相邻点相关联,以进行局部信息补充。
给定安装在车辆上的摄像头拍摄的正面图像,车道检测旨在产生道路上每条车道线的准确形状。由于车道线的形状很细,并且需要进行等级判别,因此适当地制定车道检测任务至关重要。受基于锚的目标检测方法[22]的启发,一些工作[10,25]遵循自上而下的设计,如图1a所示。与目标检测类似,具有不同方向的一组直线被定义为锚点。通过预测定位点和车道点之间的偏移,将定位点上的点回归到车道线。然后,应用非最大抑制(NMS)来选择具有最高置信度的车道线。尽管这种方法在车道识别方面是有效的,但由于预定义的锚形状,它是不灵活的。强形状先验限制了描述各种车道形状的能力,导致这些方法的性能次优。
为了灵活描述复杂形状的车道线,Qu等人[21]提出将车道检测公式化为一个关键点估计和关联问题,该问题采用自下而上的设计,如图1b所示。具体来说,车道是用一组有序的关键点来表示的,这些关键点以稀疏的方式均匀采样。每个关键点通过估计它们之间的空间偏移来与其邻居相关联。通过这种方式,属于同一车道的关键点被迭代地集成到连续曲线中。尽管基于关键点的方法在车道线的形状上是灵活的,但在每一步仅将一个关键点与其所属车道线关联是低效且耗时的。此外,由于缺乏全局观,关键点的逐点扩展容易导致误差积累。一旦错误地关联了特定的关键点,车道线的其余部分的估计将失败。
为了克服上述局限性,我们从一个新的基于关键点的角度来阐述车道检测问题,其中每个关键点都直接回归到其所属的车道,在此基础上提出了一个名为全局关联网络(GANet)的新管道。如图1c所示,每条车道线的起点都是唯一的,很容易确定,没有歧义。为了正确地关联关键点,我们估计从关键点到其相应起点的偏移量。近似起点位于同一邻域的关键点将被分配给同一车道线实例,从而将关键点分为不同的组。与以前的基于关键点的方法[21]不同,我们将关键点分配给其所属的车道是相互独立的,并使并行实现变得可行,这大大提高了后处理的效率。此外,由于每个关键点都拥有全局视图,因此关键点关联对累积的单点误差更具鲁棒性。
尽管属于同一车道线的关键点在后处理过程中被积分,但重要的是要确保相邻点之间的相关性,以获得连续的曲线。为此,我们开发了一个名为车道感知特征聚合器(LFA)的局部信息聚合模块,以增强相邻关键点之间的相关性。为了适应车道的细长形状,我们通过预测到相邻点的偏移量来修改标准2D可变形卷积[3]的采样位置,以便每次在车道上的局部区域内进行采样。通过这种方式,每个关键点的特征与其他相邻点聚合,从而获得更具代表性的特征。我们进一步添加了辅助损失,以便于估计在每个关键点上预测的偏移。我们的LFA模块补充了全局关联过程,以启用局部和全局视图,这对于车道检测等密集标记任务至关重要。
我们的贡献总结如下:
-
我们提出了一种新的全局关联网络(GANet),从一个新的基于关键点的角度来制定车道检测,该网络直接将每个关键点回归到其所属车道。据我们所知,我们是第一个以全局方式回归关键点的人,这比局部回归更有效。
-
我们开发了一个名为车道感知特征聚合器(LFA)的局部信息聚合模块,以增强相邻关键点之间的相关性,从而补充局部信息。
-
我们提出的GANet在两个流行的车道检测基准上以更快的速度实现了最先进的性能,这表明我们的全局关联公式具有卓越的性能-效率权衡和巨大的潜力。
2. 相关工作
2.1 车道检测方法
车道检测的目的是获得准确的车道线形状并区分它们。根据车道建模的方式,目前基于深度学习的方法大致可以分为几类。我们将在本节中单独阐述这些方法。
基于分割的方法。基于分割的方法将车道线检测建模为每个像素的分类问题,每个像素被分类为车道区域或背景[6,8,16,18]。为了区分不同的车道线,SCNN[18]将不同车道线视为不同的类别,从而将车道检测转化为多类别分割任务。还提出了一种逐片CNN结构,以实现消息在行和列之间的传递。为了满足实践中的实时性要求,ENet SAD[6]将自注意蒸馏机制应用于上下文聚合,以允许使用轻量级主干。LaneNet[16]采用了一种不同的车道表示方式,将车道检测作为实例分割问题。包括二进制分割分支和嵌入分支,以将分割结果分解为车道实例。与LaneNet不同,我们的方法使用偏移量而不是嵌入特征来对每条车道线进行聚类,这更高效、更省时。
基于检测的方法。这种方法通常采用自上而下的方式来预测车道线。其中,基于锚的方法[10,25,28]设计线形锚,并回归采样点和预定义锚定点之间的偏移。然后应用非最大抑制(NMS)来选择具有最高置信度的车道线。LineCNN[10]使用从具有特定方向的图像边界发射的直线射线作为一组锚点。Curve NAS[28]将锚点定义为垂直线,并进一步采用神经结构搜索(NAS)来搜索更好的主干。LaneATT[25]提出了一种基于锚点的池化方法和注意力机制,以聚合更多的全局信息。另一种方法[14,20]将车道检测公式化为按行分类问题。对于每一行,模型预测可能包含车道线的位置。
基于关键点的方法。受人体姿态估计的启发,一些工作将车道检测视为一个关键点估计和关联问题。PINet[9]使用堆叠沙漏网络[17]来预测关键点位置和特征嵌入。基于特征嵌入之间的相似性对不同的车道实例进行聚类。FOOLLANE[21]生成具有与输入相同分辨率的逐像素热图,以获得车道上的点。还开发了一种局部几何构造方式来关联属于同一车道实例的关键点。我们的GANet采用了一种更有效的后处理方法,既不需要特征嵌入,也不需要局部关联来聚类或重建整个车道。每个关键点通过以平行方式将其带有偏移的坐标添加到车道线起点来找到其对应的车道。
2.2 可变形建模
由于卷积运算的固定网格样采样范围,传统的CNN固有地局限于对不规则结构进行建模。为了克服这一限制,Dai等人[3]提出了可变形卷积来自适应地聚合局部区域内的信息。与标准卷积相比,在采样期间,在每个空间位置添加通过额外卷积获得的2D偏移,以实现采样网格的自由变形。通过学习的偏移量,根据目标的随机尺度和形状自适应地调整卷积的感受野和采样位置。可变形建模的精神已应用于许多任务,如目标检测[30,34]、目标跟踪[33]和视频理解[2,29,31]。RepPoints[30]将目标建模为一组点,并使用可变形卷积预测这些点到目标中心的偏移。这种可变形目标表示为目标检测以及自适应语义特征提取提供了精确的几何定位。Ying等人[31]提出了可变形三维卷积来探索时空信息,并实现视频超分辨率的自适应运动理解。与这些方法不同的是,我们的LFA模块适应车道线的长结构,并通过车道感知可变形卷积将特征聚合的范围限制在每条车道上的相邻点。
3. 方法
我们提出的全局关联网络(GANet)的总体架构如图2所示。给定一个前视图像作为输入,采用CNN主干和FPN[12]颈部来提取输入图像的多层次视觉表示。为了更好地进行特征学习,在主干和颈部之间进一步插入了自注意力层[27],以获得丰富的上下文信息。在解码器中,利用关键点头和偏移头分别生成置信图和偏移图。两个头都由完全卷积层组成。我们在关键点头部之前进一步设计了一个车道感知特征聚合器模块,以增强相邻关键点之间的局部相关性,从而有助于生成连续的车道线。对于每个车道实例,我们首先通过在偏移图上选择值小于1的点来获得其起点作为簇质心。然后,使用置信图和偏移图的组合,将属于同一车道的关键点聚集在采样的起点周围,以构建完整的车道线。
图2. GANet的整体架构。给定一个前视图像作为输入,使用CNN主干,然后是自注意力层(SA)和FPN颈部来提取多尺度视觉特征。在解码器中,关键点头部和偏移头部分别用于生成置信度图和偏移图,然后将其组合以将关键点聚类为若干组,每组指示车道线实例。我们的LFA模块在关键点头之前应用,以更好地捕捉车道线上的局部上下文,用于关键点估计。
References
[1] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020. 5
[2] Jingwen Chen, Yingwei Pan, Yehao Li, Ting Yao, Hongyang Chao, and Tao Mei. Temporal deformable convolutional encoder-decoder networks for video captioning. In AAAI, 2019. 3
[3] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In ICCV, 2017. 2, 3, 5
[4] Mohsen Ghafoorian, Cedric Nugteren, N´ora Baka, Olaf Booij, and Michael Hofmann. El-gan: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018. 8
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 6
[6] Yuenan Hou, Zheng Ma, Chunxiao Liu, and Chen Change Loy. Learning lightweight lane detection CNNS by self attention distillation. ICCV, 2019. 2
[7] Yuenan Hou, Zheng Ma, Chunxiao Liu, and Chen Change Loy. Learning lightweight lane detection cnns by self attention distillation. In ICCV, 2019. 7, 8
[8] Seokwoo Jung, Sungha Choi, Mohammad Azam Khan, and Jaegul Choo. Towards lightweight lane detection by optimizing spatial embedding. ECCVW, 2020. 2
[9] Yeongmin Ko, Younkwan Lee, Shoaib Azam, Farzeen Munir, Moongu Jeon, and Witold Pedrycz. Key Points Estimation and Point Instance Segmentation Approach for Lane Detection. IEEE Transactions on Intelligent Transportation Systems, 2021. 3
[10] Xiang Li, Jun Li, Xiaolin Hu, and Jian Yang. Line-cnn: End-to-end traffic line detection with line proposal unit. IEEE Transactions on Intelligent Transportation Systems, 2019. 1, 3
[11] Xiang Li, Jun Li, Xiaolin Hu, and Jian Yang. Line-cnn: Endto-end traffic line detection with line proposal unit. IEEE Transactions on Intelligent Transportation Systems, 2019. 8
[12] Tsung-Yi Lin, Piotr Doll´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 3
[13] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. In ICCV, 2017. 4
[14] Lizhe Liu, Xiaohao Chen, Siyu Zhu, and Ping Tan. Cond-lanenet: A top-to-down lane detection framework based on conditional convolution. In ICCV, 2021. 3
[15] Ruijin Liu, Zejian Yuan, Tie Liu, and Zhiliang Xiong. End-to-end lane shape prediction with transformers. In WACV, 2021. 8
[16] Davy Neven, Bert De Brabandere, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. Towards End-to-End Lane Detection: An Instance Segmentation Approach. IEEE Intelligent Vehicles Symposium, Proceedings, 2018. 2
[17] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hour-glass networks for human pose estimation. In ECCV, 2016. 3
[18] Xingang Pan, Jianping Shi, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Spatial as deep: Spatial cnn for traffic scene understanding. In AAAI, 2018. 2, 6, 7, 8
[19] Jonah Philion. Fastdraw: Addressing the long tail of lane detection by adapting a sequential prediction network. In CVPR, 2019. 7, 8
[20] Zequn Qin, Huanyu Wang, and Xi Li. Ultra fast structure-aware deep lane detection. In ECCV, 2020. 3, 7, 8
[21] Zhan Qu, Huan Jin, Yang Zhou, Zhen Yang, and Wei Zhang. Focus on local: Detecting lane marker from bottom up via key point. In CVPR, 2021. 2, 3, 6, 7, 8
[22] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 2015. 1
[23] Russell Stewart, Mykhaylo Andriluka, and Andrew Y Ng. End-to-end people detection in crowded scenes. In CVPR, 2016. 5
[24] Lucas Tabelini, Rodrigo Berriel, Thiago M Paixao, Claudine Badue, Alberto F De Souza, and Thiago Oliveira-Santos. Polylanenet: Lane estimation via deep polynomial regression. In ICPR, 2020. 8
[25] Lucas Tabelini, Rodrigo Berriel, Thiago M. Paixao, Claudine Badue, Alberto F. De Souza, and Thiago Oliveira-Santos. Keep your eyes on the lane: Real-time attention-guided lane detection. In CVPR, 2021. 1, 3, 7, 8
[26] TuSimple. Tusimple lane detection benchmark, 2017. https : / / github . com / TuSimple / tusimple -benchmark, 2017. 6
[27] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, 2017. 3
[28] Hang Xu, Shaoju Wang, Xinyue Cai, Wei Zhang, Xiaodan Liang, and Zhenguo Li. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In ECCV, 2020. 3, 7
[29] Xiangyu Xu, Muchen Li, and Wenxiu Sun. Learning deformable kernels for image and video denoising. arXiv preprint arXiv:1904.06903, 2019. 3
[30] Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and Stephen Lin. Reppoints: Point set representation for object detection. In ICCV, 2019. 3
[31] Xinyi Ying, Longguang Wang, Yingqian Wang, Weidong Sheng, Wei An, and Yulan Guo. Deformable 3d convolution for video super-resolution. IEEE Signal Processing Letters, 2020. 3
[32] Seungwoo Yoo, Hee Seok Lee, Heesoo Myeong, Sungrack Yun, Hyoungwoo Park, Janghoon Cho, and Duck Hoon Kim. End-to-end lane marker detection via row-wise classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020. 6, 7, 8
[33] Yuechen Yu, Yilei Xiong, Weilin Huang, and Matthew R Scott. Deformable siamese attention networks for visual object tracking. In CVPR, 2020. 3
[34] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR, 2020. 3