FlinkCheckpoint 问题排查
Flink Checkpoint 问题排查
1. Flink Checkpoint 流程
在使用 Flink 时, 我们基本都会用到 Checkpoint,也难免不会遇到 Checkpoint 慢或者失败等问题,如果想要排查这些问题,那么必须先知道 Checkpoint 的生产流程。一个 Task 的 Checkpoint 流程包括以下几个步骤:
-
JobManager 向 Source 算子发送 Barrier ,初始化 Checkpoint;
-
Source 算子收到 Barrier 之后,Checkpoint 自己的 State,并向下游发送 Barrier;
-
下游收到 Barrier 后,进行 Barrier Alignment 处理;
-
Task 开始同步阶段的 Snapshot;
-
Task 开始异步阶段的 Snapshot;
-
Task 做完 Checkpoint 之后,再上报 JobManager。
2. Checkpoint 监控
通过 Flink UI,我们可以看到 Flink Job 的运行状态、运行日志、Checkpoint 和反压等情况。现在我们就认识下 Flink UI 中与 Checkpoint 相关的部分,图 1 是 Flink 1.35 版本的 UI
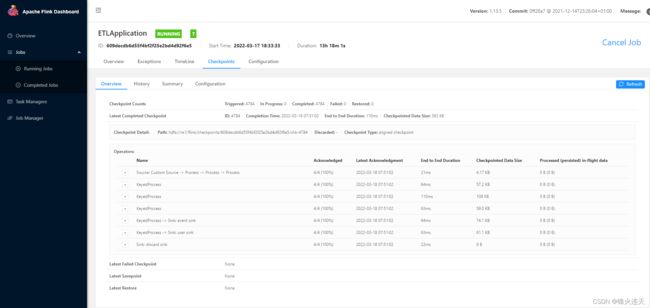
图1
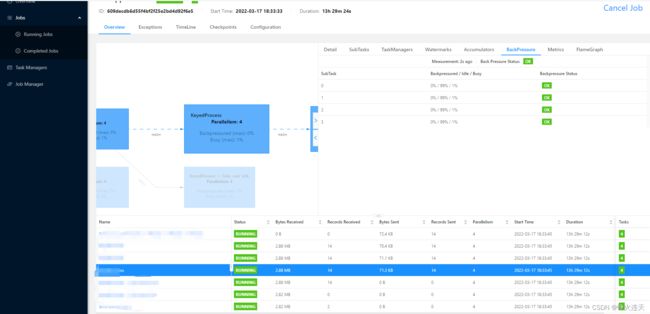
图2
其中左侧侧边栏的:
- Task Manager:可以查看各个 Task 的配置、日志、资源等相关信息;
- Job Manager:可以查看 JobManager 的配置、资源、日志等相关信息。
图 1 右侧下方与 Checkpoint 相关的主要是 Checkpoints,在排查 Checkpoint 的相关问题时,也可能会用到 Subtasks 和 Back Pressures(图 2)。
-
Subtasks:可以查看 JobGraph 的各个节点 Subtask 的吞吐量等情况,能够据此判断数据倾斜情况;
-
Back Pressures
:用于观察 JobGraph 各节点算子的反压情况,其中:
- OK: 0 <= Ratio <= 0.10
- LOW: 0.10 < Ratio <= 0.5
- HIGH: 0.5 < Ratio <= 1
-
Checkpoints:与 Checkpoint 相关的信息基本都在这里了。
-
Overview:相当于是 Checkpoint Dashboard;
-
History:各个 Checkpoint 的执行信息;
-
Summary:整个 Job 所有 Checkpoint 的 End to End Duration、State Size 和 Buffered During Alignment 的最大值、最小值和均值;
-
Configuration:Checkpoint 的配置信息,不多说了,一眼可以看到
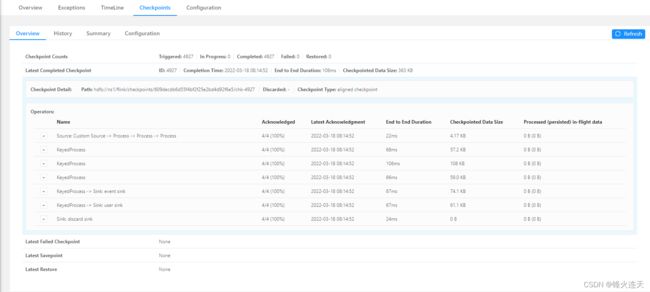
Summary 和 Configuration 比较简单就不多做赘述了,而 Overview 则如图 1 所示,比较简洁明了,需要说明的是 ID 都是 Checkpoint ID——可用于在 Task Manager 日志和 Job Manager 日志中查找对应的信息,More details 是该 Checkpoint 的生产明细信息。而 History 如图 2 所示:
-
3. Checkpoint 失败
对于追查 Checkpoint 失败的具体原因,从日志角度来说大体有这几个步骤:
- 在 Flink UI 的 Checkpoints 中,找到失败的 Checkpoint 的 ID;
- 用 Checkpoint ID 去 Job Manager 日志中,定位该 Checkpoint 失败发生的 Execution 以及 Task Manager;
- 在 Task Manager 查找该 Checkpoint 失败的具体原因。
通常情况下,Checkpoint 大概失败有两种情况:
- Checkpoint Decline
- Checkpoint Expire
3.1 Checkpoint Decline
按照前文的思路,假设我们已经在 Flink UI 中找到了失败的 Checkpoint ID 是 16883。然后,我们就去 Job Manager 日志中定位 ID 16883:
Decline checkpoint 16883 by task ab66f08bf898b7d25b4fe69bc74ce2e1 of job 7af7749825e6bef10cbd909f2746acfc
其中,ab66f08bf898b7d25b4fe69bc74ce2e1 是 Execution ID,7af7749825e6bef10cbd909f2746acfc 是当前 Job I。
然后,用 Execution ID ab66f08bf898b7d25b4fe69bc74ce2e1 在 Job Manager 日志中定位发生在哪个 Task Manager。
******** (18/36) (ab66f08bf898b7d25b4fe69bc74ce2e1) switched from SCHEDULED to DEPLOYING.
Deploying ******** (18/36) (attempt #0) to slot container_e12_1590211490022_8088_03_102035_2 on HOSTNAME
我们发现该 Execution 被调度到了 HOSTNAME 的 container_e12_1590211490022_8088_03_102035_2 Slot 上,然后再去对应的 Task Manager 中查找失败的具体原因即可。
社区还给出了另一种 Checkpoint Decline 发生在 Checkpoint Cancel 的时候:如果 Flink 在较小的 Checkpoint ID 还没有对齐的时候,收到了更大的 Checkpoint ID,则会把较小的 Checkpoint ID 给取消掉。会有如下日志
Received checkpoint barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint
这个日志表示,当前 Checkpoint 19 还在对齐阶段,就收到了 Checkpoint 20 的 Barrier。然后,会逐级通知到下游的 Task Checkpoint 19 被取消了,同时也会通知 Job Manager 当前 Checkpoint 被 Decline 了。
3.2 Checkpoint Expire
如果 Checkpoint 生产时间大于超时时间,该 Checkpoint 就会以失败而告终。按照前文的方法,假设我们已经在 Flink UI 中找到了失败的 Checkpoint ID 是 16881,接着去 Job Manager 日志中定位 ID 16881。
Checkpoint 16881 of job 7af7749825e6bef10cbd909f2746acfc expired before completing.
......
Received late message for now expired checkpoint attempt 16881 from a9c6af93c028b7d25b4fe693e4aaf09f of job 7af7749825e6bef10cbd909f2746acfc.
可以看到日志描述了,7af7749825e6bef10cbd909f2746acfc 这个 Job 的 Checkpoint 16881 在生产完成之前因超时而过期了,并且发生在 a9c6af93c028b7d25b4fe693e4aaf09f 这个 Execution 上。然后,按照上一节的步骤继续排查,就可以在 Task Manager 的日志中定位的失败的具体原因。
4. Checkpoint 慢
Checkpoint 有很多配置项,如果配置不当,会导致 Checkpoint 慢或者 Checkpoint 失败,最终都会影响应用程序的性能及稳定性。下面我们按照 Checkpoint 的流程逐一讨论。
4.1 Source Trigger Checkpoint 慢
这种情况很少见,笔者暂时还未遇到过。从资料中可以发现,因为 Source 做 Snapshot 并往下游发送 Barrier 的时候,需要抢锁(目前社区已经用 MailBox 替代当前抢锁的方式)。如果一直抢不到锁的话,则可能导致 Checkpoint 一直得不到机会进行。如果在 Source 所在的 Task Manager 日志中找不到开始做 Checkpoint 的日志,则可以考虑是否属于这种情况,可以通过 jstack 进行进一步确认锁的持有情况。
4.2 Barrier Alignment 慢
Checkpoint 时,会在 Barrier Alignment 之后进入 Snapshot 的同步阶段和异步阶段。如果应用程序 Checkpoint 时有 Barrier Alignment,而上游某些 Barrier 还未抵达,那么就无法开始产生 Snapshot,Checkpoint 也就不能继续。如果 Checkpoint 使用的是 AT_LEAST_ONCE 模式,就需要进行 Barrier Alignment。
4.3 同步阶段慢
一般情况下,同步阶段不会太慢。但是,如果我们通过 Flink UI 或日志发现同步阶段比较慢的话,对于 FsStateBackend 可以考虑查看是否开启了异步 Snapshot,如果开启了异步 Snapshot 还是慢,需要看整个 JVM 的使用情况。对于 RocksDBBackend 来说,需要用 iostate 查看磁盘的使用,另外可以查看 Task Manager 日志中关于 RocksDBBackend 的信息。
4.4 异步阶段慢
在异步阶段,Task Manager 主要将 State 持久化到存储上。对于 FsStateBackend,主要瓶颈来自于网络传输,这个阶段可以观察网络相关的 Metric,或者对应机器上能够观察到网络流量的情况。对于 RocksDBBackend,则需要从本地读取文件,写入到远程的持久化存储上,所以不仅需要考虑网络的瓶颈,还需要考虑本地磁盘的性能。如果觉得网络流量不是瓶颈,但是上传比较慢的话,还可以尝试开启多线程上传功能。
4.5 主线程没机会做 Snapshot
在 Task Manager 中,数据处理和 Barrier 处理都由主线程处理。如果主线程在处理速度太慢,就会导致 Barrier 处理慢,从而影响 Checkpoint 进度。这时候就需要使用 jstack、JProfier 或者 async-profiler 等工具分析应用层的堆栈、CPU使用情况。
4.6 Checkpoint 时间配置不当
Checkpoint 与时间相关的配置有:
- 时间间隔:env.enableCheckpointing()
- 超时时间:CheckpointConfig.setCheckpointTimeout()
- 停顿时间:CheckpointConfig.setMinPauseBetweenCheckpoints()
我们配置的目标是避免由于 Checkpoint 时间间隔过长,导致生成的 State 过大,从而使网络传输过慢;避免 Checkpoint 超时时间小于生产时间。下图描述了 Checkpoint 的时间关系。
4.7 使用增量 Checkpoint
Flink Checkpoint 有两种模式,全量 Checkpoint 和增量 Checkpoint,其中全量 Checkpoint 会把当前的 State 全部备份一次到持久化存储;而增量 Checkpoint 则只备份上一次 Checkpoint 中不存在的 State,因此增量 Checkpoint 在速度上会有更大的优势。但是,目前的 Flink 中仅 RocksDBStateBackend 支持增量 Checkpoint,如果你已经使用 RocksDBStateBackend,建议通过开启增量 Checkpoint 来加速。
4.8 反压
Flink 应用程序的反压情况可在 Flink UI 中看到
应用程序中 Subtask 被标记为 HIGH,表示此时反压很严重,同时会导致下游接受很晚才能接到 Barrier,进而拖慢 Checkpoint 进度,会引起checkpoint失败。
Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
1) Flink 1.5 之前的版本并没有对反压做特别的处理,它利用 buffer 来暂存堆积的无法处理的数据, 当 buffer 用满了,则上游的流阻塞,不再发送数据。
2) 可⻅此时的反压是从下游往上游传播的,一直往上传播到 Source Task 后,Source Task 最终会降低或提升从外部 Source 端读取数据的速率。
这种机制有一个比较大的问题,在这样的一个场景下:如果一个TaskManager中有多个Task,只要其中一个Task A触发了反压机制,但是Task B是正常的,此时Task A和Task B对于上游数据的获取是来自不同的TaskManager,两个Task是共享一个网络传输的TCP信道,A的反压会导致这个公用的TCP信道阻塞,会导致Task B也接受不到上游的数据了。
基于TCP的流控和反压方案有两大缺点:
- 只要TaskManager执行的一个Task触发反压,该TaskManager与上游TaskManager的Socket就不能再传输数据,从而影响到所有其他正常的Task,
以及Checkpoint Barrier的流动,可能造成作业雪崩;
- 反压的传播链路太长,且需要耗尽所有网络缓存之后才能有效触发,延迟比较大。
Flink 1.5 版本之后的基于 Credit 反压机制解决了上述问题。这种机制主要是每次上游 SubTask 给下游 SubTask 发送数据时,会把 Buffer 中的数据和上游 ResultSubPartition 堆积的数据量Backlog size 发给下游,下游会接收上游发来的数据,并向上游反馈目前下游现在的 Credit 值, Credit 值表示目前下游可以接收上游的 Buffer 量,
1 个 Buffer 等价于 1 个 Credit。可⻅,这种策略上游向下游发送数据是按需发送的,
而不是和之前一样会在公用的 Netty 和 TCP 这一层数据堆积,避免了影响其他 SubTask 通信的问题。
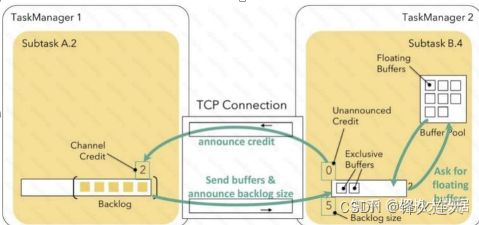
1)上游 SubTask A 向下游的 SubTask B 发送数据并告诉 SubTask B 还积压了 5 个 buffer(Backlog size=5)的数据。
2)SubTask B 接受到数据后,得知上游还有 5 个 buffer 需要发过来,于是向 Buffer Pool 申请Buffer,但是容量不足,仅申请到 2 个 Buffer 空间。
3)此时 SubTask B 会向上游反馈 Credit=2,代表下游最多只能接收 2 个 buffer 了。
4)SubTask A 收到反馈消息后得知空间不足,所以最多只给会下游发送 2 个 Buffer 的数据。
5)这样每次上游发送的数据都是下游 Buffer 可以承受的数据量,而不会在 TCP 信道阻塞,影响其他SubTask 通信。
4.9 数据倾斜
无论是离线计算(包括 SQL、Code),还是实时计算(包括 SQL、Code),数据倾斜(Data Skew)都是不得不面对的一个问题。而且实时计算的数据倾斜解决方案,要比离线计算的解决方案要复杂一些。虽然发生数据倾斜有很多种情况,不过,其解决方案的思想确实大同小异
对于 Flink 应用程序,我们可以在 Flink UI 中看观察是否有 Subtask 发生了数据倾斜。通过 Subtask 的 Records Received、Bytes Received 这类 TPS 指标,就可以知道哪些 Subtask 处理的数据量较大,即哪些 Subtask 发生了数据倾斜。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XMpVozIS-1647820943165)(C:\Users\songzhan\AppData\Roaming\Typora\typora-user-images\image-20220318082925827.png)]
5. 总结
Checkpoint 是 Flink 比较核心的特性,也是经常用到的特性,所以难免会遇到 Checkpoint 慢或者失败等问题,本文介绍了如何查看 Checkpoint 的各项指标,怎样定位 Checkpoint 失败的根因,以及导致 Checkpoint 慢的因素。
发生了数据倾斜。
[外链图片转存中…(img-XMpVozIS-1647820943165)]
5. 总结
Checkpoint 是 Flink 比较核心的特性,也是经常用到的特性,所以难免会遇到 Checkpoint 慢或者失败等问题,本文介绍了如何查看 Checkpoint 的各项指标,怎样定位 Checkpoint 失败的根因,以及导致 Checkpoint 慢的因素。