多轮对话(二):多轮对话理解的研究进展和主流方法
本文是基于 Advances in Multi-turn Dialogue Comprehension: A Survey。这是一篇综述论文,我也顺便总结一下像我一样的小白,怎么读综述好一些。我读综述是为了快速切入某领域,比如我以前做的是跨模态检索,现在要进入对话系统,那么我可以去读几篇综述,来了解当前该领域的研究进展和主流方法。在找综述时,不应该查找过于具体的细分方向,可以从大角度出发,不仅论文会多一些,而且可以了解其他方向的方法,为日后研究提供思路。
一、Introduction
在对话系统发研究中,最基本但也最具挑战性的任务类型是对话理解,其作用是教会机器在做出回应之前阅读和理解对话上下文。对比纯文本阅读理解,我们总结了对话理解的特点和挑战,并讨论了对话建模的三种典型模式。
建立一个能够与人类进行自然而有意义的交流的智能对话系统是人工智能(AI)的一个长期目标,由于其潜在的影响力和诱人的商业价值,它已经引起了学术界和工业界越来越多的兴趣。
然而,这一领域的增长受到数据稀缺问题的阻碍,因为这些系统预计将从数量不足的高质量语料库中学习语言知识、决策和问题回答。为了缓解这种稀缺性,人们提出了各种各样的任务,如响应选择,基于对话的问答(QA),决策和问题生成。

随着深度学习方法的发展,神经模型的能力得到了极大的提升。然而,大多数研究都集中在响应检索或生成等单个任务上。在构建更有效和更全面的系统来解决现实世界问题的兴趣的刺激下,这些任务倾向于在形式上交叉和统一。我们可以用对话理解的一般形式来看待主要的对话任务:给定上下文,需要一个系统来理解上下文,然后reply或answer问题,可以从检索或生成中获得应答。
早期技术主要关注对话上下文的成对序列与候选回答之间的匹配机制。最近,PrLMs对包括对话理解在内的各种下游NLP任务(BERT)显示了令人印象深刻的评估结果。他们将整个文本作为连续符号的线性序列处理,并通过自我关注捕获这些符号的上下文化表示。通过这些语言模型得到的词嵌入是在大型语料库上进行预训练的。这些预训练的模型提供了细粒度的上下文嵌入,可以轻松地作为编码器应用于下游模型,也可以用于微调。并且为预训练设计对话驱动的自我监督任务方面也出现了兴趣。
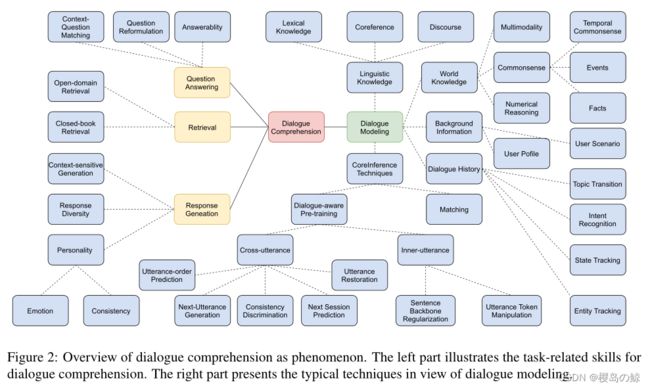
在本次调查中,我们从对话任务建模为两阶段编码器-解码器框架的角度回顾了前人对对话理解的研究,通过这种方式弥合了对话建模和理解之间的差距。
二、Characteristics of Dialogues
与SQuAD这样的纯文本阅读理解相比,多回合对话直观地与口语语言联系在一起,而且也是互动的,涉及多个说话人、意图、主题,因此话语充满过渡。
- Speaker interaction
对话中说话人的转换是随机的,由于在多人聊天中常见的交叉依赖关系的存在,打破了在普通非对话文本中的连续性。 - Topic Transition
在一个对话历史中可能会同时出现多个对话主题,在口语对话中,话题漂移是很常见的。因此,多方对话出现了非相邻话语之间的话语依赖关系,从而形成了复杂的话语结构。 - Colloquialism
对话是口语化的,导致对话语境中存在丰富的成分省略和信息冗余。然而,在对话中,说话者不能收回已经说过的话,这很容易导致自相矛盾,需要更多的上下文,特别是澄清,以充分理解对话。 - Timeliness
每个话语对预期回答的重要性是不同的,这使得话语对最终回答的贡献具有巨大的多样性。因此,话语的顺序影响着对话的建模。一般来说,最新的言论会更具有判别性(Multi-turn dialogue reading comprehension with pivot turns and knowledge)。
三、Methodology
1. Problem Formulation
虽然现有的对话理解研究通常为每个下游任务设计独立的系统,但我们发现对话系统通常可以被表述为Encoder-Decoder框架,其中编码器用于理解对话上下文,解码器用于给出响应。我们可以得出这样的观点,对话理解任务,特别是对话生成,与机器翻译具有本质的相似性,从这种统一的建模观点可以帮助开发更好的翻译和对话生成模型。
数据集 D = { ( C i , X i ; Y i ) } i = 1 N D=\{(C_i, X_i; Y_i)\}^N_{i=1} D={(Ci,Xi;Yi)}i=1N,其中 C i = { u i , 1 , . . . , u n i } C_i=\{u_{i,1},...,u_{n_i}\} Ci={ui,1,...,uni}表示 { u i , k } k = 1 n i \{u_{i,k}\}^{n_i}_{k=1} {ui,k}k=1ni作为utterances的对话上下文, X i X_i Xi是特定于任务的配对输入, Y i Y_i Yi表示模型的预测。
2. Dialogue Modeling Framework
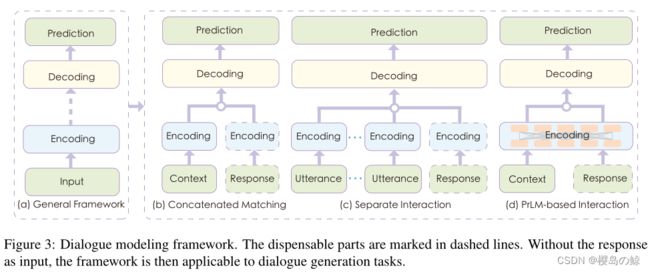
我们从将对话任务建模为两阶段编码器-解码器框架的角度回顾了前人对对话理解的研究。对话建模方法可分为三种模式:1) 串联匹配;2) 单独交互;3) 基于PrLM的交互。
- Concatenated Matching
早期的方法将对话上下文作为一个整体,将之前的所有话语和最后的话语串联起来作为上下文表示,然后根据上下文表示计算匹配度得分,对候选响应进行编码。
E C = E n c o d e r ( C ) EC=Encoder(C) EC=Encoder(C)
E R = E n c o d e r ( R ) ER=Encoder(R) ER=Encoder(R)
Y = D e c o d e r ( E C ; E R ) Y=Decoder(EC;ER) Y=Decoder(EC;ER) - Separate Interaction
随着以注意力为基础的成对匹配机制的兴起,研究人员很快发现,通过计算对话上下文和反应之间不同程度的互动,这种机制是有效的。(在单词水平和话语水平上使用多视图模型进行上下文-响应匹配、通过将响应与上下文中的每个话语匹配来捕获话语关系和上下文信息)
E U i = E n c o d e r ( u i ) EU_i=Encoder(u_i) EUi=Encoder(ui)
E R = E n c o d e r ( R ) ER=Encoder(R) ER=Encoder(R)
I = A T T ( [ E U 1 , . . . , E U n ] ; E R ) I=ATT([EU_1,...,EU_n];ER) I=ATT([EU1,...,EUn];ER)
Y = D e c o d e r ( I ) Y=Decoder(I) Y=Decoder(I) - PrLM-base Interaction
PrLM将整个输入文本作为连续标记的线性序列处理,并通过自我关注隐式捕获这些标记的上下文化表示。给定上下文C和响应R,我们将上下文和响应候选中的所有话语连接为一个单独的连续标记序列,并使用特殊的标记将它们分开,然后通过PrLM对文本序列进行编码:
E C = E n c o d e r ( [ C L S ] C [ S E P ] R [ S E P ] ) EC=Encoder([CLS]C[SEP]R[SEP]) EC=Encoder([CLS]C[SEP]R[SEP])
Y = D e c o d e r ( E C ) Y=Decoder(EC) Y=Decoder(EC)
在缺乏计算源的早期研究阶段,级联匹配具有效率的优势,它以简单的结构将上下文作为一个整体进行编码,并直接将其馈送到解码器。随着注意机制的迅速普及,由于细粒度的基于注意的交互可以充分捕捉话语之间以及话语与反应之间的关系,分离交互已经成为主流,并且通常比串联匹配更好。基于PrLM的模型通过在上下文和响应上进行多层逐字交互,进一步扩展了交互的优势。
然而,后两种基于交互的方法由于计算量大,在实际应用中效率较低。受到最近关于密集检索的研究( Dense passage retrieval for open-domain question answering、Smoothing dialogue states for open conversational machine reading)的启发,以及对话历史经常被重复使用的事实,一个潜在的解决方案是预先计算它们的表示,以用于后面的索引,这允许在生产设置中进行快速实时推理,提高准确性和速度之间的平衡。
3. Dialogue-related Pre-training
尽管PrLMs在自我监督的预训练中表现出了强大的表现能力,但在详细的任务特定训练中有效地捕获任务相关知识仍然具有挑战性。一般来说,直接使用PrLMs来建模对话任务是次优的,因为它包含了纯文本的PrLMs训练可能很难体现的独家文本特征。因此,一些研究者试图在域内对话文本上进一步用通用语言建模(LM)目标对PrLMs进行预训练。(Structural pre-training for dialogue comprehension.)
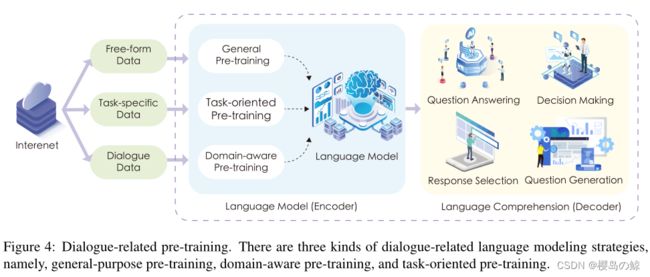
虽然NSP在RoBERTa的通用预训练中被证明是微不足道的,但它在对话场景中产生了惊人的收益(Task-specific Objectives of Pre-trained Language Models for Dialogue Adaptation)。最合理的理由是,对话强调对话上下文与后续反应之间的相关性,这与NSP的目标相似。尽管这些方法具有流畅性的优势,但也有批评指出,它们往往存在factual incorrectness和hallucination of knowledge(Recipes for building an open-domain chatbot)。一个潜在的解决方案是检索相关知识和对话转折条件(Retrieval Augmentation Reduces Hallucination in Conversation)。
与PrLMs的重点纯文本建模相比,对话文本涉及多个说话人,并反映出主题过渡和结构话语依赖等特殊特征。从话语交叉和话语内两方面来看,有两类研究。Cross-utterance:以往的工作表明,顺序信息在文本表示中很重要,而众所周知的NSP和SOP可以看作是顺序预测的特例。Whang等人提出了各种话语操作策略,包括话语插入、删除和搜索,以保持对话连贯性(Do response selection
models really know what’s next? utterance manipulation strategies for multi-turn response selection)。Inner-utterance:这一类型的目标一直没有引起太多的关注。直觉是在话语中模拟事实和事件。Zhang和Zhao引入了一个句子主干正则化任务作为正则化,以提高总结的主谓宾三连词的事实正确性( Structural pre-training for dialogue comprehension)。
四、Dialogue Comprehension with Explicit Knowledge
对话上下文口语化和信息不完整,需要机器在反映相关细节的同时提炼关键信息。如果没有背景知识作为参考,机器可能只能从对话上下文或查询的表面文本中捕获有限的信息。这样的知识并不局限于主题、情感和多模态对齐(multimodal grounding)。这些来源可以提供文本对话上下文之外的额外信息,以增强对对话的理解。
- Auxiliary Knowledge Grounding
语言知识已被证明对对话建模很重要,比如句法,话语信息,常识项,领域知识,从知识图中增强推理能力、于人物属性如说话人身份、对话主题、说话人情绪等来丰富对话语境。(Dialogue graph modeling for conversational machine reading,Multi-turn dialogue reading comprehension with pivot turns and knowledge) - Emotional Promotion
情感感受或情感是区分人与机器的关键特征。人的情感是复杂的,在对话中存在着隐喻、反讽等各种复杂的情感特征。此外,同样的表达在不同的情况下可能有不同的含义。对话系统不仅应该捕捉用户意图、话题转换和对话结构,还应该能够感知情绪变化,甚至根据用户的情绪状态调整语气和引导对话,以提供更友好、更可接受和更有同情心的对话,这对于构建社交机器人和自动电子商务营销尤其有用。 - Multilingual and Multimodal Dialogue
对话系统作为人机交互的自然界面,有利于不同语言背景的人之间的交流。除了自然语言文本外,视觉和音频资源也是有效的载体,可以与文本相结合,进行全面、沉浸式的对话。随着多语种的快速发展和多模态研究,构建智能对话系统在未来并非遥不可及。(Aspect-aware response generation
for multimodal dialogue system,Cosda-ml: Multi-lingual code-switching data augmentation for zero-shot cross-lingual NLP)
五、Empirical Analysis
1. Dataset
- Ubuntu
- Douban
- ECD
Modeling multi-turn conversation with deep utterance aggregation
数据集是从电子商务平台上客户与服务人员之间的对话中提取的。它包含基于20多个商品的超过5种类型的对话。在训练集中还有100万个上下文-响应对,在验证集中有50万个,在测试集中有50万个。 - Mutual
MuTual: A dataset for multi-turn dialogue reasoning
由8860个基于中国学生英语听力考试的手动注释对话组成。对于每个上下文,有一个积极的回答和三个消极的回答。与上述三个数据集相比,只有MuTual是基于推理的。MuTual中体现了6种以上的推理能力。 - DREAM
DREAM: A challenge data set and models for dialogue-based reading comprehension
是一个基于对话的多选题阅读理解数据集,它是从英语考试中收集的。在给定的语境下,每个对话有多个问题,每个问题有三个回答选项。总共包含6444个对话和10197个问题。数据集最重要的特征是,超过80%的问题是非提取性的,超过三分之一的给定问题涉及常识性知识。因此,数据集很小,但相当具有挑战性。
2. Evaluation Metrics
根据Lowe等人(The Ubuntu dialogue corpus: A large dataset for research in unstructured multiturn dialogue systems)的研究,我们计算了从一个上下文的n个可用候选列表中选出的前k个响应中真实积极响应的比例,记为Rn@k。对于基于对话的QA任务DREAM,官方的度量标准是准确性(Acc)。
3. Observations
原文中有有很多实验结果的表格,可以前往原文中查看。如下是一些观察结果,具有参考意义:
- 交互方法通常比单轮模型产生更好的性能
在没有PrLMs的早期阶段,separate interaction通常比简单的串联匹配获得更好的性能,验证了基于注意的成对匹配的有效性。然而,多回合匹配网络(separate interaction)比基于PrLMs的网络表现得更差,说明了上下文化表示在上下文敏感对话建模中的力量。 - 对话相关的预训练有助于PrLMs更好地适应对话理解
- 基于检索或判别的方法胜过生成方法
- 从负抽样中进行数据扩充,是扩大语料库规模、提高响应质量的重要方法
- 语境分解有助于发现基本的对话结构
Filling the Gap of Utterance-aware and Speaker-aware Representation for Multi-turn Dialogue 表明对说话人信息建模对于对话建模是有效的。
Explicit memory tracker with coarse-to-fine reasoning for conversational machine reading、Discern: Discourse-aware entailment reasoning network for conversational machine reading、Dialogue graph modeling for conversational machine reading 表明将对话上下文解解为基本话语单元(edu),并对edu之间的图状关系进行建模,将有效地捕捉复杂对话的内部话语结构。 - 额外的知识注入进一步改善了对话建模
六、Frontiers of Training Dialogue Comprehension Models
1. Dialogue Disentanglment Learning
最近广泛使用的基于PrLMs的模型处理整个对话,这会导致纠缠原本属于不同部分的信息,并不是对话建模的最佳选择。序列解耦(Sequence decoupling)是一种解决这个问题的策略,它通过显式地将上下文分离为不同的部分,并进一步构造这些部分之间的关系来产生更好的细粒度表示。
一个可能的解决方案是将上下文分成几个主题块(Topic-aware multi-turn dialogue modeling、Improving contextual language models for response retrieval in multi-turn conversation)。但是,存在主题交叉,会影响分割效果。另一种方案是在自注意网络中采用掩蔽机制,将每个单词的焦点限制在相关的单词上(Filling the Gap of Utterance-aware and Speaker-aware Representation for Multi-turn Dialogue),以建模局部依赖关系,以补充PrLMs的全局上下文化表示。此外,最近的研究表明,明确地建模话语结构和行动三元组对于提高对话理解是有效的( Discern: Discourse-aware entailment reasoning network for conversational machine reading、Structure-aware abstractive conversation summarization via discourse and action graphs)。
2. Dialogue-aware Language Modeling
最近的研究表明,与对话相关的语言建模可以极大地提高对话理解能力。然而,这些方法依赖于对话式语料库进行预训练,这在一般应用场景中并不总是可用的。鉴于互联网上海量的自由形式和无领域数据,如何利用通用和通用领域的数据进行对抗性的会话模拟是一个很有前景的研究方向。除了从通用建模到对话感知建模,多域自适应(multi-domain adaption)是另一个重要的主题,它可以有效地降低注释成本,实现健壮和可扩展的对话系统( Dynamic fusion network for multi-domain end-to-end task-oriented dialog)。
3. High-quality Negative Sampling
以往的研究大多是用简单的启发式方法构造训练数据来训练对话理解模型。他们把人写的回答作为积极的例子,从其他对话环境中随机取样的回答作为同样糟糕的消极例子。随机抽样的消极回答往往过于琐碎,使得模型无法处理对话理解的强干扰因素。为了训练一个更有效、更可靠的模型,人们对挖掘更好的训练数据越来越感兴趣( The world is not binary: Learning to rank with grayscale data for dialogue response selection、Dialogue response selection with hierarchical curriculum learning)。
七、Open Challenge
- Temporal Reasoning
日常对话中有丰富的事件,这反过来需要理解与这些事件交织在一起的时间常识概念,如持续时间、频率和顺序。有初步的尝试来调查时间特征,如话语顺序和主题流。然而,这样的特征太肤浅,无法揭示事件的推理链。 - Logic Consistency
逻辑在对话系统中至关重要,它不仅保证了应答的一致性和意义,而且加强了具有逻辑推理能力的模式。现有的基于交互的方法通常侧重于捕捉对话上下文和响应之间的语义相关性,但通常忽略了对话过程中的逻辑一致性,这是反映在对话模型中的一个关键问题。 - Large-scale Open-retrieval
当前主流的对话任务往往假设为用户查询提供对话上下文或背景信息。在现实场景中,系统需要检索各种类型的相关信息,例如从大型语料库中检索相似的对话历史,或者从知识库中检索必要的支持证据,以交互式地响应查询。因此,如何检索准确的、一致的、语义上有意义的证据是至关重要的。与开放域QA任务相比,开放检索对话的人机交互特性对效率和效果提出了新的挑战。 - Dialogue for Social Good
为了有效地解决对话任务,我们通常配备了具体而准确的信息,其中的数据集通常是从需要大量人力的现实对话历史中抓取的。域迁移是制约对话系统实际应用的一个长期难题,至今仍未得到解决。由于缺乏商业利益或缺乏注释数据,有许多领域没有得到足够的重视。此外,对低资源社区的关注较少,英语社区之外的高质量对话语料库普遍匮乏。