决策树的过拟合问题
决策树是一种分类器,通过ID3,C4.5和CART等算法可以通过训练数据构建一个决策树。但是,算法生成的决策树非常详细并且庞大,每个属性都被详细地加以考虑,决策树的树叶节点所覆盖的训练样本都是“纯”的。因此用这个决策树来对训练样本进行分类的话,你会发现对于训练样本而言,这个树表现完好,误差率极低且能够正确得对训练样本集中的样本进行分类。训练样本中的错误数据也会被决策树学习,成为决策树的部分,但是对于测试数据的表现就没有想象的那么好,或者极差,这就是所谓的过拟合(Overfitting)问题。
决策树的剪枝
决策树的剪枝有两种思路:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)
预剪枝(Pre-Pruning)
在构造决策树的同时进行剪枝。所有决策树的构建方法,都是在无法进一步降低熵的情况下才会停止创建分支的过程,为了避免过拟合,可以设定一个阈值,熵减小的数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。但是这种方法实际中的效果并不好。
后剪枝(Post-Pruning)
决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否小于某一阈值。如果确实小,则这一组节点可以合并一个节点,其中包含了所有可能的结果。后剪枝是目前最普遍的做法。
后剪枝的剪枝过程是删除一些子树,然后用其叶子节点代替,这个叶子节点所标识的类别通过大多数原则(majority class criterion)确定。所谓大多数原则,是指剪枝过程中, 将一些子树删除而用叶节点代替,这个叶节点所标识的类别用这棵子树中大多数训练样本所属的类别来标识,所标识的类 称为majority class ,(majority class 在很多英文文献中也多次出现)。
后剪枝算法
后剪枝算法有很多种,这里简要总结如下:
Reduced-Error Pruning (REP,错误率降低剪枝)
这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
Pessimistic Error Pruning (PEP,悲观剪枝)
PEP剪枝算法是在C4.5决策树算法中提出的, 把一颗子树(具有多个叶子节点)用一个叶子节点来替代(我研究了很多文章貌似就是用子树的根来代替)的话,比起REP剪枝法,它不需要一个单独的测试数据集。
PEP算法首先确定这个叶子的经验错误率(empirical)为(E+0.5)/N,0.5为一个调整系数。对于一颗拥有L个叶子的子树,则子树的错误数和实例数都是就应该是叶子的错误数和实例数求和的结果,则子树的错误率为e,这个e后面会用到

子树的错误率
然后用一个叶子节点替代子树,该新叶子节点的类别为原来子树节点的最优叶子节点所决定(这句话是从一片论文看到的,但是论文没有讲什么是最优,通过参考其他文章,貌似都是把子树的根节点作为叶子,也很形象,就是剪掉所有根以下的部分),J为这个替代的叶子节点的错判个数,但是也要加上0.5,即KJ+0.5。最终是否应该替换的标准为:
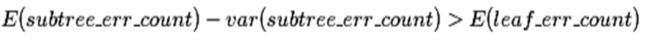
被替换子树的错误数-标准差 > 新叶子错误数
出现标准差,是因为我们的子树的错误个数是一个随机变量,经过验证可以近似看成是二项分布,就可以根据二项分布的标准差公式算出标准差,就可以确定是否应该剪掉这个树枝了。子树中有N的实例,就是进行N次试验,每次实验的错误的概率为e,符合B(N,e)的二项分布,根据公式,均值为Ne,方差为Ne(1-e),标准差为方差开平方。
(二项分布的知识在文章最后)
网上找到这个案例,来自西北工业大学的一份PPT,我个人觉得PPT最后的结论有误
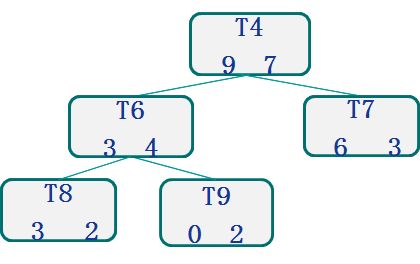
PEP案例
这个案例目的是看看T4为根的整个这颗子树是不是可以被剪掉。
树中每个节点有两个数字,左边的代表正确,右边代表错误。比如T4这个节点,说明覆盖了训练集的16条数据,其中9条分类正确,7条分类错误。
我们先来计算替换标准不等式中,关于子树的部分:
子树有3个叶子节点,分别为T7、T8、T9,因此L=3
子树中一共有16条数据(根据刚才算法说明把三个叶子相加),所以N=16
子树一共有7条错误判断,所以E=7
那么根据e的公式e=(7+0.5×3)/ 16 = 8.5 /16 = 0.53
根据二项分布的标准差公式,标准差为(16×0.53×(1-0.53))^0.5 = 2.00
子树的错误数为“所有叶子实际错误数+0.5调整值” = 7 + 0.5×3 = 8.5
把子树剪枝后,只剩下T4,T4的错误数为7+0.5=7.5
这样, 8.5-2 < 7.5, 因此不满足剪枝标准,不能用T4替换整个子树。
Cost-Complexity Pruning(CCP,代价复杂度剪枝)
CART决策树算法中用的就是CCP剪枝方法。也是不需要额外的测试数据集。
Minimum Error Pruning(MEP)
Critical Value Pruning(CVP)
Optimal Pruning(OPP)
Cost-Sensitive Decision Tree Pruning(CSDTP)
。
附录
二项分布 Binomial Distribution
考察由n次随机试验组成的随机现象,它满足以下条件:
重复进行n次随机试验;
n次试验相互独立;
每次试验仅有两个可能结果;
每次试验成功的概率为p,失败的概率为1-p。
在上述四个条件下,设X表示n次独立重复试验中成功出现的次数,显然X是可以取0,1,…,n等n+1个值的离散随机变量,且它的概率函数为:
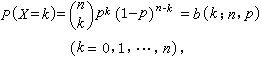
二项分布概率公式
这个分布称为二项分布,记为b(n,p)。
二项分布的均值:E(X)=np
二项分布的方差:Var(X)=np(1-p)。
标准差就是方差开平方
举个例子比较好理解。扔好多次硬币就是一个典型的二项分布,符合四项条件:
扔硬币看正反面是随机的,我们重复进行好多次,比如扔5次
每次扔的结果没有前后关联,相互独立
每次扔要么正面,要么反面
每次正面(看作成功)概率1/2, 反面(看作失败)概率1-1/2 = 1/2 ,即这里p=0.5
于是这个实验就符合B(5,0.5)的二项分布。那么计算扔5次硬币,出现2次正面的概率,就可以带入公式来求:
P(X=2)= C(5,2)×(0.5)2×(0.5)3 = 31.25%
这个实验的的期望(均值)为np=5×0.5=2.5,意思是:每扔5次,都记录正面次数,然后扔了好多好多的“5次”,这样平均的正面次数为2.5次
这个实验的方差为np(1-p)=5×0.5×0.5=1.25,表示与均值的误差平方和,表示波动情况。
多说一句,二项分布在n很大时,趋近于正态分布。
作者:程sir
链接:https://www.jianshu.com/p/794d08199e5e
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。