【计算机视觉|生成对抗】条件生成对抗网络(CGAN)
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:Conditional Generative Adversarial Nets
链接:[1411.1784] Conditional Generative Adversarial Nets (arxiv.org)
摘要
生成对抗网络(Generative Adversarial Nets)[8] 最近被引入为训练生成模型的一种新颖方法。
在这项工作中,我们介绍了生成对抗网络的条件版本,通过简单地将我们希望依赖的数据 y y y同时提供给生成器和判别器,就可以构建它。我们展示了这个模型可以生成依据类标签条件化的MNIST数字。
我们还说明了如何使用这个模型学习一个多模态模型(multi-modal model),并提供了一个初步的图像标记应用示例,在其中我们展示了如何使用这种方法生成并不是训练标签部分的描述性标签。
1 引言
生成对抗网络最近被引入为训练生成模型的一种替代框架,以便绕过许多难以处理的概率计算的困难。
对抗网络具有以下优势:
-
从不需要马尔可夫链,仅使用反向传播来获取梯度
-
学习过程中不需要推理,而且
-
各种因素和相互作用都可以轻松纳入模型中
此外,正如[8]中所展示的,它可以产生最先进的对数似然估计和逼真的样本。
在一个无条件的生成模型中,生成数据的模式没有控制。
然而,通过在模型上附加额外的信息进行条件化,就可以引导数据生成过程。这种条件化可能基于类标签,像[5]那样基于部分数据进行修补,甚至基于不同的模态数据。
在这项工作中,我们展示了如何构建条件生成对抗网络。至于实证结果,我们展示了两组实验。一组是基于类标签的MNIST数字数据集,另一组是用于多模态学习的MIR Flickr 25,000数据集[10]。
2 相关工作
2.1 针对图像标记的多模态学习
尽管监督神经网络(特别是卷积网络)[13, 17]近来取得了许多成功,但将这些模型扩展以容纳极大数量的预测输出类别仍然具有挑战性。第二个问题是迄今为止的大部分工作都集中在学习输入到输出的一对一映射。然而,许多有趣的问题更自然地被认为是概率性的一对多映射。例如,在图像标记的情况下,可能有许多不同的标签可以适当地应用于给定的图像,不同的(人类)注释者可能使用不同的(但通常是同义或相关的)术语来描述同一图像。
-
解决第一个问题的一种方法
- 是利用其他模态的附加信息:例如,使用自然语言语料库学习标签的向量表示,其中几何关系在语义上有意义。
- 在这样的空间中进行预测时,我们从事实中受益,即当预测错误时,我们仍然通常接近真相(例如,预测“桌子”而不是“椅子”),并且也从我们可以自然地对训练期间未见过的标签进行预测概括的事实中受益。
- 诸如[3]的作品已经表明,即使是从图像特征空间到单词表示空间的简单线性映射也可以提高分类性能。
-
解决第二个问题的一种方法
- 是使用条件概率生成模型,输入被视为条件变量,一对多映射被实例化为条件预测分布。
- [16]对此问题采取了类似的方法,并在MIR Flickr 25,000数据集上训练了一种多模态深度玻尔兹曼机,就像我们在这项工作中所做的那样。
此外,在[12]中,作者展示了如何训练一种受监督的多模态神经语言模型,并且他们能够为图像生成描述性句子。
3 条件生成对抗网络
3.1 生成对抗网络
生成对抗网络最近被引入作为训练生成模型的一种新颖方法。
它们由两个“对抗”的模型组成:一个生成模型G,用于捕获数据分布;和一个判别模型D,用于估计样本来自训练数据还是G的概率。G和D都可以是非线性映射函数,例如多层感知器。
为了学习生成器分布 p g p_g pg在数据 x x x上的分布,生成器从先验噪声分布 p z ( z ) p_z(z) pz(z)构建到数据空间的映射函数 G ( z ; θ g ) G(z; \theta_g) G(z;θg)。而判别器 D ( x ; θ d ) D(x; \theta_d) D(x;θd)输出一个标量,表示 x x x来自训练数据而不是 p g p_g pg的概率。
G和D都同时进行训练:我们调整G的参数以使 log ( 1 − D ( G ( z ) ) \log(1 - D(G(z)) log(1−D(G(z))最小化,并调整D的参数以使 log D ( X ) \log D(X) logD(X)最小化,就好像它们在遵循具有值函数 V ( G , D ) V(G, D) V(G,D)的两玩家极小极大博弈:
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] 。 (1) \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z)))]。 \tag{1} GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]。(1)
3.2 条件生成对抗网络
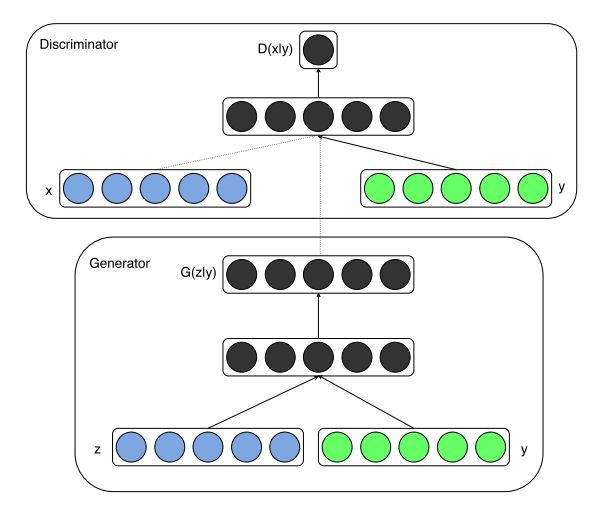
生成对抗网络可以扩展到条件模型,如果生成器和判别器都基于一些额外的信息 y y y进行条件化。 y y y可以是任何类型的辅助信息,例如类标签或来自其他模态的数据。我们可以通过将 y y y作为附加的输入层输入到判别器和生成器中来执行条件化。
在生成器中,先验输入噪声 p z ( z ) p_z(z) pz(z)和 y y y结合在联合隐藏表示中,而对抗训练框架允许在组成这个隐藏表示方面具有相当大的灵活性。1
在判别器中, x x x和 y y y被呈现为输入,并输入到判别函数(在这种情况下再次由MLP体现)。
两个玩家极小极大博弈的目标函数将与等式2相同
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ∣ y ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ∣ y ) ) ) ] 。 (2) \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)} [\log D(x|y)] + \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z|y)))]。 \tag{2} GminDmaxV(D,G)=Ex∼pdata(x)[logD(x∣y)]+Ez∼pz(z)[log(1−D(G(z∣y)))]。(2)
图1说明了一个简单条件对抗网络的结构。
图1:条件生成对抗网络
4 实验结果
4.1 单模态
我们在MNIST图像上训练了一个条件生成对抗网络,并基于它们的类标签进行条件化,以one-hot向量进行编码。
在生成器网络中,从单位超立方体中均匀分布抽取了一个具有100个维度的噪声先验 z z z。 z z z和 y y y都被映射到具有整流线性单元(ReLu)激活[4, 11]的隐藏层,层大小分别为200和1000,然后再被映射到维度为1200的第二个组合隐藏ReLu层。然后我们有一个最终的Sigmoid单元层作为生成784维MNIST样本的输出。
判别器将 x x x映射到具有240个单元和5个部分的maxout [6]层,并将 y y y映射到具有50个单元和5个部分的maxout层。在被送入Sigmoid层之前,两个隐藏层都映射到一个具有240个单元和4个部分的联合maxout层。(判别器的确切架构并不关键,只要它具有足够的能力;我们发现maxout单元通常适合这项任务。)
该模型使用具有大小为100的小批量和初始学习率0.1的随机梯度下降进行训练,该学习率以1.00004的衰减因子呈指数递减至0.000001。初始动量为0.5,增加到0.7。Dropout [9]概率为0.5应用于生成器和判别器。并以验证集上的对数似然的最佳估计作为停止点。
表1显示了用于MNIST数据集测试数据的高斯Parzen窗口对数似然估计。从每个10个类别中抽取1000个样本,并对这些样本拟合高斯Parzen窗口。然后我们使用Parzen窗口分布估计测试集的对数似然。(有关如何构建此估计的更多详细信息,请参见[8]。)
表1:基于Parzen窗口的MNIST对数似然估计。我们遵循了与[8]相同的程序来计算这些值。
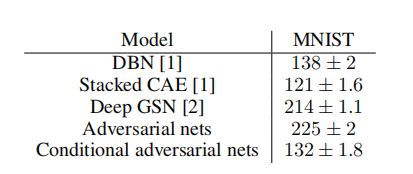
我们展示的条件生成对抗网络结果与其他一些基于网络的结果相当,但被其他几种方法所超过,包括非条件生成对抗网络。我们更多地将这些结果作为概念验证而非有效性展示,并相信通过进一步探索超参数空间和架构,条件模型应当匹配或超过非条件结果。
图2显示了一些生成的样本。每一行都以一个标签为条件,每一列都是一个不同的生成样本。
图2:生成的MNIST数字,每一行都是基于一个标签

4.2 多模态
像Flickr这样的照片网站是图像及其关联的用户生成元数据(UGM)形式的丰富标签数据源,特别是用户标签。用户生成的元数据与更“规范”的图像标签方案不同,因为它们通常更具描述性,并且在语义上更接近人们如何用自然语言描述图像,而不仅仅是识别图像中存在的对象。UGM的另一个方面是同义词普遍存在,不同的用户可能会使用不同的词汇来描述相同的概念,因此,有效地标准化这些标签变得重要。概念词嵌入[14]在这里可能非常有用,因为相关概念最终会被表示为相似的向量。
在本节中,我们演示了使用条件对抗网络生成图像的自动标签(可能是多模态的)标签向量分布的多标签预测。
对于图像特征,我们使用与[13]类似的卷积模型预训练了具有21,000个标签[15]的完整ImageNet数据集。我们使用最后一个完全连接的层的输出,该层具有4096个单元作为图像表示。
对于世界表示,我们首先从YFCC100M2数据集元数据的用户标签、标题和描述的串联中收集文本。在文本的预处理和清理之后,我们用单词向量大小为200训练了一个跳过的gram模型[14]。我们省略了在词汇表中出现少于200次的任何单词,从而最终得到大小为247465的字典。
在对抗网络的训练期间,我们保持卷积模型和语言模型固定。并将通过这些模型的反向传播留作未来工作。
对于我们的实验,我们使用MIR Flickr 25,000数据集[10],并使用我们上述描述的卷积模型和语言模型提取图像和标签特征。未加任何标签的图像被省略,注释被视为额外标签。前150,000个示例用作训练集。具有多个标签的图像在训练集内重复,每个关联标签重复一次。
对于评估,我们为每个图像生成100个样本,并使用词汇表中单词的向量表示与每个样本的余弦相似度找到最接近的前20个单词。然后我们选择所有100个样本中最常见的前10个单词。表4.2显示了用户分配的标签和注释以及生成的标签的一些样本。
最佳工作模型的生成器接收大小为100的高斯噪声作为噪声先验,并将其映射到500维ReLu层。并将4096维图像特征向量映射到2000维ReLu隐藏层。这两层都映射到200维线性层,该层将输出生成的单词向量。
鉴别器由单词向量和图像特征分别为500和1200维的ReLu隐藏层组成,并且具有1000个单位和3个部分的最大层作为连接层,最终输入到一个单一的S形单元。
该模型使用随机梯度下降进行训练,批量大小为100,并且初始学习速率为0.1,这个速率呈指数下降至.000001,衰减因子为1.00004。还使用了初始值为.5的动量,该动量增加到0.7。在生成器和鉴别器上均应用了概率为0.5的丢弃。
通过交叉验证和随机网格搜索与手动选择的混合(尽管在有限的搜索空间内)获得了超参数和架构选择。
5 未来工作
本文所示的结果非常初步,但它们展示了条件对抗网络的潜力,并对有趣和有用的应用展示了希望。
在现在和工作坊之间的未来探索中,我们期望呈现更复杂的模型,以及对它们的性能和特性进行更详细和彻底的分析。
表格2:生成标签样本
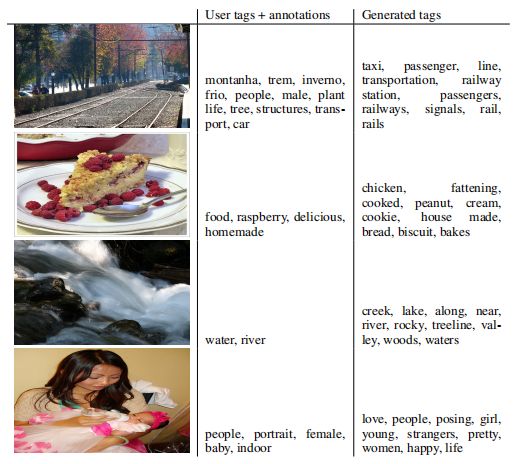
此外,在当前的实验中,我们只单独使用每个标签。但是,通过同时使用多个标签(有效地将生成问题提出为“集合生成”问题),我们希望能够取得更好的结果。
未来工作的另一个明显方向是构建联合训练方案以学习语言模型。例如[12]的工作表明,我们可以为特定任务学习适合的语言模型。
致谢
本项目是在Pylearn2 [7] 框架中开发的,我们想要感谢Pylearn2的开发者们。我们还要感谢Ian Goodfellow在蒙特利尔大学任职期间的有益讨论。作者衷心感谢Flickr的视觉与机器学习团队以及生产工程团队的支持(按字母顺序:Andrew Stadlen, Arel Cordero, Clayton Mellina, Cyprien Noel, Frank Liu, Gerry Pesavento, Huy Nguyen, Jack Culpepper, John Ko, Pierre Garrigues, Rob Hess, Stacey Svetlichnaya, Tobi Baumgartner, 和 Ye Lu)。
参考文献
- Bengio, Y., Mesnil, G., Dauphin, Y.和Rifai, S.(2013)。通过深度表示实现更好的混合。在ICML’2013上。
- Bengio, Y., Thibodeau-Laufer, E., Alain, G.和Yosinski, J.(2014)。可以通过反向传播进行训练的深度生成随机网络。在第30届国际机器学习大会(ICML’14)论文集中。
- Frome, A., Corrado, G. S., Shlens, J., Bengio, S., Dean, J., Mikolov, T.等(2013)。Devise:一种深度视觉语义嵌入模型。在神经信息处理系统的进展中,页码:2121–2129。
- Glorot, X., Bordes, A.和Bengio, Y.(2011)。深度稀疏整流器神经网络。在人工智能与统计学国际会议上,页码:315–323。
- Goodfellow, I.,Mirza, M.,Courville, A.和Bengio, Y.(2013a)。多预测深度Boltzmann机。在神经信息处理系统的进展中,页码:548–556。
- Goodfellow, I. J.,Warde-Farley, D.,Mirza, M.,Courville, A.和Bengio, Y.(2013b)。最大输出网络。在ICML’2013上。
- Goodfellow, I. J., Warde-Farley, D., Lamblin, P., Dumoulin, V., Mirza, M., Pascanu, R., Bergstra, J., Bastien, F.和Bengio, Y.(2013c)。Pylearn2:一个机器学习研究库。arXiv预印本arXiv:1308.4214。
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A.和Bengio, Y.(2014)。生成对抗网络。在NIPS’2014上。
- Hinton, G. E.,Srivastava, N.,Krizhevsky, A.,Sutskever, I.和Salakhutdinov, R.(2012)。通过防止特征检测器的共适应来改善神经网络。技术报告,编号:arXiv:1207.0580。
- Huiskes, M. J.和Lew, M. S.(2008)。mir flickr检索评估。在MIR’08:2008年ACM国际多媒体信息检索大会上,纽约,美国。ACM。
- Jarrett, K.,Kavukcuoglu, K.,Ranzato, M.和LeCun, Y.(2009)。用于对象识别的最佳多级架构是什么?在ICCV’09上。
- Kiros, R.,Zemel, R.和Salakhutdinov, R.(2013)。多模态神经语言模型。在NIPS深度学习研讨会的论文集中。
- Krizhevsky, A.,Sutskever, I.和Hinton, G.(2012)。使用深度卷积神经网络的ImageNet分类。在神经信息处理系统25的进展(NIPS’2012)中。
- Mikolov, T.,Chen, K.,Corrado, G.和Dean, J.(2013)。在向量空间中有效估计单词表示。在学习表示国际会议:研讨会跟踪上。
- Russakovsky, O.和Fei-Fei, L.(2010)。大规模数据集中的属性学习。在欧洲计算机视觉大会(ECCV),希腊克里特岛的部分和属性国际研讨会上。
- Srivastava, N.和Salakhutdinov, R.(2012)。用深度Boltzmann机进行多模态学习。在NIPS’2012上。
- Szegedy, C.,Liu, W.,Jia, Y.,Sermanet, P.,Reed, S.,Anguelov, D.,Erhan, D.,Vanhoucke, V.和Rabiovich, A.(2014)。用卷积深入探究。arXiv预印本arXiv:1409.4842。
References
- Bengio, Y., Mesnil, G., Dauphin, Y., and Rifai, S. (2013). Better mixing via deep representations. In ICML’2013.
- Bengio, Y., Thibodeau-Laufer, E., Alain, G., and Yosinski, J. (2014). Deep generative stochastic networks trainable by backprop. In Proceedings of the 30th International Conference on Machine Learning (ICML’14).
- Frome, A., Corrado, G. S., Shlens, J., Bengio, S., Dean, J., Mikolov, T., et al. (2013). Devise: A deep visual-semantic embedding model. In Advances in Neural Information Processing Systems, pages 2121–2129.
- Glorot, X., Bordes, A., and Bengio, Y. (2011). Deep sparse rectifier neural networks. In International Conference on Artificial Intelligence and Statistics, pages 315–323.
- Goodfellow, I., Mirza, M., Courville, A., and Bengio, Y. (2013a). Multi-prediction deep Boltzmann machines. In Advances in Neural Information Processing Systems, pages 548–556.
- Goodfellow, I. J., Warde-Farley, D., Mirza, M., Courville, A., and Bengio, Y. (2013b). Maxout networks. In ICML’2013.
- Goodfellow, I. J., Warde-Farley, D., Lamblin, P., Dumoulin, V., Mirza, M., Pascanu, R., Bergstra, J., Bastien, F., and Bengio, Y. (2013c). Pylearn2: a machine learning research library. arXiv preprint arXiv:1308.4214.
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014). Generative adversarial nets. In NIPS’2014.
- Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2012). Improving neural networks by preventing co-adaptation of feature detectors. Technical report, arXiv:1207.0580.
- Huiskes, M. J. and Lew, M. S. (2008). The mir flickr retrieval evaluation. In MIR ’08: Proceedings of the 2008 ACM International Conference on Multimedia Information Retrieval, New York, NY, USA. ACM.
- Jarrett, K., Kavukcuoglu, K., Ranzato, M., and LeCun, Y. (2009). What is the best multi-stage architecture for object recognition? In ICCV’09.
- Kiros, R., Zemel, R., and Salakhutdinov, R. (2013). Multimodal neural language models. In Proc. NIPS Deep Learning Workshop.
- Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25 (NIPS’2012).
- Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013). Efficient estimation of word representations in vector space. In International Conference on Learning Representations: Workshops Track.
- Russakovsky, O. and Fei-Fei, L. (2010). Attribute learning in large-scale datasets. In European Conference of Computer Vision (ECCV), International Workshop on Parts and Attributes, Crete, Greece.
- Srivastava, N. and Salakhutdinov, R. (2012). Multimodal learning with deep Boltzmann machines. In NIPS’2012.
Vision (ECCV), International Workshop on Parts and Attributes, Crete, Greece. - Srivastava, N. and Salakhutdinov, R. (2012). Multimodal learning with deep Boltzmann machines. In NIPS’2012.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabiovich, A. (2014). Going deeper with convolutions. arXiv preprint arXiv:1409.4842.
目前,我们简单地将条件输入和先验噪声作为MLP的单个隐藏层的输入,但人们可以想象使用更高阶的交互作用,允许复杂的生成机制,这在传统的生成框架中将非常难以处理。 ↩︎
Yahoo Flickr Creative Common 100M 数据集:http://webscope.sandbox.yahoo.com/catalog.php?datatype=i&did=67。 ↩︎