分布式系统的挑战
分布式系统的挑战
尽管之前已经聊了很多分布式系统的问题和处理方式,例如节点失效,主从复制滞后,以及事务并发控制。实际上分布式系统带来的问题和挑战远远不止之前讨论的一些,本书的作者一直在极力的描述软件系统各个环节的不可靠性,故障是一定会发生。我们的目标是构建可靠性的软件,本书推崇的方式是通过软件控制来保证系统在各种出错的情况下仍可以完成预定工作。
故障与部分失效
单个节点会以确定性的方式运行:要么运行成功,要么运行失败,这涉及到一个计算机设计非常谨慎的选择:如果发生了某个系统内部错误,我们宁愿使计算机全部崩溃,而不是返回一个错误的结果。
错误的结果往往更难处理
但是分布式系统会出现模棱两可的情况,比如网络的超时,上游服务的时钟比下游时钟慢。不确定性大大提高了分布式系统的复杂性,因为分布式系统不仅要处理系统崩溃的故障,还容忍程序错误运行产生的结果。任何一种错误都可能要付出十分惨痛的代价,在分布式系统中,怀疑、悲观、和偏执狂才能生存。
不可靠的网络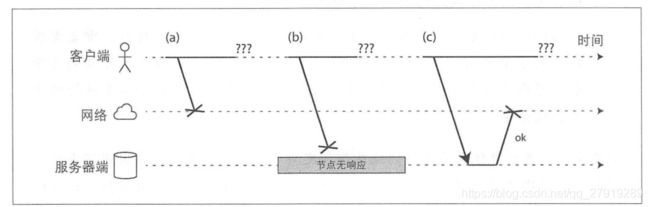
网络是计算机的通信的最常见的方式,因为网络通信包含多个环节,所以我们很难确定错误是在哪个环节发生的。
- 请求可能在某个消息队列里等待
- 远程节点已经失效 远程节点暂时无法响应(长时间GC)
- 远程节点已经完成处理,回复却在网络丢失
- 远程节点已经完成处理,回复却被延迟处理(网络阻塞)
如果请求方长时间没有收到回复,就会判断请求超时,但是请求方并不知道是哪个环节出了问题。
网络故障的处理方式
- 避免向失效节点分发请求 (心跳下线)
- 高可用服务主从选举
- 登录节点查看网络状态
- 单个节点失效主动通知
实际上这些处理方式还是无法判断节点是否故障,我们使用的最有效的手段依然是请求超时时间,但是如何设计尝试时间也是一个问题。因为网络的波动是比较常见的,所以我们应该考虑网络波动导致的延迟。TCP可靠性是通过超时重传和流量控制保证的,协议层已经完全屏蔽了实现的细节。设置超长超时时间,我们可以依靠TCP协议自生的重传机制来保证网络的可靠性,但是也要考虑到延迟和重试可能带来的时间消耗。超时的设置并不是一个不变的常量,可以通过持续监测响应时间来调整超时时间是一种更好的方法(Phi Accrual故障检测器)。
网络问题的本质
给每个通信分配固定的、带宽有保证的通信链路,这样端到端最大延迟是固定的,我们称为有界延迟。网络延迟的本质问题是资源分配的问题,网络可变延迟并不是一种自然规律,只是成本和收益互相博弈的结果。
不可靠的时钟
在分布式系统中,每台服务都有自己的时钟硬件设备,这些设备绝非是完全准确,每台机器都维护自己的时间版本。可能比其他机器块或者更慢。可以在一定程度上同步机器之间的时钟,最常用的方法是网络时间协议(Network Time Protocol),它提供一组专门的时间服务器来调整本地时间,时间服务器从精度更高的时间源获取更高精度的时间。
墙上时钟
墙上时钟根据某个日历返回当前的日期和时间,例如Java的System.currentTimeMillis()会返回自1970年1月1日以来的毫秒数。
单调时钟
单调时钟更适合测量持续的时间段,例如Java的System.nanoTime()返回的是单调时钟。单调时钟的名字来源于它们保证总是向前(而不会出现墙上时钟的回拨现象)。可以在一个时间点读取单调时钟的值,完成某项工作,然后再检查时钟,时钟值两次的差值就是就是两次检查的间隔。单调时钟的绝对值没有任何意义,不同的计算机基准可能不同,因此只在单机上有效。
依赖时钟的场景
- 请求是否超时
- 服务RT99
- 服务QPS
- 用户浏览时间
- 数据库记录
- 创建更新时间
事件顺序错乱

不同节点的时间不同,导致事件的顺序出了逻辑问题,后发生的时间比先发生的时间早。解决问题的方法:时间的置信区间 机械无法保证时间的精度,因此我们不应该时钟读数视为一个精确的时间点,应该视为带有置信区间的时间范围。
全局快照的同步时钟 单调递增的事务ID
最大等待时间

租约模式是分布式系统资源分配方式比较常见的方式,主节点轮询维护租约有效性,资源到期就重新分配资源。可能会引发的问题:两台机器时间精度不同,导致资源分配不均衡;如果主节点执行流程比较耗时,会导致租期过短完不成工作(GC,同步system call,缺页中断)。实际上这些现象,都是程序逻辑未按照预期执行,一般来说这种问题最难排查,只能依靠经验来大胆判断,小心求证。
拜占庭故障
以上的故障都是出现在节点虽然不可靠,但是诚实的情况,如果节点会“撒谎“,那么问题复杂性就会再上一个维度。如果某个系统中及时发生部分节点故障,甚至不遵从协议恶意冲攻击,干扰网络,但是仍然可以正常运行,那么我们称之为拜占庭容错系统。因为拜占庭容错系统的协议异常复杂,而容错的嵌入式系统依赖硬件的支持。
理论系统模型与现实
计时维度
- 同步模型 有上界的网络延迟、进程暂停、时钟误差,大部分系统不是同步模型。
- 异步模型 算法不对时间做任何假设,这样的系统并不常见。
- 部分同步模型 大部分会像同步系统一样运行,但是有时会超过网络延迟、进程暂停和时钟漂移的上界。
节点失效模型
- 崩溃-中止模型 一个节点只能用一种方式发生故障,就是系统崩溃,且崩溃无法恢复。
- 崩溃-恢复模型 节点可能在任何时间崩溃,可能在一段时间之后再次响应,需要考虑节点恢复后工作不受影响。
- 拜占庭失效模型 节点可能会发生任何事情,包括试图作弊欺诈其他节点。
一致性和共识
分布式系统可能存在太多可能出错的场景,而处理故障最简单的办法就是整个服务停下来,向用户提供出错信息。如果不能接受服务中止,就需要更加容错的解决方案,即使某些内部组件发生故障,系统依旧可以对外提供服务。
可线性化
写请求会在不同的时间到达不同的节点,无论数据库采用何种复制方法(包括主从复制、多主节点复制或者无主节点复制),都无法避免这种不一致的情况。大部分数据提供了最终一直性保证,这是一个非常弱的保证,因为我们无法知道系统何时会收敛,在收敛之前读请求可能获取到不同值。可线性化可以保证分布式系统在任何时候读写一致性。
| 概念 | 让每个数据节点都有相同的视图,且数据操作是原子的 |
| 底层 | 数据版本号、加锁、CAS |
| 依赖 | 唯一主节点 |
| 实现方式 | 主从复制、共识算法 |
| 应用 | ZooKeeper、etcd等 |
CAP
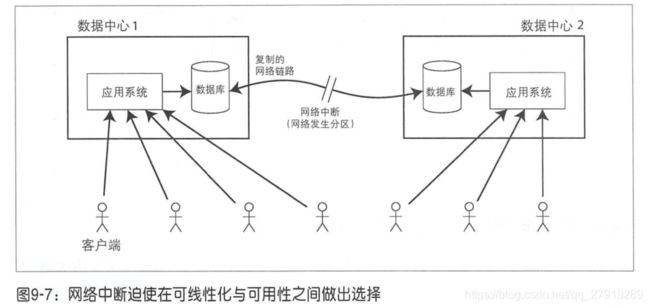
理想情况下的可线性化,没有考虑网络不稳定和时钟不一致带来的问题。如果在主从复制的场景下,网络中断会导致主从无法同步的问题,最终导致服务的不可用。因此不要求线性化的应用更能容忍网络故障,这种思路通常被称为CAP定理。
许多分布式系统热衷于集中共享存储上提供线性化语义,而CAP理论事实上鼓励大家去探索无共享系统,后者更适合大规模的Web服务。CAP理论有时也代表一致性、可用性、分区容错性,系统只能支持其中两个特性。这种理解存在误导性,网络分区是一种故障,不管喜欢和不喜欢都可能会发生。正式的CAP定理的范围很窄,只考虑一种一致性模型(可线性化)和一种故障(网络分区,节点处于活动状态但相互断开)。
线性化的顺序保证
| 名称 | 实现方式 | 备注 |
|---|---|---|
| 序列号排序 | 序列号或者时间戳排序 | 节点时钟不一致 |
| 非因果序列发生器 | 每个节点产生自己的一组序列号 每个操作附加时间戳信息 预先分配序列号的区间范围 |
节点处理速度不同 墙上时钟不一致 分区之间的序列号无法判断顺序 |
| Lamport时间戳 | 节点标识符+节点ID+时间戳,每个节点保存最大事件值 | 并没有解决容错性问题 例如保证唯一性的场景,出现网络中断 |
| 全序关系广播 | 基于一致性算法 保证消息可靠性和有序性 |
比较常见的实现方式,例如Zookeeper,etcd |
分布式事务
在异构分布式事务通常由消息队列和数据库来完成,只有数据库中处理消息的事务成功提交,消息队列才会标记消息已处理完毕。分布式事务常用的实现方式有二阶段提交和XA交易。

其中二阶段提交中主节点会向所有节点发送准备请求,如果所有节点都回答是,则执行;任意节点返回否,取消执行。
尽管通过一些手段,我们可以在分布式系统上实现事务特性,但是它并不是完美的。
- 如果协调者不支持数据复制,会成为系统的单点故障
- 包含协调者会导致应用程序不再是无状态的,因为要包含协调者的日志信息
- 无法解决分布式事务的死锁问题
- 必须所有节点同意,任何节点故障会导致事务失败,和容错系统的目标背道而驰
支持容错的共识
共识算法给不确定系统带来了明确的安全属性,此外还支持容错。共识性算法包括VSR,Paxos,Raft,Zab,本文主要了解他们共同的设计思想。
- 协商一致性 所有节点支持相同的决议
- 诚实性 所有节点不能反悔,对一项提议不能有两次决定
- 合法性 如果决定值V,则V一定是某个节点提议的
- 可终止性 节点不崩溃则一定可以达成协议
共识算法同样有一些限制
- 节点投票是一个同步复制的过程可能会导致性能降低
- 需要严格多的节点,例如至少三个节点才能容忍一个节点故障
- 假定一组固定参与投票的节点集,因此不能动态增删节点
- 对网络问题特别敏感,依赖超时检测节点失效,网络波动可能导致频繁选举主节点
成员与协调服务
Zookeeper通常被成为协调配置服务,从他们对外提供的API来看和数据库非常像:读取、写入对应主键的值,或者遍历主键。如果只是一个普通的数据库,我们为什么还要额外花费力气去实现共识算法。
- Zookeeper一般不会直接使用,会作为其他项目的依赖
- Zookeeper主要针对保存少量的,完全可以载入内存的数据设计
- Zookeeper通常采用容错的全序广播算法在所有节点上复制数据从而实现高可靠
- 全序广播保证事件在不同节点按相同顺序执行,从而保证一致性
- Zookeeper还实现了线性化原子操作(实现分布式加锁),操作全序(事件单增序号,防止锁冲突),故障检测,更改通知(订阅通知机制)
成员与协调服务应用场景包括节点任务分配、服务发现、成员服务。
小结
实现可靠的系统的本质上是成本和收益的博弈,在非特殊的场景下,设计中无法避免不可靠网络和不可靠时钟的问题。如果两个操作是天然隔离的,并不需要考虑上述两个问题,我们真正需要解决的问题是保证有因果关系的一组操作的执行顺序。