李宏毅-2023春机器学习 ML2023 SPRING-学习笔记:3/24机器如何生成图像
目录
- 3/24 机器如何生成图像
-
- 速览图像生成常见模型
- 浅谈图像生成模型 Diffusion Model 原理
- Stable Diffusion、DALL-E、Imagen 背后共同的套路
- Variational Auto-encoder (VAE)
- Flow-based Generative Model
- Generative Adversarial Network (GAN)
3/24 机器如何生成图像
速览图像生成常见模型
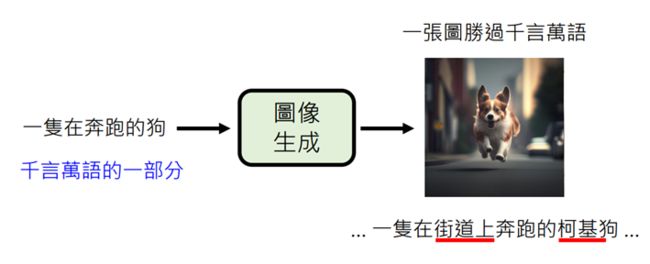
一图胜万言,一张好的图像的资讯量是远超一句文句所能提供的
在图像中许多文字中没有提供的信息(在哪跑?什么品种的狗?),
是需要机器进行大量的脑部才能产生的,这也是图片生成(或语音生成)与文字生成的不同之处,
而这种不同体现在模型的设计上。
文字生成多采用Autoregressive(各个击破)的方法,也就是去计算下一个输出文字的概率

如果将这个方法应用在图像生成上
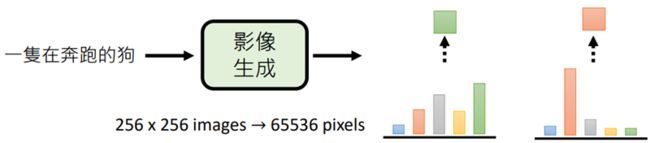
输入一张256×256大小的图像,即65536个像素的输入,去计算下一个生成的像素的概率(我们可以固定能够生成的颜色数量,例如64色就已经足够)
影像版的GPT就采用了这个图像生成方法
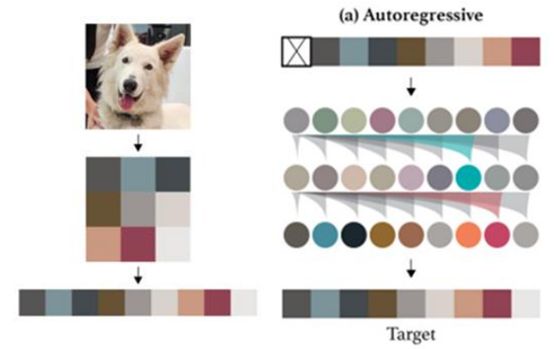
图像逐行生成,可行,但是生成速度慢,所以在图像生成中一般采用一次到位的生成方法
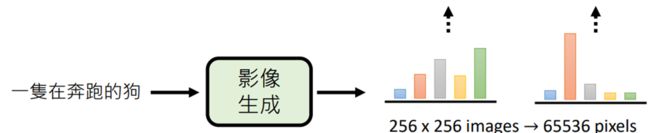
输入一句文字后,先计算每一个位置要放什么颜色的概率分布(全部计算出来),再根据分布产生样例
但这种方法会带来问题:输入一段文字,正确答案并不是只有一个,单独做每个像素的分布,各有各的想法,会导致生成的图像像拼凑的破布

为了解决这个问题,目前的图像生成,会增加一个额外的输入:normal/uniform distribution
通过一个已知的高维的normal distribution取样(李宏毅老师一直说的是Sample,具体中文不确定)出的向量,向量与文字结合生成图像
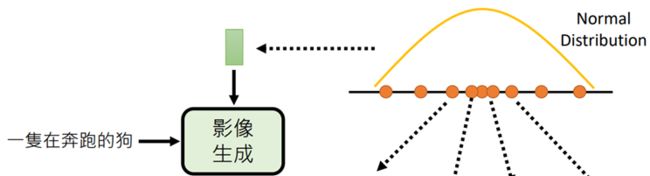
具体的原理解释:
假设,文字为y,影像为x,可以生成的图像有很多,我们只要能得到P(x|y),就能选择要生成的图像,
但P(x|y)是一个十分复杂模型(不是Guass distribution),无法直接得出,
使用下述策略:
把normal distribution中取样(Sample)出的每一个向量,都对应到P(x|y),就是将生成出来的众多图片对应到每个向量,而影像生成模型的工作,就是在产生这种对应关系。难点在于如何将normal distribution进行变换,变为P(x|y)。(这就是所有影像生成模型都在攻克的问题)
(友友们,你们懂了吗,我快要长脑子了)
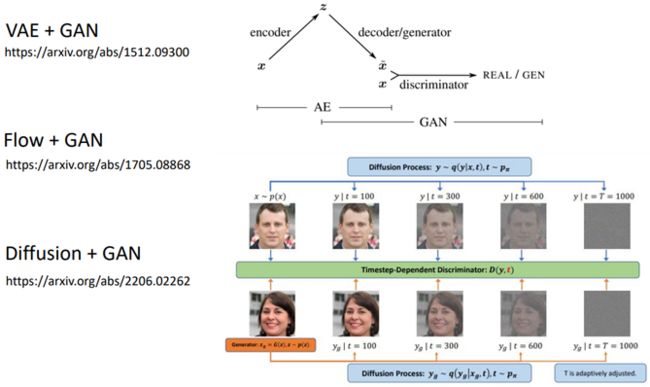
- 目前采用的影像生成模型:VAE, Flow-based Generative Model, Diffusion Model, GAN
(Diffusion Model的相关笔记在下一节,其余三个模型我虽然都会去了解,但是详细的笔记就不一定了orz)
下面是关于四个模型的简要介绍
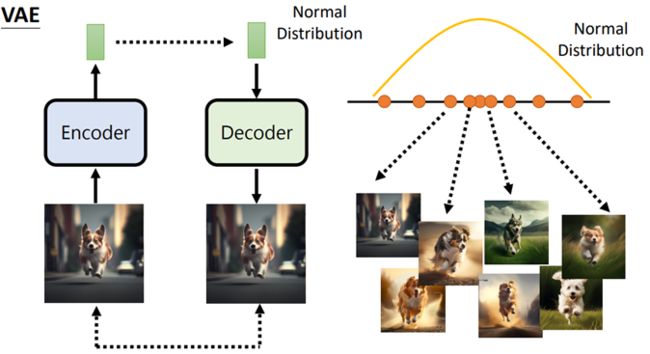
文字输入decoder,用于限制图像生成的范围,
Encoder输出一个向量,交给decoder,希望还原回一样的图像,
encoder和decoder一起训练,希望生成的图像约相似越好
同时要对encoder生成的向量做限制,强制其是normal distribution
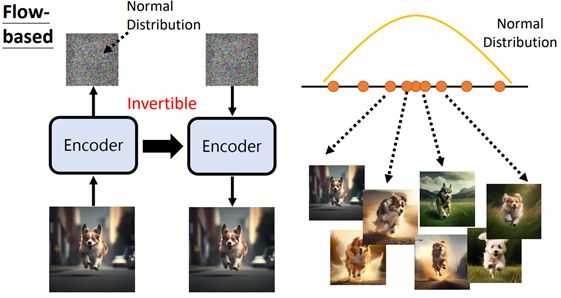
训练encoder,输入一张图片输出一个向量,并保证这个向量是可逆的(大小与输入图像一致),
多个向量组成normal distribution,输入encoder得出生成图像
对一张图片不断添加噪声,让它看起来就像一个normal distribution取样得出的向量
训练一个denoise(解噪声)模型,一步步去除噪音,得到原图

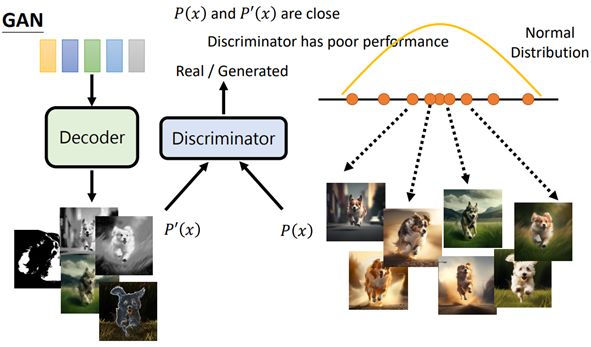
训练decoder,输出大量从normal distribution中sample出的向量(此时的输出质量差,几乎看不出是什么,只是一堆噪音),
训练discriminator(鉴别器),作用是判断一张图片是decoder生成的图片P’(x)(左)还是真正的图片P(x)(右),
调整decoder的参数,计算P’(x)和P(x)的相似程度Loss,使discriminator越差越好(不理解)
- 速览VAE、Flow-based、Diffusion模型的差异

其中没有GAN是因为GAN与上面3个模型都不冲突,都可以在decoder后加上一个discriminator
浅谈图像生成模型 Diffusion Model 原理
相关论文:Denoising Diffusion Probabilistic Models (DDPM)
论文地址:https://arxiv.org/abs/2006.11239
- Diffusion Model的原理
- 首先取样(sample)一个充满噪音的图片(大小应与你最终要生成图片的大小一致),也就是从guass distribution中sample一个向量,向量的大小与要生成图像一致
- 将图片输入denoise,得到的输出再作为输入,输入denoise,以此类推
(理解:图像本身就存在于噪音中,而diffusion model的工作就是将被视作噪音的部分过滤)
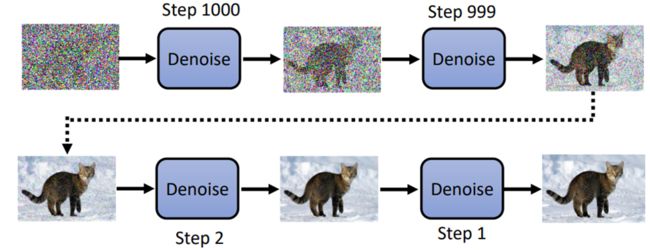
下面分析denoise模型
Q:图中是denoise模型是同一个模型吗? A:是的,同一个denoise模型反复使用
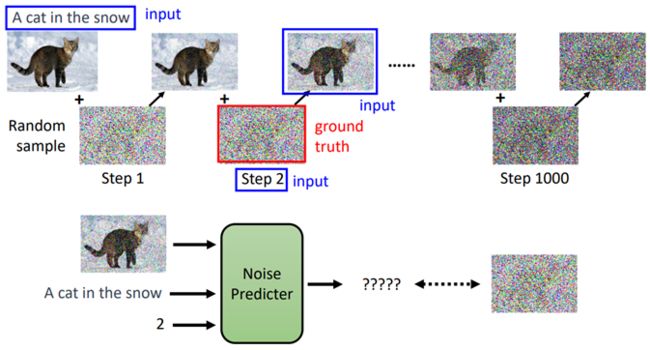
但是每张输出的图片需要过滤的杂质量是有很大差别的,所以在输入图片的同时,还会输入一个数字,来代表现在noise的严重程度(严重程度不断减减)

Denoise内部工作原理:
- 将带有噪音的图像和噪音严重程度输入Noise Predicter
- Noise Predicter预测输入图片的噪音并输出噪音图像
- 最后将输入的图片减去预测的噪音图像作为输出结果
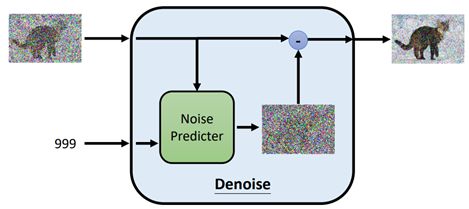
Q:为什么不直接输出带有噪音(但比输入图片带有少)的图片,而是先生成噪音图像,再相减
A:直接生成带有噪音的图像相当于生成图像了,难度比生成一张噪音图像大得多
如何训练Noise Predictor
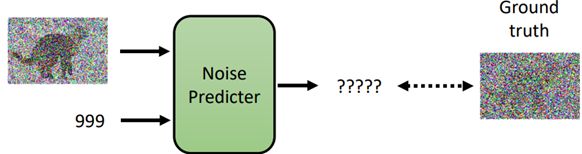
目标:生成输入图片的噪音图像
训练资料:人为创造,对一张图像不断的添加噪音,称为Forward/Diffusion Process
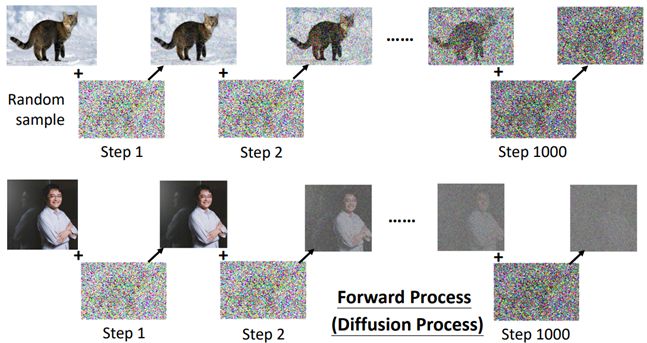
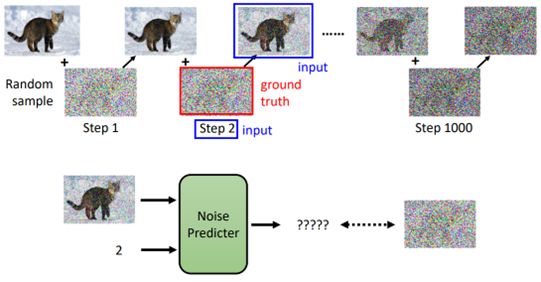
在不断添加噪音的过程中就创造出了输入图像input、噪声严重程度step以及noise predicter的输出Ground truth
回归主题,怎么通过输入文字来生成图像呢?
(这里插入我的一些拙见,可以略过)
上一节课中,李宏毅老师有举过一个例子:“塑像本来就在石头里,我只是把不要的部分去掉——米开朗基罗”。用同样的思想类比图像生成,最初随机产生一张全是噪音的图像,通过文字的引导以及不断的denoise,图像中的噪音不断被过滤,最终生成我们期待的图像。
- Text-to-Image
先介绍一个图片数据集(训练资料):LAION
数据量:5.85Biliion
网站地址:https://laion.ai/blog/laion-5b/
(其他数据集大小:此次HW6:70k;ImageNet:1M)
我们在原来模型的基础上增加额外的输入:文字描述
如图中的“A cat in the snow”,输入Denoise中的Noise Predicter
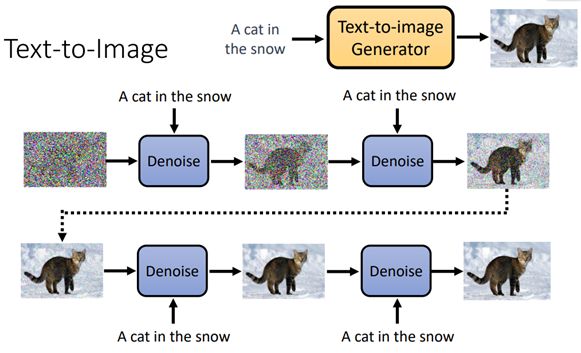

同理,训练Noise Predicter时,增加文字输入
Denoising Diffusion Probabilistic Modal(DDPM) 的完整演算法

Stable Diffusion、DALL-E、Imagen 背后共同的套路
Stable diffusion模型内部包含三个原件:Text Encoder、Generation Model、Decoder
- Text Encoder将文字叙述转化为一个个向量
- Generation Model,例如diffusion Model,输入杂讯(图中粉红色九宫格,我个人将杂讯理解为噪音)和text Encoder生成的向量,生成一个中间产物(中间产物有不同的形式,后面会详细说明)
- 把中间产物(图中的中间产物是图片的压缩版本)输入Decoder,将图片还原为原始图像
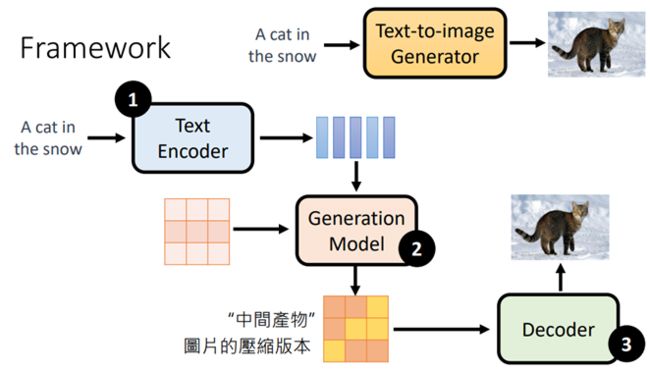
通常三个模块分开训练,最后再组合起来
- Stable Diffusion
和上诉的工作流程类似
最右边是输入(不只可以输入文字),中间是一个生成模型(使用diffusion modal),将diffusion modal生成的中间产物(一个图片压缩后的版本)输入最左边,还原回原来的图像

(论文地址:https://arxiv.org/abs/2112.10752)
其他图像生成模型,也是同样的套路
DALL-E series内置两个生成模型autoregressive(图像不大时使用)与diffusion modal
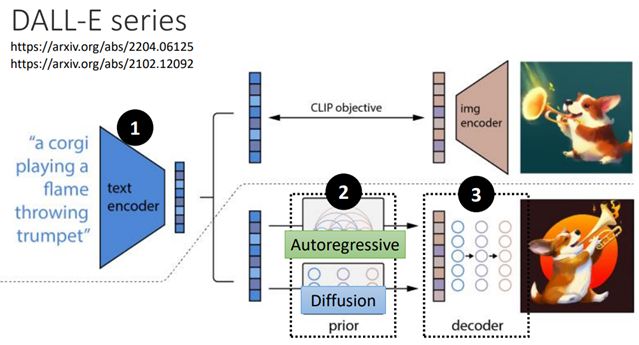
先通过diffusion modal生成64×64的小图,再通过decoder生成256×256的大图

下面详细介绍3个模组
- Text Encoder
对于将文字转为向量,在前面几堂课都进行了详细的介绍
例如将GPT或BERT当作text encoder
注意,text encoder对生成的图片影响很大
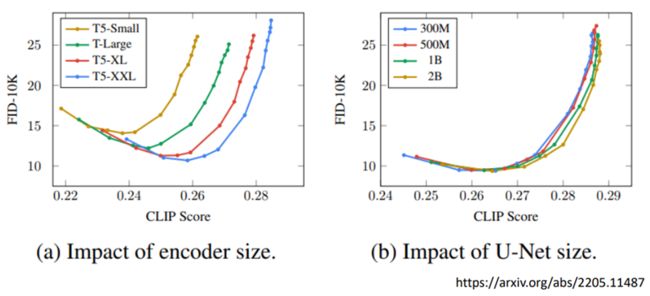
横轴:CLIP,越大越好
纵轴:FID-10k,越小越好,sample了10k张image进行FID的计算(等会详细介绍这两个衡量标准)
(a)T5:一个文字encoder,不同颜色的线:由上至下,由小到大
结论:随着text encoder模组大小的增大,图像生成的质量越好
(b)U-Net:这里指diffusion model里noise predicter
结论:不同颜色(不同大小)的diffusion modal线都十分接近,证明diffusion modal的增大对结果的帮助是十分有限的
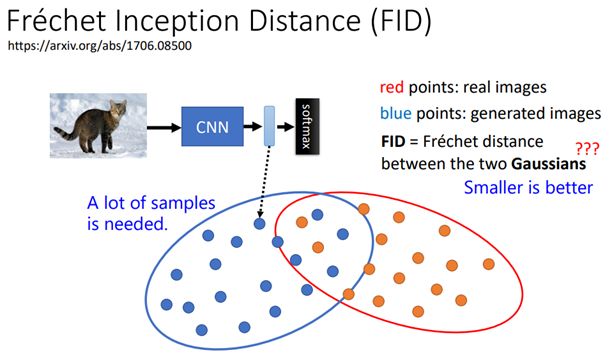
先有一个pretrain好的CNN模型,将图片输入CNN得到representation(图像特征)
将真实影像的representation(图中红点)与生成影像的representation(图中蓝点)
如果这两组representation越接近,表示生成与真实图像越接近
如何计算距离?
假设两组representation都是gaussian distribution,计算两个gaussian distribution的frechet distance
注意,FID需要sample出大量的图像
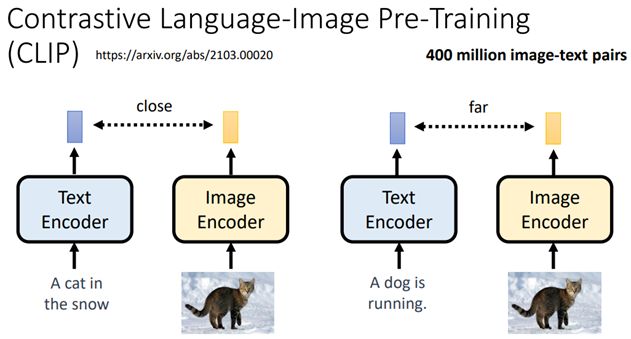
使用400millio图像-文字对训练出来的模型
包含两个模组:text encoder和image encoder,分别输入一段文字和一张图片,各输出一个向量
如果文字和图片是成对的,那么两个向量越近越好,反之越远越好
所以,CLIP的数值越高,表示文字和图像相关性越高,也就是生成图像的质量越高
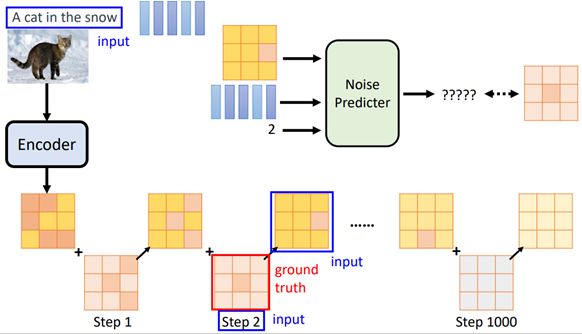
- Generation Model
(老师先讲了decoder再讲Generation Model)
输入文字的representation和噪音图像,输出中间产物
与前面的描述diffusion model不同的是,noise不是直接加在图片上,而是加在representation上

训练Noise Predicter的方法与之前类似,只是将图像换成了representation
训练完成后,使用方法也和之前类似,将Latent Representation与一段文字输入Denoise,重复多次,得到合适的中间产物后,交给Decoder
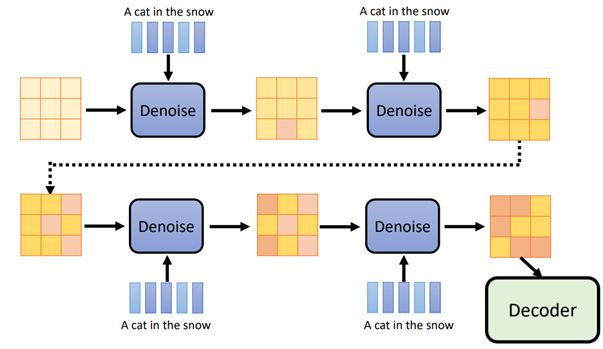
联想:在使用生成图像的软件时(如Midjouney),使用的diffusion modal,那么在生成图像的过程中,能观察到的应该是一张完全随机噪音的图像,噪音逐渐减少的过程,但实际中,观察到的是一张从模糊到清晰的图像,原因是它展示的是每一次denoise后再经过decoder的图像
- Decoder
Decoder的训练不需要文字资料,只需要大量的影像资料
第一种:中间产物是小图
将原图(图像对的右边)做down-sampling变为小图(左),即可得到训练资料

第二种:中间产物是Latent Representation(潜在图像特征)

如何得到decoder?
训练一个Auto-encoder

往encoder输入一张图像,生成Latent Representation,再把Latent Representation输入decoder,以还原原来的图片,让输入与输出越接近越好。训练完成后,取出decoder即为所求。
Variational Auto-encoder (VAE)
https://blog.csdn.net/Transfattyacids/article/details/130473587