MISRA 2012学习笔记(3)-Rules 8.4-8.7
文章目录
-
- Rules
-
- 8.4 字符集和词汇约定(Character sets and lexical conventions)
-
- Rule 4.1 八进制和十六进制转译序列应有明确的终止识别标识
- Rule 4.2 禁止使用三字母词(trigraphs)
- 8.5 标识符(Identifiers)
-
- Rule 5.1 外部标识符不得重名
- Rule 5.2 同范围和命名空间内的标识符不得重名
- Rule 5.3 内部声明的标识符不得隐藏外部声明的标识符
- Rule 5.4 宏标识符不得重名
- Rule 5.5 宏标识符与其他标识符不得重名
- Rule 5.6 typedef 名称应是唯一标识符
- Rule 5.7 标签(tag)名称应是唯一标识符
- 全局(external linkage)对象和函数的标识符应是唯一的
- Rule 5.9 局部全局(internal linkage)对象和函数的标识符应是唯一的
- 8.6 类型(Types)
-
- Rule 6.1 位域(位带)仅允许使用适当的类型来声明(位域成员类型限制)
- Rule 6.2 单比特(single-bit)位域成员不可声明为有符号类型
- 8.7 字符和常量(Literals and constants)
-
- Rule 7.1 禁止使用八进制常数
- Rule 7.2 后缀“u”或“U”应使用于所有无符号的整数常量
- Rule 7.3 小写字符“l”不得作为常量的后缀使用(仅可使用“L”)
- Rule 7.4除非对象的类型为“指向 const char 的指针”,否则不得将字符串常量赋值给该对象
Rules
8.4 字符集和词汇约定(Character sets and lexical conventions)
Rule 4.1 八进制和十六进制转译序列应有明确的终止识别标识
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:八进制或十六进制转义序列应通过以下任一方式来标识其已终止:
•另一个转义序列的开始,或
•字符常量的结尾或字符串的结尾
原理:如果十进制或十六进制转义序列后面跟着其他字符,可能会造成混淆。例如,字符常量’\x1f’由单个字符组成,而字符常量’\x1g’由两个字符’\x1’和’g’组成。将多字符常量表示为整数的方式是由实现定义的。
如果给字符常量或字符串文字中的每个八进制或十六进制转义序列增加显示的终止标识,则可以减少混淆的可能性。
示例:在此示例中,由 s1,s2 和 s3 指向的每个字符串都等效于字符串“Ag”
const char *s1 = "\x41g"; /* Non-compliant */
const char *s2 = "\x41" "g"; /* Compliant - terminated by end of literal */
const char *s3 = "\x41\x67"; /* Compliant - terminated by another escape */
int c1 = '\141t'; /* Non-compliant */
int c2 = '\141\t'; /* Compliant - terminated by another escape */
Rule 4.2 禁止使用三字母词(trigraphs)
等级:建议
分析:可判定,单一编译单元
适用:C90,C99
原理:三字母词(或叫三联符序列)由两个问号起始,后跟一个特定字符组成。
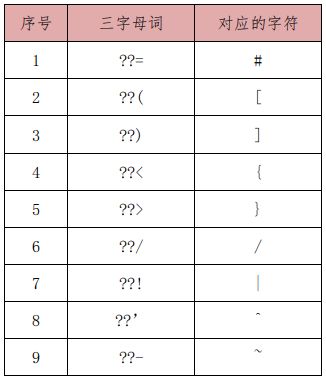
注意:复合字母(“<:” “:>” “<%” “%>” “%:” “%:%:”)是被允许的,因为它们只是标记符。
示例:比如字符串
"(Date should be in the form ??-??-??)"
会被编译器解析为
"(Date should be in the form ~~]"
8.5 标识符(Identifiers)
Rule 5.1 外部标识符不得重名
等级:必要
分析:可判定,系统范围
适用:C90,C99
展开:本准则要求不同的外部标识符在实现的有效范围内的字符是不同的。
“不重名”取决于实现和所使用的 C 语言版本:
•在 C90 中,最小有效字符范围是前 6 个字符,且不区分大小写;
•在 C99 中,最小有效字符范围是前 31 个字符,而其通用字符和扩展字符的有效范围是 6 到 10 个字符
实际上,许多实际的使用环境(编译环境)提供了更大的限制。 例如,通常 C90 中的外部标识符区分大小写,并且至少前 31 个字符有意义。
原理:如果两个标识符仅在非有效字符上不同,则实际行为无法确定。
如果考虑到可移植性,则应谨慎使用“标准”中指定的最低限制来应用此规则。
长标识符可能会损害代码的可读性。 尽管许多自动代码生成系统生成的标识符很长,但是有一个很好的论据可以将标识符长度保持在此限制之下。
注意:在C99中,如果扩展源字符出现在外部标识符中,并且该字符没有对应的通用字符,则标准不会指定它占用多少字符。
示例:在下面的示例中,所有定义都出现在同一个编译单元中。所讨论的实现在外部标识符中支持31个区分大小写的字符。
/* 1234567890123456789012345678901********* Characters */
int32_t engine_exhaust_gas_temperature_raw;
int32_t engine_exhaust_gas_temperature_scaled; /* Non-compliant */
/* 1234567890123456789012345678901********* Characters */
int32_t engine_exhaust_gas_temp_raw;
int32_t engine_exhaust_gas_temp_scaled; /* Compliant */
超过32个字符后的变量不同,是违法规则的。
在以下违规示例中,该实现在外部标识符中支持 6 个不区分大小写的字符。 两个编译单元中的标识符不同,但在主要特征上并没有区别。
/* file1.c */
int32_t abc = 0;
/* file2.c */
int32_t ABC = 0;
不应存在大小写可能一样的变量,或者函数,这样编译的时候可能会报错。
Rule 5.2 同范围和命名空间内的标识符不得重名
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:如果两个标识符都是外部标识符,则本准则不适用,因为此情况适用于 Rule 5.1。
如果每个标识符都是宏标识符,则本准则不适用,因为这种情况已被 Rule 5.4 和 Rule 5.5 涵盖。
“不重名”的定义取决于实现和所使用的 C 语言版本:
•在 C90 中,最低要求是前 31 个字符有效
•在 C99 中,最低要求是前 63 个字符有效,通用字符或扩展源字符视为一个字符。
原理:如果两个标识符仅在非有效字符上不同,则实际行为无法确定。
如果考虑到可移植性,则应谨慎使用“标准”中指定的最低限制来应用此规则。
长标识符可能会损害代码的可读性。 尽管许多自动代码生成系统生成的标识符很长,但是有一个很好的论据可以将标识符长度保持在此限制之下。
示例:在下面的示例中,所讨论的实现为:在不具有全局属性的标识符中支持 31 个区分大小写的字符。
/* 1234567890123456789012345678901********* Characters */
extern int32_t engine_exhaust_gas_temperature_raw;
static int32_t engine_exhaust_gas_temperature_scaled; /* Non-compliant */
void f ( void )
{
/* 1234567890123456789012345678901********* Characters */
int32_t engine_exhaust_gas_temperature_local; /* Compliant */
}
/* 1234567890123456789012345678901********* Characters */
static int32_t engine_exhaust_gas_temp_raw;
static int32_t engine_exhaust_gas_temp_scaled; /* Compliant */
跟5.1类似,这里指的是局部或静态变量
Rule 5.3 内部声明的标识符不得隐藏外部声明的标识符
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:内部范围声明的标识符应与外部范围声明的标识符不重名。
“不重名”的定义取决于实现和所使用的 C 语言版本:
•在 C90 中,最低要求是前 31 个字符有效
•在 C99 中,最低要求是前 63 个字符有效,通用字符或扩展源字符视为一个字符。
原理:如果在内部作用域中声明一个标识符,与在外部作用域中已经存在的标识符重名,则最内部的声明将“隐藏”外部的声明。 这可能会导致开发人员混乱。
注意:在一个名称空间中声明的标识符不会隐藏在另一个名称空间中声明的标识符
术语“内部作用域”和“外部作用域”定义如下:
•具有文件作用域的标识符可以被认为具有最外层作用域;
•文件内模块间可识别的范围,作用域较小,相对最大范围,视为内部作用域;
•连续的嵌套块,引入更多的内部作用域。
示例:
void fn1 ( void )
{
int16_t i; /* 定义变量 "i" */
{
int16_t i; /* 违规 - 会隐藏前面定义的 "i" */
i = 3; /* 这里的 "i" 是指前面哪一个, 会产生混淆 */
}
}
struct astruct
{
int16_t m;
};
extern void g ( struct astruct *p );
int16_t xyz = 0; /* 定义变量 "xyz" */
void fn2 ( struct astruct xyz ) /* 违规 - 外部定义的 "xyz" 被同名形参隐藏 */
{
g ( &xyz );
}
uint16_t speed;
void fn3 ( void )
{
typedef float32_t speed; /* 违规 - 类型将变量给隐藏 */
}
Rule 5.4 宏标识符不得重名
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:该规则要求,当定义宏时,其名称与:
•当前定义的其他宏的名称,和
•参数的名称。
“不重名”的定义取决于实现和所使用的 C 语言版本:
•在C90中,最低要求是宏标识符的前31个字符是有效的;
•在C99中,最低要求是宏标识符的前63个字符是有效的。
在实践中,实现可能提供更大的限制。该规则要求宏标识符在实现所施加的限制内是不同的。
原理:如果两个宏标识符仅非有效字符不同,则其实际实现行为不可预知。 由于宏参数仅在其宏扩展期间处于活动状态,因此一个宏中的参数与另一宏中的参数混淆不会有问题
考虑到可移植性,则应谨慎使用“标准”中指定的最低限制来应用此准则。
过长的宏标识符可能会损害代码的可读性。 尽管许多自动代码生成系统会生成很长的宏标识符,但有一个很好的论据认为宏标识符的长度应远低于此限制。
注意:在C99中,如果扩展源字符出现在宏名称中,并且该字符没有相应的通用字符,则标准不会指定它占用多少字符。
示例:在下面的示例中,所讨论的实现在宏标识符中支持31个重要的区分大小写的字符。
/* 1234567890123456789012345678901********* Characters */
#define engine_exhaust_gas_temperature_raw egt_r
#define engine_exhaust_gas_temperature_scaled egt_s /* Non-compliant */
/* 1234567890123456789012345678901********* Characters */
#define engine_exhaust_gas_temp_raw egt_r
#define engine_exhaust_gas_temp_scaled egt_s /* Compliant */
Rule 5.5 宏标识符与其他标识符不得重名
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:该规则要求预处理前存在的宏的名称与预处理后存在的标识符不同。它适用于标识符,而不考虑其作用域或名称空间,也适用于已定义的任何宏,而不考虑在声明标识符时定义是否仍然有效。
根据所使用的C 语言的实现和版本,“不重名”的定义不相同:
•在C90中,最低要求是前31个字符是有效的;
•在C99中,最低要求是前63个字符是有效的,每个通用字符或扩展源字符计数为单个字符
原理:保持宏名称和标识符不同有助于避免开发人员混淆
示例:在下面的不兼容示例中,类似函数的宏Sum的名称也用作标识符。对象Sum的声明不受宏展开的约束,因为它后面没有“(”字符。因此,在执行了预处理之后,标识符仍然存在。
#define Sum(x, y) ( ( x ) + ( y ) )
int16_t Sum;
下面的示例是兼容的,因为预处理后没有标识符Sum的实例
#define Sum(x, y) ( ( x ) + ( y ) )
int16_t x = Sum ( 1, 2 );
在下面的示例中,假定有效字符长度为 31 且区分大小写。该示例违规,因为宏名称与标识符的前 31 个字符完全相同。
/* 1234567890123456789012345678901********* Characters */
#define low_pressure_turbine_temperature_1 lp_tb_temp_1
static int32_t low_pressure_turbine_temperature_2;
Rule 5.6 typedef 名称应是唯一标识符
等级:必要
分析:可判定,系统范围
适用:C90,C99
展开:类型定义名称在所有名称空间和翻译单元中应该是唯一的。只有当类型定义在头文件中并且该头文件包含在多个源文件中时,该规则才允许对相同的typedef名称进行多个声明。
原理:如果多个 typedef 名称命名相同而它们实际指代又是不同的函数、对象或枚举常量时,开发人员会被困扰
例外:typedef 名称可以与和 typedef 相关联的结构、联合或枚举标记(tag)名称相同。
void func ( void )
{
{
typedef unsigned char u8_t;
}
{
typedef unsigned char u8_t; /* Non-compliant - reuse */
}
}
typedef float mass;
void func1 ( void )
{
float32_t mass = 0.0f; /* Non-compliant - reuse */
}
typedef struct list
{
struct list *next;
uint16_t element;
} list; /* Compliant - exception */
typedef struct
{
struct chain
{
struct chain *list;
uint16_t element;
} s1;
uint16_t length;
} chain; /* Non-compliant - tag "chain" not
* associated with typedef */
Rule 5.7 标签(tag)名称应是唯一标识符
等级:必要
分析:可判定,系统范围
适用:C90,C99
展开:标签(tag)在所有名称空间和单位翻译中应是唯一的。
标签(tag)的所有声明应指定相同的类型。
仅当在头文件中声明标签(tag)并且该头文件被多个源文件包含时,此准则才允许使用同一标签(tag) 的多个完整声明。
与 typedef 名称相同,这种情况下,所有声明都是完全相同的,且由于头文件防止多次包含的举措,也不会出现多个声明
原理:重用标签(tag)名称可能会导致开发人员混乱。
例外:标签(tag)名称可能与与其关联的 typedef 名称相同。
struct stag
{
uint16_t a;
uint16_t b;
};
struct stag a1 = { 0, 0 }; /* 合规 - 与前面的定义一致 */
union stag a2 = { 0, 0 }; /* 违规 - 与声明的 struct stag 不一致。
* 同时也违背了C99的约束 */
下述的示例也违背了 Rule 5.3:
struct deer
{
uint16_t a;
uint16_t b;
};
void foo ( void )
{
struct deer
{
uint16_t a;
};/* 违规 - 标签 "deer" 重复使用 */
}
typedef struct coord
{
uint16_t x;
uint16_t y;
} coord;/* 合规 - 符合例外情况 */
struct elk
{
uint16_t x;
};
struct elk /* 违规 - 同一个标签被声明为不同的类型
* 同时也违背了C99的约束 */
{
uint32_t x;
};
全局(external linkage)对象和函数的标识符应是唯一的
等级:必要
分析:可判定,系统范围
适用:C90,C99
展开:用作外部标识符的标识符不得在任何命名空间或编译单元中用于任何其他目的,即使它没有链接的对象。
原理:强制标识符名称的唯一性有助于避免混淆。没有链接对象的标识符不必是唯一的,因为混淆风险很小
示例:下面的示例中,“file1.c”和“file2.c”是同一个项目的一部分。
/* file1.c */
int32_t count; /* "count" 具有全局属性(全局变量) */
void foo ( void ) /* "foo" 具有全局属性(全局函数) */
{
int16_t index; /* "index" 无全局属性(临时变量) */
}
/* file2.c */
static void foo ( void ) /* 违规 - “ foo”不唯一(在file1.c中有全局属
* 性的同名函数) */
int16_t count; /* 违规 - "count" 没有全局属性, 但与另一文
* 件的有全局属性的变量重名 */
int32_t index; /* 合规 - "index"无全局属性(临时变量) */
}
全局变量不能与局部变量名称一样,全局函数不能与局部函数名称一致。
Rule 5.9 局部全局(internal linkage)对象和函数的标识符应是唯一的
等级:必要
分析:可判定,系统范围
适用:C90,C99
展开:标识符名称在所有命名空间和编译单元中都应该唯一。任何标识符都不应与任何其他标识符具有相同的名称,即使该其他标识符没有链接的对象也是如此。
原理:强制标识符名称的唯一性有助于避免混淆。
例外:可以在一个以上的转换单元中定义具有局部属性的内联函数,条件是所有这些定义都在每个转换单元中包含的同一头文件中进行。即:定义在头文件中的内联函数,不受限制。
示例:下面的示例中,“file1.c”和“file2.c”是同一个项目的一部分。
/* file1.c */
static int32_t count; /* "count" 局部全局属性 */
static void foo ( void ) /* "foo" 局部全局属性 */
{
int16_t count; /* 违规 - "count" 没有全局属性, 但与有局部全
* 局属性的标识符冲突 */
int16_t index; /* "index" 无全局属性 */
}
void bar1 ( void )
{
static int16_t count; /* 违规 - "count" 没有全局属性, 但与有局部全
* 局属性的标识符冲突 */
int16_t index; /* 合规 - "index" 不唯一但它没有与其冲突的具全
* 局属性的标识符 */
foo ( );
}
/* End of file1.c */
/* file2.c */
static int8_t count; /* 违规 - "count" 具有局部全局属性, 与另一个
* 具有局部全局属性的标识符重复 */
static void foo ( void ) /* 违规 - "foo" 具有局部属性, 与另一个具有局
* 部属性的函数标识符重复 */
{
int32_t index; /* 合规 - "index" 和 "nbytes" " */
int16_t nbytes; /* 不唯一, 但因都不具全局属性, 因而不冲突 */
}
void bar2 ( void )
{
static uint8_t nbytes; /* 合规 - "nbytes" 不唯一, 但它没有全局属性,
* 全局属性与存储类别无关 */
}
/* End of file2.c */
内部链接(internal linkage)翻译为局部全局,即被“static”修饰的全局变量和函数
静态全局变量不能与局部变量/局部静态变量同名,也不能与其他文件的静态全局变量同名。静态全局函数也不能与其他文件的静态全局函数同名。
8.6 类型(Types)
Rule 6.1 位域(位带)仅允许使用适当的类型来声明(位域成员类型限制)
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:“适当的”位域类型为:
•C90: unsigned int或signed int;
•C99:下列之一:
-无符号整型或有符号整型;
-实现允许的另一种显式有符号或显式无符号整数类型;
—_Bool
注意:允许使用typedef来指定适当的类型。
原理:使用int是实现定义的,因为int类型的bit-fields字段可以是有符号的也可以是无符号的
在C90中不允许使用enum、short、char或任何其他类型的bit-fields字段,因为该行为是未定义的。
在C99中,实现可以定义在bit-fields字段声明中允许的其他整数类型。
示例:以下示例适用于不提供任何其他位域类型的 C90 和 C99 实现。假定 int 类型为 16 位。
typedef unsigned int UINT_16;
struct s {
unsigned int b1:2; /* 合规 */
int b2:2; /* 违规 - 不允许使用不明确符号的"int" */
UINT_16 b3:2; /* 违规 - 不允许使用不明确符号的"int" */
signed long b4:2; /* 违规 - 即使 long 和 int 大小相同 */
};
该定义一般用在寄存器定义中,字段的数据类型一般都保持一致
Rule 6.2 单比特(single-bit)位域成员不可声明为有符号类型
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
原理:根据 C99 标准第 6.2.6.2 节,一个单比特(single-bit)带符号的位域数据具有 1 个符号位和 0 个值位。
在任何整数表示中,0 个值位都无法指定有意义的值。如果定义会对编程人员产生疑问。
尽管C90标准没有提供太多关于类型表示的细节,但同样的考虑也适用于C99
注意:此规则不适用于未命名的位字段,因为它们的值不能被访问
8.7 字符和常量(Literals and constants)
Rule 7.1 禁止使用八进制常数
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
原理:开发人员编写带有前导零的常量时,可能希望它们被解释为十进制常量。八进制常数的表述方式:0xx。
注意:此规则不适用于八进制转义序列,因为使用前导字符\意味着混淆的空间更小
例外:整数常数零(写为“0”)严格来说是八进制常数,但是是本准则的允许例外。
示例:
extern uint16_t code[ 10 ];
code[ 1 ] = 109; /* Compliant - decimal 109 */
code[ 2 ] = 100; / * Compliant - decimal 100 */
code[ 3 ] = 052; /* Non-Compliant - decimal 42 */
code[ 4 ] = 071; /* Non-Compliant - decimal 57 */
八进制数一般不会在嵌入式中使用,此处也规定不能使用
Rule 7.2 后缀“u”或“U”应使用于所有无符号的整数常量
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:此规则适用于:
•在预处理指令#if和#elif的控制表达式中出现的整型常量;
•预处理后存在的任何其他整型常量。
注:在预处理过程中,整型常量的类型确定与预处理后相同,不同之处在于:
•所有有符号整数类型的行为就像它们是long (C90)或intmax_t (C99);
•所有无符号整数类型的行为就像它们是unsigned long (C90)或uintmax_t (C99)
原理: 整数常量的类型是潜在的混淆源,因为它取决于多种因素的复杂结合,包括:
•常数的大小;
•实现的整数类型的大小;
•任何后缀的存在;
•表示值的基数(即十进制、八进制或十六进制)。
例如,整数常数40000在32位环境中是signed int类型,但在16位环境中是signed long类型。值0x8000在16位环境中是无符号int类型,但在32位环境中是有符号int类型。
注意:
•任何带有“U”后缀的值都是unsigned类型;
•小于2^31的无后缀十进制值为有符号类型
•大于或等于2^15的无后缀十进制值为有符号类型号或无符号类型
•对于 C90,大于或等于 2^31的无后缀十进制值可能是有符号或无符号类型
常量的符号应该是显式的。如果常量是无符号类型,则应用“U”后缀可以清楚地表明程序员理解该常量是无符号的
注意:该规则不依赖于使用常量的上下文;可应用于常数的提升和其他转换与确定是否符合此规则无关
示例:以下示例假定计算机具有 16 位 int 类型和 32 位 long 类型。它显示了根据标准确定的每个整数常量的
类型。整数常量 0x8000 不符合标准,因为它具有无符号类型,但没有“ U”后缀。

Rule 7.3 小写字符“l”不得作为常量的后缀使用(仅可使用“L”)
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
原理:在声明文字时,使用大写后缀“L”可消除“1”(数字 1)和“l”(字母“ el”)之间的潜在歧义。
示例:
const int64_t a = 0L;
const int64_t b = 0l; /* Non-compliant */
const uint64_t c = 0Lu;
const uint64_t d = 0lU; /* Non-compliant */
const uint64_t e = 0ULL;
const uint64_t f = 0Ull; /* Non-compliant */
const int128_t g = 0LL;
const int128_t h = 0ll; /* Non-compliant */
const float128_t m = 1.2L;
const float128_t n = 2.4l; /* Non-compliant */
Rule 7.4除非对象的类型为“指向 const char 的指针”,否则不得将字符串常量赋值给该对象
等级:必要
分析:可判定,单一编译单元
适用:C90,C99
展开:不得尝试直接修改字符串常量或宽字符串常量。
除非对象的类型为“指向 const char 型数组的指针”,否则对字符串常量取地址(&运算符修饰)的结果不得赋值给该对象
同样的,此限制也适用于宽字符串常量。 除非对象的类型是“指向 const wchar_t 的指针”,否则不得将宽字符串常量赋值给该对象。 除非该对象的类型是“指向 const wchar_t 数组的指针”,否则对宽字符串常量取地址(&运算符)的结果不得赋值给该对象。
原理:对字符串常量的修改结果无法预知。例如,某些实现可能会将字符串常量存储在只读存储器中,在这种情况下,尝试修改字符串常量将失败,并且还可能导致异常或崩溃。
此规则可防止误修改字符串常量。
在 C99 标准中,并未明确指定是否将共享共同结尾的字符串常量存储在不同的内存位置中。因此,即使尝试修改字符串常量看起来成功了,也可能会无意中更改了另一个字符串。
示例:下面示例显示了直接修改字符串常量的尝试:
"0123456789"[0] = '*'; /* 违规 */
这些示例描述了如何防止间接修改字符串常量。
/* 违规 - s 缺少 const 修饰 */
char *s = "string";
/* 合规 - p 有 const 修饰; 其他限定词是可接受的 */
const volatile char *p = "string";
extern void f1 ( char *s1 );
extern void f2 ( const char *s2 );
void g ( void )
{
f1 ( "string" ); /* 违规 - 形参 s1 缺少 const 修饰 */
f2 ( "string" ); /* 合规 */
}
char *name1 ( void )
{
return ( "MISRA" ); /* 违规 - 返回类型缺少 const 修饰 */
}
const char *name2 ( void )
{
return ( "MISRA" ); /* 合规 */
}
指针对象需要定义为const char,才可以赋值字符串常量