感知损失(perceptual loss)详解
本文来自收费专栏:感知损失(perceptual loss)详解_南淮北安的博客-CSDN博客_感知损失
目录
一.感知损失
二、Loss_feature
三、Loss_style
感知损失的作用:
贡献当然就是图像风格转换的实用化:
- 速度三个量级的提升
- fully convolutional network可以应用于各种各样的尺寸
引入
图像风格转换算法,虽然效果好,但对于每一张要生成的图片,都需要初始化,然后保持CNN的参数不变,反向传播更新图像,得到最后的结果。性能问题堪忧。
但是图像风格转换算法的成功,在生成图像领域,产生了一个非常重要的idea,那就是可以将卷积神经网络提取出的feature,作为目标函数的一部分,通过比较待生成的图片经过CNN的feature值与目标图片经过CNN的feature值,使得待生成的图片与目标图片在语义上更加相似(相对于Pixel级别的损失函数)。
图像风格转换算法将图片生成以生成的方式进行处理,如风格转换,是从一张噪音图(相当于白板)中得到一张结果图,具有图片A的内容和图片B的风格。
而Perceptual Losses则是将生成问题看做是变换问题。即生成图像是从内容图中变化得到。
图像风格转换是针对待生成的图像进行求导,CNN的反向传播由于参数众多,是非常慢的,同样利用卷积神经网络的feature产生的loss,训练了一个神经网络,将内容图片输入进去,可以直接输出转换风格后的图像。而将低分辨率的图像输入进去,可以得到高分辨率的图像。因为只进行一次网络的前向计算,速度非常快,可以达到实时的效果。
架构
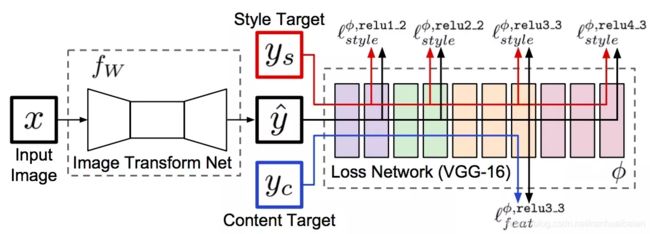
下面这个网络图是论文的精华所在。图中将网络分为Transform网络和Loss网络两种,在使用中,
Transform网络用来对图像进行转换,它的参数是变化的,
而Loss网络,则保持参数不变,Transform的结果图,风格图和内容图都通过Loss Net得到每一层的feature激活值,并以之进行Loss计算。
一.感知损失
网络细节
网络细节的设计大体遵循DCGAN中的设计思路:
- 不使用pooling层,而是使用strided和fractionally strided卷积来做downsampling和upsampling,
- 使用了五个residual blocks
- 除了输出层之外的所有的非residual blocks后面都跟着spatial batch normalization和ReLU的非线性激活函数。
- 输出层使用一个scaled tanh来保证输出值在[0, 255]内。
- 第一个和最后一个卷积层使用9×9的核,其他卷积层使用3×3的核。
输入输出
- 对于风格转换来说,输入和输出的大小都是256×256×3。
- 对于图片清晰化来说,输出是288×288×3,而输入是288/f×288/f×3,f是压缩比,因为Transform Net是全卷积的,所以可以支持任意的尺寸。
Downsampling and Upsampling
- 对于图片清晰化来说,当upsampling factor是f的时候,使用后面接着log2f个stride为1/2卷积层的residual blocks.
- fractionally-strided卷积允许网络自己学习一个upsampling函数出来。
- 对于风格转换来说,使用2个stride=2的卷积层来做downsample,每个卷积层后面跟着若干个residual blocks。然后跟着两个stride=1/2的卷积层来做upsample。虽然输入和输出相同,但是这样有两个优点:
- 提高性能,减少了参数
- 大视野,风格转换会导致物体变形,因而,结果图像中的每个像素对应着的初始图像中的视野越大越好。
Residual Connections
残差连接可以帮助网络学习到identify function,而生成模型也要求结果图像和生成图像共享某些结构,因而,残差连接对生成模型正好对应得上。
图中:
蓝线加黑线表示内容损失,作用在较低特征层上
红线和黑线表示风格损失,作用在从低到高所有特征层上

这个结构和GAN较为相似
左边是Transform Net: fw,起着条件生成器的作用, pix2pix GAN 的生成器就也这个网络。
右边是Loss Network,一个固定参数的 pretrained VGG-16,可以类比为GAN的判别器,都是通过自己的Loss 来引导生成器。
与GAN不同的地方有:
- Loss Network是固定参数的pretrained VGG-16,参数不更新
- 生成器的 Loss 为 Perceptual Loss = Loss_feature + Loss_style
Perceptual Loss = Loss_feature + Loss_style
Perceptual loss是是如何做的?
它是将真实图片卷积得到的feature与生成图片卷积得到的feature作比较,使得高层信息(内容和全局结构)接近,也就是感知的意思。
二、Loss_feature
Loss_feature用来约束fw(x)的语义信息和空间结构,步骤如下:
1. 将 x 输入 Loss Network,提取 relu3_3 的 feature as feature_1
2. 将 fw(x) 接到 Loss Network 的输入,同样提取 relu3_3 的 feature as feature_2
3. 计算 feature_1 和 feature_2 的 normalized L2 Loss(欧氏距离),
即 Loss_feature = ((feature_1 - feature_2)^2).sum()**.5 / feature_1.size
4. 回传 Loss_feature 且只对 fw 更新参数

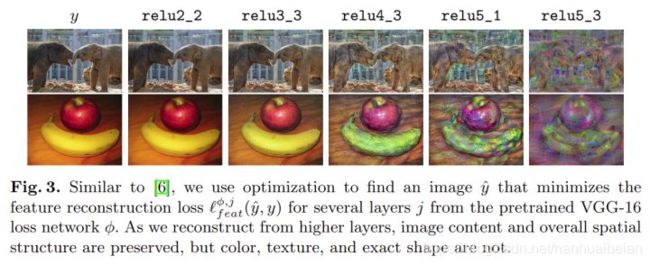
在Loss Network各层feature上单独计算Loss_feature,生成图像的效果:
三、Loss_style
Style Transfer的核心是 Loss_style,用来约束fw(x)的艺术风格,步骤如下:
1. 将 y_style 输入 Loss Network,提取 4 层 features as feature_1
2. 将 fw(x) 接到 Loss Network 的输入,同样提取 4 层 features as feature_2
3. 如下图的公式,先计算两个 feature 的 Gram matrices,
然后 Loss_style 就是两个 Gram matrices 的 squared Frobenius norm

两张图片,在Loss网络的每一层都求出Gram矩阵,然后对应层之间计算欧式距离,最后将不同层的欧氏距离相加,得到最后的风格损失.
根据Loss_style的运算,猜测Gram matrices的功能是:
- 通过矩阵乘法运算,去除了Convolution feature上空间结构信息
- 保留代表全图的某种共性的语义信息,而这种共性恰好表现为图像的艺术风格。
- 最后回传Loss_style,只对 fw更新参数
在Loss Network各层feature 上单独计算Loss_style,生成图像的效果: 
参考:感知损失(perceptual loss)详解_南淮北安的博客-CSDN博客_感知损失