突破边界:文本检测算法的革新与应用前景
突破边界:文本检测算法的革新与应用前景
1.文本检测理论篇(文本检测方法介绍)
文本检测任务是找出图像或视频中的文字位置。不同于目标检测任务,目标检测不仅要解决定位问题,还要解决目标分类问题。
文本在图像中的表现形式可以视为一种‘目标‘,通用的目标检测的方法也适用于文本检测,从任务本身上来看:
- 目标检测:给定图像或者视频,找出目标的位置(box),并给出目标的类别;
- 文本检测:给定输入图像或者视频,找出文本的区域,可以是单字符位置或者整个文本行位置;

目标检测和文本检测同属于“定位”问题。但是文本检测无需对目标分类,并且文本形状复杂多样。
当前所说的文本检测一般是自然场景文本检测,其难点在于:
- 自然场景中文本具有多样性:文本检测受到文字颜色、大小、字体、形状、方向、语言、以及文本长度的影响;
- 复杂的背景和干扰;文本检测受到图像失真,模糊,低分辨率,阴影,亮度等因素的影响;
- 文本密集甚至重叠会影响文字的检测;
- 文字存在局部一致性,文本行的一小部分,也可视为是独立的文本;
针对以上问题,衍生了很多基于深度学习的文本检测算法,解决自然场景文字检测问题,这些方法可以分为基于回归和基于分割的文本检测方法。
下一节将简要介绍基于深度学习技术的经典文字检测算法。
近些年来基于深度学习的文本检测算法层出不穷,这些方法大致可以分为两类:
- 基于回归的文本检测方法
- 基于分割的文本检测方法
本节筛选了2017-2021年的常用文本检测方法,按照如上两类方法分类如下表格所示:

1.1 基于回归的文本检测
基于回归文本检测方法和目标检测算法的方法相似,文本检测方法只有两个类别,图像中的文本视为待检测的目标,其余部分视为背景。
1.1.1 水平文本检测
早期基于深度学习的文本检测算法是从目标检测的方法改进而来,支持水平文本检测。比如Textbox算法基于SSD算法改进而来,CTPN根据二阶段目标检测Fast-RCNN算法改进而来。
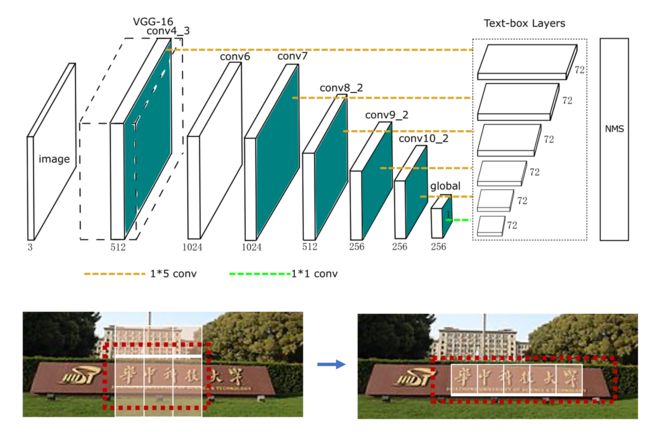
在TextBoxes[1]算法根据一阶段目标检测器SSD调整,将默认文本框更改为适应文本方向和宽高比的规格的四边形,提供了一种端对端训练的文字检测方法,并且无需复杂的后处理。
- 采用更大长宽比的预选框
- 卷积核从3x3变成了1x5,更适合长文本检测
- 采用多尺度输入
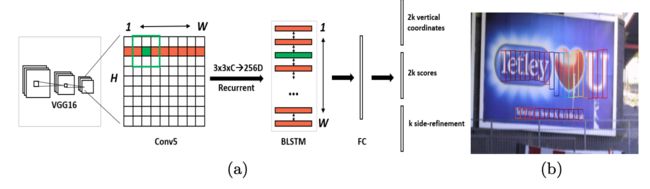
CTPN[3]基于Fast-RCNN算法,扩展RPN模块并且设计了基于CRNN的模块让整个网络从卷积特征中检测到文本序列,二阶段的方法通过ROI Pooling获得了更准确的特征定位。但是TextBoxes和CTPN只支持检测横向文本。
1.1.2 任意角度文本检测
TextBoxes++[2]在TextBoxes基础上进行改进,支持检测任意角度的文本。从结构上来说,不同于TextBoxes,TextBoxes++针对多角度文本进行检测,首先修改预选框的宽高比,调整宽高比aspect ratio为1、2、3、5、1/2、1/3、1/5。其次是将 1 ∗ 5 1*5 1∗5的卷积核改为 3 ∗ 5 3*5 3∗5,更好的学习倾斜文本的特征;最后,TextBoxes++的输出旋转框的表示信息。

EAST[4]针对倾斜文本的定位问题,提出了two-stage的文本检测方法,包含 FCN特征提取和NMS部分。EAST提出了一种新的文本检测pipline结构,可以端对端训练并且支持检测任意朝向的文本,并且具有结构简单,性能高的特点。FCN支持输出倾斜的矩形框和水平框,可以自由选择输出格式。
- 如果输出检测形状为RBox,则输出Box旋转角度以及AABB文本形状信息,AABB表示到文本框上下左右边的偏移。RBox可以旋转矩形的文本。
- 如果输出检测框为四点框,则输出的最后一个维度为8个数字,表示从四边形的四个角顶点的位置偏移。该输出方式可以预测不规则四边形的文本。
考虑到FCN输出的文本框是比较冗余的,比如一个文本区域的邻近的像素生成的框重合度较高,但不是同一个文本生成的检测框,重合度都很小,因此EAST提出先按行合并预测框,最后再把剩下的四边形用原始的NMS筛选。
MOST[15]提出TFAM模块动态的调整粗粒度的检测结果的感受野,另外提出PA-NMS根据位置信息合并可靠的检测预测结果。此外,训练中还提出 Instance-wise IoU 损失函数,用于平衡训练,以处理不同尺度的文本实例。该方法可以和EAST方法结合,在检测极端长宽比和不同尺度的文本有更好的检测效果和性能。

1.1.3 弯曲文本检测
利用回归的方法解决弯曲文本的检测问题,一个简单的思路是用多点坐标描述弯曲文本的边界多边形,然后直接预测多边形的顶点坐标。
CTD[6]提出了直接预测弯曲文本14个顶点的边界多边形,网络中利用Bi-LSTM[13]层以细化顶点的预测坐标,实现了基于回归方法的弯曲文本检测。
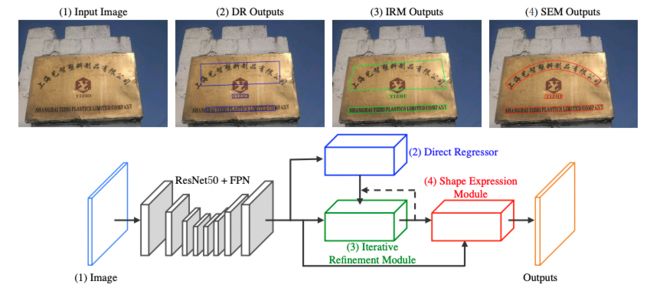
LOMO[19]针对长文本和弯曲文本问题,提出迭代的优化文本定位特征获取更精细的文本定位,该方法包括三个部分,坐标回归模块DR,迭代优化模块IRM以及任意形状表达模块SEM。分别用于生成文本大致区域,迭代优化文本定位特征,预测文本区域、文本中心线以及文本边界。迭代的优化文本特征可以更好的解决长文本定位问题以及获得更精确的文本区域定位。
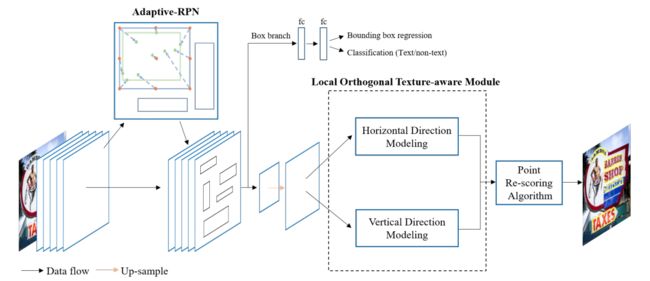
Contournet[18]基于提出对文本轮廓点建模获取弯曲文本检测框,该方法首先使用Adaptive-RPN获取文本区域的proposal特征,然后设计了局部正交纹理感知LOTM模块学习水平与竖直方向的纹理特征,并用轮廓点表示,最后,通过同时考虑两个正交方向上的特征响应,利用Point Re-Scoring算法可以有效地滤除强单向或弱正交激活的预测,最终文本轮廓可以用一组高质量的轮廓点表示出来。
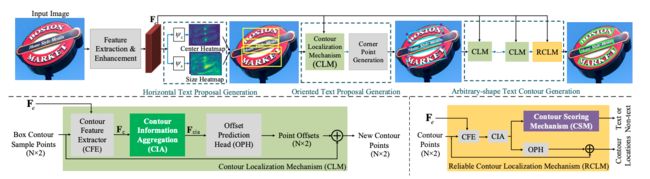
PCR[14]提出渐进式的坐标回归处理弯曲文本检测问题,总体分为三个阶段,首先大致检测到文本区域,获得文本框,另外通过所设计的Contour Localization Mechanism预测文本最小包围框的角点坐标,然后通过叠加多个CLM模块和RCLM模块预测得到弯曲文本。该方法利用文本轮廓信息聚合得到丰富的文本轮廓特征表示,不仅能抑制冗余的噪声点对坐标回归的影响,还能更精确的定位文本区域。
1.2 基于分割的文本检测
基于回归的方法虽然在文本检测上取得了很好的效果,但是对解决弯曲文本往往难以得到平滑的文本包围曲线,并且模型较为复杂不具备性能优势。于是研究者们提出了基于图像分割的文本分割方法,先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线。

此类方法通常是基于分割的方法实现文本检测,基于分割的方法对不规则形状的文本检测有着天然的优势。基于分割的文本检测方法主体思想为,通过分割方法得到图像中文本区域,再利用opencv,polygon等后处理得到文本区域的最小包围曲线。
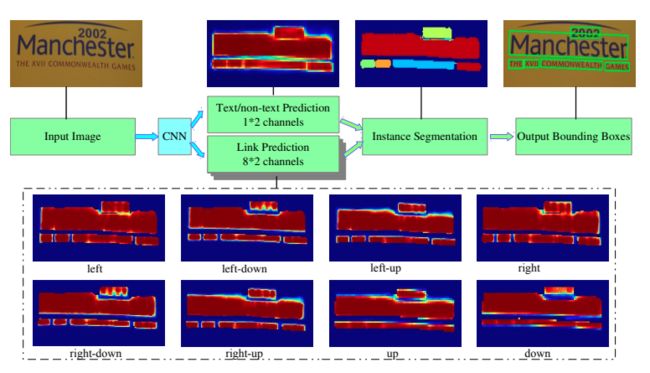
Pixellink[7]采用分割的方法解决文本检测问题,分割对象为文本区域,将同属于一个文本行(单词)中的像素链接在一起来分割文本,直接从分割结果中提取文本边界框,无需位置回归就能达到基于回归的文本检测的效果。但是基于分割的方法存在一个问题,对于位置相近的文本,文本分割区域容易出现“粘连“问题。Wu, Yue等人[8]提出分割文本的同时,学习文本的边界位置,用于更好的区分文本区域。另外Tian等人[9]提出将同一文本的像素映射到映射空间,在映射空间中令统一文本的映射向量距离相近,不同文本的映射向量距离变远。
MSR[20]针对文本检测的多尺度问题,提出提取相同图像的多个scale的特征,然后将这些特征融合并上采样到原图尺寸,网络最后预测文本中心区域、文本中心区域每个点到最近的边界点的x坐标偏移和y坐标偏移,最终可以得到文本区域的轮廓坐标集合。

针对基于分割的文本算法难以区分相邻文本的问题,PSENet[10]提出渐进式的尺度扩张网络学习文本分割区域,预测不同收缩比例的文本区域,并逐个扩大检测到的文本区域,该方法本质上是边界学习方法的变体,可以有效解决任意形状相邻文本的检测问题。

假设用了PSENet后处理用了3个不同尺度的kernel,如上图s1,s2,s3所示。首先,从最小kernel s1开始,计算文本分割区域的连通域,得到(b),然后,对连通域沿着上下左右做尺度扩张,对于扩张区域属于s2但不属于s1的像素,进行归类,遇到冲突点时,采用“先到先得”原则,重复尺度扩张的操作,最终可以得到不同文本行的独立的分割区域。
Seglink++[17]针对弯曲文本和密集文本问题,提出了一种文本块单元之间的吸引关系和排斥关系的表征,然后设计了一种最小生成树算法进行单元组合得到最终的文本检测框,并提出instance-aware 损失函数使Seglink++方法可以端对端训练。

虽然分割方法解决了弯曲文本的检测问题,但是复杂的后处理逻辑以及预测速度也是需要优化的目标。
PAN[11]针对文本检测预测速度慢的问题,从网络设计和后处理方面进行改进,提升算法性能。首先,PAN使用了轻量级的ResNet18作为Backbone,另外设计了轻量级的特征增强模块FPEM和特征融合模块FFM增强Backbone提取的特征。在后处理方面,采用像素聚类方法,沿着预测的文本中心(kernel)四周合并与kernel的距离小于阈值d的像素。PAN保证高精度的同时具有更快的预测速度。

DBNet[12]针对基于分割的方法需要使用阈值进行二值化处理而导致后处理耗时的问题,提出了可学习阈值并巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能端对端的学习文本分割的阈值。自动调节阈值不仅带来精度的提升,同时简化了后处理,提高了文本检测的性能。

FCENet[16]提出将文本包围曲线用傅立叶变换的参数表示,由于傅里叶系数表示在理论上可以拟合任意的封闭曲线,通过设计合适的模型预测基于傅里叶变换的任意形状文本包围框表示,从而实现了自然场景文本检测中对于高度弯曲文本实例的检测精度的提升。

1.3. 小结
本节介绍了近几年来文本检测领域的发展,包括基于回归、分割的文本检测方法,并分别列举并介绍了一些经典论文的方法思路。下一节以PaddleOCR开源库为例,讲解如何从0到1构建文本检测算法并完成训练。
2.OCR 文本检测实战
安装paddleocr whl包
PaddleOCR提供了一系列测试图片,点击这里下载并解压,然后在终端中切换到相应目录
cd /path/to/ppocr_img
如果不使用提供的测试图片,可以将下方--image_dir参数替换为相应的测试图片路径。
2.1 DB文本检测算法详细实现
2.1.1 DB文本检测算法原理
DB是一个基于分割的文本检测算法,其提出可微分阈值Differenttiable Binarization module(DB module)采用动态的阈值区分文本区域与背景。

图1 DB模型与其他方法的区别
基于分割的普通文本检测算法其流程如上图中的蓝色箭头所示,此类方法得到分割结果之后采用一个固定的阈值得到二值化的分割图,之后采用诸如像素聚类的启发式算法得到文本区域。
DB算法的流程如图中红色箭头所示,最大的不同在于DB有一个阈值图,通过网络去预测图片每个位置处的阈值,而不是采用一个固定的值,更好的分离文本背景与前景。
DB算法有以下几个优势:
- 算法结构简单,无需繁琐的后处理
- 在开源数据上拥有良好的精度和性能
在传统的图像分割算法中,获取概率图后,会使用标准二值化(Standard Binarize)方法进行处理,将低于阈值的像素点置0,高于阈值的像素点置1,公式如下:
B i , j = { 1 , i f P i , j > = t , 0 , o t h e r w i s e . B_{i,j}=\left\{ \begin{aligned} 1 , if P_{i,j} >= t ,\\ 0 , otherwise. \end{aligned} \right. Bi,j={1,ifPi,j>=t,0,otherwise.
但是标准的二值化方法是不可微的,导致网络无法端对端训练。为了解决这个问题,DB算法提出了可微二值化(Differentiable Binarization,DB)。可微二值化将标准二值化中的阶跃函数进行了近似,使用如下公式进行代替:
B ^ = 1 1 + e − k ( P i , j − T i , j ) \hat{B} = \frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}} B^=1+e−k(Pi,j−Ti,j)1
其中,P是上文中获取的概率图,T是上文中获取的阈值图,k是增益因子,在实验中,根据经验选取为50。标准二值化和可微二值化的对比图如 下图3(a) 所示。
当使用交叉熵损失时,正负样本的loss分别为 l + l_+ l+ 和 l − l_- l− :
l + = − l o g ( 1 1 + e − k ( P i , j − T i , j ) ) l_+ = -log(\frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}}) l+=−log(1+e−k(Pi,j−Ti,j)1)
l − = − l o g ( 1 − 1 1 + e − k ( P i , j − T i , j ) ) l_- = -log(1-\frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}}) l−=−log(1−1+e−k(Pi,j−Ti,j)1)
对输入 x x x 求偏导则会得到:
δ l + δ x = − k f ( x ) e − k x \frac{\delta{l_+}}{\delta{x}} = -kf(x)e^{-kx} δxδl+=−kf(x)e−kx
δ l − δ x = − k f ( x ) \frac{\delta{l_-}}{\delta{x}} = -kf(x) δxδl−=−kf(x)
可以发现,增强因子会放大错误预测的梯度,从而优化模型得到更好的结果。图3(b) 中, x < 0 x<0 x<0 的部分为正样本预测为负样本的情况,可以看到,增益因子k将梯度进行了放大;而 图3(c) 中 x > 0 x>0 x>0 的部分为负样本预测为正样本时,梯度同样也被放大了。
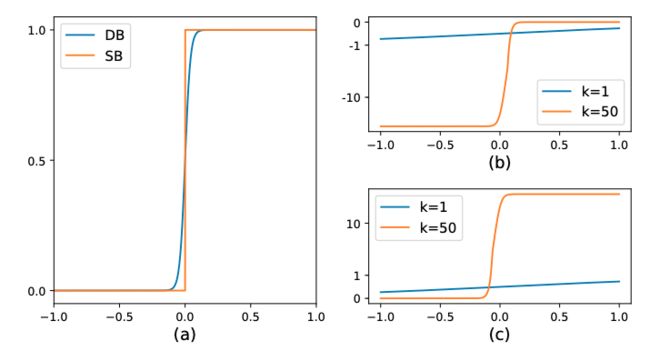
图3:DB算法示意图
DB算法整体结构如下图所示:

图2 DB模型网络结构示意图
输入的图像经过网络Backbone和FPN提取特征,提取后的特征级联在一起,得到原图四分之一大小的特征,然后利用卷积层分别得到文本区域预测概率图和阈值图,进而通过DB的后处理得到文本包围曲线。
2.1.2 DB文本检测模型构建
DB文本检测模型可以分为三个部分:
- Backbone网络,负责提取图像的特征
- FPN网络,特征金字塔结构增强特征
- Head网络,计算文本区域概率图
本节使用PaddlePaddle分别实现上述三个网络模块,并完成完整的网络构建。
backbone网络
DB文本检测网络的Backbone部分采用的是图像分类网络,论文中使用了ResNet50,本节实验中,为了加快训练速度,采用MobileNetV3 large结构作为backbone。
2.1.3 数据预处理
训练时对输入图片的格式、大小有一定的要求,同时,还需要根据标注信息获取阈值图以及概率图的真实标签。所以,在数据输入模型前,需要对数据进行预处理操作,使得图片和标签满足网络训练和预测的需要。另外,为了扩大训练数据集、抑制过拟合,提升模型的泛化能力,还需要使用了几种基础的数据增广方法。
本实验的数据预处理共包括如下方法:
- 图像解码:将图像转为Numpy格式;
- 标签解码:解析txt文件中的标签信息,并按统一格式进行保存;
- 基础数据增广:包括:随机水平翻转、随机旋转,随机缩放,随机裁剪等;
- 获取阈值图标签:使用扩张的方式获取算法训练需要的阈值图标签;
- 获取概率图标签:使用收缩的方式获取算法训练需要的概率图标签;
- 归一化:通过规范化手段,把神经网络每层中任意神经元的输入值分布改变成均值为0,方差为1的标准正太分布,使得最优解的寻优过程明显会变得平缓,训练过程更容易收敛;
- 通道变换:图像的数据格式为[H, W, C](即高度、宽度和通道数),而神经网络使用的训练数据的格式为[C, H, W],因此需要对图像数据重新排列,例如[224, 224, 3]变为[3, 224, 224];
更多内容请参考:https://aistudio.baidu.com/education/group/info/25207
2.2 快速开始
- 安装PaddlePaddle
如果您没有基础的Python运行环境,请参考运行环境准备。
-
您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple -
您的机器是CPU,请运行以下命令安装
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照飞桨官网安装文档中的说明进行操作。
- 安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
- 对于Windows环境用户:直接通过pip安装的shapely库可能出现
[winRrror 126] 找不到指定模块的问题。建议从这里下载shapely安装包完成安装。
- 命令行使用
PaddleOCR提供了一系列测试图片,点击这里下载并解压,然后在终端中切换到相应目录
cd /path/to/ppocr_img
如果不使用提供的测试图片,可以将下方--image_dir参数替换为相应的测试图片路径。
2.2.1 中英文模型
-
检测+方向分类器+识别全流程:
--use_angle_cls true设置使用方向分类器识别180度旋转文字,--use_gpu false设置不使用GPUpaddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false结果是一个list,每个item包含了文本框,文字和识别置信度
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)] ......此外,paddleocr也支持输入pdf文件,并且可以通过指定参数
page_num来控制推理前面几页,默认为0,表示推理所有页。paddleocr --image_dir ./xxx.pdf --use_angle_cls true --use_gpu false --page_num 2
-
单独使用检测:设置
--rec为falsepaddleocr --image_dir ./imgs/11.jpg --rec false结果是一个list,每个item只包含文本框
[[27.0, 459.0], [136.0, 459.0], [136.0, 479.0], [27.0, 479.0]] [[28.0, 429.0], [372.0, 429.0], [372.0, 445.0], [28.0, 445.0]] ...... -
单独使用识别:设置
--det为falsepaddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.994467]
版本说明
paddleocr默认使用PP-OCRv4模型(--ocr_version PP-OCRv4),如需使用其他版本可通过设置参数--ocr_version,具体版本说明如下:
| 版本名称 | 版本说明 |
|---|---|
| PP-OCRv4 | 支持中、英文检测和识别,方向分类器,支持多语种识别 |
| PP-OCRv3 | 支持中、英文检测和识别,方向分类器,支持多语种识别 |
| PP-OCRv2 | 支持中英文的检测和识别,方向分类器,多语言暂未更新 |
| PP-OCR | 支持中、英文检测和识别,方向分类器,支持多语种识别 |
如需新增自己训练的模型,可以在paddleocr中增加模型链接和字段,重新编译即可。
2.2.2 多语言模型
PaddleOCR目前支持80个语种,可以通过修改--lang参数进行切换,对于英文模型,指定--lang=en。
paddleocr --image_dir ./imgs_en/254.jpg --lang=en
结果是一个list,每个item包含了文本框,文字和识别置信度
[[[67.0, 51.0], [327.0, 46.0], [327.0, 74.0], [68.0, 80.0]], ('PHOCAPITAL', 0.9944712519645691)]
[[[72.0, 92.0], [453.0, 84.0], [454.0, 114.0], [73.0, 122.0]], ('107 State Street', 0.9744491577148438)]
[[[69.0, 135.0], [501.0, 125.0], [501.0, 156.0], [70.0, 165.0]], ('Montpelier Vermont', 0.9357033967971802)]
......
常用的多语言简写包括
| 语种 | 缩写 | 语种 | 缩写 | 语种 | 缩写 | ||
|---|---|---|---|---|---|---|---|
| 中文 | ch | 法文 | fr | 日文 | japan | ||
| 英文 | en | 德文 | german | 韩文 | korean | ||
| 繁体中文 | chinese_cht | 意大利文 | it | 俄罗斯文 | ru |
全部语种及其对应的缩写列表可查看多语言模型教程
2.2.3 中英文与多语言使用
通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。
- 检测+方向分类器+识别全流程
from paddleocr import PaddleOCR, draw_ocr
#Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
#例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
#显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
结果是一个list,每个item包含了文本框,文字和识别置信度
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)]
......
结果可视化
如果输入是PDF文件,那么可以参考下面代码进行可视化
from paddleocr import PaddleOCR, draw_ocr
#Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
#例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=2) # need to run only once to download and load model into memory
img_path = './xxx.pdf'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
#显示结果
import fitz
from PIL import Image
import cv2
import numpy as np
imgs = []
with fitz.open(img_path) as pdf:
for pg in range(0, pdf.pageCount):
page = pdf[pg]
mat = fitz.Matrix(2, 2)
pm = page.getPixmap(matrix=mat, alpha=False)
# if width or height > 2000 pixels, don't enlarge the image
if pm.width > 2000 or pm.height > 2000:
pm = page.getPixmap(matrix=fitz.Matrix(1, 1), alpha=False)
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
imgs.append(img)
for idx in range(len(result)):
res = result[idx]
image = imgs[idx]
boxes = [line[0] for line in res]
txts = [line[1][0] for line in res]
scores = [line[1][1] for line in res]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result_page_{}.jpg'.format(idx))
3. 总结
本节介绍了PaddleOCR文本检测模型的快速使用方法,并且以DB算法为例,介绍了从数据处理到完成文本检测算法训练的实现过程。下一节将介绍文本识别算法的相关内容。
- 遇到如下图文字漏检测部分,该如何处理?
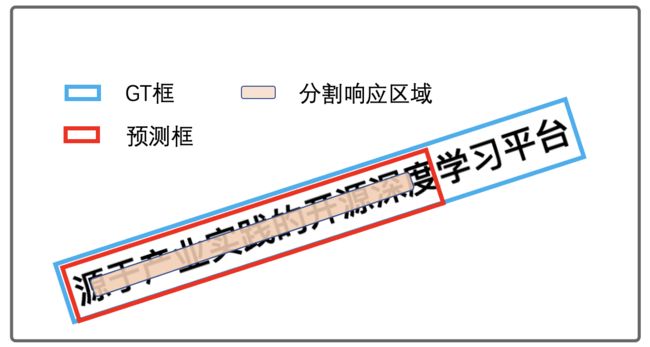
图 文字区域漏检测
上述问题表现检测了一部分文字,但是文本预测框和GT框的IOU大于阈值0.5,检测指标无法正常反馈出来,如果此类结果较多,建议增大IOU阈值。另外,漏检测的本质原因在于,一部分文字的特征没有响应,归根结底是网络没有学习到漏检测部分文字的特征。建议具体问题具体分析,可视化预测结果分析漏检测的原因,是否是因为光照,形变,文字较长等因素导致的,然后针对性的使用数据增强、调整网络、或者调整后处理等方法优化检测结果。
4.文本检测FAQ
本节罗列一些开发者们使用PaddleOCR的文本检测模型常遇到的一些问题,并给出相应的问题解决方法或建议。
FAQ分两个部分来介绍,分别是:
- 文本检测训练相关
- 文本检测预测相关
4.1. 文本检测训练相关FAQ
1.1 PaddleOCR提供的文本检测算法包括哪些?
A:PaddleOCR中包含多种文本检测模型,包括基于回归的文本检测方法EAST、SAST,和基于分割的文本检测方法DB,PSENet。
1.2:请问PaddleOCR项目中的中文超轻量和通用模型用了哪些数据集?训练多少样本,gpu什么配置,跑了多少个epoch,大概跑了多久?
A:对于超轻量DB检测模型,训练数据包括开源数据集lsvt,rctw,CASIA,CCPD,MSRA,MLT,BornDigit,iflytek,SROIE和合成的数据集等,总数据量越10W,数据集分为5个部分,训练时采用随机采样策略,在4卡V100GPU上约训练500epoch,耗时3天。
1.3 文本检测训练标签是否需要具体文本标注,标签中的”###”是什么意思?
A:文本检测训练只需要文本区域的坐标即可,标注可以是四点或者十四点,按照左上,右上,右下,左下的顺序排列。PaddleOCR提供的标签文件中包含文本字段,对于文本区域文字不清晰会使用###代替。训练检测模型时,不会用到标签中的文本字段。
1.4 对于文本行较紧密的情况下训练的文本检测模型效果较差?
A:使用基于分割的方法,如DB,检测密集文本行时,最好收集一批数据进行训练,并且在训练时,并将生成二值图像的shrink_ratio参数调小一些。另外,在预测的时候,可以适当减小unclip_ratio参数,unclip_ratio参数值越大检测框就越大。
1.5 对于一些尺寸较大的文档类图片, DB在检测时会有较多的漏检,怎么避免这种漏检的问题呢?
A:首先,需要确定是模型没有训练好的问题还是预测时处理的问题。如果是模型没有训练好,建议多加一些数据进行训练,或者在训练的时候多加一些数据增强。
如果是预测图像过大的问题,可以增大预测时输入的最长边设置参数det_limit_side_len,默认为960。
其次,可以通过可视化后处理的分割图观察漏检的文字是否有分割结果,如果没有分割结果,说明是模型没有训练好。如果有完整的分割区域,说明是预测后处理的问题,建议调整DB后处理参数。
1.6 DB模型弯曲文本(如略微形变的文档图像)漏检问题?
A: DB后处理中计算文本框平均得分时,是求rectangle区域的平均分数,容易造成弯曲文本漏检,已新增求polygon区域的平均分数,会更准确,但速度有所降低,可按需选择,在相关pr中可查看可视化对比效果。该功能通过参数 det_db_score_mode进行选择,参数值可选[fast(默认)、slow],fast对应原始的rectangle方式,slow对应polygon方式。感谢用户buptlihang提pr帮助解决该问题。
1.7 简单的对于精度要求不高的OCR任务,数据集需要准备多少张呢?
A:(1)训练数据的数量和需要解决问题的复杂度有关系。难度越大,精度要求越高,则数据集需求越大,而且一般情况实际中的训练数据越多效果越好。
(2)对于精度要求不高的场景,检测任务和识别任务需要的数据量是不一样的。对于检测任务,500张图像可以保证基本的检测效果。对于识别任务,需要保证识别字典中每个字符出现在不同场景的行文本图像数目需要大于200张(举例,如果有字典中有5个字,每个字都需要出现在200张图片以上,那么最少要求的图像数量应该在200-1000张之间),这样可以保证基本的识别效果。
1.8 当训练数据量少时,如何获取更多的数据?
A:当训练数据量少时,可以尝试以下三种方式获取更多的数据:(1)人工采集更多的训练数据,最直接也是最有效的方式。(2)基于PIL和opencv基本图像处理或者变换。例如PIL中ImageFont, Image, ImageDraw三个模块将文字写到背景中,opencv的旋转仿射变换,高斯滤波等。(3)利用数据生成算法合成数据,例如pix2pix等算法。
1.9 如何更换文本检测/识别的backbone?
A:无论是文字检测,还是文字识别,骨干网络的选择是预测效果和预测效率的权衡。一般,选择更大规模的骨干网络,例如ResNet101_vd,则检测或识别更准确,但预测耗时相应也会增加。而选择更小规模的骨干网络,例如MobileNetV3_small_x0_35,则预测更快,但检测或识别的准确率会大打折扣。幸运的是不同骨干网络的检测或识别效果与在ImageNet数据集图像1000分类任务效果正相关。飞桨图像分类套件PaddleClas汇总了ResNet_vd、Res2Net、HRNet、MobileNetV3、GhostNet等23种系列的分类网络结构,在上述图像分类任务的top1识别准确率,GPU(V100和T4)和CPU(骁龙855)的预测耗时以及相应的117个预训练模型下载地址。
(1)文字检测骨干网络的替换,主要是确定类似与ResNet的4个stages,以方便集成后续的类似FPN的检测头。此外,对于文字检测问题,使用ImageNet训练的分类预训练模型,可以加速收敛和效果提升。
(2)文字识别的骨干网络的替换,需要注意网络宽高stride的下降位置。由于文本识别一般宽高比例很大,因此高度下降频率少一些,宽度下降频率多一些。可以参考PaddleOCR中MobileNetV3骨干网络的改动。
1.10 如何对检测模型finetune,比如冻结前面的层或某些层使用小的学习率学习?
A:如果是冻结某些层,可以将变量的stop_gradient属性设置为True,这样计算这个变量之前的所有参数都不会更新了,参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/faq/train_cn.html#id4
如果对某些层使用更小的学习率学习,静态图里还不是很方便,一个方法是在参数初始化的时候,给权重的属性设置固定的学习率,参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api/paddle/fluid/param_attr/ParamAttr_cn.html#paramattr
实际上我们实验发现,直接加载模型去fine-tune,不设置某些层不同学习率,效果也都不错
1.11 DB的预处理部分,图片的长和宽为什么要处理成32的倍数?
A:和网络下采样的倍数(stride)有关。以检测中的resnet骨干网络为例,图像输入网络之后,需要经过5次2倍降采样,共32倍,因此建议输入的图像尺寸为32的倍数。
1.12 在PP-OCR系列的模型中,文本检测的骨干网络为什么没有使用SEBlock?
A:SE模块是MobileNetV3网络一个重要模块,目的是估计特征图每个特征通道重要性,给特征图每个特征分配权重,提高网络的表达能力。但是,对于文本检测,输入网络的分辨率比较大,一般是640*640,利用SE模块估计特征图每个特征通道重要性比较困难,网络提升能力有限,但是该模块又比较耗时,因此在PP-OCR系统中,文本检测的骨干网络没有使用SE模块。实验也表明,当去掉SE模块,超轻量模型大小可以减小40%,文本检测效果基本不受影响。详细可以参考PP-OCR技术文章,https://arxiv.org/abs/2009.09941.
1.13 PP-OCR检测效果不好,该如何优化?
A: 具体问题具体分析:
- 如果在你的场景上检测效果不可用,首选是在你的数据上做finetune训练;
- 如果图像过大,文字过于密集,建议不要过度压缩图像,可以尝试修改检测预处理的resize逻辑,防止图像被过度压缩;
- 检测框大小过于紧贴文字或检测框过大,可以调整db_unclip_ratio这个参数,加大参数可以扩大检测框,减小参数可以减小检测框大小;
- 检测框存在很多漏检问题,可以减小DB检测后处理的阈值参数det_db_box_thresh,防止一些检测框被过滤掉,也可以尝试设置det_db_score_mode为’slow’;
- 其他方法可以选择use_dilation为True,对检测输出的feature map做膨胀处理,一般情况下,会有效果改善;
4.2. 文本检测预测相关FAQ
2.1 DB有些框太贴文本了反而去掉了一些文本的边角影响识别,这个问题有什么办法可以缓解吗?
A:可以把后处理的参数unclip_ratio适当调大一点,该参数越大文本框越大。
2.2 为什么PaddleOCR检测预测是只支持一张图片测试?即test_batch_size_per_card=1
A:预测的时候,对图像等比例缩放,最长边960,不同图像等比例缩放后长宽不一致,无法组成batch,所以设置为test_batch_size为1。
2.3 在CPU上加速PaddleOCR的文本检测模型预测?
A:x86 CPU可以使用mkldnn(OneDNN)进行加速;在支持mkldnn加速的CPU上开启enable_mkldnn参数。另外,配合增加CPU上预测使用的线程数num_threads,可以有效加快CPU上的预测速度。
2.4 在GPU上加速PaddleOCR的文本检测模型预测?
A:GPU加速预测推荐使用TensorRT。
-
- 从链接下载带TensorRT的Paddle安装包或者预测库。
-
- 从Nvidia官网下载TensorRT版本,注意下载的TensorRT版本与paddle安装包中编译的TensorRT版本一致。
-
- 设置环境变量LD_LIBRARY_PATH,指向TensorRT的lib文件夹
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:
-
- 开启PaddleOCR预测的tensorrt选项。
2.5 如何在移动端部署PaddleOCR模型?
A: 飞桨Paddle有专门针对移动端部署的工具PaddleLite,并且PaddleOCR提供了DB+CRNN为demo的android arm部署代码,参考链接。
2.6 如何使用PaddleOCR多进程预测?
A: 近期PaddleOCR新增了多进程预测控制参数,use_mp表示是否使用多进程,total_process_num表示在使用多进程时的进程数。具体使用方式请参考文档。
2.7 预测时显存爆炸、内存泄漏问题?
A: 如果是训练模型的预测,由于模型太大或者输入图像太大导致显存不够用,可以参考代码在主函数运行前加上paddle.no_grad(),即可减小显存占用。如果是inference模型预测时显存占用过高,可以配置Config时,加入config.enable_memory_optim()用于减小内存占用。
另外关于使用Paddle预测时出现内存泄漏的问题,建议安装paddle最新版本,内存泄漏已修复。
参考链接
https://aistudio.baidu.com/education/group/info/25207
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。