今天来说一个老生常谈的问题,来看一个实际案例:
现有业务中往往都会通过缓存来提高查询效率,降低数据库的压力,尤其是在分布式高并发场景下,大量的请求直接访问Mysql很容易造成性能问题。
有一天老板找到了你......
老板:听说你会缓存?
你:来看我操作。

你设计了一个最常见的缓存方案,基于这种方案,开始对用户积分功能进行优化,但当你睡的正酣时,系统悄悄进行了下面操作:
1、线程A根据业务会把用户id为1的积分更新成100
2、 线程B根据业务会把用户id为1的积分更新成200
3、在数据库层面,由于数据库用锁来保证了ACID,线程A和线程B不存在并发情况,,无论数据库中最终的值是100还是200,我们都假设正确
4、假设线程B在A之后更新数据库,则数据库中的值为200
5、线程A和线程B在回写缓存过程中,很可能会发生线程A在线程B之后操作缓存的情况(因为网络调用存在不确定性),这个时候缓存内的值会被更新成100,发生了缓存和数据库不一致的情况。
第二天早上你收到了用户投诉,怎么办?人工修改积分值还是删库跑路?
凡是处于不同物理位置的两个操作,如果操作的是相同数据,都会遇到一致性问题,这是分布式系统不可避免的一个痛点。
1 什么是数据一致性?
数据一致性通常讲的主要是数据存储系统,主从mysql、分布式存储系统等,如何保证数据一致性,
比如说主从一致性,副本一致性,保证不同的时间或者相同的请求访问这种主从数据库时访问的数据是一致性的,不会这次访问是结果A下次是结果B。
2 CAP定理
说到数据一致性,就必须说CAP定理。
CAP定理是2000年由Brewer提出的,他认为分布式系统在设计和部署时,面临3个核心问题:
Consistency:一致性。数据库ACID操作是在一个事务中对数据加以约束,使得执行后仍处于一致状态,而分布式系统在进行更新操作时所有的用户都应该读到最新值。
Availability:可用性。每一个操作总是能够在一定时间内返回结果。结果可以是成功或失败,一定时间是给定的时间。
Partition Tolerance:分区容忍性。考虑系统效能和可伸缩性,是否可进行数据分区。
CAP定理认为,一个提供数据服务的存储系统无法同时满足数据一致性、数据可用性、分区容忍性。
为什么?如果采用分区,分布式节点之间就需要进行通信,涉及到通信,就会存在某一时刻这一节点只完成一部分业务操作,在通信完成的这一段时间内,数据就是不一致的。如果要保证一致性,就要 在通信完成的这段时间内保护数据,使得对访问这些数据的操作都不可用。
反过来思考,如果想保证一致性和可用性,那么数据就不能够分区。一个简单的理解就是所有的数据就必须存放在一个数据库里面,不能进行数据库拆分。这个对于大数据量、高并发的互联网应用来说,是不可接受的。
3 数据一致性模型
基于CAP定理,一些分布式系统通过复制数据来提高系统的可靠性和容错性,也就是将数据的不同副本存放在不同的机器。常用的一致性模型有:
强一致性: 数据更新完成后,任何后续访问将会返回最新的数据。这在分布式网络环境几乎不可能实现。
弱一致性:系统不保证数据更新后的访问会得到最新的数据。客户端获取最新的数据之前需要满足一些特殊条件。
最终一致性:是弱一致性的一种特例,保证用户最终能够读取到某操作对系统特定数据的更新。
4 如何保证数据一致性?
针对刚开始的问题,如果加以思考,你可能会发现不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。
(1)先删除缓存
1、如果先删除Redis缓存数据,然而还没有来得及写入MySQL,另一个线程就来读取;
2、这个时候发现缓存为空,则去Mysql数据库中读取旧数据写入缓存,此时缓存中为脏数据;
3、然后数据库更新后发现Redis和Mysql出现了数据不一致的问题。
(2)后删除缓存
1、如果先写了库,然后再删除缓存,不幸的写库的线程挂了,导致了缓存没有删除;
2、这个时候就会直接读取旧缓存,最终也导致了数据不一致情况;
3、因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
解决方案1:分布式锁
在平时开发中,利用分布式锁可能算是比较常见的解决方案了。利用分布式锁把缓存操作和数据库操作封装为逻辑上的一个操作可以保证数据的一致性,具体流程为:
1、每个想要操作缓存和数据库的线程都必须先申请分布式锁;
2、如果成功获得锁,则进行数据库和缓存操作,操作完毕释放锁;
3、如果没有获得锁,根据不同业务可以选择阻塞等待或者轮训,或者直接返回的策略。
流程见下图:
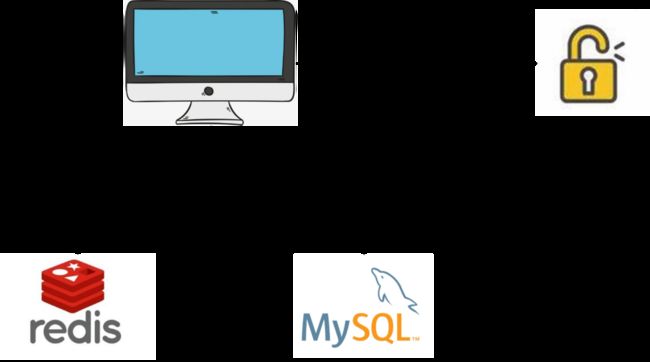
利用分布式锁是解决分布式事务的一种方案,但是在一定程度上会降低系统的性能,而且分布式锁的设计要考虑到down机和死锁的意外情况。
解决方案2:延迟双删
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下:
public void write( String key, Object data ){
redis.delKey( key );
db.updateData( data );
Thread.sleep( 500 );
redis.delKey( key );
}
具体步骤:
1、先删除缓存
2、再写数据库
3、休眠500毫秒(这个根据读取的业务时间来定)
4、再次删除缓存
来看之前的案例在这种方案下的情景:
T1线程线删除缓存再更新db , T1线程更新db完成之前T2线程如果读取到db旧的数据, 会再把旧的数据写入Redis缓存。
此时T1线程延迟一段时间后再删除Redis缓存操作. 当其他线程再读取缓存为null时会查询db最新数据重新进行缓存, 保证了Mysql和Redis缓存的数据一致性。
在此基础上,缓存也要设置过期时间,来保证最终数据的一致性。 只要缓存过期,就去读数据库然后重新缓存。
这种双删+缓存超时的策略,最差的情况是在缓存过期时间内发生数据存在不一致,而且写的时候增加了耗时。
但是这种方案还会出现一个问题,如何保证写入库后,再次删除缓存成功?
如果删除失败,还有可能出现数据不一致的情况。这时候需要提供一个重试方案。
解决方案3:异步更新缓存(基于Mysql binlog的同步机制)
1、涉及到更新的数据操作,利用Mysql binlog 进行增量订阅消费;
2、将消息发送到消息队列;
3、通过消息队列消费将增量数据更新到Redis上。
这样的效果是:
读取Redis缓存:热数据都在Redis上;
写Mysql:增删改都是在Mysql进行操作;
更新Redis数据:Mysql的数据操作都记录到binlog,通过消息队列及时更新到Redis上。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
方案2中的重试方案就可以借助方案3,启动一个订阅程序订阅数据库的binlog,提取所需要的数据和key,另起代码获取这些信息。如果尝试删除缓存失败,就发送消息给消息队列,重新从消息队列获取数据,重试删除操作。
参考文档:
- https://mp.weixin.qq.com/s/k38MZRAGmZ8EhDB5DcVhhQ
- https://baijiahao.baidu.com/s?id=1678826754388688520&wfr=spider&for=pc
- https://www.php.cn/faq/415782.html
- https://blog.csdn.net/u013256816/article/details/50698167
- https://blog.csdn.net/My\_Best\_bala/article/details/121977033?spm=1001.2101.3001.6661.1&utm\_medium=distribute.pc\_relevant\_t0.none-task-blog-2~default~CTRLIST~Rate-1.pc\_relevant\_antiscan&depth\_1-utm\_source=distribute.pc\_relevant\_t0.none-task-blog-2~default~CTRLIST~Rate-1.pc\_relevant\_antiscan&utm\_relevant_index=1
感谢阅读~
作者:京东零售 李泽阳
来源:京东云开发者社区 转载请注明来源