在上一篇逻辑回归中,我们利用批量梯度下降算法BGD求解使损失函数J(θ)取得最小值的θ,同时也提到了SGD和MBGD,本篇我们实现下这三个算法,并进行简单比较。关于梯度下降算法的原理可以参考https://www.cnblogs.com/pinard/p/5970503.html。
1. 批量梯度下降法(Batch Gradient Descent)
批量梯度下降算法是梯度下降算法的最常用形式,即在更新参数时利用所有的样本来进行更新,参数的更新过程可写成:
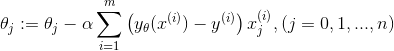
由于有m个样本,所以求梯度的时候就用了所有m个样本的梯度数据。
BGD的Python实现
def BGD_LR(data_x, data_y, alpha=0.1, maxepochs=10000, epsilon=1e-4):
xMat = np.mat(data_x)
yMat = np.mat(data_y)
m,n = xMat.shape
weights = np.ones((n,1)) #初始化模型参数
epochs_count = 0
loss_list = []
epochs_list = []
while epochs_count < maxepochs:
loss = cost(xMat,weights,yMat) #上一次损失值
hypothesis = sigmoid(np.dot(xMat,weights)) #预测值
error = hypothesis -yMat #预测值与实际值误差
grad = (1.0/m)*np.dot(xMat.T,error) #损失函数的梯度
last_weights = weights #上一轮迭代的参数
weights = weights - alpha*grad #参数更新
loss_new = cost(xMat,weights,yMat)#当前损失值
print(loss_new)
if abs(loss_new-loss)2. 随机梯度下降法(Stochastic Gradient Descent)
批量梯度下降算法每次更新参数都需要遍历整个数据集(通过遍历整个数据集来计算损失函数的梯度),那么在样本数据量巨大的时候,计算复杂度会很高。因此出现了随机梯度下降算法:即每次迭代都随机选取一个样本计算损失函数的梯度来更新参数。参数更新公式可变为:
与批量梯度下降算法相比,SGD的区别在于求梯度时没有用所有的m个样本数据,而是随机选取了一个样本i来求梯度。在样本量很大的时候,SGD由于仅采用了一个样本来迭代,因此训练速度很快,但很可能导致解不是最优的,准确度下降。
SGD的Python实现
def SGD_LR(data_x, data_y, alpha=0.1, maxepochs=10000,epsilon=1e-4):
xMat = np.mat(data_x)
yMat = np.mat(data_y)
m, n = xMat.shape
weights = np.ones((n, 1)) # 模型参数
epochs_count = 0
loss_list = []
epochs_list = []
while epochs_count < maxepochs:
rand_i = np.random.randint(m) # 随机取一个样本
loss = cost(xMat,weights,yMat) #前一次迭代的损失值
hypothesis = sigmoid(np.dot(xMat[rand_i,:],weights)) #预测值
error = hypothesis -yMat[rand_i,:] #预测值与实际值误差
grad = np.dot(xMat[rand_i,:].T,error) #损失函数的梯度
weights = weights - alpha*grad #参数更新
loss_new = cost(xMat,weights,yMat)#当前迭代的损失值
print(loss_new)
if abs(loss_new-loss)3. 小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降算法与随机梯度下降算法的折中,因为用一个样本代表全部可能不太准,那么选取其中一部分来代表全部的样本会比只用一个好很多。即对于m个样本,每次迭代选取其中x个样本进行更新参数,其中x称为小批量大小(1 MBGD的Python实现 运行结果 在小数据集上分别跑了这三种方法,可以看出SGD受噪声的影响,其损失函数的收敛伴随的震动比较大;而MBGD通过设置3个小批量明显减弱了收敛的震动现象,且更接近BGD训练得到的最小损失函数值。 BGD:每次迭代使用所有样本来计算损失函数的梯度 以上只是自己的学习反馈,如有错误,欢迎指正。def MBGD_LR(data_x, data_y, alpha=0.1,batch_size=3, maxepochs=10000,epsilon=1e-4):
xMat = np.mat(data_x)
yMat = np.mat(data_y)
m, n = xMat.shape
weights = np.ones((n, 1)) # 模型参数
epochs_count = 0
loss_list = []
epochs_list = []
while epochs_count < maxepochs:
randIndex = np.random.choice(range(len(xMat)), batch_size, replace=False)
loss = cost(xMat,weights,yMat) #前一次迭代的损失值
hypothesis = sigmoid(np.dot(xMat[randIndex],weights)) #预测值
error = hypothesis -yMat[randIndex] #预测值与实际值误差
grad = np.dot(xMat[randIndex].T,error) #损失函数的梯度
weights = weights - alpha*grad #参数更新
loss_new = cost(xMat,weights,yMat)#当前迭代的损失值
print(loss_new)
if abs(loss_new-loss)总结
SGD:每次迭代随机选取1个样本来计算损失函数的梯度
MBGD:每次迭代随机选取x个样本来计算损失函数的梯度
本文代码地址:https://github.com/DaHuangTyro/Daily_Machine_Learning