CelebA-HQ数据集下载【详细明了版】分辨率包括【64,128,256,512,1024】
CelebA-HQ数据集下载,分辨率包括【64,128,256,512,1024】
- 前言
- 下载&处理
-
- 1.下载合并解压img_celeba.7z
- 2.下载list_landmarks_celeba.txt
- 3.获取h5tool.py
- 4.mkdir
- 5. 下载.dat数据
- 配置环境
- 生成数据集
前言
CelebA-HQ 是在ICLR2018上,nVidia发表了一篇名为Progressive Growing of GANs for Improved Quality, Stability, and Variation的论文,文中通过训练高分辨率GAN生成了一个新的人脸数据集CelebA-HQ.CelebA是港科大汤晓鸥组收集的人脸数据集(总共200k图片),包括了人脸特征点(landmark),人脸属性(attribute)等信息,详细介绍参考链接[1]和[2]. CelebA-HQ是对CelebA的升级,总共30k图片,每一张的分辨率都是1024*1024,效果非常的好.
搞完下载&处理,最终目录如下:
参考https://zhuanlan.zhihu.com/p/52188519
修改了一部分。
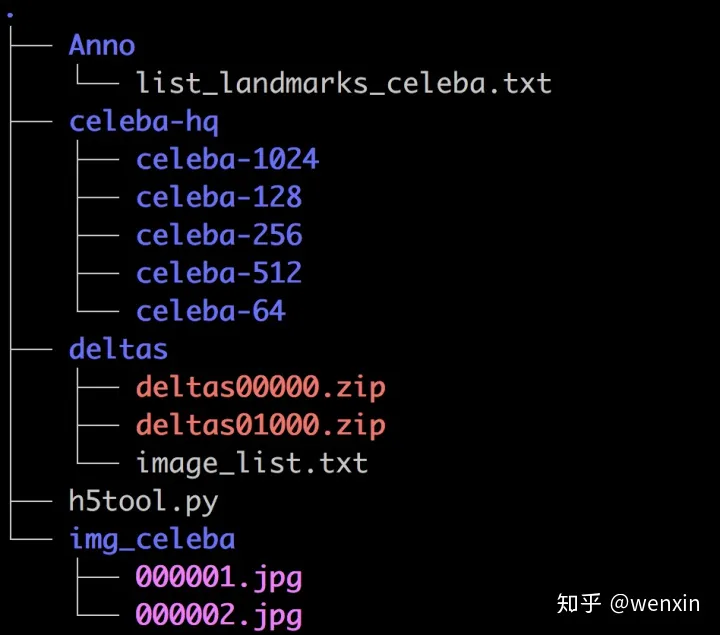
下载&处理
1.下载合并解压img_celeba.7z
点击下载链接:img_celeba.7z下载其中的img_celeba.7z(文件是14个压缩包分卷,分别是001-014)
已经下载好img_celeba.7z 需要将其中的14个压缩包解压,得到202599张原图。
原来的压缩包无法直接解压。
然后cd到下载目录,执行下面的命令:
linux:
cat img_celeba.7z.0** > img_celeba.7z
windows:
copy /B img_celeba.7z.0** img_celeba.7z
就可以合并压缩包,得到这个压缩包就可以直接解压得到202599张图片了。
合成的img_celeba.7z文件大小应为10.2 GB
解压该文件获取图片:
后缀名为“.7z"的文件需要7zip解压,于是先安装7zip:
sudo apt-get install p7zip-full
然后解压
7za x img_celeba.7z
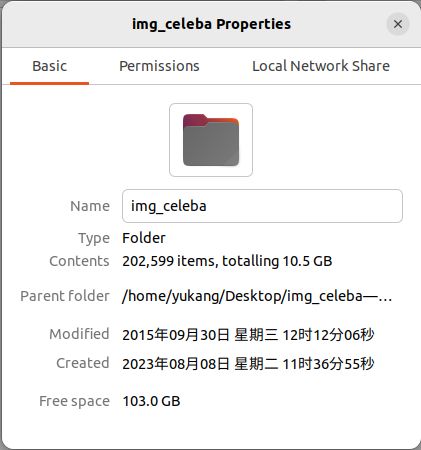
得到img_celeba文件夹,如下:(大小为10.5GB,有202599张图像)
2.下载list_landmarks_celeba.txt
下载链接链接:https://pan.baidu.com/s/1DLXoVozeqojIzO3JDIMYZQ
提取码:y7la
然后
mkdir Anno
并把并将list_landmarks_celeba.txt放在里面。
3.获取h5tool.py
在这个链接里面https://github.com/willylulu/celeba-hq-modified
git clone https://github.com/willylulu/celeba-hq-modified
4.mkdir
首先
mkdir celeba-hq
然后在该文件夹下面
cd celeba-hq
mkdir celeba-64
mkdir celeba-128
mkdir celeba-256
mkdir celeba-512
mkdir celeba-1024
5. 下载.dat数据
下载nVidia官方提供的.dat数据 , 我们需要下载30个压缩包(deltas00000-29000.zip),以及img_list.txt. 这次不需要解压。
下载链接是https://drive.google.com/drive/folders/1iGK3jDe_1-V0Lyy5468WNpb7y74u-iEp
mkdir deltas
将这31个文件放在deltas文件夹中。
配置环境
首先,在anaconda创建一个python是2.7的虚拟环境
conda create -n python2.7 python=2.7
下载依赖包
# 激活虚拟环境
conda activate python2.7
pip install numpy
pip install scipy
pip install pillow
pip install h5py
pip install cryptography
生成数据集
修改代码h5tool.py。
1、修改list_landmarks_celeba.txt文件的读取地址;
# with open(os.path.join(celeba_dir, '..', 'Anno', 'list_landmarks_celeba.txt'), 'rt') as file:
with open('./Anno/list_landmarks_celeba.txt', 'rt
在命令行里面运行程序生成图像(注意是cd到开始的根目录)
python h5tool.py create_celeba_hq celeba-hq-1024x1024.h5 ./ ./deltas
如下:

生成运行时间为:
2023/8/8 16:10 至 2023/8/9 9:00已完成,具体用时不知。小于17h
![]()
每个分辨率3万张图片,共15万张,大工告成!
下载链接在:
https://drive.google.com/drive/folders/11Vz0fqHS2rXDb5pprgTjpD7S2BAJhi1P。
有问题欢迎在评论区提问