DETR 系列 Mask Frozen-DETR: High Quality Instance Segmentation with One GPU 论文阅读笔记
DETR 系列 Mask Frozen-DETR: High Quality Instance Segmentation with One GPU 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 目标检测
- 实例分割
- 讨论
- 四、本文的 方法
-
- 4.1 Baseline 设置
-
- 结果
- 实验设置
- 4.2 图像特征编码器
-
- Deformable encoder block
- Swin Transformer encoder block
- ConvNext encoder block
- 结果
- 4.3 Box 特征编码器
-
- 通道映射器
- 结果
- 4.4 Query 特征编码器
-
- Object-to-Object attention
- Box-to-object attention
- FFN
- 结果
- 4.5 其他的提升
-
- 在采样像素点上的 Mask Loss
- Mask 打分
- 用于 Backbone 特征的 Neck 结构
- 结果
- 五、与 SOTA 的比较
- 六、消融实验与分析
-
-
- RoIAlign 的输出尺寸
- 训练的 Epoch
- 大尺度抖动
- 实例 mask 头的设计
- Bach Size
- 编码器特征图的层索引
- 图像特征编码器深度和 box 特征编码器的影响
- 微调 DETR 的效果
- 定性结果
-
- 七、结论
写在前面
这篇文章的亮点很明显,一个 GPU 就能跑起来!这种题目的构思方式值得学习。
- 论文地址:Mask Frozen-DETR: High Quality Instance Segmentation with One GPU
- 代码地址:arxiv 版本未提供
- 预计投稿于:某个顶会
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
本文旨在研究建立一个仅需最小训练时间和 GPU 的实例分割器,Mask Frozen-
DETR,能够将任何基于 DETR 的目标检测模型转化为一个实例分割模型。提出的方法仅需训练附加的轻量化 mask 网络,通过一个冻结的基于 DETR 的目标检测器在 Bounding box 内预测实例 mask。在 COCO 数据集上效果很好,仅需单张 V100 16G 卡即可进行训练。

二、引言
首先指出实例分割的难点,最近的一些方法:Cascade Mask R-CNN、Mask DINO。这些方法通常以 ResNet-50、Swin-L 为 Backbone,需要大量的 GPU 时间来训练。
本文表明现有的基于 DETR 的目标检测模型能够转化为实例分割模型。以 H \mathcal{H} H-DETR 和 DINO-DETR 为例,提出两个创新:设计一种轻量化的实例分割网络来有效利用冻结的 DETR 目标检测器的输出;论证本文提出的方法在不同尺度模型下的有效性。
三、相关工作
目标检测
目标检测是个基础研究领域,涉及大量的工作:Faster R-CNN、Cascade R-CNN、YOLO、DETR、Deformable DETR、DINO-DETR、 H \mathcal{H} H-DETR。本文的方法建立在这些基于 DETR 的方法之上,实现 SOTA 性能的同时有着 10 倍的训练速度。
实例分割
初始的实例分割方法基于 R-CNN 系列,先检测后分割的思想。例如 Mask R-CNN、 Casacde Mask R-CNN、HTC。有一些方法的设计比较简单:SOLO、QueryInst。有一些是基于 DETR 的方法:MaskFormer、Mask2Former、Mask-DINO。还有一些方法建立在 3D 实例分割的基础上,例如 SPFormer。
讨论
大多数实例分割模型并未利用离线的目标检测模型的权重,因而需要大量的训练时间。本文的方法采用冻结的基于 DETR 的模型,并引入轻量化的实例分割头。下图是一些方法的比较:
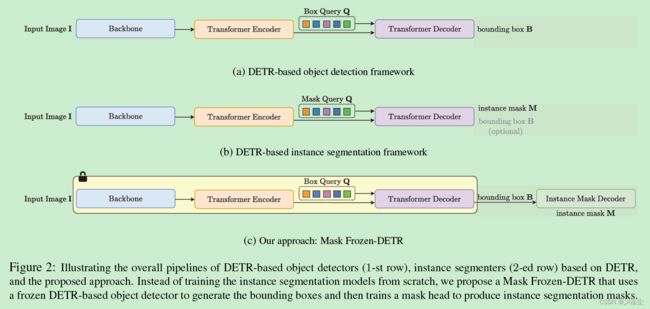
四、本文的 方法
4.1 Baseline 设置
采用 H \mathcal{H} H-DETR+ResNet50 作为 Baseline,并报道 H \mathcal{H} H-DETR+Swin-L 和 DINO-DETR+FocalNet-L 的对比性能。 H \mathcal{H} H-DETR+ResNet50 模型预训练在 Object365 数据集上,然后在 COCO 数据集上微调。
首先基于目标检测模型的最后一层 Transformer 解码器层输出的 queries 得分进行排序,选择出 top~100 个目标 queries 用于 mask 预测。然后将这些 queries { q i ∣ q i ∈ R d } i = 1 N \{{\mathbf{q}_i|\mathbf{q}_i\in\mathbb{R}^\mathsf{d}\}}_{i=1}^N {qi∣qi∈Rd}i=1N 与 1 / 4 1/4 1/4 原始分辨率的图像特征 F ∈ R H W 16 × d {\operatorname*{F}}\in\mathbb{R}^{\frac{\mathsf{H}\mathsf{W}}{16}\times\mathsf{d}} F∈R16HW×d 相乘,得到实例分割 masks:
F = C 1 + interpolate ( E ) M i = interpolate ( reshape ( Sigmoid ( q i F ⊤ ) ) ) \begin{aligned} \text{F}& =\mathrm{C}_1+\text{interpolate}(\mathbf{E}) \\ \mathrm{M}_{i}& =\text{interpolate}(\text{reshape}(\text{Sigmoid}(\mathbf{q}_i\mathbf{F}^\top))) \end{aligned} FMi=C1+interpolate(E)=interpolate(reshape(Sigmoid(qiF⊤)))
其中 C 1 ∈ R H W 16 × d \mathrm{C}_1\in\mathbb{R}^{\frac{\mathsf{H}\mathsf{W}}{16}\times\mathsf{d}} C1∈R16HW×d 表示 Backbone 第一阶段输出的特征图, E ∈ R H W 64 × d \mathbf{E}\in\mathbb{R}^{\frac{\mathsf{H}\mathsf{W}}{64}\times\mathsf{d}} E∈R64HW×d 表示 Transformer 编码器输出的 1 / 8 1/8 1/8 原始分辨率的特征图。 H \mathsf{H} H, W \mathsf{W} W, d \mathsf{d} d 分别表示输入图像的高、宽、特征隐藏维度。 M i ∈ R H W \mathrm{M}_{i}\in\mathbb{R}^{\mathsf{H}\mathsf{W}} Mi∈RHW 表示最后预测的 mask 概率图。下图为整体路线图:

接下来计算置信度得分,从而反应 mask 的质量:
s i = c i × s u m ( M i [ M i > 0.5 ] ) s u m ( [ M i > 0.5 ] ) \mathrm{s}_{i}=c_{i}\times\frac{\mathrm{sum}(\mathbf{M}_{i}[\mathbf{M}_{i}>0.5])}{\mathrm{sum}([\mathbf{M}_{i}>0.5])} si=ci×sum([Mi>0.5])sum(Mi[Mi>0.5])其中 c i c_i ci 表示第 i i i 个目标 query 的分类得分。
接下来在预测的 Bounding boxes 内采用 RoIAlign 来聚合用于定位的区域特征图:
R i = r e s h a p e ( R o I A l i g n ( r e s h a p e ( F ) , b i ) ) \mathbf{R}_i=\mathrm{reshape}(\mathrm{RoIAlign}(\mathrm{reshape}(\mathbf{F}),\mathbf{b}_i)) Ri=reshape(RoIAlign(reshape(F),bi))其中 R i ∈ R H W × d \mathbf{R}_i\in\mathbb{R}^{\mathsf{H}\mathsf{W}\times\mathsf{d}} Ri∈RHW×d, b i \mathbf{b}_i bi 表示根据 q i \mathbf{q}_i qi 预测的 bouding box。默认设置 h = 32 \mathsf{h}=32 h=32, w = 32 \mathsf{w}=32 w=32。之后计算实例分割 mask:
M i r = paste ( interpolate ( reshape ( Sigmoid ( q i R i ⊤ ) ) ) ) \mathbf{M}_i^r=\text{paste}(\text{interpolate}(\text{reshape}(\text{Sigmoid}(\mathbf{q}_i\mathbf{R}_i^\top)))) Mir=paste(interpolate(reshape(Sigmoid(qiRi⊤))))首先将预测的区域 masks 变形和缩放为原始图像尺寸,并将其粘贴到一个空的 mask 上。同样以类似的方式基于 M i r \mathbf{M}_i^r Mir 来计算置信度得分。
结果

根据上表 Baseline 的实验,表明可以从三个方面来提升模型的性能:图像特征编码器的设计、box 区域特征编码器的设计、query 特征编码器的设计。
接下来在消融实验中通过冻结整体的目标检测器网络,仅仅微调附加引入的参数,约 6 个 epoch 的训练。
实验设置
AdamW 优化器,初始学习率 1.5 × 1 0 − 4 1.5\times10^{-4} 1.5×10−4, β 1 = 0.9 \beta_1 =0.9 β1=0.9, β 2 = 0.999 \beta_2 =0.999 β2=0.999,权重衰减 5 × 1 0 − 5 5\times10^{-5} 5×10−5,训练模型 88500 次,即 6 个 epoch,在 0.9 和 0.95 个迭代次数时,学习率衰减 10%。数据预处理的步骤与 Deformable DETR 相同,Batch_size 8,所有的实验均在单 V100 16G 卡上进行,评估指标 COCO:AP,AP50,AP75,APS,APM,APL。
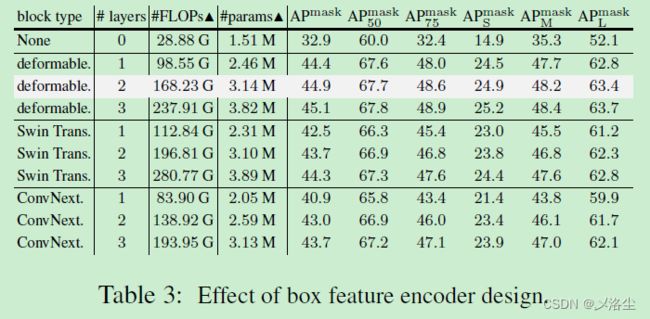
4.2 图像特征编码器
首先整合一个可训练的图像特征编码器,将图像特征图转化为一个更合适的特征空间用于实例分割 masks,下图表明了整体的路线图:

如上图所示,在 Transformer 编码器中应用图像特征编码器到特征图 E \mathbf{E} E 中:
F = C 1 + interpolate ( F e ( E ) ) \mathrm{F}=\mathrm{C}_1+\text{interpolate}(\mathcal{F}_e(\mathrm{E})) F=C1+interpolate(Fe(E))其中 F e \mathcal{F}_e Fe 表示图像特征编码器,旨在同时提炼所有目标 queries 的图像特征图。其结构由三种类型的卷积或 Transformer block 块组成。
Deformable encoder block
采用多尺度 deformable encoder 的设计堆叠多尺度 deformable encoder blocks,从而增强多尺度特征图:
E = [ E 1 , E 2 , E 3 , E 4 ] F e ( E ) = MultiScaleDeformable E n c ( ∣ E 1 , E 2 , E 3 , E 4 ∣ ) \begin{aligned} \text{E}& =[\mathbf{E}_1,\mathbf{E}_2,\mathbf{E}_3,\mathbf{E}_4] \\ \mathcal{F}_e(\mathbf{E})& =\text{MultiScaleDeformable}\mathrm{Enc}(|\mathbf{E}_1,\mathbf{E}_2,\mathbf{E}_3,\mathbf{E}_4|) \end{aligned} EFe(E)=[E1,E2,E3,E4]=MultiScaleDeformableEnc(∣E1,E2,E3,E4∣)其中 E 1 \mathbf{E}_1 E1, E 2 \mathbf{E}_2 E2, E 3 \mathbf{E}_3 E3, E 4 \mathbf{E}_4 E4 分别表示目标检测器中 Transformer 编码器的不同尺度的特征图。每个多尺度 deformable encoder 遵循着 MSDeformAttn → LayerNorm → FFN → LayerNorm 的设计,而 FFN 采用 Linear → GELU → Linear 的设计。
Swin Transformer encoder block
沿用 Swin Transformer 的设计,应用堆叠的多个 Swin Transformer blocks 在最高分辨率的特征图 E 1 \mathbf{E}_1 E1 上:
F e ( E 1 ) = SwinTransformer E n c ( E 1 ) \mathcal{F}_e(\mathbf{E}_1)=\text{SwinTransformer}\mathrm{Enc}(\mathbf{E}_1) Fe(E1)=SwinTransformerEnc(E1)其中每个 Swin Transformer block 都是沿着 LayerNorm → W-MSA → LayerNorm → FFN 的路线。W-MSA 表示滑动窗口的多头自注意力操作。
ConvNext encoder block
应用 ConvNext encoder block 在 Transformer encoder 的特征图上:
F e ( E 1 ) = ConvNextBlock ( E 1 ) \mathcal{F}_e(\mathbf{E}_1)=\text{ConvNextBlock}(\mathbf{E}_1) Fe(E1)=ConvNextBlock(E1)其中每个 ConvNext block 沿着 DWC → LayerNorm → FFN 的路线,DWC 表示大尺度卷积核 7 × 7 7\times7 7×7 的逐深度卷积。
结果

4.3 Box 特征编码器
Box 特征编码器路线图如下图所示:

如上图所示,在 R i \mathbf{R}_i Ri 中简单的添加一个额外的 transformer 层:
R i = F b ( R i ) \mathbf{R}_i=\mathcal{F}_b(\mathbf{R}_i) Ri=Fb(Ri)与图像特征编码器类似,研究不同的 box 特征编码器的结构对于模型性能的影响。
通道映射器
使用通道映射器作为一个简单的线性层来减少 F ∈ R H W 16 × d \mathbf{F}\in{\mathbb{R}}^{\frac{\mathsf{HW}}{16}\times\mathsf{d}} F∈R16HW×d 的特征通道维度,并将 box 区域特征编码器应用在更新后的特征图上。
结果

4.4 Query 特征编码器
Object-to-Object attention
目标之间的彼此接近可能会导致多个实例在同一个 Bounding box 内,于是添加 Object-to-Object 注意力来辅助 Object Query 彼此间能够区分开来。具体来说,使用多头注意力机制来处理 Queries:
[ q 1 , q 2 , ⋯ , q N ] = SelfAttention ( [ q 1 , q 2 , ⋯ , q N ] ) [\mathbf{q}_1,\mathbf{q}_2,\cdots,\mathbf{q}_N]=\text{SelfAttention}([\mathbf{q}_1,\mathbf{q}_2,\cdots,\mathbf{q}_N]) [q1,q2,⋯,qN]=SelfAttention([q1,q2,⋯,qN])
Box-to-object attention
在冻结的基于 DETR 的目标检测器中,目标 queries 用于执行目标检测并处理整个图像特征,而非单个的区域特征。于是引入 Box-to-object 注意力将 queries 转化为适应分割任务的 queries:
q i = CrossAttention ( q i , R i ) \mathbf{q}_i=\text{CrossAttention}(\mathbf{q}_i,\mathbf{R}_i) qi=CrossAttention(qi,Ri)其中目标 queries 通过指代的 box 区域特征来更新。
FFN
FFN对调整 Object query 表示可能也有一个辅助作用。
结果

结论:仅采用 Box-to-object 注意力的设计就可以了。
4.5 其他的提升
在采样像素点上的 Mask Loss
在最终损失的计算过程中,引入采样点的 Mask 损失。具体来说,考虑 N N N 个点,过采样率 k ( k > 1 ) k~(k>1) k (k>1),采样率 β ( β ∈ [ 0 , 1 ] ) \beta~(\beta\in[0,1]) β (β∈[0,1])。从输出的 mask 中随机采样 k N kN kN 个点,并从这些采样点中随机选择 β N \beta N βN 个点。然后随机采样其他的 ( 1 − β ) N (1-\beta) N (1−β)N 个点,计算这 N N N 个点的损失。
Mask 打分
由于冻结的 DETR 输出的分类得分不能反应分割 mask 的质量,于是引入 Mask 打分来调整分类分数。具体来说, mask 打分头以 mask 和 box 区域特征作为输入,来预测输出的 masks 和 GT 的 IoU 得分:
i o u i = M L P ( F l a t t e n ( C o n v ( C a t ( M i , R i ) ) ) ) \mathrm{iou}_i=\mathrm{MLP}(\mathrm{Flatten}(\mathrm{Conv}(\mathrm{Cat}(\mathbf{M}_i,\mathbf{R}_i)))) ioui=MLP(Flatten(Conv(Cat(Mi,Ri))))其中 Cat、Conv、MLP 分别表示拼接操作、卷积层、多层感知机。通过 mask 打分头预测出的 iou 得分用于调整分类分数:
s i = c i i o u i \mathrm{s}_i=\mathrm{c}_i\mathrm{i}\mathrm{o}\mathrm{u}_i si=ciioui其中 s i s_i si 为输出 mask 的置信度得分。
用于 Backbone 特征的 Neck 结构
Backbone 第一阶段输出的特征 C 1 ∈ R H W 16 × d \mathbf{C}_1\in\mathbb{R}^{\frac{\mathsf{HW}}{16}\times\mathsf{d}} C1∈R16HW×d 可能不会包含充分的语义信息。于是引入一个简单的 neck 块来编码语义信息到高分辨率的特征图 C 1 \mathbf{C}_1 C1:
C 1 = G N ( P W C o n v ( C 1 ) ) \mathbf{C}_1=\mathrm{GN}(\mathrm{PWConv}(\mathbf{C}_1)) C1=GN(PWConv(C1))其中 G N \mathrm{GN} GN 和 P W C o n v \mathrm{PWConv} PWConv 分别指组正则化和逐点卷积。
结果

五、与 SOTA 的比较

六、消融实验与分析
RoIAlign 的输出尺寸

训练的 Epoch

大尺度抖动

实例 mask 头的设计

Bach Size

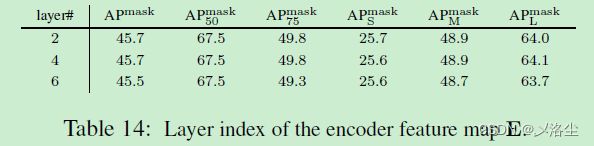
编码器特征图的层索引
图像特征编码器深度和 box 特征编码器的影响

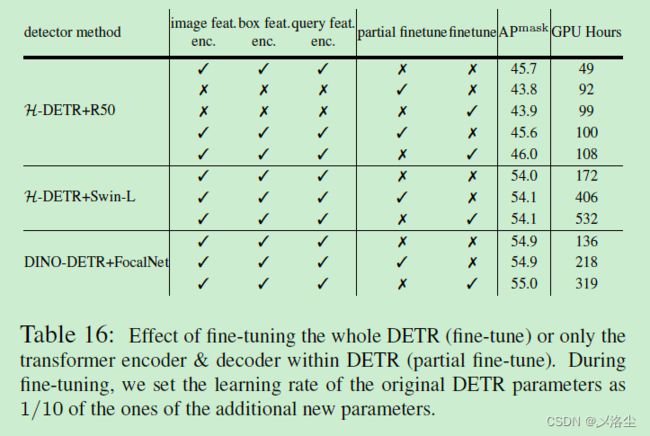
微调 DETR 的效果
定性结果

七、结论
本文详细展示了如何采用最小的训练时间和成本,将离线的基于 DETR 的目标检测模型转化为实例分割模型。实验表明很有效。
写在后面
拖了这么久终于写完这篇博文了。文章思路是借鉴 Parameter-Efficiency 的思想,引入新的结构来微调原有的模型,还是有点东西的。尤其是实验非常充足。缺点也有,Fig1 论文中并未引用;消融实验很多没必要全部分开,可以合并几个。