Rasa 多轮对话机器人
Rasa 开源机器人
目录
Rasa 开源机器人
1. 学习资料
2. Rasa 安装
2.1. rasa 简介
2.2. Rasa系统结构
编辑
2.3. 项目的基本流程
编辑
2.4. Rasa安装
2.5. 组件介绍
3. Rasa NLU
3.0. NLU 推理输出格式
3.1. 训练数据 ./data/nlu.yml 数据文件
3.2. ./config.yml配置文件
4. Rasa Core
4.1. 领域
4.2. 动作Action
4.2.1. 回复动作
4.2.2. 表单
4.2.3. 默认动作
4.2.2. 自定义动作
4.3. 词槽slots
4.3.1. 词槽的映射
4.4. 回复
4.5. 会话配置
4.6. 全局设置
4.7. 故事 story ./data/stories.yml
4.8. 策略 policy
4.8.1. 策略配置policy ./config.yml
4.9. 数据增强
4.10. 端点 ./endpoints.yml
5. Rasa SDK 和自定义动作
5.1. 安装
5.2. 自定义动作action
5.2.1. tracker对象
5.2.2. 事件对象 event
5.3. Rasa支持的客户端 ./credentials.yml
6. Rasa 使用ResponseSelector实现FAQ和闲聊功能
6.1. 自定义用户问题
6.2. 自定义用户答案 ./domain.yml
6.3. 如何训练Rasa
1. 学习资料
线上版:Rasa 实战:构建开源对话机器人 - 手册 - 文江博客 (wenjiangs.com)
离线版:Rasa 实战:构建开源对话机器人
章节附带代码:
GitHub - Chinese-NLP-book/rasa_chinese_book_code: 《Rasa实战:构建开源对话机器人》官方随书代码 | The official source code of Rasa in Action: Building Open Source Conversational AI
2. Rasa 安装
2.1. rasa 简介
- Rasa NLU:提取用户想要做什么和关键的上下文信息
- Rasa Core:基于对话历史,选择最优的回复和动作
- 通道(channel)和动作(action):连线对话机器人与用户及后端服务系统。
- tracker store、lock store和event broker等辅助系统
2.2. Rasa系统结构
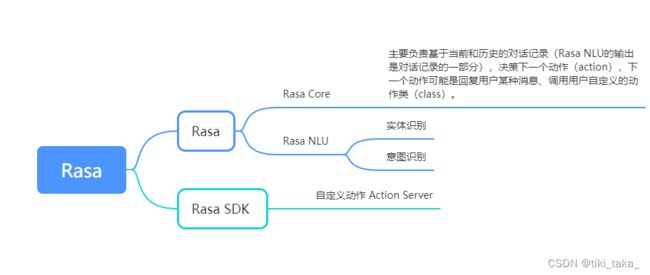
graph TD
client --> rasa_nlu
rasa_nlu --> rasa_core
rasa_core --> action_server
action_server --> rasa_core
rasa_core --> client
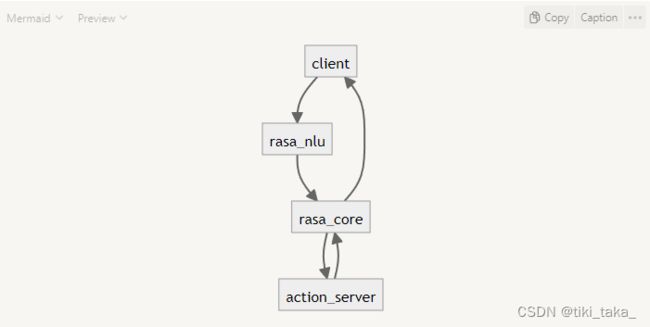
2.3. 项目的基本流程
graph TD
初始化项目 --> 准备NLU训练数据 --> 配置NLU模型 --> 准备故事数据 -->
定义领域domain --> 配置RasaCore模型 --> 训练模型--> 测试机器人 --> 上线
2.4. Rasa安装
conda create -n rasa3py39 python=3.9
activate rasa3py39
pip install rasa
pip3 install rasa-x --extra-index-url
2.5. 组件介绍
- 组件之间的顺序关系至关重要。例如,NER组件需要前面的组件提供分词结果才能正常工作,因此前面的组件中必须有一个分词器。
- 组件是可以相互替换的。例如,清华大学开发的分词器和北京大学开发的分词器均能提供分词结果。
- 有些组件是互斥的。例如,分词结果不能同时由两个分词器提供,否则会出现混乱。
- 有些组件是可以同时使用的。例如,提取文本特征的组件可以同时使用基于规则的和基于文本嵌入向量的组件。
| 组件名称 | 功能 | 模型 |
|---|---|---|
| 语言模型 | 为了加载模型文件,为后续的组件提供框架支持,如初始化spaCy和BERT。 | spacyNLP MitieNLP |
| 分词组件 | 将文本分割成词,为后续的高级NLP任务提供基础数据。 | JiebaTokenizer MitieTokenizer spaCyTokenizer |
| 特征提取组件 | 提取词语序列的文本特征。可以同时使用多个特征提取组件。 | MitieFeatuizer spaCyFeatuizer ConveRTFeatuizer LanguageModelFeaturizer RegexFeatuizer LexicalSyntacticFeaturizer |
| NER组件 | 根据前面提供的特征对文本进行命名实体的识别。 | CRFEntityExtractor spaCyEntityExtractor DucklingHTTPExtractor EntitySynonymMapper DIENTClassifer RegexEntityExtractor |
| 意图分类组件 | 按照语义对文本进行意图的分类,也称意图识别组件。 | MitiieIntentClassifier SklearnIntentClassifier KeywordIntentClassifier DIETClassifier FallbackClassifier |
| 结构化输出组件 | 将预测结果整理成结构化数据并输出。这一部分功能不是以组件的形式提供的,而是流水线内建的功能,开发者不可见。 |
| 组件 | 命令 | 含义 |
|---|---|---|
| NLU | rasa train nlu | 这条命令将会从data/目录查找训练数据,使用config.yml作为流水线配置并将训练后的模型(一个压缩文件)保存在models/目录中,模型的名字以nlu-为前缀。 |
| rasa shell nlu | 命令行和模型交互的命令 | |
| rasa shell -m models/nlu- |
-m 指定运行的模型 | |
| rasa run --enable-api | curl http://localhost:5005/model/parse -d ‘{”text”:“hello”}‘ | |
3. Rasa NLU
NLU 负责实体和意图识别,大体上NLU配置文件可以分为3个主要的键“recipe、language、pipeline
3.0. NLU 推理输出格式
输出内容主要包含Text、intent、entities,分别表示请求文本、意图识别和实体识别
NLU 推理输出格式如下:
{
"text":"show me chinese restaurants",
"intent":"restaurant_search",
"entities":[
"start":8,
"end":15,
"value":"chinese",
"entity":"cuisine",
"extractor":"CRFEntityExtractor",
"confidence":0.855,
"processors":[]
]
}
3.1. 训练数据 ./data/nlu.yml 数据文件
| component组件 | 配置文件 | 字段 | 含义 |
|---|---|---|---|
| RasaNLU | nlu.yml | intent | 意图,不能包含“/”字符 |
| synonym | 同义词 | ||
| lookup | 查找表字段 | ||
| regex | 正则表达式字段 | ||
意图字段中不能包含“/”字符,
- 具有synonym键表明当前的对象是用来存储同义词信息的。例如,西红柿是番茄的同义词,后者更为正式。在启动EntitySynonymMapper组件(后续章节将会介绍)的情况下,推理时会将得到的实体值的同义词替换成它的“标准词”。提取的实体值无论是蕃茄、西红柿,还是洋柿子,都会将实体的具体值替换成“标准词”:番茄。这个特性只会修改实体的值,并不会影响实体的类型。注意:同义词是在实体被识别后实体的值被替换成标准值的过程中使用的,因此同义词定义不会对实体识别的提高有帮助,只会帮助后续对话处理动作更统一地处理实体的值。
- lookup:查找表字段。具有lookup键表明当前的对象是用来存储查找表的。在实体识别和意图识别的时候,如果开发者能给这些组件一些额外的特征,那么将提高这些组件的准确度。其中一种方式就是提供一个特征词列表,这个特征词列表就是查找表。
version: "3.1"
nlu:
- intent: greet
examples: |
- 你好
- 您好
- 喂
- 在么
- synonmy: 番茄
examples: |
- 番茄
- 番茄炒蛋
- 洋柿子
- 火柿子
- 西红柿
- lookup: 城市
examples: |
- 北京
- 南京
- 广州
- regex: 帮助
examples: |
- \\b帮助\\b
3.2. ./config.yml配置文件
# step2:
recipe: default.v1
assistant_id: placeholder_default
# Configuration for Rasa NLU.
# for more information.
# - name: WhitespaceTokenizer
# - name: RegexFeaturizer
# - name: LexicalSyntacticFeaturizer
# - name: CountVectorsFeaturizer
# - name: CountVectorsFeaturizer
# analyzer: char_wb
# min_ngram: 1
# max_ngram: 4
# - name: DIETClassifier
# epochs: 100
# constrain_similarities: true
# - name: EntitySynonymMapper
# - name: ResponseSelector
# epochs: 100
# constrain_similarities: true
# - name: FallbackClassifier
# threshold: 0.3
# ambiguity_threshold: 0.1
-name: JiebaTokenizer
-name: **LanguageModelFeaturizer**
model_name:"bert"
model_weights: "bert-base-chinese"
-name: "DIETClassifier"
- language:en→zh
- pipeline:组件
- Rasa中JiebaTokenizer、LanguageModelTokenizer、DIETClassifier各自的作用及区别
- DIETClassifier作
- DIETClassifier是一种意图分类和实体提取的深度学习模型。基于Transformers的结构,使用了一个双向的循环神经网络来处理文本,并生成一个上下文相关的表示。这个表示同时包括了文本中的语义信息、实体信息及对话历史信息。
- 使用 DIETClassifier 可以显著提高机器人的性能,因为它可以从更全面的角度理解用户的输入,并精确地确定用户的意图和提取所需的实体信息。此外,DIETClassifier 还可以通过正则化、Dropout等技巧来避免过拟合,从而提高模型的泛化能力。总之,DIETClassifier 是 Rasa 机器人的核心组件之一,可以大幅提升机器人的智能水平和交互效果。
- rasa 中 LanguageModelFeaturizer 与 DIETClassifier 的区别
- 在 Rasa 中,LanguageModelFeaturizer 和 DIETClassifier 都是用于意图分类和实体提取的关键组件,但它们的作用不同。
- LanguageModelFeaturizer 主要用于将输入文本转换成句子嵌入向量(sentence embedding vector),这些向量捕捉了文本中的语义信息。它使用预训练的语言模型来生成这些句子嵌入向量,例如 Google 的 BERT 模型或 OpenAI 的 GPT-3 模型。在生成这些向量后,LanguageModelFeaturizer 将其传递给 DIETClassifier,DIETClassifier 然后使用这些向量来进行意图分类和实体提取。
- 相对应地,DIETClassifier 是一个深度学习模型,它接受从LanguageModelFeaturizer传递过来的句子嵌入向量,并结合一定数量的对话历史信息,通过神经网络计算得出一系列分类结果,包括意图、实体、情感等信息。DIETClassifier 不仅可以对每个用户输入进行意图分类和实体提取,而且还可以自动根据上下文生成机器人的回复。
- 总之,LanguageModelFeaturizer 和 DIETClassifier 这两个组件在 Rasa 机器人中通常是必需的,因为它们能够有效地捕获用户输入中的语义信息并提高机器人的性能。但是,它们的作用是有所不同的:LanguageModelFeaturizer 生成句子嵌入向量,DIETClassifier 则使用这些向量进行分类和回复生成。
- rasa 中 LanguageModelFeaturizer 与 JiebaTokenizer 的区别
- JiebaTokenizer 主要是用于对中文文本进行分词和词性标注。它会根据用户输入的句子将其分割成一个个单独的词语,并为每个词语添加一个标记表示其词性。这样做有助于提高机器人对中文文本的理解能力,从而更准确地进行意图分类和实体提取。
- 相比之下,LanguageModelFeaturizer 则主要用于生成句子嵌入向量,帮助 DIETClassifier 模型更好地理解输入文本中的语义信息。它使用预训练的语言模型(例如 BERT 或 GPT-3)来计算出句子嵌入向量,并将其传递给 DIETClassifier 进行意图分类和实体提取。
- 总之,JiebaTokenizer 和 LanguageModelFeaturizer 都是 Rasa 机器人中非常重要的组件,但它们的作用不同。JiebaTokenizer 用于将中文文本进行分词和词性标注,帮助机器人更好地理解用户输入;而 LanguageModelFeaturizer 则用于生成句子嵌入向量,帮助 DIETClassifier 更好地理解输入文本中的语义信息。
- DIETClassifier作
4. Rasa Core
Rasa core 是rasa 体系中负责对话管理的部分,主要职责是记录对话的过程和选择下一个动作。
4.1. 领域
领域 定义了对话机器人需要知道的所有信息,包含意图(intent)、实体(entity)、词槽(slot)、动作(Action)、表单(form)、回复(response)。
4.2. 动作Action
动作action是对话管理模型的输出。动作定义了机器人呢可以执行的动作,如控制对话按照填表方案进行、回复消息给用户、调用外部API或查询数据库等。
在Rasa中,以**utter_**开头的动作表示玄滩同名的模版并发给用户,这属于一种特殊的约定。
Rasa支持开发者自定义动作。
4.2.1. 回复动作
回复动作和领域里面的回复(response)关联在一起,当调用这类动作时,会自动查找回复中同名的模板并渲染。由于需要和回复模板保持名字相同,因此这类动作和回复模板一样使用utter_开头。
4.2.2. 表单
任务型对话的一个重要的模式就是多次和用户交互,以收集任务所需要的要素,直到所需的要素收集完整。这种模式常被称为填表。填表模式十分重要,本书的后面会有专门的章节深入讲解这一部分。
4.2.3. 默认动作
| 名称 | 功能(效果) |
|---|---|
| action_listen | 停止预测动作,等待用户输入 |
| action_restart | 重启对话过程,清理对话历史和词槽。用户可以通过在客户端输入restart来执行此动作。 |
| action_session_start | 所有的对话开始前都会执行此动作,启动对话过程。当用户不活动时间超过session_expiration_time的值时,该动作会拷贝先前会话中的所有词槽至新的会话。和action_restart相同,可以通过输入session_start的方式来执行此动作。 |
| action_default_fallback | 重置系统状态至上一轮(就像用户从来没有说过这句话,系统也从来没有做出反应一样),并将渲染utter_default模版作为给用户的消息。 |
| action_deactivate_loop | 停用当前已经几乎的active_loop,并重置名为requested_slot的词槽。 |
| action_two_stage_fallback | 用于处理NLU得分较低时触发的fallback逻辑 |
| action_default_ask_affirmation | 被action_two_stage_fallback使用,要求用户确认他们的意图。 |
| action_default_ask_rephrase | 被action_two_stage_fallback使用,要求用户重新表述 |
| action_back | 回退一轮,回退到最后一次用户消息前,用户可以用back来执行这个动作 |
4.2.2. 自定义动作
Rasa将自定义动作独立成为一个接口,允许开发者自行开发服务后,用HTTP接口的形式和Rasa进行交互,从而做到和语言无关,方便开发。为了更好地服务开发者,Rasa提供了Rasa SDK来帮助Python开发者快速地构建自定义动作服务器。
4.3. 词槽slots
词槽slots定义了机器人在对话过程中需要跟踪的信息。domain.yml
- influence_conversation来设置该词槽对对话过程是否有影响。influence_conversation:true默认,为false时,该词槽仅用于存储信息,不会影响对话行为。
| 类型 | 功能 |
|---|---|
| text | 可以存储文本值。Rasa 系统只判断该词槽是否设定了值,而不关心值的内容,因此该词槽比较适合作为通用实体的存储容器。 |
| bool | 只存储true或false 的值,适合作为信号处理(如抢火车票是否成功)的存储容器 |
| category | 只能存储指定的有限个值(等同于编程语言中的枚举值)。值得注意的是,Rasa会在开发者定义的值之外再增加一个other,当词槽被赋值时,若这个值并不匹配其他值,则会自动转换成other。Rasa可能会根据该词槽取值的不同(转换成独热编码)做出不同的动作。这一类型的词槽适合存储范围有限的值,如性别情况或婚姻状况等 |
| float | 可以用来存储浮点数,同时此类型的词槽需要设定最大值和最小值,如果赋值超出范围就会自动设成最大值或最小值。Rasa 会将该词槽的值作为预测动作的特征 |
| list | 可以存储多个任意值。Rasa在将这一词槽转换成特征时只考虑列表是否为空,因此列表中有多少个元素,以及有什么样的元素都不会影响系统 |
| any | 对 Rasa的动作预测没有任何影响,开发者可以把一些无关系统运行状态的值放在这里进行信息传递 |
4.3.1. 词槽的映射
映射(mapping)指定了在对话过程中如何自动地为这个词槽赋值。一个词槽可以同时有多个映射,在运行时会按照从上到下的顺序依次执行。在每一个映射中,type字段给出了这个映射的类型,其余的字段都是这个类型的参数,和type字段密切相关。如下就是一个词槽映射的示例。
slots:
priority: # 词槽名
type: text # 词槽类型
initial_value: "人类" # 初始化
values: # 词槽值被限定为3种
- high
- low
- medium
influence_conversation:false
mappings: # 指定了对话过程中如何自动为这个词槽赋值。
- type: from_entity
entity: priority
本例中只有一个映射。这个映射的type为from_entity。这种类型的映射表示将读取某个实体的值来赋值词槽。具体使用哪个实体,将由参数entity来指定(本例中是entity_name)。Rasa提供了丰富的词槽映射方案,可以满足各种需求
4.4. 回复
responses:
utter_greet:
- text: "Hey! How are you?{name}"
utter_goodbye:
- text: "Bye"
utter_default:
- text: "Sorry, I didn't get that, please try again."
Rasa的模板字符串支持变量,并支持随机选择任一模板。utter_greet中的{name}是一个变量或占位符,在渲染时会被实际的名为name的词槽的真实值替换,也可以在自定义渲染模板时通过类似dispatcher.utter_message(template="utter_greet",name="Silly")来给出模板变量{name}的实际值(Silly)。
4.5. 会话配置
会话 session指 用户和机器人之间的一轮对话。一个会话可能横跨很多轮对话。目前Rasa支持的会话配置有session_expiration_time 【表示在用户的最新消息多久后,会话被认为过期】和 carry_over_slots_to_new_session【当新的会话开始时,是否应该将上一个会话的词槽延续到新的会话】。
session_config:
session_expiration_time: 60 # 单位min,设为0表示无失效期
carry_over_slots_to_new_session:true # 设为false 表示不继承历史词槽
4.6. 全局设置
Rasa目前只有一个全局性配置选项:store_entities_as_slots。这个选项用于决定当得到NLU结果时,是否同步更新同名的词槽,其默认值为true。
4.7. 故事 story ./data/stories.yml
Rasa是通过story的方式来学习对话管理知识的。故事是一种在较高的层次上记录对话过程的方式。故事不仅需要记录用户的语义表达,还需要记录系统内部正确的状态变化。
stories:
- story: ask about weather
steps:
-intent: greet
-action: action_ask_howcanhelp
# 词槽事件就是能对词槽状态进行更改的事件,将词槽asked_for_help值设置为true了
-slot_was_set:
- asked_for_help: true
# 用户消息 intent键提供了意图信息,entities提供了实体信息,location 和 price 都是实体的类型
-intent: inform
entities:
-location: "上海"
-price : "实惠"
# 机器人动作与事件,对于复杂的故事,可能存在用户请求一次后Rasa连续执行多次动作的情况
-action: action_on_it
-action: action_ask_cuisine
-intent: inform
- action: restaurant_form
# active_loop 事件主要负责激活和取消激活表单
- active_loop: restaurant_form
故事本身的结构是字典,必须要有的键是story和steps。story键给出的值代表这个故事的备注(上例中是“这是一个story描述”),用于给开发者提供关于这个故事的一些信息。
4.8. 策略 policy
策略policy负责学习故事,从而预测动作。
策略需要通过特征提取组件featurizer将故事转成对话状态,进而得到对话状态特征,按照对话特征预测下一个对话动作。
在Rasa中,我们可以同时拥有多个策略,这些策略可独立进行训练和预测,最后通过优先级及预测分数共同决策。
4.8.1. 策略配置policy ./config.yml
| 内置策略名称 | 描述 |
|---|---|
| TEDPolicy | TED是Transformer Embedding Dialogue的缩写,是Rasa自行开发的一套对话预测算法,采用基于transformer的方案将当前的会话映射成一个对话向量,找到和这个向量最近的已知动作的对话向量 |
| MemoizationPolicy | 这个策略比较简单,直接记住历史中出现的状态和对应的动作,把这种关系做成字典。在预测时,直接查询相关的字典,如果有这样的状态,则将对应的动作作为结果;如果没有,则预测失败 |
| AugmentedMemoizationPolicy | 这个策略和MemoizationPolicy 的工作原理一致,只是它有一个遗忘机制,会随机地遗忘当前对话历史中的部分步骤,随后试图在训练的故事集合中寻找和当前历史匹配的故事 |
| RulePolicy | 这个策略是规则驱动的,它合并了 Rasa 1x中所有基于规则的策略MappingPolicy、FallbackPolicy、TwoStageFallbackPolicy 和 FormPolicy |
policies:
-name: "MemoizationPolicy"
max_history: 5
-name: "FallbackPolicy"
nlu_threshold: 0.4
core_threshold: 0.3
fallback_action_name: "my_action_default_fallback"
-name: "path.to.your.policiy.class"
arg1: "..."
4.9. 数据增强
在默认情况下,Rasa可把故事首尾相接,生成新的故事,这就是故事的数据增强。开发者可以在使用Rasa命令时,添加--augmentation来设定数据增强的数量,Rasa按照最多生成--augmentation设置乘以10的数量来增强故事。--augmentation 0可以完全关闭数据增强功能。
4.10. 端点 ./endpoints.yml
endpoints.yml定义了Rasa Core和其他服务进行连接的配置信息,这种信息被称为端点(endpoint)。目前支持的端点有event broker、tracker store、lock store、动作服务器(action server)、NLU服务器、NLG服务器和model storage。
# This file contains the different endpoints your bot can use.
# Server where the models are pulled from.
#
#models:
# url:
# wait_time_between_pulls: 10 # [optional](default: 100)
# Server which runs your custom actions.
#
#action_endpoint:
# url: ""
# Tracker store which is used to store the conversations.
# By default the conversations are stored in memory.
#
#tracker_store:
# type: redis
# url:
# port:
# db:
# password:
# use_ssl:
#tracker_store:
# type: mongod
# url:
# db:
# username:
# password:
# Event broker which all conversation events should be streamed to.
#
#event_broker:
# url: localhost
# username: username
# password: password
# queue: queue
5. Rasa SDK 和自定义动作
5.1. 安装
Rasa本身包含Rasa SDK,所以安装了Rasa也就自动安装了Rasa SDK。如果只使用Rasa SDK而不想安装Rasa(如在生产环境中),那么可以按照如下方式安装。
pip install rasa-sdk
5.2. 自定义动作action
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
class ActionHelloWorld(Action):
def name(self):
return "action_hello_world"
def run(self, dispatcher, tracker, domain):
cuisine = tracker.get_slot('cuisine')
q = "select * from restaurans where cuisine = '{0}' limit 1".format(cuisine)
result = query_db(q)
return [SlotSet("cuisine", cuisine), SlotSet("restaurant", result[0][0])]er
通过重写name()方法返回一个字符串,可以向服务器申明这个动作的名字。
通过重写run()方法,开发者可以获得当前的对话信息(tracker对象和领域对象)和用户消息对象(dispatcher)。开发者可以利用这些信息来完成业务动作。如果想对当前的对话状态进行更改(如更改词槽),则需要通过返回事件(event)(可以是多个事件)的形式发送给Rasa服务器。即使对话状态没有发生任何变化,也需要返回一个空的列表。
5.2.1. tracker对象
tracker代表对话状态追踪,也就是对话的历史记忆。在自定义动作中,开发者可以通过tracker对象来获取当前(或历史的)的对话状态(实体情况和词槽情况等),这通常作为业务的输入。
| 属性名称 | 说明 |
|---|---|
| sender_id | 字符串类型,当前对话用户的唯一id |
| slots | 词槽列表 |
| latest_message | 字典类型,包含3个键:intent、entities和text,分别代表意图、实体和用户的话 |
| events | 代表历史上所有的事件 |
| active_form | 字符串类型,表示当前被激活的表单,也可能是空(没有表单被激活) |
| latest_action_name | 字符串类型,表示最后一个动作的名字。 |
| 方法名称 | 功能 |
|---|---|
| current state() | 返回当前的 tracker对象 |
| is_paused() | 返回当前的tracker对象的过程是否被暂停 |
| get_latest_entity_values() | 返回某个实体的最后值 |
| get_latest_input_channel() | 返回最后用户所用的输入通道(input channel)的名字 |
| events_after_latest_restart() | 返回最后一次重启后的所有事件 |
| get_slot() | 返回一个词槽的具体值 |
5.2.2. 事件对象 event
在自定义动作中,如果想要更改对话状态,则需要用到事件(event)对象。
| 事件对象【通用事件】 | 说明 |
|---|---|
| SlotSet(key,value=None) | 要求系统将名字为 key的词槽的值设置为 value |
| Restarted() | 重启对话过程 |
| AllSlotReset() | 重制所有的词槽 |
| ReminderScheduled() | 在指定的时间发起一个意图和实体都给定的请求,也称为定时任务 |
| ReminderCancelled() | 取消一个定时任务 |
| ConversationPaused() | 暂停对话过程 |
| ConversationResumed() | 继续对话过程 |
| FollowupAction(name) | 强制设定下一轮的动作(不通过预测得到) |
| Rasa自动跟踪事件 | 说明 |
| UserUttered() | 表示用户发送的消息 |
| BotUttered() | 表示机器人发送给用户的消息 |
| UserUtteranceReverted() | 撤销用户最后消息(UserUttered)后的发生的所有事件(包含用户事件本身)在通常情况下,这时只剩下action listen,机器人会回到等待用户输入的状态 |
| ActionReverted() | 撤销上一个动作,会清除上个动作所有的事件效果,机器人会重新开始预测下一个动作 |
| ActionExecuted() | 记录一个动作,动作创造的事件会被单独记录 |
| SessionStarted() | 开始一个新的对话会话。重置 tracker,并触发执行ActionSessionStart (在默认情况下,将已经存在的 SlotSet 拷贝到新的会话) |
5.3. Rasa支持的客户端 ./credentials.yml
在绝大部分情况下,用户都是使用各种即时通信软件(Instant Messaging, IM)来和对话机器人进行沟通的。Rasa在IM集成方面有着优良的表现,支持市面上主流的开放API的IM,包括Facebook Messenger、Slack、Telegram、Twilio、Microsoft Bot Framework、Cisco Webex Teams、RocketChat、Mattermost和Google Hangouts Chat等。同时,社区开发者为Rasa打造了多款开源的IM,这些IM常被创业公司和开发人员用来做实际产品或进行演示。其中,功能比较完善的有Rasa Webchat和Chatroom。
在Rasa中,负责和IM连接的组件称为connector。connector负责实现通信协议,由于不同的IM可能使用IM相同的通信协议,所以connector并不是和IM一一对应的。除上述IM都有对应的connector外,Rasa还支持开发者自定义connector,以满足用户连接其他IM的需求。Rasa支持同时使用多个connector(也就是同时连接多个IM),开发者需要在credentials.yml文件中配置如何连接客户端。Rasa对于所有的connector都有详细的文档,如下是Rasa Webchat的配置示例。
Rasa WebChat使用的底层协议是socketio,所以配置里使用的是socketio。
rest:
# # you don't need to provide anything here - this channel doesn't
# # require any credentials
#facebook:
# verify: ""
# secret: ""
# page-access-token: ""
#slack:
# slack_token: ""
# slack_channel: ""
# slack_signing_secret: ""
socketio:
user_message_evt:
bot_message_evt:
session_persistence:
#mattermost:
# url: "https:///api/v4"
# token: ""
# webhook_url: ""
# This entry is needed if you are using Rasa Enterprise. The entry represents credentials
# for the Rasa Enterprise "channel", i.e. Talk to your bot and Share with guest testers.
rasa:
url: ""
6. Rasa 使用ResponseSelector实现FAQ和闲聊功能
多数对话机器人都需要有简单的FAQ(Frequently Asked Question,常见问题解答)和闲聊(chitchat)的功能。在一般情况下,FAQ和闲聊的问答数量很多。如果想用一个意图来表示一个FAQ或闲聊并为之搭配一个动作,那么这个故事写起来将会非常繁杂,从而导致整个过程非常低效。幸运的是,Rasa提供了NLU组件ResponseSelector来做这种FAQ型或闲聊型的任务。使用ResponseSelector,需要为每种问题定义一种分类,并为每种分类定义想要返回给用户的答案。
6.1. 自定义用户问题
ResponseSelector需要采用group/intent的格式命名。group部分称为检索意图(retrieval intent)
nlu:
- intent: chitchat/ask_name
examples: |
- 你叫什么名字?
- 你是谁?
- 你叫啥?
- 你的名字是什么?
- intent: chitchat/ask_age
examples: |
- 你多大了?
- 你多高?
- 你的身高是多少?
例中的意图chitchat/ask_name和chitchat/ask_age都属于检索意图chitchat。
6.2. 自定义用户答案 ./domain.yml
在ResponseSelector中,使用domain.yml的responses字段来存放答案数据。这里有一个约定,Rasa中意图名为intent的问题都需要有一个名为utter_intent的response作为答案。以下是一段示例的答案定义。
responses:
utter_chitchat/ask_age
- text: 我刚成立
utter_chitchat/ask_name
- text: 我是 Silly,一个基于 Rasa 的 FAQ 机器人
6.3. 如何训练Rasa
为了根据问题智能(具有良好的泛化能力)地进行回答,需要让ResponseSelector在现有数据上进行训练。训练部分相当简单,只需要将ResponseSelector组件加入NLU的流水线即可,如下所示。
./data/NLU.yml
pipeline:
- name : XXXFeaturizer # 替换为真实的特征提取组件
- name : XXXClassifier # 替换为真实的意图分类组件
# 经过训练后的 ResponseSelector组件能够根据用户的语义正确地进行语义分类。但要实现自动地根据语义分类返回对应的答案(也就是分类到现有的用户问题分类中),我们还需要启用RulePolicy。
#
policies:
# other policies
# RulePolicy
设置一个规则(rule),将问题分类映射到对应的动作上。
./data/rules.yml
version: "3.0"
rules:
- rule: respond to FAQs
steps:
- intent: faq
- action: utter_faq