C语言系统化精讲(一):C 语言开发环境搭建
文章目录
- 一、Windows 开发环境搭建
-
- 1.1 安装 mingw 编译器
- 1.2 下载并安装 CLion
- 1.3 启动 CLion
- 二、Linux 开发环境搭建(建议使用)
-
- 2.1 VMware Workstation Pro软件简介及安装
- 2.2 安装 Ubuntu 系统
-
- 2.2.1 Ubuntu 下载
- 2.2.2 安装 Ubuntu
- 2.2.3 安装共享文件夹
- 2.3 概念介绍
-
- 2.3.1 源文件
- 2.3.2 C语言编译和链接详解
- 2.3.3 编译(Compile)
- 2.3.4 链接(Link)
- 2.3.5 C语言编译器
- 2.3.6 集成开发环境(IDE)
- 2.3.7 工程/项目
- 2.3.8 C语言的三套标准:C89、C99和C11
- 2.3.9 程序安装是怎么回事
- 三、第一个C语言程序
一、Windows 开发环境搭建
参考笔者之前的文章(不推荐使用此种方式,有兴趣可以自己倒腾倒腾):https://blog.csdn.net/xw1680/article/details/113796917
Windows 下建议按照如下步骤操作:
1.1 安装 mingw 编译器
下载地址:
链接:https://pan.baidu.com/s/1Ca-z8MKLjdWFaPHdpfeHOg
提取码:7ip7
--来自百度网盘超级会员V9的分享
下载 mingw64.zip 压缩包,在 D 盘根目录新建一个文件夹 DevelopSoftware,将下载好的 mingw64.zip 压缩包放入 DevelopSoftware 文件夹中,如下图所示:
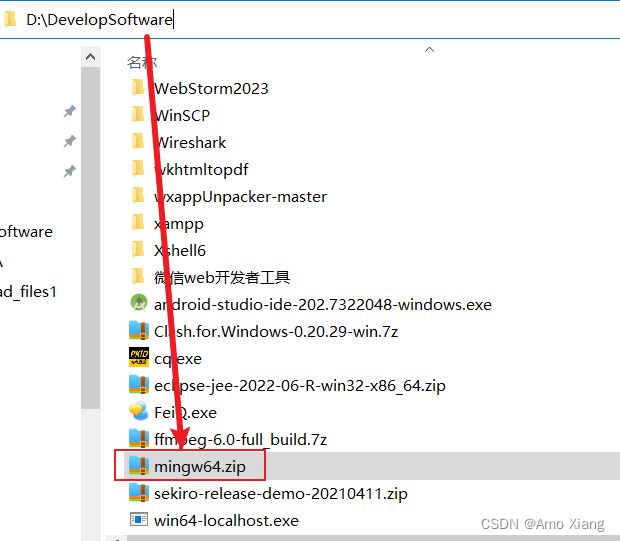
选中 mingw64.zip 压缩包,右键解压,如下图所示:

最后如下图所示:

ps:你也可以将安装包解压到自己熟悉的位置(初学者最好和我保持一致),不要放在含有中文或者空格的路径下。
1.2 下载并安装 CLion
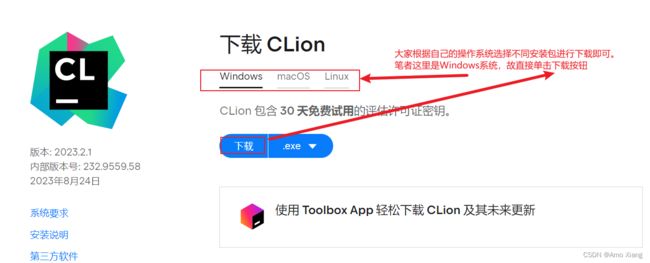
打开网址:https://www.jetbrains.com.cn/clion/ 单击页面上的下载按钮,切换到如下界面:
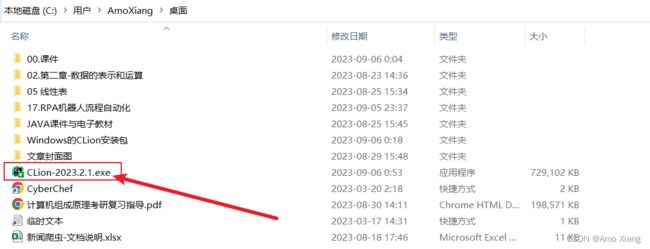
下载完成后,可以看到在我本地桌面已经有下载好的 CLion 安装包,如下图所示:
安装 CLion 的步骤如下:
① 双击 CLion 安装包进行安装,将显示如下图所示的 当前无法访问 窗体,此处单击 运行 按钮即可:

② 在欢迎界面单击 Nex t按钮进入软件安装路径设置界面:

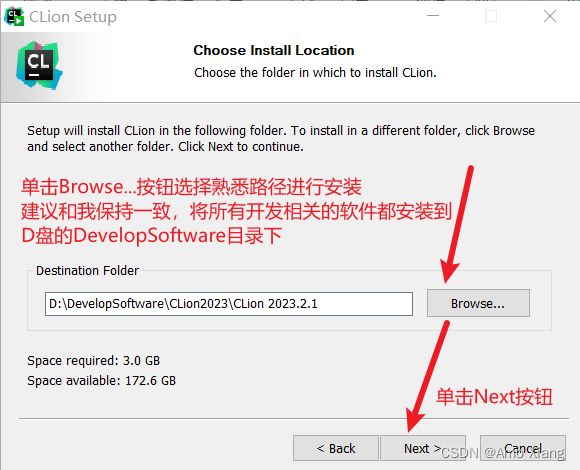
③ 在软件安装路径设置界面,设置合理的安装路径。强烈建议不要把软件安装到操作系统所在的路径,否则当出现操作系统崩溃等特殊情况而必须重做操作系统时,CLion 程序路径下的程序将被破坏。CLion 默认的安装路径为操作系统所在的路径,建议更改,另外安装路径中建议不要包含中文字符与空白字符。我选择的安装路径为 D:\DevelopSoftware\CLion2023\,如下图所示。单击 Next 按钮,进入创建快捷方式界面:
④ 勾选 Create Desktop Shortcut 与 Add "bin" folder to the PATH 左侧的复选框,如下图所示:
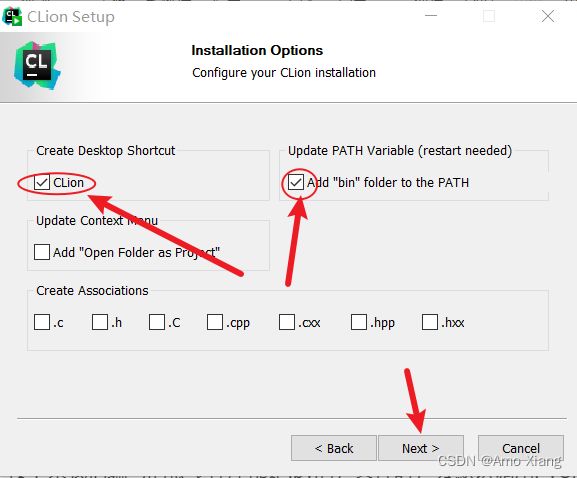
⑤ 单击 Next> 按钮,进入选择开始菜单文件夹界面,如下图所示,该界面不用设置,采用默认即可,单击 Install 按钮:
安装大概5分钟左右,视自己电脑决定,请耐心等待,如下图所示:

⑥ 安装完成后,选中 Reboot now 左侧的单选按钮,紧接着单击 Finish 按钮,结束安装,如下图所示:

1.3 启动 CLion
运行 CLion 开发环境的步骤如下 (激活自己解决-某宝):
① 单击 CLion 桌面快捷方式 CLion 2023.2.1,启动 CLion 程序。选择是否导入开发环境配置文件,这里选择不导入,单击 OK 按钮,进入阅读协议页,如下图所示:

② 点击 New Project ,如下图所示:

③ 点击 New Project 后,弹出下面窗口,图中的项目存储路径与项目名必须是英文的,不可含有中文,如果自己的用户名是中文的,可以在 D/E 盘新建一个文件夹,放项目!

点击 create 后会得到如下图所示效果:

二、Linux 开发环境搭建(建议使用)
说明:这里为了方便后期的学习,本次采用的是 ubuntu-18.04 的操作系统
2.1 VMware Workstation Pro软件简介及安装
https://blog.csdn.net/xw1680/article/details/113635955
2.2 安装 Ubuntu 系统
可以参考文章:https://blog.csdn.net/xw1680/article/details/115434578
2.2.1 Ubuntu 下载
百度网盘:
链接:https://pan.baidu.com/s/1ewlex1T5VxNj2ei6OKtRVA
提取码:m3wu
--来自百度网盘超级会员V8的分享
2.2.2 安装 Ubuntu
将上述百度网盘中下载好的安装包进行解压,如下图所示:

接着打开安装好的 Vmware 软件,点击 文件-打开,如下图所示:
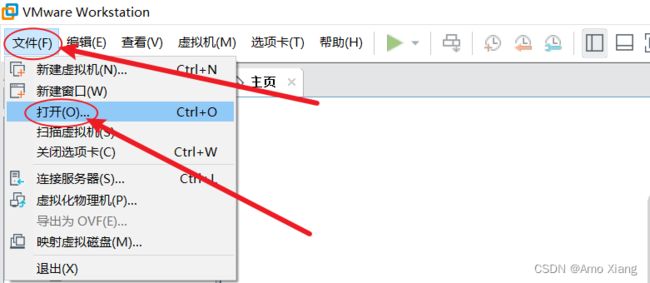
选择我们刚刚解压的 ubuntu-18.04 的路径,找到 Ubuntu 64.vmx,然后打开,如下图所示:

选中左侧的Ubuntu 64 位,点击开启此虚拟机,启动 ubuntu系统,如下图所示:
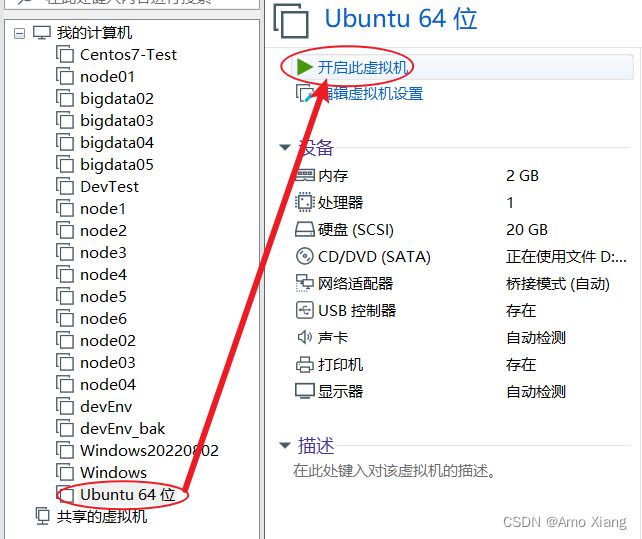
在启动过程中,会弹出如下对话框,选择 我已复制该虚拟机(P) 即可,

点击登录用户:

输入密码1,即可进入 Ubuntu 系统,如下图所示:
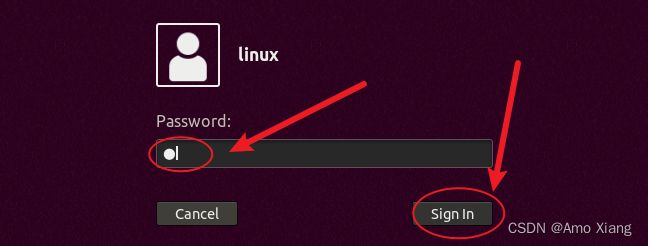
成功进入 Ubuntu 系统界面,如下图所示:

2.2.3 安装共享文件夹
说明:Ubuntu 系统想要和 Windows 之间传输文件等信息,可以通过设置共享文件夹来实现。
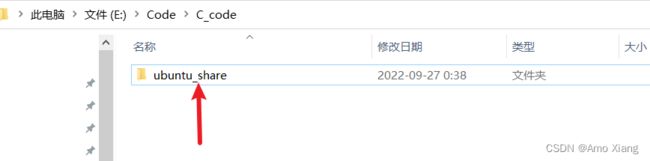
进入到 E:\Code\C_code 路径(路径自选)下,新建一个叫做 ubuntu_share 的文件夹,如下图所示:
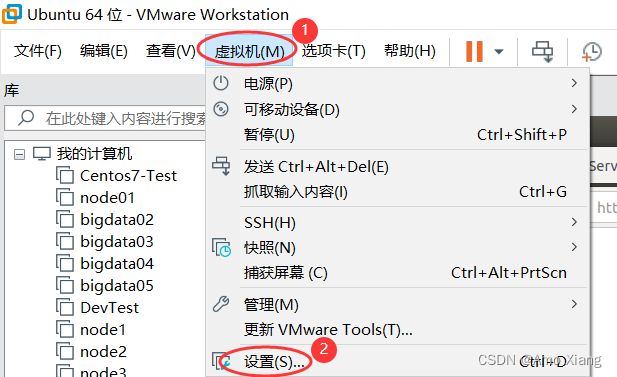
打开 Vmware 软件后,点击 虚拟机–设置,如下图所示:
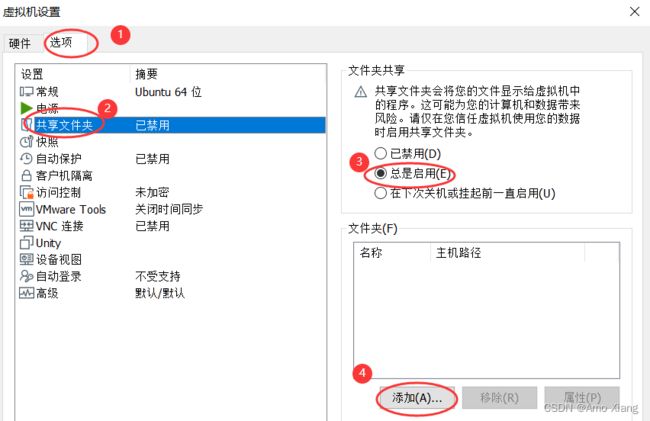

选中刚刚在 E:\Code\C_code 下新建的 ubuntu_share 文件夹,如下图所示:


最后回到 VMware 设置界面点击确定即可。
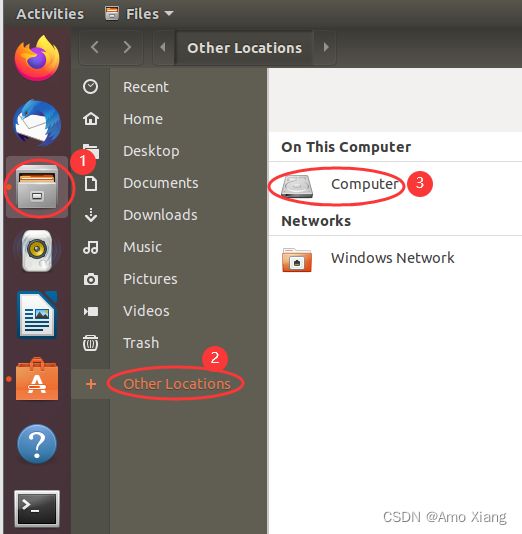
测试: 打开 VMware,进入 Ubuntu 系统中,找到 /mnt/hgfs/ubuntu_share 文件夹,新建文件夹 test_share 和 文件 hello.txt,如下图所示:

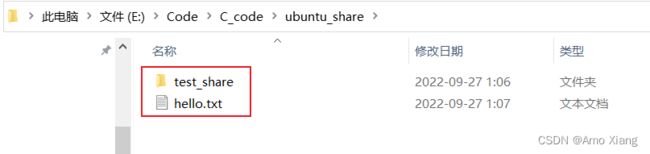
在 Windows 中查看,自动同步了,如下图所示:
2.3 概念介绍
2.3.1 源文件
在开发软件的过程中,我们需要将编写好的代码(Code)保存到一个文件中,这样代码才不会丢失,才能够被编译器找到,才能最终变成可执行文件。这种用来保存代码的文件就叫做 源文件(Source File)。
每种编程语言的源文件都有特定的后缀,以方便被编译器识别,被程序员理解。源文件后缀大都根据编程语言本身的名字来命名,例如:
- C语言源文件的后缀是
.c - C++语言(C Plus Plus) 源文件的后缀是
.cpp - Java 源文件的后缀是
.java - Python 源文件的后缀是
.py - JavaScript 源文件后缀是
.js
源文件其实就是纯文本文件,它的内部并没有特殊格式, 源文件的后缀仅仅是为了表明该文件中保存的是某种语言的代码(例如 .c 文件中保存的是C语言代码),这样程序员更加容易区分,编译器也更加容易识别,它并不会导致该文件的内部格式发生改变。
2.3.2 C语言编译和链接详解
我们平时所说的程序,是指双击后就可以直接运行的程序,这样的程序被称为可执行程序(Executable Program)。在 Windows 下,可执行程序的后缀有 .exe(比较常见)、.com 和 sys 等;在类 UNIX 系统(Linux、Mac OS 等)下,可执行程序没有特定的后缀,系统根据文件的头部信息来判断是否是可执行程序。可执行程序的内部是一系列计算机指令和数据的集合,它们都是二进制形式的,CPU 可以直接识别,毫无障碍;但是对于程序员,它们非常晦涩,难以记忆和使用。例如,在屏幕上输出 VIP会员,C语言的写法为:
puts("VIP会员");
二进制的写法为:

在计算机发展的初期,程序员就是使用这样的二进制指令来编写程序的,那个拓荒的年代还没有编程语言。
直接使用二进制指令编程对程序员来说简直是噩梦,尤其是当程序比较大的时候,不但编写麻烦,需要频繁查询指令手册,而且出现错误时会异常苦恼,要直接面对一堆二进制数据,让人眼花缭乱。另外,用二进制指令编程步骤繁琐,要考虑各种边界情况和底层问题,开发效率十分低下。这就倒逼程序员开发出了编程语言,提高自己的生产力,例如汇编、C语言、C++、Java、Python、Go语言等,都是在逐步提高开发效率。
2.3.3 编译(Compile)
C语言代码由固定的词汇按照固定的格式组织起来,简单直观,程序员容易识别和理解,但是对于CPU,C语言代码就是天书,根本不认识,CPU 只认识几百个二进制形式的指令。这就需要一个工具,将C语言代码转换成 CPU 能够识别的二进制指令,也就是将代码加工成 .exe 程序的格式;这个工具是一个特殊的软件,叫做 编译器(Compiler)。
编译器能够识别代码中的词汇、句子以及各种特定的格式,并将他们转换成计算机能够识别的二进制形式,这个过程称为 编译(Compile)。 编译也可以理解为 翻译,类似于将中文翻译成英文、将英文翻译成象形文字,它是一个复杂的过程,大致包括词法分析、语法分析、语义分析、性能优化、生成可执行文件五个步骤,期间涉及到复杂的算法和硬件架构。对于学计算机或者软件的大学生,编译原理 是一门专业课程,有兴趣的请自行阅读《编译原理》一书。
C语言的编译器有很多种,不同的平台下有不同的编译器,例如:
- Windows 下常用的是微软开发的 Visual C++,它被集成在 Visual Studio 中,一般不单独使用
- Linux 下常用的是 GNU 组织开发的 GCC,很多 Linux 发行版都自带 GCC,详情:https://baike.baidu.com/item/gcc/17570?fr=aladdin
- Mac 下常用的是 LLVM/Clang,它被集成在 Xcode 中(Xcode 以前集成的是 GCC,后来由于 GCC 的不配合才改为 LLVM/Clang,LLVM/Clang 的性能比 GCC 更加强大)。
你的代码语法正确与否,编译器说了才算,我们学习C语言,从某种意义上说就是学习如何使用编译器。编译器可以 100% 保证你的代码从语法上讲是正确的,因为哪怕有一点小小的错误,编译也不能通过,编译器会告诉你哪里错了,便于你的更改。
2.3.4 链接(Link)
C语言代码经过编译以后,并没有生成最终的可执行文件(.exe 文件),而是生成了一种叫做目标文件(Object File) 的中间文件(或者说临时文件)。目标文件也是二进制形式的,它和可执行文件的格式是一样的。对于 Visual C++,目标文件的后缀是 .obj;对于 GCC,目标文件的后缀是 .o。
目标文件经过链接(Link)以后才能变成可执行文件。既然目标文件和可执行文件的格式是一样的,为什么还要再链接一次呢,直接作为可执行文件不行吗?不行的!因为编译只是将我们自己写的代码变成了二进制形式,它还需要和系统组件(比如标准库、动态链接库等)结合起来,这些组件都是程序运行所必须的。链接(Link) 其实就是一个 打包 的过程,它将所有二进制形式的目标文件和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做 链接器(Linker)。
随着学习的深入,我们编写的代码会越来越多,最终需要将它们分散到多个源文件中,编译器每次只能编译一个源文件,生成一个目标文件,这个时候,链接器除了将目标文件和系统组件组合起来,还需要将编译器生成的多个目标文件组合起来。再次强调,编译是针对一个源文件的,有多少个源文件就需要编译多少次,就会生成多少个目标文件。
总结:不管我们编写的代码有多么简单,都必须经过「编译 --> 链接」的过程才能生成可执行文件:
编译就是将我们编写的源代码 “翻译” 成计算机可以识别的二进制格式,它们以目标文件的形式存在;
链接就是一个 “打包” 的过程,它将所有的目标文件以及系统组件组合成一个可执行文件。
2.3.5 C语言编译器
对于当前主流桌面操作系统而言,可使用 Visual C++、GCC 以及 LLVM Clang 这三大编译器。Visual C++(简称 MSVC) 是由微软开发的,只能用于 Windows 操作系统;GCC 和 LLVM Clang 除了可用于 Windows 操作系统之外,主要用于 Unix/Linux 操作系统。现在很多版本的 Linux 都默认使用 GCC 作为C语言编译器,而像 FreeBSD、macOS 等系统默认使用 LLVM Clang 编译器。由于当前 LLVM 项目主要在 Apple 的主推下发展的,所以在 macOS中,Clang 编译器又被称为 Apple LLVM 编译器。
MSVC 编译器主要用于 Windows 操作系统平台下的应用程序开发,它不开源。用户可以使用 Visual Studio Community 版本来免费使用它,但是如果要把通过 Visual Studio Community 工具生成出来的应用进行商用,则需要好好阅读一下微软的许可证和说明书了。
而使用 GCC 与 Clang 编译器构建出来的应用一般没有任何限制,程序员可以将应用程序随意发布和进行商用。MSVC 编译器对 C99 标准的支持十分有限,直到发布 Visual Studio Community 2019,也才对 C11 和 C17 标准做了部分支持。 所幸的是,Visual Studio Community 2017 加入了对 Clang 编译器的支持,官方称之为——Clang with Microsoft CodeGen,当前版本基于的是 Clang 3.8。
C语言从诞生到现在,更新、迭代了多个版本,比如 C99、C11、C17 等。有关这些版本和它们之间的区别,后续会详细地介绍。也就是说,应用于 Visual Studio 集成开发环境中的 Clang 编译器前端可支持 Clang 编译器的所有语法特性,而后端生成的代码则与 MSVC 效果一样,包括像 long 整数类型在 64 位编译模式下长度仍然为 4 个字节。
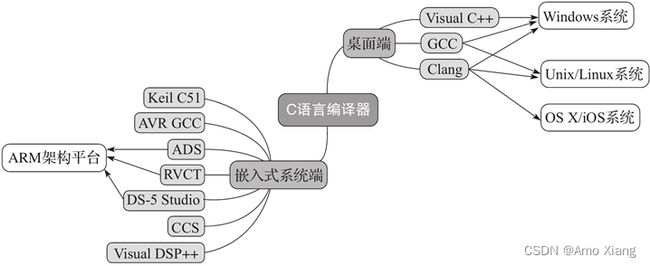
而在嵌入式系统方面,可用的C语言编译器就非常丰富了,比如:
- 用于 Keil 公司 51 系列单片机的 Keil C51 编译器
- 当前大红大紫的 Arduino 板搭载的开发套件,可用针对 AVR 微控制器的 AVR GCC 编译器
- ARM 自己出的 ADS(ARM Development Suite)、RVDS(RealView Development Suite)和当前最新的 DS-5 Studio
- DSP 设计商 TI(Texas Instruments) 的 CCS(Code Composer Studio)
- DSP 设计商 ADI(Analog Devices,Inc.) 的 Visual DSP++ 编译器等等
通常,用于嵌入式系统开发的编译工具链都没有免费版本,而且一般需要通过国内代理进行购买。所以,这对于个人开发者或者嵌入式系统爱好者而言是一道不低的门槛。不过 Arduino 的开发套件是可免费下载使用的,并且用它做开发板连接调试也十分简单。Arduino 所采用的C编译器是基于 GCC 的。还有像 树莓派(Raspberry Pi) 这种迷你电脑可以直接使用 GCC 和 Clang 编译器。此外,还有像 nVidia 公司推出的 Jetson TK 系列开发板也可直接使用 GCC 和 Clang 编译器。树莓派与 Jetson TK 都默认安装了 Linux 操作系统。
在嵌入式领域,一般比较低端的单片机,比如 8 位的 MCU 所对应的C编译器可能只支持 C90 标准,有些甚至连 C90 标准的很多特性都不支持。因为它们一方面内存小,ROM 的容量也小;另一方面,本身处理器机能就十分有限,有些甚至无法支持函数指针,因为处理器本身不包含通过寄存器做间接过程调用的指令。而像 32 位处理器或 DSP,一般都至少能支持 C99 标准,它们本身的性能也十分强大。而像 ARM 出的 RVDS 编译器甚至可用 GNU 语法扩展。下图展示了上述C语言编译器的分类:
2.3.6 集成开发环境(IDE)
实际开发中,除了编译器是必须的工具,我们往往还需要很多其他辅助软件,例如:
- 编辑器:用来编写代码,并且给代码着色,以方便阅读
- 代码提示器:输入部分代码,即可提示全部代码,加速代码的编写过程,提高工作效率
- 调试器:观察程序的每一个运行步骤,发现程序的逻辑错误
- 项目管理工具:对程序涉及到的所有资源进行管理,包括源文件、图片、视频、第三方库等;
- 漂亮的界面:各种按钮、面板、菜单、窗口等控件整齐排布,操作更方便。
这些工具通常被打包在一起,统一发布和安装,例如 Visual Studio、Dev C++、Xcode、Visual C++ 6.0、C-Free、Code::Blocks 等,它们统称为 集成开发环境(IDE,Integrated Development Environment)。
集成开发环境就是一系列开发工具的组合套装。这就好比台式机,一个台式机的核心部件是主机,有了主机就能独立工作了,但是我们在购买台式机时,往往还要附带上显示器、键盘、鼠标、U盘、摄像头等外围设备,因为只有主机太不方便了,必须有外设才能玩的爽。集成开发环境也是这个道理,只有编译器不方便,所以还要增加其他的辅助工具。在实际开发中,肯定要使用集成开发环境,而不是单独地使用编译器。
2.3.7 工程/项目
一个真正的程序(也可以说软件)往往包含多项功能,每一项功能都需要几十行甚至几千行、几万行的代码来实现,如果我们将这些代码都放到一个源文件中,那将会让人崩溃,不但源文件打开速度极慢,代码的编写和维护也将变得非常困难。在实际开发中,我们都是将这些代码分门别类地放到多个源文件中。除了这些成千上万行的代码,一个程序往往还要包含图片、视频、音频、控件、库(也可以说框架)等其它资源,它们也都是一个一个地文件。
为了有效地管理这些种类繁杂、数目众多的文件,我们有理由把它们都放到一个目录(文件夹)下,并且这个目录下只存放与当前程序有关的资源。实际上 IDE 也是这么做的,它会为每一个程序都创建一个专门的目录,将用到的所有文件都集中到这个目录下,并对它们进行便捷的管理,比如重命名、删除文件、编辑文件等。这个为当前程序配备的专用文件夹,在 IDE 中也有一个专门的称呼,叫做 Project,翻译过来就是 工程 或者 项目。在 Visual C++ 6.0 下,这叫做一个 工程,而在 Visual Studio 下,这又叫做一个 项目,它们只是单词 Project 的不同翻译而已,实际上是一个概念。
工程类型/项目类型: 程序 是一个比较宽泛的称呼,它可以细分为很多种类,例如:
有的程序不带界面,完全是 黑屏 的,只能输入一些字符或者命令,称为 控制台程序(Console Application), 例如 Windows 下的 cmd.exe,Linux 或 Mac OS 下的终端(Terminal)。
有的程序带界面,看起来很漂亮,能够使用鼠标点击,称为 GUI程序(Graphical User Interface Program), 例如 QQ、迅雷、Chrome 等。有的程序不单独出现,而是作为其它程序的一个组成部分,普通用户很难接触到它们,例如静态库、动态库等。
不同的程序对应不同的工程类型(项目类型),使用 IDE 时必须选择正确的工程类型才能创建出我们想要的程序。换句话说,IDE 包含了多种工程类型,不同的工程类型会创建出不同的程序。不同的工程类型本质上是对 IDE 中各个参数的不同设置;我们也可以创建一个空白的工程类型,然后自己去设置各种参数(不过一般不这样做)。控制台程序对应的工程类型为 Win32控制台程序 (Win32 Console Application),GUI 程序对应的工程类型为 Win32程序 (Win32 Application)。
控制台程序是 DOS 时代的产物了,它没有复杂的功能,没有漂亮的界面,只能看到一些文字,虽然枯燥无趣,也不实用,但是它非常简单,不受界面的干扰,所以适合入门,我强烈建议初学者从控制台程序学起。等大家对编程掌握的比较熟练了,能编写上百行的代码了,再慢慢过渡到 GUI 程序。
C语言的集成开发环境有很多种,尤其是 Windows 下,多如牛毛,初学者选择 https://blog.csdn.net/xw1680/article/details/113796917 即可。
说明:为了让初学者更好地理解C语言程序的生成过程,以及打好编程的基础,后续我将会在上述安装好的 Ubuntu 中使用 Vim 编辑器进行基础代码的编写。
2.3.8 C语言的三套标准:C89、C99和C11
我们今天使用的 Windows、Linux、Mac OS 等操作系统都是由一种叫做 Unix 的系统演化而来。Unix 作为80年代主流的操作系统,是整个软件工业的基础,是现代操作系统的开山鼻祖,C语言就是为 Unix 而生的。Unix和C语言的开发者是同一人,名字叫 丹尼斯·里奇(Dennis MacAlistair Ritchie)。

C 语言的诞生:https://baike.baidu.com/item/c%E8%AF%AD%E8%A8%80/105958?fr=kg_general
C89 标准: 到了80年代,C语言越来越流行,广泛被业界使用,从大型主机到小型微机,各个厂商群雄并起,推出了多款C语言的编译器。这些编译器根据行业和厂商自己的需求,进行了各种扩展,C语言进入了春秋战国时代,逐渐演变成一个松散杂乱的大家族。为统一C语言版本,1983 年美国国家标准局(American National Standards Institute,简称 ANSI) 成立了一个委员会,专门来制定C语言标准。1989 年C语言标准被批准,被称为 ANSI X3.159-1989 Programming Language C。这个版本的C语言标准通常被称为 ANSI C。又由于这个版本是 89 年完成制定的,因此也被称为 C89。后来 ANSI 把这个标准提交到 ISO(国际化标准组织),1990 年被 ISO 采纳为国际标准,称为 ISO C。又因为这个版本是1990年发布的,因此也被称为 C90。ANSI C(C89) 与 ISO C(C90) 内容基本相同,主要是格式组织不一样。因为 ANSI 与 ISO 的C标准内容基本相同,所以对于C标准,可以称为 ANSI C,也可以说是 ISO C,或者 ANSI / ISO C。以后大家看到 ANSI C、ISO C、C89、C90,要知道这些标准的内容都是一样的。目前常用的编译器,例如微软编译器、GCC、LLVM/Clang 等,都能很好地支持 ANSI C 的内容。
C99 标准: 在 ANSI C 标准确立之后,C语言的规范在很长一段时间内都没有大的变动。1995 年C程序设计语言工作组对C语言进行了一些修改,增加了新的关键字,编写了新的库,取消了原有的限制,并于 1999 年形成新的标准—— ISO/IEC 9899:1999 标准, 通常被成为 C99。但是这个时候的C语言编译器基本已经成熟,各个组织对 C99 的支持所表现出来的兴趣不同。当 GCC 和其它一些商业编译器支持 C99 的大部分特性的时候,微软和 Borland 却似乎对此不感兴趣,或者说没有足够的资源和动力来改进编译器,最终导致不同的编译器在部分语法上存在差异。例如,ANSI C 规定,局部变量要在函数开头定义,而 C99 取消了这个限制,变量可以在任意位置定义,我们将在后续的学习中进行详细地介绍。
C11 标准: C11 标准由国际标准化组织(ISO)和国际电工委员会(IEC)旗下的C语言标准委员会于 2011 年底正式发布,支持此标准的主流C语言编译器有 GCC、LLVM/Clang、Intel C++ Compile 等。C11 标准主要增加了以下内容:
增加了安全函数,例如 gets_s()、fopen_s() 等
增加了 头文件以支持多线程
增加了 头文件以支持 Unicode 字符集, 以及其它一些细节
通过上述 C语言的三套标准:C89、C99和C11 的介绍可以发现,C语言并没有一个官方机构,也不属于哪个公司,它只有一个制定标准的委员会,任何其他组织或者个人都可以开发C语言的编译器,而这个编译器要遵守哪个C语言标准,是 100% 遵守还是部分遵守,并没有强制性的措施,也没有任何约束。
换句话说,各个厂商可以为了自己的利益、根据自己的喜好来开发编译器。
这就导致了一个棘手的问题,有的编译器遵守较新的C语言标准,有的编译器只能遵守较老的C语言标准,有的编译器还进行了很多扩展。比如:GCC、LLVM/Clang 更新非常及时,能够支持最新的 C11 标准(前提是你得使用最新版的编译器)。微软编译器更新比较缓慢,迟迟不能支持新标准,例如 VC 6.0、VS2010 都在使用 C89 标准,VS2015 部分支持 C99 标准(其他版本的VS没有测试)。微软官方给出的答复是,最新的标准已经在 C++ 中支持了,C语言就没必要再重复了。
初学者经常会遇到这种情况,有些代码在微软编译器下能够正常运行,拿到 GCC 下就不行了,一堆报错信息;或者反过来,在 GCC 上能运行的代码在微软编译器下不能运行。这是因为不同的编译器支持不同的标准,并且每个编译器都进行了自己的扩展,假如你使用了微软编译器私有的扩展函数,那么拿到 GCC 下肯定是不支持的。
2.3.9 程序安装是怎么回事
大部分软件都需要先安装才能使用,例如 QQ、360、迅雷等,要先从网上下载一个安装包,然后安装到计算机的C盘或者D盘等。大部分程序还会在开始菜单或者桌面上生成一个快捷方式,用户只要点击快捷方式,就可以启动软件。不同的操作系统,安装软件的方法虽然不一样,但基本原理是相同的,主要的思想就是将程序的二进制可执行文件拷贝到某个目录,设置一些路径。如果程序运行时需要一些库,将这些库拷贝到系统目录即可。程序的安装基本上要经过下面四个步骤:
- 将程序的可执行文件从安装包所在的位置,拷贝到要安装的目录。安装程序的时候,程序会给用户指定一个默认的安装目录,如果用户需要,也可以自定义安装,改变安装目录。一般所谓的
绿色软件到此就安装结束了,可以使用了。 - 如果有必要,可以向系统目录拷贝一些动态链接库(DLL)。(可选操作) 有的程序,比如大型游戏,可能需要很多动态链接库(DLL)的支持,这时候程序可能会将这些 DLL 拷贝到系统库的默认目录,Windows 下在 C:\Windows\System32\ 会看到很多 DLL 文件。有些程序用到的 DLL 文件不是系统必需的,只能由程序自己使用,这样放在系统目录里就不太合适,安装的软件多了,就会造成系统臃肿,所以这些 DLL 会被拷贝到程序的安装目录。

- 向系统注册表中写入相应的设置项,注册程序或者库的安装信息。(可选操作) 安装前,用户可能会对软件做一些设置,安装时,这些设置就会被写入注册表。另外,当安装程序将 DLL 文件拷贝到系统目录时,一些 DLL 还需要向系统注册,告诉系统我在这里,不然使用的时候可能会找不到。
- 在开始菜单或者桌面上位程序创建快捷方式。(可选操作) 创建快捷方式主要是为了用户使用方便,有了快捷方式,就不用再到安装目录去启动程序了。由此可见,程序在安装前后并没有什么区别,只不过是进行了一些设置,有的设置是程序运行所必须的,有的是为了让用户更加方便。
三、第一个C语言程序
我们有两种方式从计算机获得信息:一是看屏幕上的文字、图片、视频等,二是听从喇叭发出来的声音。让喇叭发出声音目前还比较麻烦,我们先来看看如何在屏幕上显示一些文字吧。在屏幕上显示文字非常简单,只需要一个语句,例如,下面的代码会让屏幕显示出 welcome to study C Program!\n:
puts("welcome to study C Program!\n");
这里有一个生疏的词汇 puts,用来让计算机在屏幕上显示文字。更加专业的称呼:
在屏幕上显示文字叫做输出 Output
每个文字都是一个字符 Character
多个字符组合起来,就是一个字符序列,叫做字符串 String
puts 是 output string 的缩写,意思是 输出字符串。 在C语言中,字符串需要用 双引号 " " 包围起来,welcome to study C Program!\n 什么也不是,计算机不认识它,"welcome to study C Program!\n" 才是字符串。puts 在输出字符串的时候,需要将字符串放在 ( ) 内。在汉语和英语中,分别使用 。 和 . 表示一句话的结束,而在C语言中,使用 ; 表示一个语句的结束。puts("welcome to study C Program!\n"); 表达了完整的意思,是一个完整的语句,需要在最后加上 ;,表示当前语句结束了。总结起来,上面的语句可以分为三个部分:
puts( )命令计算机输出字符串
"welcome to study C Program!\n" 是要输出的内容
;表示语句结束
C语言程序的整体框架: puts 可以在显示器上输出内容,但是仅有 puts 是不够的,程序不能运行,还需要添加其他代码,构成一个完整的框架。完整的程序如下:
#include 第 1~4 行、第 6~7 行是固定的,所有C语言源代码都必须有这几行。你暂时不需要理解它们是什么意思,反正有这个就是了,以后会慢慢讲解。但是请记住,今后我们写的所有类似 puts 这样的语句,都必须放在 { } 之间才有效。
打开安装好的 Ubuntu,进入到共享文件夹中,右键,选择 Open in Terminal,如下图所示:

进入终端命令行之后,使用 touch 命令,创建 hello.c 文件,如下图所示:

使用 Vim 编辑器打开 hello.c 文件,编写代码,如下图所示:

:wq 退出保存。Vim 使用参考:https://blog.csdn.net/xw1680/article/details/111880317
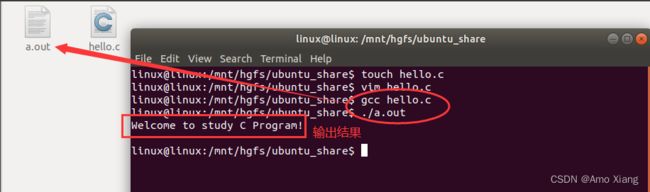
方法1: 使用系统生成的可执行文件。gcc hello.c 编译代码,系统默认会在当前目录下,生成一个叫做 a.out 的文件。 all out,./a.out 执行 a.out 文件,输出对应的结果,如下图所示:
方法2: 用户自定义可执行文件,gcc hello.c -o exec 编译代码,用户自定义生成的可执行文件名字。./exec 执行 ./exec 文件,输出对应的结果,如下图所示:

gcc 编译的流程:

预处理---->生成预处理过得C代码 xx.i
gcc -E xx.c -o xx.i -E 使编译器在预处理结束的时候停止
编译---->把我们预处理过的代码生成我们的汇编代码 xx.s
gcc -S xx.i -o xx.s -S 使编译器在编译结束的时候停止
汇编---->把汇编代码生成我们的目标文件 xx.o
gcc -c xx.s -o xx.o -c 使编译器在汇编结束的时候停止
链接---->把我们的目标文件生成我们的可执行文件
gcc xx.o -o xx -o 输出gcc编译的结果
分析第一个C语言程序:
先来看第 4 行代码,这行代码会在显示器上输出 welcome to study C Program!\n。前面我们已经讲过,puts 后面要带 ( ),字符串也要放在 ( ) 中。在C语言中,有的语句使用时不能带括号,有的语句必须带括号。带括号的称为 函数(Function)。 C语言提供了很多功能,例如输入输出、获得日期时间、文件操作等,我们只需要一句简单的代码就能够使用。但是这些功能的底层都比较复杂,通常是软件和硬件的结合,还要要考虑很多细节和边界,如果将这些功能都交给程序员去完成,那将极大增加程序员的学习成本,降低编程效率。好在C语言的开发者们为我们做了一件好事,他们已经编写了大量代码,将常见的基本功能都完成了,我们可以直接拿来使用。但是现在问题来了,那么多代码,如何从中找到自己需要的呢?一股脑将所有代码都拿来显然是非常不明智的。
这些代码,早已被分门别类地放在了不同的文件中,并且每一段代码都有唯一的名字。使用代码时,只要在对应的名字后面加上( )就可以。这样的一段代码能够独立地完成某个功能,一次编写完成后可以重复使用,被称为 函数(Function)。 读者可以认为,函数就是一段可以重复使用的代码。函数的一个明显特征就是使用时必须带括号 ( ),必要的话,括号中还可以包含待处理的数据。例如, puts("welcome to study C Program!\n"); 就使用了一段具有输出功能的代码,这段代码的名字是 puts,"welcome to study C Program!\n" 是要交给这段代码处理的数据。使用函数在编程中有专业的称呼,叫做 函数调用(Function Call)。
如果函数需要处理多个数据,那么它们之间使用逗号 , 分隔,例如:
pow(10, 2);
该函数用来求10的2次方。需要注意的是,C语言中的函数和数学中的函数不是同一个概念,不要拿两者对比。函数的英文名称是 Function,它还有 功能 的意思。
自定义函数和main函数: C语言自带的函数称为库函数(Library Function)。库(Library) 是编程中的一个基本概念,可以简单地认为它是一系列函数的集合,在磁盘上往往是一个文件夹。C语言自带的库称为 标准库(Standard Library), 其他公司或个人开发的库称为 第三方库(Third-Party Library)。 除了库函数,我们还可以编写自己的函数,拓展程序的功能。自己编写的函数称为自定义函数。自定义函数和库函数在编写和使用方式上完全相同,只是由不同的机构来编写。
示例中第 3~6 行代码就是我们自己编写的一个函数。main 是函数的名字,( ) 表明这是函数定义,{ } 之间的代码是函数要实现的功能。函数可以接收待处理的数据,同样可以将处理结果告诉我们;使用 return 可以告知处理结果。示例中第5行代码表明,main 函数的处理结果是整数 0。return 可以翻译为 返回,所以函数的处理结果被称为 返回值(Return Value)。 第2行代码中,int 是 integer 的简写,意为 整数。它告诉我们,函数的返回值是整数。
需要注意的是,示例中的自定义函数必须命名为 main。C语言规定,一个程序必须有且只有一个 main 函数。main 被称为主函数,是程序的入口函数,程序运行时从 main 函数开始,直到 main 函数结束(遇到 return 或者执行到函数末尾时,函数才结束)。也就是说,没有 main 函数程序将不知道从哪里开始执行,运行时会报错。综上所述:第 2~6 行代码定义了主函数 main,它的返回值是整数 0,程序将从这里开始执行。main 函数的返回值在程序运行结束时由系统接收。关于自定义函数的更多内容,我们将在后续的学习中详细讲解,这里不再展开讨论(在前期的学习过程中,大家只需要记着这种固定格式即可)。
#include #include 命令,并将文件名放在 < > 中,#include 和 < > 之间可以有空格,也可以没有。头文件以 .h 为后缀,而C语言代码文件以 .c 为后缀,它们都是文本文件,没有本质上的区别,#include 命令的作用也仅仅是将头文件中的文本复制到当前文件,然后和当前文件一起编译。你可以尝试将头文件中的内容复制到当前文件,那样也可以不引入头文件。.h 中代码的语法规则和 .c 中是一样的,你也可以 #include ,这是完全正确的。不过实际开发中没有人会这样做,这样看起来非常不专业,也不规范。较早的C语言标准库包含了15个头文件,stdio.h 和 stdlib.h 是最常用的两个:stdio 是 standard input output 的缩写,stdio.h 被称为 标准输入输出文件,包含的函数大都和输入输出有关,puts() 就是其中之一。stdlib 是 standard library 的缩写,stdlib.h 被称为 标准库文件,包含的函数比较杂乱,多是一些通用工具型函数,system() 就是其中之一。
总结:
- 第1行引入头文件 stdio.h,这是编程中最常用的一个头文件。头文件不是必须要引入的,我们用到了 puts 函数,所以才引入 stdio.h。例如下面的代码完全正确:
我们没有调用任何函数,所以不必引入头文件。int main() { return 0; } - 第3行开始定义主函数 main。main 是程序的入口函数,一个C程序必须有 main 函数,而且只能有一个
- 第4行调用 puts 函数向显示器输出字符串
- 第5行是 main 函数的返回值。程序运行正确一般返回 0
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习C语言的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!