2023-大数据应用开发-平台搭建部署实训
集群部署测试实训
1、组件版本
| 组件 | 版本 |
|---|---|
| jdk | 1.8 |
| hadoop | 3.1.3 |
| hive | 3.1.2 |
| Hbase | 2.2.3 |
| Kafka | 2.4.1 |
| redis | 6.2.6 |
| flume | 1.9.0 |
| maxwell | 1.29.0 |
| flink | 1.14.0 |
| clickhouse | 21.9.4 |
| mysql | 5.7 |
2、系统环境
- firewalld
- SSH
- NTP
- JDK
- MySQL
3、hadoop 完全分布式
步骤一、解压并重命名hadoop
[root@master ~]#
tar -xzvf /chinaskills/hadoop-3.1.3.tar.gz -C /usr/local/src/
mv /usr/local/src/hadoop-3.1.3 /usr/local/src/hadoop
步骤二、配置hadoop环境变量
[root@master ~]#
vim /root/.bash_profile
配置内容:
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
加载环境变量
source /root/.bash_profile
步骤三、配置hadoop-env.sh
[root@master ~]#
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
配置内容:
export JAVA_HOME=/usr/local/src/java
步骤四、配置core-site.xml
[root@master ~]#
vim $HADOOP_HOME/etc/hadoop/core-site.xml
配置内容:
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/src/hadoop/dfs/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.usersname>
<value>*value>
property>
步骤五、配置hdfs-site.xml
[root@master ~]#
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
配置内容:
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/local/src/hadoop/dfs/namevalue>
property>
<property>
<name>dfs.blocksizename>
<value>268435456value>
property>
<property>
<name>dfs.namenode.handler.countname>
<value>100value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/local/src/hadoop/dfs/datavalue>
property>
步骤六、配置yarn-site.xml
[root@master ~]#
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
配置内容:
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>4096value>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabled name>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>5value>
property>
步骤七、配置mapred-site.xml
[root@master ~]#
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
配置内容:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/src/hadoopvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/src/hadoopvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/src/hadoopvalue>
property>
<property>
<name>mapreduce.map.memory.mbname>
<value>2048value>
property>
<property>
<mame>mapreduce.map.java.optsmame>
<value>-Xmx1536Mvalue>
property>
<property>
<name>mapreduce.reduce.memory.mbname>
<value>4096value>
property>
<property>
<mame>mapreduce.map.java.optsmame>
<value>-Xmx2560Mvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dirname>
<value>/mr-history/tmpvalue>
property>
<property>
<name>mapreduce.jobhistory.done-dirname>
<value>/mr-history/donevalue>
property>
步骤八、配置works
[root@master ~]#
vim $HADOOP_HOME/etc/hadoop/workers
配置内容:
master
slave1
slave2
步骤九、修改start-dfs.sh和start-yarn.s
[root@master ~]#
vim $HADOOP_HOME/sbin/start-dfs.sh
配置内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vim $HADOOP_HOME/sbin/start-yarn.sh
配置内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
步骤十、修改stop-dfs.sh 和stop-yarn.sh
[root@master ~]#
vim $HADOOP_HOME/sbin/stop-dfs.sh
配置内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vim $HADOOP_HOME/sbin/stop-yarn.sh
配置内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
步骤十一、分发文件
[root@master ~]#
scp -r /usr/local/src/hadoop root@slave1:/usr/local/src/
scp -r /usr/local/src/hadoop root@slave2:/usr/local/src/
scp /root/.bash_profile root@slave1:/root/
scp /root/.bash_profile root@slave2:/root/
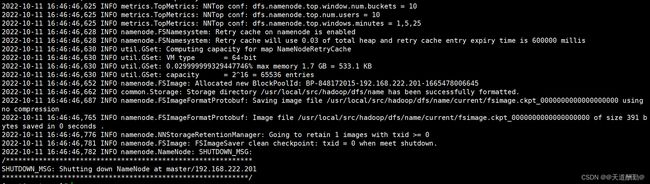
步骤十二、格式化namenode
[root@master ~]#
hdfs namenode -format
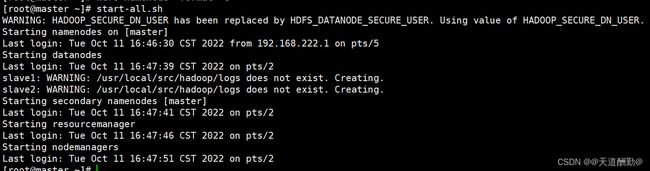
步骤十三、启动集群
[root@master ~]#
start-all.sh
步骤十四、查看jps守护进程
[root@master ~]#
jps
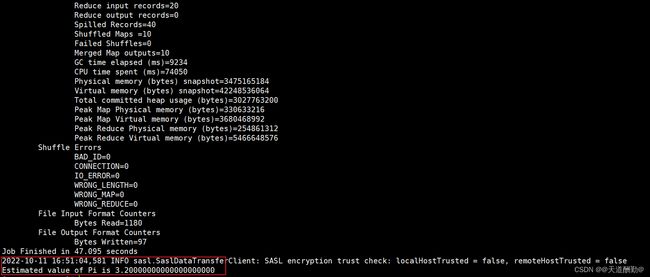
步骤十五、运行pi程序测试
[root@master ~]# 
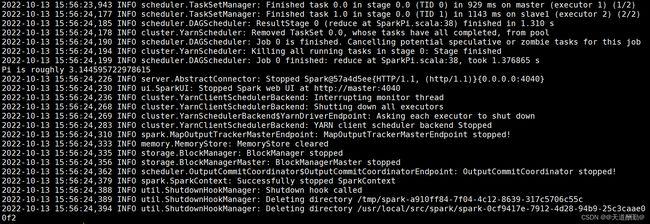
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 10 10
4、Hive部署
步骤一、解压并重命名
[root@master ~]#
tar -xzvf /chinaskills/apache-hive-3.1.2-bin.tar.gz -C /usr/local/src/
mv /usr/local/src/apache-hive-3.1.2-bin /usr/local/src/hive
步骤二、配置环境变量
[root@master ~]#
vim /root/.bash_profile
配置内容
export HIVE_HOME=/usr/local/src/hive
export PATH=$PATH:$HIVE_HOME/bin
加载环境变量
source /root/.bash_profile
步骤三、配置hive-site.xml
[root@master ~]#
cp /usr/local/src/hive/conf/hive-default.xml.template /usr/local/src/hive/conf/hive-site.xml
vim /usr/local/src/hive/conf/hive-site.xml
配置内容:
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://master:9083value>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>mastervalue>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
<property>
<name>hive.server2.thrift.min.worker.threadsname>
<value>5value>
property>
<property>
<name>hive.server2.thrift.max.worker.threadsname>
<value>500value>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://master:9083value>
property>
<property>
<name>hive.exec.scratchdirname>
<value>/tmp/hiveinfovalue>
property>
步骤四 添加mysql驱动包
[root@master ~]#
cp /chinaskills/mysql-connector-java-5.1.47.jar /usr/local/src/hive/lib/
步骤五、guava jar包版本冲突
[root@master ~]#
rm -rf /usr/local/src/hive/lib/guava-19.0.jar
cp /usr/local/src/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/src/hive/lib/
步骤六 hive初始化
[root@master ~]#
schematool -dbType mysql -initSchema
步骤七、开启metastore和H2S
[root@master ~]#
nohup hive --service metastore > metastore.log 2>&1 &
nohup hive --service hiveserver2 > H2S.log 2>&1 &
5、zookeeper分布式
步骤一、解压并重命名
[root@master ~]#
tar -xzvf /chinaskills/apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/src/
mv /usr/local/src/apache-zookeeper-3.7.1-bin /usr/local/src/zookeeper
步骤二、配置环境变量
[root@master ~]#
vim /root/.bash_profile
配置内容:
export ZOOKEEPER_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
步骤三 配置zoo.cfg
[root@master ~]#
cp /usr/local/src/zookeeper/conf/zoo_sample.cfg /usr/local/src/zookeeper/conf/zoo.cfg
vim /usr/local/src/zookeeper/conf/zoo.cfg
配置内容:
dataDir=/usr/local/src/zookeeper/data
dataLogDir=/usr/local/src/zookeeper/logs
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
步骤四 配置myid文件
[root@master ~]#
mkdir /usr/local/src/zookeeper/{data,logs}
echo "1" > /usr/local/src/zookeeper/data/myid
source /root/.bash_profile
步骤五 将文件发送给slave1和slave2
scp -r /usr/local/src/zookeeper slave1:/usr/local/src/
scp -r /usr/local/src/zookeeper slave2:/usr/local/src/
scp /root/.bash_profile slave1:/root/
scp /root/.bash_profile slave2:/root/
步骤六 修改slave1和slave2 myid文件
[root@slave1 ~]#
echo 2 > /usr/local/src/zookeeper/data/myid
source /root/.bash_profile
[root@slave2 ~]#
echo 3 > /usr/local/src/zookeeper/data/myid
source /root/.bash_profile
步骤七、启动zk集群
[root@master ~]#
zkServer.sh start
[root@slave1 ~]#
zkServer.sh start
[root@slave2 ~]#
zkServer.sh start
6、hbase 分布式部署
步骤一、解压并重命名
[root@master ~]#
tar -xzvf /chinaskills/hbase-2.2.3-bin.tar.gz -C /usr/local/src/
mv /usr/local/src/hbase-2.2.3 /usr/local/src/hbase
步骤二、配置环境变量并加载
[root@master ~]#
vim /root/.bash_profile
配置内容
export HBASE_HOME=/usr/local/src/hbase
export PATH=$PATH:$HBASE_HOME/bin
加载环境变量:
source /root/.bash_profile
步骤三、配置hbase-env.sh
[root@master ~]#
vim /usr/local/src/hbase/conf/hbase-env.sh
配置内容:
# 配置jdk文件路径
export JAVA_HOME=/usr/local/src/java
# 是否使用hbase的zk服务
export HBASE_MANAGES_ZK=false
步骤四、配置hbase-site.xml
[root@master ~]#
vim /usr/local/src/hbase/conf/hbase-site.xml
配置内容:
<property>
<name>hbase.rootdirname>
<value>hdfs://master:8020/hbasevalue>
property>
<property>
<name>hbase.tmp.dirname>
<value>/usr/local/src/hbase/tmpvalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>master,slave1,slave2value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/usr/local/src/zookeeper/datavalue>
property>
步骤五、配置regionservers
[root@master ~]#
vim /usr/local/src/hbase/conf/regionservers
配置内容:
slave1
slave2
步骤六、分发文件
[root@master ~]#
scp -r /usr/local/src/hbase root@slave1:/usr/local/src/
scp -r /usr/local/src/hbase root@slave2:/usr/local/src/
scp /root/.bash_profile root@slave1:/root/
scp /root/.bash_profile root@slave2:/root/
步骤七、启动集群
[root@master ~]#
start-hbase.sh
stop-hbase.sh
7、安装部署redis
步骤一、解压并重命名
[root@master ~]#
tar -xzvf /chinaskills/redis-6.2.6.tar.gz -C /usr/local/src/
步骤二、安装yum依赖
[root@master ~]#
yum install -y centos-release-scl yum-plugin-downloadonly devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils --downloadonly --downloaddir=redis_dependencies
步骤三、源码编译
[root@master ~]#
cd /usr/local/src/redis-6.2.6
[root@master redis-6.2.6]#
make
make install
步骤四、配置redis.conf
[root@master ~]#
vim /usr/local/src/redis-6.2.6/redis.conf
配置内容:
# 配置允许访问地址
bind 0.0.0.0 -::1
# 开启后台运行
daemonize yes
步骤五、启动redis服务
[root@master ~]#
redis-server /usr/local/src/redis-6.2.6/redis.conf
步骤六、客户端访问redis
[root@master ~]#
redis-cli --raw

8、部署clickhouse
步骤一、解压click-common
[root@master ~]#
tar -xzvf /chinaskills/clickhouse-common-static-21.1.9.41.tgz -C /usr/local/src/
mv /usr/local/src/clickhouse-common-static-21.1.9.41 /usr/local/src/clickhouse-common-static
步骤二、安装click-common
[root@master ~]#
/usr/local/src/clickhouse-common-static/install/doinst.sh
步骤三、解压click-server
[root@master ~]#
tar -xzvf /chinaskills/clickhouse-server-21.1.9.41.tgz -C /usr/local/src/
mv /usr/local/src/clickhouse-server-21.1.9.41 /usr/local/src/clickhouse-server
步骤四、安装click-server
[root@master ~]#
/usr/local/src/clickhouse-server/install/doinst.sh
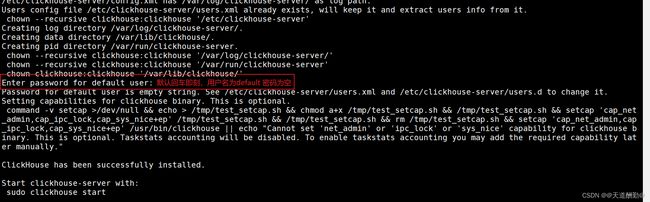
步骤五、启动click-server
[root@master ~]#
systemctl start clickhouse-server.service
步骤六、查看状态
[root@master ~]#
systemctl status clickhouse-server.service
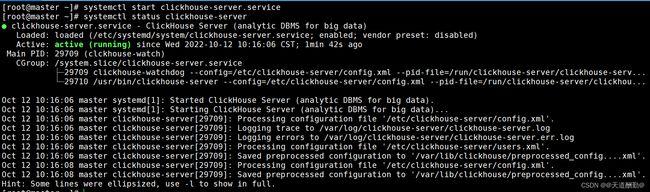
步骤七、解压click-client
[root@master ~]#
tar -xzvf /chinaskills/clickhouse-client-21.1.9.41.tgz -C /usr/local/src/
mv /usr/local/src/clickhouse-client-21.1.9.41 /usr/local/src/clickhouse-client
步骤八、安装客户端
[root@master ~]#
/usr/local/src/clickhouse-client/install/doinst.sh
步骤九、客户端连接服务端
[root@master ~]#
clickhouse-client

步骤十、关闭clickhouse
[root@master ~]#
systemctl stop clickhouse-server.service
9、部署flink
模式一、Flink Standalone
步骤一、解压并重命名
[root@master ~]#
tar -xzvf /chinaskills/flink-1.14.0-bin-scala_2.12.tgz -C /usr/local/src/
mv /usr/local/src/flink-1.14.0 /usr/local/src/flink
步骤二、配置环境变量
[root@master ~]#
vim /root/.bash_profile
配置内容:
export FLINK_HOME=/usr/local/src/flink
export PATH=$PATH:$FLINK_HOME/bin
加载环境变量
source /root/.bash_profile
步骤三、启动standalone集群
[root@master ~]#
start-cluster.sh

步骤四、提交一个任务
[root@master ~]#
flink run $FLINK_HOME/examples/batch/WordCount.jar

步骤五、关闭集群
[root@master ~]#
stop-cluster.sh

模式二、Flink 分布式集群
延续上述步骤
步骤一、配置master
[root@master ~]#
vim /usr/local/src/flink/conf/masters
配置内容:
master:8081
步骤二、配置works
[root@master ~]#
vim /usr/local/src/flink/conf/workers
配置内容:
slave1
slave2
步骤三、配置flink-conf.yaml
[root@master ~]#
vim /usr/local/src/flink/conf/flink-conf.yaml
配置内容:
# 设置jobmanager
jobmanager.rpc.address: master
步骤四、配置日志等级
[root@master ~]#
vim /usr/local/src/flink/conf/log4j.properties
配置内容:
rootLogger.level = DEBUG
步骤五、分发文件
[root@master ~]#
scp -r /usr/local/src/flink root@slave1:/usr/local/src
scp -r /usr/local/src/flink root@slave2:/usr/local/src
scp /root/.bash_profile root@slave1:/root
scp /root/.bash_profile root@slave2:/root
步骤六、启动集群
[root@master ~]#
start-cluster.sh

步骤七、关闭集群
[root@master ~]#
stop-cluster.sh

模式三、Flink on Yarn
延用上述配置
步骤一、配置hadoop classpath
[root@master ~]#
vim /root/.bash_profile
配置内容:
export HADOOP_CLASSPATH=$(/usr/local/src/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/Hadoop
加载环境变量
source /root/.bash_profile
步骤二、启动一个session会话
[root@master ~]#
yarn-session.sh -n 1 -jm 2048 -tm 4096 -d
步骤三、启动一个job任务
[root@master ~]#
flink run $FLINK_HOME/examples/batch/WordCount.jar
运行结果:
步骤四、关闭session会话
[root@master ~]#
flink list
echo "stop" | yarn-session.sh -id application_1665642382955_0004

步骤五、yarn-per-job提交
[root@master ~]#
flink run -t yarn-per-job $FLINK_HOME/examples/batch/WordCount.jar
报错警告
Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.
解决措施配置flink-conf.yaml
vim /usr/local/src/flink/conf/flink-conf.yaml
修改配置内容:
classloader.check-leaked-classloader: false

10、Spark on yarn
步骤一、解压并重命名
[root@master ~]#
tar -xzvf /chinaskills/spark-3.1.1-bin-hadoop3.2.tgz -C /usr/local/src/
mv /usr/local/src/spark-3.1.1-bin-hadoop3.2 /usr/local/src/spark
步骤二、配置环境变量
[root@master ~]#
vim /root/.bash_profile
配置内容
export SPARK_HOME=/usr/local/src/spark
export PATH=$PATHL:$SPARK_HOME/bin
加载环境变量
source /root/.bash_profile
步骤三、配置spark-env.sh
[root@master ~]#
cp /usr/local/src/spark/conf/spark-env.sh.template /usr/local/src/spark/conf/spark-env.sh
vim /usr/local/src/spark/conf/spark-env.sh
配置内容:
# java位置
export JAVA_HOME=/usr/local/src/java
# master节点IP或域名
export SPARK_MASTER_IP=master
# worker内存大小
export SPARK_WORKER_MEMORY=2G
# Worker的cpu核数
export SPARK_WORKER_CORES=2
export SCALA_HOME=/usr/local/scala
export SPARK_LOCAL_DIRS=/usr/local/src/spark
# hadoop配置文件路径
export HADOOP_CONF_DIR=/usr/local/src/hadoop/etc/hadoop
步骤四、测试job任务
[root@master ~]#
spark-submit --master yarn --class org.apache.spark.examples.SparkPi /usr/local/src/spark/examples/jars/spark-examples_2.12-3.1.1.jar